Introduction aux Ansible Content Collections
On ne présente plus Ansible, un outil de configuration management et de provisionning Open Source qui se démarque pour sa souplesse, la simplicité de son architecture et de son utilisation.
La version 2.9 introduit un nouveau concept (précédemment en tech preview) qui touche au mécanisme de distribution de contenu : Les collections.
Quels problèmes sont résolus avec les collections ? Comment en tant que développeur de playbook vais-je utiliser ce nouveau concept ? Je vous propose un petit tour d’horizon qui vous permettra de mieux comprendre les collections Ansible ainsi qu’une présentation de la commande <br>ansible-test<br> qui permet de tester le contenu d’une collection.
Le challenge des mainteneurs
Si l’on regarde le projet sur Github, on peut facilement voir que la somme de travail de l’équipe de Redhat est conséquente :
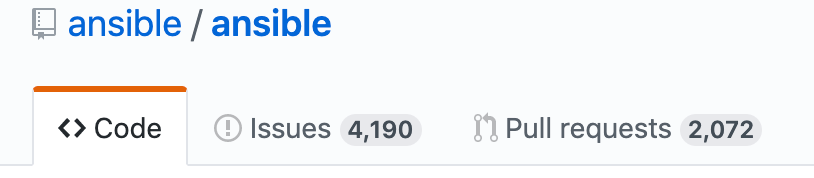
Plus de 4 000 issues ouvertes et 2 000 Pull Requests à traiter au moment de l’écriture de ces lignes.
Derrière ces chiffres se cache une organisation centralisée du code Ansible. Toutes les contributions au projet passent par un seul et même repository, il n’y a pas de séparation entre le cœur d’Ansible et les contributions de la communauté qui étendent l’outil avec divers modules.
En comparaison, un projet comme Terraform d’Hashicorp a vu ses sources se séparer entre le cœur de l’outil et les providers. Les providers peuvent donc suivre leur propre cycle de vie et les correctifs être déployés fréquemment. Le projet du cœur du produit est donc libéré (délivré) du “bruit” lié aux contributions de la communauté.
En effectuant une recherche dans le repository Ansible, sur les presque 4 000 modules disponibles, pas loin de 3 000 modules sont marqués comme supportés par la communauté !
Les mainteneurs du projets ont donc cherché un moyen de faire basculer les contributions de la communauté en dehors du projet principal (<br>ansible/ansible<br>) afin de permettre aux modules et autres plugins d’avoir un cycle de release plus rapide et indépendant vis à vis du cœur Ansible.
La solution choisie se tourne vers Ansible Galaxy et un nouveau format de distribution supporté par Galaxy : les collections. Le plan annoncé ici consiste à faire sortir les contributions de la communauté du dépôt principal pour les transformer en collections dont les sources seront dans un dépôt différent.
Il sera donc impossible de parler d’Ansible sans évoquer les collections dans un avenir très proche, et nous pouvons commencer à manipuler ce nouveau concept dès la version 2.9 d’Ansible.
Je n’irai pas plus loin concernant la stratégie de déplacement des sources des modules “community” dans cet article. La stratégie des mainteneurs n’étant pas encore communiquée. Cependant l’objectif reste d’avoir Ansible “battery included” suite à la commande <br>pip install ansible<br>.
C’est quoi une collection ?
Les collections sont un simple format de distribution de contenu pour Ansible Galaxy. Dans les faits, une collection est une grosse archive compressée qui contient votre contenu dans une arborescence stricte :
<br>collection/<br>├── docs/<br>├── galaxy.yml<br>├── plugins/<br>│ ├── modules/<br>│ │ └── module1.py<br>│ ├── inventory/<br>│ └── .../<br>├── README.md<br>├── roles/<br>│ ├── role1/<br>│ ├── role2/<br>│ └── .../<br>├── playbooks/<br>
On y retrouve un répertoire <br>roles<br> dans lequel les utilisateurs de Galaxy ayant déjà publié un rôle pourront placer leur code et retrouver leurs habitudes. La nouveauté se trouve évidemment dans la présence de répertoires visant à accueillir le nouveau contenu distribuable sur Galaxy, parmis les plus intéressants on trouvera :
<br>plugins/modules<br>: pour vos modules.<br>plugins/inventory<br>: pour vos plugins d’inventaire.<br>plugins/filter<br>: pour vos filtres.<br>plugins/module_utils<br>: pour le code commun à vos plugins !
Une collection vous permettra donc de créer une suite de composants utilisables avec Ansible. Les filtres et modules ne seront plus liés à un rôle mais utilisables n’importe où dès le moment où la collection sera installée. La présence du répertoire plugins/module_utils permettra également de factoriser le code (Python vraisemblablement) entre les différents composants de la collection ce qui facilitera la maintenance pour l’auteur de la collection.
Créer une collection
Pour illustrer l’utilisation des collections nous allons créer une collection contenant un rôle et un filtre et nous tenterons d’utiliser ces deux composants dans un playbook. Le rôle et le filtre seront des plus inutiles et ne serviront qu’à illustrer l’utilisation d’une collection.
Commençons par créer un répertoire de travail en créant un répertoire <br>ansible_collections<br> :
<br>$ mkdir ansible_collections<br>
Le nom du répertoire n’est pas anodin, Ansible sera très regardant sur l’arborescence menant à une collection et vos collections devront impérativement être placées dans un répertoire <br>ansible_collections<br> !
Dans la suite de l’article nous partirons du principe que les commandes doivent être exécutées depuis ce répertoire.
Pour faciliter la vie aux utilisateurs, la commande ansible-galaxy a été enrichie d’une sous-commande <br>collection<br> :
<br>$ ansible-galaxy collection --help<br>usage: ansible-galaxy collection [-h] COLLECTION_ACTION ...<br><br>positional arguments:<br>COLLECTION_ACTION<br>init Initialize new collection with the base structure of a<br>collection.<br>build Build an Ansible collection artifact that can be publish<br>to Ansible Galaxy.<br>publish Publish a collection artifact to Ansible Galaxy.<br>install Install collection(s) from file(s), URL(s) or Ansible<br>Galaxy<br><br>optional arguments:<br>-h, --help show this help message and exit<br>
La commande init nous permet de créer l’arborescence de base d’une collection :
<br>$ ansible-galaxy collection init rrey.my_collection<br>- Collection rrey.my_collection was created successfully<br>
Le nom de la collection doit respecter le format ., ces deux notions permettent de faire de la classification sur votre compte Ansible Galaxy.
Nous nous retrouvons donc avec l’arborescence suivante :
<br>rrey/<br>└── my_collection<br>├── README.md<br>├── docs<br>├── galaxy.yml<br>├── plugins<br>│ ├── README.md<br>├── roles<br>
Créons maintenant un rôle <br>idiot<br> qui affichera simplement un message de debug :
<br>$ ansible-galaxy role init idiot<br>- Role idiot was created successfully<br>
Il devient important d’utiliser la commande ansible-galaxy pour créer la structure du role car la commande va créer les fichiers attendus pour une publication sur Galaxy. Après une rapide modification du fichier meta/main.yml nous pouvons écrire notre rôle :
<br><br># rrey/my_collection/roles/idiot/tasks/main.yml<br>---<br><br>- name: mon debug<br> debug:<br> msg: "{{ ansible_default_ipv4.address }}"<br><br>...<br><br>
Le rôle affichera simplement l’adresse ipv4 de la machine cible dans une tâche de debug. Créons également un filtre qui ne fera rien de plus intelligent mais qui nous servira à illustrer l’utilisation d’un filtre présent dans notre collection :
<br><br># rrey/my_collection/plugins/filter/my_custom_filters.py<br><br>from __future__ import (absolute_import, division, print_function)<br>__metaclass__ = type<br><br><br>def split_ip(value):<br> return value.split(".")<br><br><br>class FilterModule(object):<br><br> def filters(self):<br> return {<br> 'split_ip': split_ip<br> }<br>
Ce fichier permet de créer un filtre jinja2 appelé <br>split_ip<br> qui nous renverra les chiffres composants une address IP sous forme de liste.
Revenons à notre rôle et utilisons ce filtre :
<br><br># rrey/my_collection/roles/idiot/tasks/main.yml<br>---<br><br>- name: mon debug<br> debug:<br> msg: "{{ ansible_default_ipv4.address | rrey.my_collection.split_ip }}"<br><br>...<br>
Nous rencontrons la première subtilité de l’utilisation d’une collection. Il est désormais nécessaire de préciser le namespace et le nom de la collection que nous utilisons : <br>rrey.my_collection<br> Cette forme d’appel est appelée Fully Qualified Collection Name (FQCN).
Nous avons maintenant une collection avec un filtre et un rôle, essayons de tester l’utilisation de cette collection.
Testons l’utilisation de notre collection
Afin de pouvoir utiliser notre collection nous devons préciser à Ansible son emplacement car nous n’avons pas créé celle-ci dans l’un des emplacements reconnu par défaut :
<br>$HOME/.ansible/collections<br><br>/usr/share/ansible/collections<br>
Note : Vous remarquerez que ces emplacements par défaut ne contiennent pas le fameux répertoire <br>ansible_collections<br> auquel je fais référence en début d’article. Il sera pourtant bien créé par la commande d’installation que nous verrons un peu plus tard dans l’article. La documentation n’est actuellement pas très explicite sur le côté indispensable de ce répertoire et méritera une petite mise à jour.
Nous pouvons utiliser deux méthodes pour ajouter un chemin vers des collections :
- A travers ansible.cfg en ajoutant le paramètre
<br>collections_paths<br>dans la section<br>defaults<br> - A travers la variable d’environnement
<br>ANSIBLE_COLLECTIONS_PATHS<br>
Les 2 méthodes nécessitent de renseigner la liste complètes des emplacements de collections. J’ai choisis d’utiliser ansible.cfg pour cet article, nous devons donc créer le fichier ansible.cfg dans notre répertoire avec le contenu suivant:
<br><br># ansible.cfg<br>[defaults]<br>collections_paths = ~/.ansible/collections:/usr/share/ansible/collections:/Users/remi.rey<br>
Dans mon exemple j’ai ajouté l’emplacement <br>/Users/remi.rey<br> car c’est l’endroit dans lequel j’ai créé le répertoire <br>collections_paths<br> en début d’article. N’oubliez pas d’adapter le chemin avec l’emplacement que vous avez utilisé sur votre poste.
Créons ensuite un playbook de test utilisant notre collection :
<br><br># test.yml<br><br>- hosts: localhost<br> gather_facts: true<br> tasks:<br> - import_role:<br> name: rrey.my_collection.idiot<br>
Notre playbook est des plus simple, nous exécutons en local le rôle <br>idiot<br> en précisant le FQCN de la collection lors de l’appel du rôle.
L'exécution de notre playbook nous donne la sortie suivante :
<br>$ ansible-playbook test.yml<br><br>PLAY [localhost] **************************************************************************************************************************<br><br>TASK [Gathering Facts] ********************************************************************************************************************<br>ok: [localhost]<br><br>TASK [idiot : mon debug] ******************************************************************************************************************<br>ok: [localhost] => {<br> "msg": [<br> "10",<br> "103",<br> "253",<br> "109"<br> ]<br>}<br><br>PLAY RECAP ********************************************************************************************************************************<br>localhost : ok=2 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0<br>
Nous avons bien le message de debug attendu renvoyant l’adresse de mon poste traité par mon filtre.
Une autre forme d’appel est possible dans notre playbook pour éviter la répétition du FQCN :
<br><br># test.yml<br><br>- hosts: localhost<br> gather_facts: true<br> collections:<br> - rrey.my_collection<br> tasks:<br> - import_role:<br> name: idiot<br>
L’ajout du paramètre <br>collections<br> avec notre collection comme élément de liste nous permet de supprimer le namespace et le nom de la collection lors de l’appel du rôle.
Publication de notre collection
Maintenant que nous avons une collection (des plus inutiles, mais qui sert notre besoin de démo), nous pouvons réfléchir à la publier sur Ansible Galaxy. La première étape passe par la mise à jour du fichier galaxy.yml situé dans <br>rrey/my_collection<br>. Voici l’exemple minimal que nous utiliserons :
<br><br># rrey/my_collection/galaxy.yml<br><br>namespace: rrey<br>name: my_collection<br>version: 1.0.0<br>readme: README.md<br><br>authors:<br>- Rémi REY <br><br>license:<br>- GPL-2.0-or-later<br>license_file: ''<br><br><br>tags: []<br>dependencies: {}<br>repository: http://example.com/repository<br>documentation: http://docs.example.com<br>homepage: http://example.com<br>issues: http://example.com/issue/tracker<br>
Le fichier généré par la commande ansible-galaxy collection init contient de la documentation sous forme de commentaires que j’ai supprimés dans mon exemple pour rester concis.
Attention avec le versioning, une fois la collection publiée il sera impossible de supprimer votre version (seul le marquage <br>deprecated<br> sera possible). Ne faites pas comme dans mon exemple où je marque directement ma collection en version 1.0.0 pour la première publication, il sera de bon ton de passer par des versions expérimentale en 0.X.Y (0.0.1 par exemple).
Note : le paramètre <br>dependencies<br> permet de déclarer une dépendance avec une autre collection. Par exemple:
<br><br>dependencies: {<br> "geerlingguy.k8s": ">=0.9.0"<br>}<br>
Nous allons maintenant construire le livrable attendu par Ansible Galaxy (une archive compressée) à l’aide de la commande ansible-galaxy :
<br>$ cd rrey/my_collection<br>$ ansible-galaxy collection build<br>Created collection for rrey.my_collection at /Users/remi.rey/tmp/rrey/my_collection/rrey-my_collection-1.0.0.tar.gz<br>
La collection n’est toujours pas publiée, mais l’archive est générée en local et les plus curieux pourront en afficher le contenu avec la commande tar :
<br><br>$ tar tvzf rrey-my_collection-1.0.0.tar.gz<br>-rw-r--r-- 0 0 0 578 29 oct 17:27 MANIFEST.json<br>-rw-r--r-- 0 0 0 2237 29 oct 17:27 FILES.json<br>drwxr-xr-x 0 0 0 0 29 oct 15:46 plugins/<br>-rw-r--r-- 0 0 0 957 29 oct 15:22 plugins/README.md<br>drwxr-xr-x 0 0 0 0 29 oct 16:08 plugins/filter/<br>-rw-r--r-- 0 0 0 252 29 oct 15:59 plugins/filter/my_custom_filters.py<br>drwxr-xr-x 0 0 0 0 29 oct 16:22 roles/<br>drwxr-xr-x 0 0 0 0 29 oct 15:44 roles/idiot/<br>drwxr-xr-x 0 0 0 0 29 oct 16:09 roles/idiot/tasks/<br>-rw-r--r-- 0 0 0 113 29 oct 16:09 roles/idiot/tasks/main.yml<br>drwxr-xr-x 0 0 0 0 29 oct 15:13 docs/<br>-rw-r--r-- 0 0 0 76 29 oct 15:13 README.md<br>
Nous retrouvons notre arborescence de collection, les répertoires de namespace et de nom de collection ayant disparus. Ceux-ci étant présents dans le nom de l’archive, ils ne sont pas nécessaires dans l’archive.
Des fichiers font leur apparition :
- FILES.json : qui contient la liste des fichiers avec leur sha256.
- MANIFEST.json : qui contient des métadonnées sur la collection, on y retrouvera les informations du fichier galaxy.yml.
Ne nous attardons pas plus longuement sur l’archive et allons publier notre collection ! Vous l’aurez probablement deviné, la commande ansible-galaxy va nous permettre de faire la publication :
<br>$ ansible-galaxy collection publish ./rrey-my_collection-1.0.0.tar.gz --api-key votre_cle_d_api_a_recuperer_sur_galaxy<br>Publishing collection artifact '/Users/remi.rey/tmp/rrey/my_collection/rrey-my_collection-1.0.0.tar.gz' to default https://galaxy.ansible.com/api/<br>Collection has been published to the Galaxy server default https://galaxy.ansible.com/api/<br>Waiting until Galaxy import task https://galaxy.ansible.com/api/v2/collection-imports/502 has completed<br>Collection has been successfully published and imported to the Galaxy server default https://galaxy.ansible.com/api/<br>
La commande nécessite une clé d’API en argument, cette clé est récupérable depuis les préférences de votre compte Ansible Galaxy.
Note : La création d’un compte Galaxy n’est possible que si vous possédez un compte Github.
Vous pouvez maintenant vous connecter sur Ansible Galaxy et vous rendre dans le menu “My Content” pour y voir apparaître votre collection:
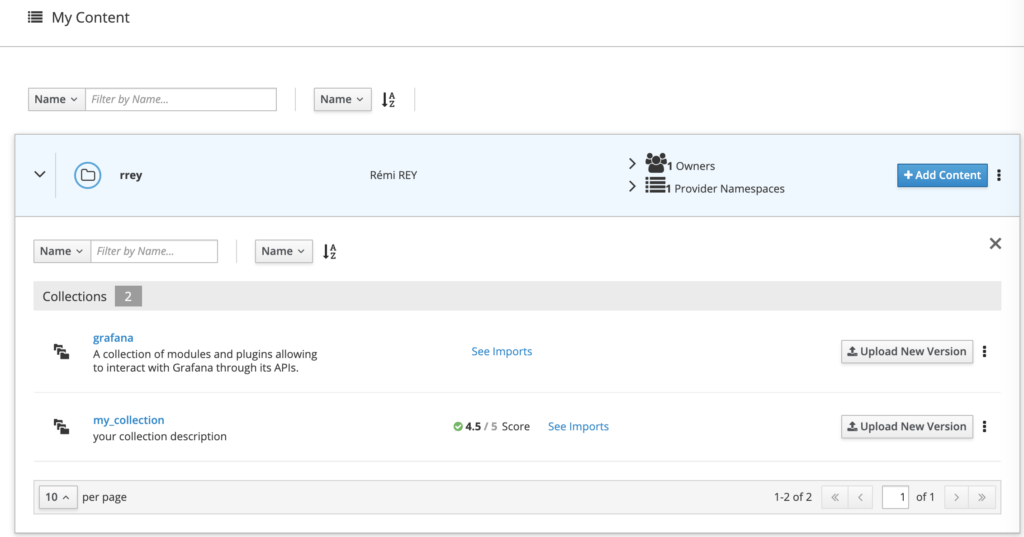
On pourra remarquer qu’un score de qualité a été positionné sur notre collection ! Celui-ci est basé sur l'exécution des linters <br>yamlint<br> et <br>ansible-lint<br> sur notre code. Il est possible de voir le détail des tests depuis l’interface :
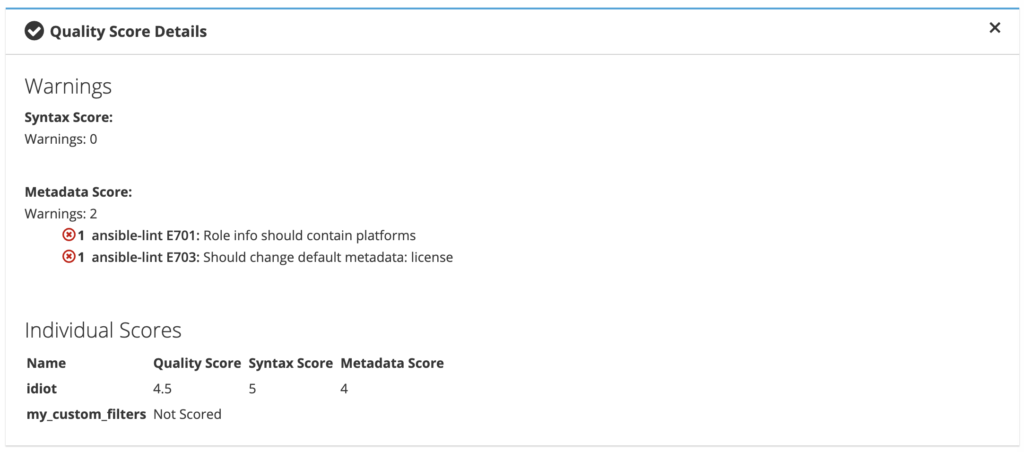
Il faudra donc faire le nécessaire pour avoir la meilleure note possible pour attirer des utilisateurs ou des mainteneurs !
La page principale de votre collection affichera des informations intéressantes comme le nombre de téléchargements et les liens vers le repo Github, la doc, le tracker d’issues ou le site du projet. Ces informations sont toutes issues du fichier galaxy.yml, d’où l’importance de le compléter soigneusement :

Utilisation d’une collection venant de Galaxy
Maintenant que nous avons une collection sur Galaxy, plaçons nous dans la peau d’un utilisateur.
Créons un nouveau répertoire avec notre playbook de test. Le fait de changer de répertoire fera disparaître la détection automatique de la collection en locale.
<br>$ mkdir galaxy-test<br>$ cp test.yml galaxy-test/<br>$ cd galaxy-test/<br>
Installons maintenant la collection comme un utilisateur lambda d’Ansible Galaxy :
<br>$ ansible-galaxy collection install rrey.my_collection<br>Process install dependency map<br>Starting collection install process<br>Installing 'rrey.my_collection:1.0.0' to '/Users/remi.rey/.ansible/collections/ansible_collections/rrey/my_collection'<br>
La commande install ne demande que le nom de la collection sous sa forme. Comme nous pouvons le voir sur la sortie standard, la collection a été copiée dans <br>$HOME/.ansible/collections/ansible_collections/<br>
Il est également possible de préciser la version de la collection dans la commande <br>install<br> :
<br>$ ansible-galaxy collection install rrey.my_collection:1.0.0<br>
Nous devrions donc a priori être capable d’exécuter le playbook sans opération supplémentaire :
<br>$ ansible-playbook test.yml<br><br>PLAY [localhost] **************************************************************************************************************************<br><br>TASK [Gathering Facts] ********************************************************************************************************************<br>ok: [localhost]<br><br>TASK [idiot : mon debug] ******************************************************************************************************************<br>ok: [localhost] => {<br> "msg": [<br> "10",<br> "103",<br> "253",<br> "109"<br> ]<br>}<br><br>PLAY RECAP ********************************************************************************************************************************<br>localhost : ok=2 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0<br>
Tout fonctionne ! L’installation de collections peut également se faire à travers un fichier requirements.yml :
<br><br>---<br>collections:<br>- name: rrey.my_collection<br> version: 1.0.0<br>
Et la commande d’installation devient :
<br>$ ansible-galaxy collection install -r requirements.yml<br>
On retrouvera donc les mécanismes existant avec l’utilisation de rôle sur Galaxy.
Les tests (c’est la vie) !
Nous n’avons pas parlé de tests jusqu’à présent et Ansible 2.9 introduit une nouvelle commande bien connue des contributeurs au projet Ansible : <br>ansible-test<br>
<br>ansible-test<br> est l’outil qui permet l'exécution des tests sur le projet ansible/ansible et celui-ci mériterait un article à lui seul pour couvrir toutes ses fonctionnalités mais cette présentation de Matt Clay à l’AnsibleFest Atlanta 2019 permet d’avoir un bon aperçu. A voir absolument ! (Si un article vous intéresse sur ce sujet, envoyez-moi une boite de chocolat au siège d’OCTO Technology) L’outil va nous permettre de jouer des tests unitaires (avec <br>unittest<br> et <br>pytest<br>) et des tests d’intégration (avec des rôles Ansible) mais également des tests syntaxiques (<br>pep8<br>, <br>yamllint<br>).
Rajoutons donc quelques tests sur le contenu de notre collection, en nous concentrant sur le filtre.
Tests unitaires
Commençons par la base de la pyramide de tests, les tests unitaires. Créons tout d’abord l’arborescence attendue par <br>ansible-test<br> pour un test unitaire :
<br>$ cd rrey/my_collection/<br>$ mkdir -p tests/unit/plugins/filter/<br>
l’arborescence est importante car elle permet à <br>ansible-test<br> de retrouver les différents types de tests supportés (units, sanity, integration etc ...). La commande help de <br>ansible-test<br> nous permet de voir cette liste:
<br>$ ansible-test --help<br>usage: ansible-test [-h] COMMAND ...<br><br>positional arguments:<br> COMMAND<br> integration posix integration tests<br> network-integration<br> network integration tests<br> windows-integration<br> windows integration tests<br> units unit tests<br> sanity sanity tests<br> shell open an interactive shell<br> coverage code coverage management and reporting<br> env show information about the test environment<br><br>optional arguments:<br> -h, --help show this help message and exit<br>
Note : Attention au piège avec ansible 2.9.0, la commande <br>ansible-test --help<br> ne fonctionne que dans le répertoire d’une collection, soit <br>rrey/my_collection<br> dans mon exemple. C’est un bug, qui est reporté ici.
Avec cette arborescence, nous pouvons écrire notre premier test unitaire :
<br><br># tests/unit/plugins/filter/test_my_custom_filters.py<br><br>import unittest<br>from ansible_collections.rrey.my_collection.plugins.filter.my_custom_filters import split_ip<br><br><br>class TestMyFilter(unittest.TestCase):<br><br> def test_filter_can_split_an_ip(self):<br><br> # Given<br> filter_input = "10.0.0.1"<br> # When<br> result = split_ip(filter_input)<br> # Then<br> self.assertEqual(result, ["10", "0", "0", "1"])<br>
Je teste ici le cas nominal en appelant la fonction qui implémente mon filtre <br>split_ip<br> avec une chaîne contenant une adresse IP valide. Exécutons la commande permettant d'exécuter le test :
<br><br>$ cd rrey/my_collection<br>$ ansible-test units --docker<br>[...]<br>Unit test with Python 3.7<br>============================= test session starts ==============================<br>platform linux -- Python 3.7.4, pytest-5.2.1, py-1.8.0, pluggy-0.13.0<br>rootdir: /root/ansible/ansible_collections/rrey/my_collection/tests/unit/plugins/filter, inifile: /root/ansible/test/lib/ansible_test/_data/pytest.ini<br>plugins: forked-1.1.1, mock-1.11.1, f5-sdk-3.0.21, xdist-1.30.0<br>gw0 I / gw1 I<br>gw0 [1] / gw1 [1]<br><br>.<br>- generated xml file: /root/ansible/ansible_collections/rrey/my_collection/tests/output/junit/python3.7-units.xml -<br>============================== 1 passed in 1.15s ===============================<br>Unit test with Python 3.8<br>============================= test session starts ==============================<br>platform linux -- Python 3.8.0, pytest-5.2.1, py-1.8.0, pluggy-0.13.0<br>rootdir: /root/ansible/ansible_collections/rrey/my_collection/tests/unit/plugins/filter, inifile: /root/ansible/test/lib/ansible_test/_data/pytest.ini<br>plugins: forked-1.1.1, mock-1.11.1, f5-sdk-3.0.21, xdist-1.30.0<br>gw0 I / gw1 I<br>gw0 [1] / gw1 [1]<br><br>.<br>- generated xml file: /root/ansible/ansible_collections/rrey/my_collection/tests/output/junit/python3.8-units.xml -<br>============================== 1 passed in 1.23s ===============================<br>
L’option <br>--docker<br> permet de demander à <br>ansible-test<br> de jouer le test dans un container docker, ce qui me permettra de toujours exécuter mon test dans un environnement isolé. En 2019 avec docker, nous ne devrions plus entendre “ça marche sur mon poste” dans les open spaces.
Non seulement mon test est validé mais nous pouvons voir qu’il a été exécuté 5 fois avec des interpréteurs différents (Python 2.7, 3.5, 3.6, 3.7 et 3.8). (J’ai volontairement supprimé une partie de la sortie standard renvoyée par la commande)
Si vous vous demandiez ce qu’apporterait <br>ansible-test<br> à votre environnement d’Intégration Continue, vous devriez avoir un début de réponse ; une seule commande permet de lancer les tests avec les 5 interpréteurs Python supportés officiellement par Ansible.
On remarquera au passage qu’un rapport de test Junit au format XML est généré pour chaque exécution. Il sera donc facile d’avoir un rapport consultable depuis une belle interface web avec des outils compatible (Gitlab et Jenkins en autres).
Si j’avais développé mon filtre en TDD, j’aurais pu tout de suite remarquer que mon filtre n’allait pas très bien réagir si je lui donnais autre chose qu’une chaîne en input et ajouter le test suivant :
<br><br>import unittest<br>from ansible.module_utils._text import to_bytes<br>from ansible_collections.rrey.my_collection.plugins.filter.my_custom_filters import split_ip<br><br><br>class TestMyFilter(unittest.TestCase):<br><br> def test_filter_can_split_an_ip(self):<br> filter_input = "10.0.0.1"<br> result = split_ip(filter_input)<br> self.assertEqual(result, ["10", "0", "0", "1"])<br><br> def test_filter_with_invalid_input(self):<br> filter_input = 42<br> with self.assertRaises(AnsibleError) as result:<br> split_ip(filter_input)<br> self.assertEqual(result.exception.args[0], "split_ip expects a str type argument, got int")<br>
En relançant mon test j’obtiens l’erreur suivante :
<br><br>[...]<br>============================= test session starts ==============================<br>platform linux2 -- Python 2.7.15+, pytest-4.6.6, py-1.8.0, pluggy-0.13.0<br>rootdir: /root/ansible/ansible_collections/rrey/my_collection/tests/unit/plugins/filter, inifile: /root/ansible/test/lib/ansible_test/_data/pytest.ini<br>plugins: forked-1.1.1, mock-1.11.1, f5-sdk-3.0.21, xdist-1.30.0<br>gw0 I / gw1 I<br>gw0 [2] / gw1 [2]<br><br>.F<br>=================================== FAILURES ===================================<br>_________________ TestMyFilter.test_filter_with_invalid_input __________________<br>[gw1] linux2 -- Python 2.7.15 /tmp/python-f9trp1k5-ansible/python<br>self = <br><br> def test_filter_with_invalid_input(self):<br> filter_input = 42<br>> result = split_ip(filter_input)<br><br>tests/unit/plugins/filter/test_my_custom_filters.py:15:<br>_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _<br><br>value = 42<br><br> def split_ip(value):<br>> return value.split(".")<br>E AttributeError: 'int' object has no attribute 'split'<br><br>plugins/filter/my_custom_filters.py:6: AttributeError<br>[...]<br>
Si ma collection est destinée à être publiée sur Galaxy, autant faire en sorte que les utilisateurs finaux n’aient pas à lire les exceptions Python pour comprendre le crash du filtre. Modifions notre filtre pour améliorer son fonctionnement :
<br><br>from __future__ import (absolute_import, division, print_function)<br>from ansible.errors import AnsibleFilterError<br>__metaclass__ = type<br><br><br>def split_ip(value):<br> if not isinstance(value, str):<br> raise AnsibleFilterError("split_ip expects a str type argument, got %s" % type(value).__name__)<br> return value.split(".")<br><br><br>class FilterModule(object):<br><br> def filters(self):<br> return {<br> 'split_ip': split_ip<br> }<br>
En relançant ma commande <br>ansible-test<br>, j’ai bien mes 2 tests qui passent maintenant :
<br><br>[...]<br>============================= test session starts ==============================<br>platform linux -- Python 3.8.0, pytest-5.2.1, py-1.8.0, pluggy-0.13.0<br>rootdir: /root/ansible/ansible_collections/rrey/my_collection/tests/unit/plugins/filter, inifile: /root/ansible/test/lib/ansible_test/_data/pytest.ini<br>plugins: forked-1.1.1, mock-1.11.1, f5-sdk-3.0.21, xdist-1.30.0<br>gw0 I / gw1 I<br>gw0 [2] / gw1 [2]<br><br>..<br>- generated xml file: /root/ansible/ansible_collections/rrey/my_collection/tests/output/junit/python3.8-units.xml -<br>============================== 2 passed in 1.27s ===============================<br>
Nous pourrions encore améliorer notre filtre, car il pourrait vérifier avec une regex que la chaîne correspond bien à une forme d’adresse IP, mais ce n’est pas l’objectif de l’article.
Tests d’intégration
Avec <br>ansible-test<br> les tests d'intégration sont réalisés à l’aide de rôles Ansible. Nous allons écrire un rôle qui fera appel à notre filtre et nous ferons des assertions après chaque appel pour vérifier que le filtre a renvoyé ce qui est attendu.
Créons tout d’abord l’arborescence attendue par <br>ansible-test<br> pour un test integration :
<br>$ cd rrey/my_collection/<br>$ mkdir -p tests/integration/targets/my_custom_filters/{tasks,defaults}<br>
Dans le répertoire <br>tests<br> nous créons un répertoire <br>integration<br> qui permettra à la commande <br>ansible-test integration<br> de trouver tous les tests d'intégration.
Nous trouvons ensuite un répertoire <br>targets<br> que nous n’avions pas pour les tests unitaires. C’est dans ce répertoire que nous allons créer nos rôles de tests. Dans mon exemple le répertoire <br>my_custom_filters<br> est un rôle qui me permettra de tester mon filtre.
Dans mon rôle <br>my_custom_filters<br>, je vais créer des variables que j’utiliserai pendant mes tests :
<br><br># tests/integration/targets/my_custom_filters/defaults/main.yml<br>---<br><br>valid_address: "10.0.0.1"<br>invalid_address: "I am not an address"<br>non_str_value: 42<br><br>...<br>
Je peux maintenant créer les tâches de tests dans mon rôle :
<br><br>---<br><br>- name: call the filter with a valid address<br> set_fact:<br> result: "{{ valid_address | rrey.my_collection.split_ip }}"<br><br>- assert:<br> that: 'result == ["10", "0", "0", "1"]'<br><br>- name: call the filter with a invalid address<br> set_fact:<br> result: "{{ invalid_address | rrey.my_collection.split_ip }}"<br><br>- assert:<br> that: 'result == ["I am not an address"]'<br><br>- name: call the filter with a non string input<br> set_fact:<br> result: "{{ non_str_value | rrey.my_collection.split_ip }}"<br> ignore_errors: yes<br> register: err<br><br>- assert:<br> that:<br> - 'err.failed == true'<br> - 'err.msg == "split_ip expects a str type argument, got int"'<br><br>...<br>
Pour mes tests j’utilise le module <br>set_fact<br> pour stocker le résultat du traitement de mes variables par mon filtre et le module <br>assert<br> pour vérifier que la variable contient bien la valeur attendue.
L’un de mes tests couvre le cas que j’ai implémenté à l’aide de mes tests unitaires. Je donne au filtre un entier qui doit provoquer une erreur de traitement par le filtre. Pour pouvoir tester qu’une erreur a été renvoyée, j’utilise le paramètre <br>ignore_errors: yes<br> qui va éviter l’arrêt d’Ansible lors de l’échec de traitement du filtre et j’enregistre l’output du module <br>set_fact<br> qui contiendra le JSON suivant:
<br><br>{<br> "failed": true,<br> "msg": "split_ip expects a str type argument, got int"<br>}<br>
Je peux donc m'assurer que la tâche a échouée et que j’ai reçu le message d’erreur attendu avec le dernier <br>assert<br> de mon exemple.
Sanity Tests
Le dernier type de tests dont je parlerai dans cet article est le test syntaxique ou “sanity test”. Ces tests ne nécessitent aucune action de votre part et peuvent immédiatement être exécutés :
<br>$ ansible-test sanity --docker<br>[...]<br>Running sanity test 'empty-init' with Python 3.6<br>Running sanity test 'future-import-boilerplate' with Python 3.6<br>See documentation for help: https://docs.ansible.com/ansible/2.9/dev_guide/testing/sanity/future-import-boilerplate.html<br>ERROR: Found 1 future-import-boilerplate issue(s) which need to be resolved:<br>ERROR: tests/unit/plugins/filter/test_my_custom_filters.py:0:0: missing: from __future__ import (absolute_import, division, print_function)<br>Running sanity test 'ignores'<br>Running sanity test 'import' with Python 2.6<br>Running sanity test 'import' with Python 2.7<br>Running sanity test 'import' with Python 3.5<br>Running sanity test 'import' with Python 3.6<br>Running sanity test 'import' with Python 3.7<br>Running sanity test 'import' with Python 3.8<br>Running sanity test 'line-endings' with Python 3.6<br>Running sanity test 'metaclass-boilerplate' with Python 3.6<br>ERROR: Found 1 metaclass-boilerplate issue(s) which need to be resolved:<br>ERROR: tests/unit/plugins/filter/test_my_custom_filters.py:0:0: missing: __metaclass__ = type<br>See documentation for help: https://docs.ansible.com/ansible/2.9/dev_guide/testing/sanity/metaclass-boilerplate.html<br>Running sanity test 'no-assert' with Python 3.6<br>Running sanity test 'no-basestring' with Python 3.6<br>Running sanity test 'no-dict-iteritems' with Python 3.6<br>Running sanity test 'no-dict-iterkeys' with Python 3.6<br>Running sanity test 'no-dict-itervalues' with Python 3.6<br>Running sanity test 'no-get-exception' with Python 3.6<br>Running sanity test 'no-illegal-filenames' with Python 3.6<br>Running sanity test 'no-main-display' with Python 3.6<br>Running sanity test 'no-smart-quotes' with Python 3.6<br>Running sanity test 'no-unicode-literals' with Python 3.6<br>Running sanity test 'pep8' with Python 3.6<br>Running sanity test 'pslint'<br>Running sanity test 'pylint' with Python 3.6<br>Running sanity test 'replace-urlopen' with Python 3.6<br>Running sanity test 'rstcheck' with Python 3.6<br>Running sanity test 'shebang' with Python 3.6<br>Running sanity test 'shellcheck'<br>Running sanity test 'symlinks' with Python 3.6<br>Running sanity test 'use-argspec-type-path' with Python 3.6<br>Running sanity test 'use-compat-six' with Python 3.6<br>Running sanity test 'validate-modules' with Python 3.6<br>Running sanity test 'yamllint' with Python 3.6<br>ERROR: The 2 sanity test(s) listed below (out of 41) failed. See error output above for details.<br>future-import-boilerplate<br>metaclass-boilerplate<br>
On peut voir que la commande me remonte des erreurs dans le code de mon filtre avec un lien vers la documentation en ligne expliquant le problème. En corrigeant les fichiers mis en évidence comme la documentation le demande, l'exécution des tests passent sans erreur.
On peut voir que pas moins de 42 types de tests sont exécutés, incluant notamment <br>yamllint<br>, <br>pylint<br> et <br>pep8<br>.
Une petite minute … Souvenez-vous de ma publication sur Galaxy, l’interface m’avait attribuée un score de qualité de 4.5/5, quelles étaient les erreurs ?
<br>ansible-lint E701: Role info should contain platforms<br><br>ansible-lint E703: Should change default metadata: license<br>
Tiens donc … Ces erreurs (des warnings en fait) ne font pas partie des problèmes que nous avons corrigés jusqu’ici. La raison est simple mais pas forcément satisfaisante : Ansible Galaxy execute yamllint et <br>ansible-lint<br> sur le code publié mais <br>ansible-test<br> n’utilise pas <br>ansible-lint<br> …
Si cela vous choque, sachez que le sujet a été discuté sur cette issue GitHub et qu’il n’est pas prévu que <br>ansible-lint<br> soit intégré à <br>ansible-test<br>... Il reste possible d’installer <br>ansible-lint<br> et de lancer la commande nous-même :
<br>$ pip install ansible-lint<br>$ cd rrey/my_collection/roles<br>$ ansible-lint *<br>[701] Role info should contain platforms<br>/Users/remi.rey/ansible_collections/rrey/my_collection/roles/idiot/meta/main.yml:1<br>{'meta/main.yml': {'galaxy_info': {'author': 'Rémi REY', 'description': 'Un exemple idiot de role', 'company': 'YOLOCORP', 'license': 'license (GPL-2.0-or-later, MIT, etc)', 'min_ansible_version': 2.9, 'galaxy_tags': [], '__line__': 1, '__file__': '/Users/remi.rey/ansible_collections/rrey/my_collection/roles/idiot/meta/main.yml'}, 'dependencies': [], '__line__': 1, '__file__': '/Users/remi.rey/ansible_collections/rrey/my_collection/roles/idiot/meta/main.yml'}}<br><br>[703] Should change default metadata: license<br>/Users/remi.rey/ansible_collections/rrey/my_collection/roles/idiot/meta/main.yml:1<br>{'meta/main.yml': {'galaxy_info': {'author': 'Rémi REY', 'description': 'Un exemple idiot de role', 'company': 'YOLOCORP', 'license': 'license (GPL-2.0-or-later, MIT, etc)', 'min_ansible_version': 2.9, 'galaxy_tags': [], '__line__': 1, '__file__': '/Users/remi.rey/ansible_collections/rrey/my_collection/roles/idiot/meta/main.yml'}, 'dependencies': [], '__line__': 1, '__file__': '/Users/remi.rey/ansible_collections/rrey/my_collection/roles/idiot/meta/main.yml'}}<br>
Nous retrouvons bien les 2 warnings qui étaient affichés sur Galaxy. La documentation en ligne permettra de résoudre les 2 alertes remontées et d’obtenir un score de 5/5 sur Galaxy !
Quels apports ?
Prenons un exemple avec un outil que nous utilisons souvent en mission : Grafana. Grafana est un outil de monitoring qui permet de créer des dashboards en se basant sur différents backends contenant des métriques. Le produit possède une API assez complète qui permet d’automatiser la création d’éléments dans Grafana (de l’utilisateur au dashboard en passant par les datasources).
A ce jour, Ansible ne possède que 3 modules pour Grafana (<br>grafana_datasource<br>, <br>grafana_dashboard<br> et <br>grafana_plugin<br>) et plusieurs modules mériteraient d’être écrits pour couvrir les besoins d’automatisation. Si nous écrivions ces modules aujourd’hui, nous devrions attendre la prochaine version d’Ansible pour les voir être distribués à la communauté. Cette mise à disposition pourrait donc prendre entre 3 et 4 mois, rythme de publication des versions d’Ansible.
Avec les collections, nous pouvons maintenant créer une collection pour Grafana et y centraliser toutes les contributions autour du produit Grafana. Le cycle de vie des modules, plugins et autre rôles pour Grafana pourra donc être indépendant du cycle de vie du cœur Ansible et des fonctionnalités peuvent apparaître en installant la nouvelle version de la collection. Nos nouveaux modules pourraient donc être disponibles dès demain.
Les collections permettent également de distribuer plus de contenu :
Un rôle pour installer Grafana sur un serveur
Un rôle pour configurer Grafana :
les utilisateurs
les équipes
les datasources
les dashboards
...
Un playbook appelant tous les rôles de la collection
Les modules pour interagir avec Grafana
Les filtres facilitant le traitement de variables
etc ...
Un utilisateur d’Ansible pourra donc trouver dans la collection tout ce qui est nécessaire pour interagir avec le produit, de son installation sur un serveur à sa configuration complète. Il ne restera à l’utilisateur qu'à créer les bonnes variables dans les <br>group_vars<br> et à appeler le playbook.
Le mot de la fin
Les collections apportent de la valeur dans Galaxy en permettant de distribuer plus de contenu et la perspective d’avoir des releases plus fréquentes est rassurante vis à vis de la stabilité des modules de la communauté.
Malgré un manque de documentation, l’arrivée de <br>ansible-test<br> permettra aux plus exigeants d’entre nous de satisfaire leur besoin de couverture de tests (Coucou les Octos !). Nous espérons voir naître sur le site docs.ansible.com de belles pages destinées aux utilisateurs de <br>ansible-test<br> en dehors du dépôt <br>ansible/ansible<br>.
Nous nous posons cependant des questions sur l'adhérence des collections avec le serveur Galaxy. Il n’y a pas de mention dans la documentation sur la possibilité d’utiliser l’URL d’un repository Git ou d’un Artefact Manager pour récupérer une collection. L’utilisation en entreprise avec des sources privées devra donc attendre cette fonctionnalité ou vous devrez effectuer quelques manipulations pour récupérer une collection localement (<br>wget<br> ou <br>git submodule<br> FTW).
L’évolution du projet dans les mois à venir va incontestablement tourner autour des collections. Ne ratez pas le train !