Algorithmes de recommandation : principes et mise en pratique
Notre objectif est d’effectuer de la recommandation d’articles pour le Blog Octo et sa nouvelle application mobile. Nous allons donc dans un premier temps étudier les contraintes de notre problème. Et dans un second temps, explorer ce qui se fait en matière d’algorithmes de recommandations afin de l’appliquer à notre usecase.
Introduction
Le blog Octo est en train de se munir d’une application mobile. Pour cette application Android, on va essayer de “comprendre l’utilisateur” et déterminer quelle(s) page(s) il est le plus susceptible de consulter. De cela découlent deux objectifs. Effectuer le pré-chargement des prochaines pages ou articles (ce qui permet entre autres de consulter un article même en l’absence de réseau), et effectuer de la recommandation d’articles afin de fidéliser le lecteur. On cherche à prédire le parcours des utilisateurs en prenant en compte les contraintes (hardware et software) qui sont propres à un téléphone.
Quelques éléments de contexte
Avant de se lancer dans la présentation des algorithmes de recommandation, comme tout projet de machine learning, il est important de consacrer du temps à comprendre les données que nous avons (data exploration).
Afin de rendre l’utilisation de l’application la plus simple possible, il a été choisi de ne pas proposer la création de compte. Quiconque souhaite lire un article n’a qu’à télécharger, installer et lancer l’application. Il est possible pour l’utilisateur de filtrer la liste des articles par catégorie pour mieux s’y retrouver.
Dans notre cas d’usage, nos données de base sont celles que nous pouvons récupérer du blog Octo. C’est un site WordPress, il dispose d’une base de donnée MySQL où sont stockées plusieurs informations dans différentes tables que l’on peut retrouver via l’API WordPress. Les informations que l’on récupère sont celles des articles (Posts) et des utilisateurs (Users):
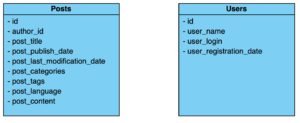
Enfin, il n’existe pas de compte utilisateur dans l’application mobile mais on peut quand même récupérer des informations intéressantes. Nous avons donc réfléchi aux données qui pourraient nous être utiles. Pour l’instant, nous avons choisi de récupérer pour chaque lecture d’article :

- visited_through_category_filtering indique si l’article a été consulté à la suite d’un filtrage par catégorie, et si c’est le cas on récupère l’id de la catégorie
- is_visited_through_recommendation indique si l’article a été consulté via une recommandation (c’est notamment utile lorsqu’on essaiera d’évaluer notre modèle)
Maintenant que nous avons fait un tour des données dont nous disposons, nous pouvons nous attaquer aux algorithmes de recommandation.
Catégorisation des algorithmes de recommandation (d’articles)
Les algorithmes de recommandation sont devenus très populaires avec l'avènement des journaux en ligne, des sites de e-commerce et de VOD. Ils permettent aux marchands d'optimiser leurs ventes, de fidéliser la clientèle, et aux utilisateurs de s’y retrouver devant l’immense quantité d’information à laquelle ils peuvent faire face. Les algorithmes de recommandation peuvent être divisés en trois catégories qui dépendent des différents types de données sur lesquelles ils s’appuient, en voici les trois types :
- les algorithmes de filtrage collaboratif
- les algorithmes basés sur des règles
- les algorithmes basés sur le contenu
Algorithmes de filtrage collaboratif
Le filtrage collaboratif (ou collaborative filtering) est l’ensemble des techniques utilisant le lien utilisateur-produit. Ce lien est représenté par des avis ou des notes, il est utilisé pour construire un système de recommandation personnalisé.
On peut notamment retrouver ce genre de systèmes chez Amazon lorsqu’il vous est recommandé des articles avec la mention “les utilisateurs ayant aimé cet article ont aussi aimé xxx ”

image : recommandations d’Amazon
Pour faire du FC, on peut faire du filtrage basé sur l’utilisateur ou bien du filtrage basé sur l’article. Dans les deux cas on regarde les notes d’un utilisateur sur un article. Ces notes peuvent êtres attribuées de façon active (en demandant directement à l’utilisateur de noter l’article) ou bien de façon passive (le nombre d'écoutes d'une musique sur Spotify par exemple).
On se retrouve avec une matrice utilisateur-article creuse (avec beaucoup de champs vides). Chaque personne dans la base de données peut être considérée comme un vecteur incomplet de notes, où la composante α sera la note de l’utilisateur correspondante pour l’article α. De la même façon, un article peut être considéré comme un vecteur où chaque composante représente un utilisateur et sa note pour l’article.
Exemple:
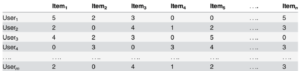
User-User
Le filtrage user-user sur l’utilisateur revient à dire que “les personnes qui vous ressemblent ont aimé l’article X.”
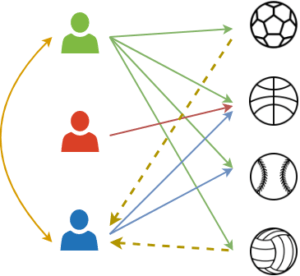
image : filtrage User-User
Pour cela, lorsqu’on a obtenu suffisamment de notes pour chaque utilisateur, une mesure de similarité entre tous les utilisateurs est effectuée. Pour calculer cette mesure, on emploie la corrélation de Karl Pearson qui s’exprime comme suit:
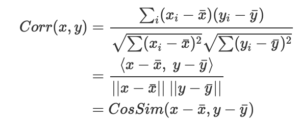

(c’est la plus couramment utilisée dans ce cas, mais il en existe d'autres cf: section 2.3. de l'article de Elsa Negre. Comparaison de textes: quelques approches.... 2013. ffhal-00874280f). Elle permet d’établir la corrélation entre deux vecteurs et donne un résultat dans [-1, 1]. Deux vecteurs de variables aléatoires parfaitement corrélées donneront donc 1, non corrélées 0, et -1 pour si elles sont inversement corrélées.
En appliquant donc la corrélation de Pearson aux vecteurs des utilisateurs on peut établir ceux qui sont plus similaires les uns des autres. Une fois ceci fait, en effectuant la moyenne pondérée sur les notes des utilisateurs qui sont semblables à un utilisateur donné, on peut estimer la note qu'aurait attribuée cet utilisateur à un article qu’il n’a pas encore noté. En faisant cela pour tous ces articles sans notes, il ne nous reste plus qu'à suggérer à notre utilisateur l’article avec la plus haute note.
Item-Item
Ici, le FC revient à dire à l’utilisateur que les personnes ayant acheté/consulté un objet X ont également acheté/consulté l’objet Y.
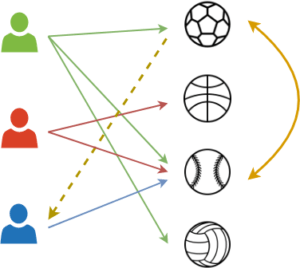
image : filtrage Item-Item
Ce deuxième type de FC est très semblable au premier, à ceci près que cette fois c’est l’article qui est au centre. Au lieu de calculer les similarités des utilisateurs par rapport aux notes des utilisateurs, cette fois on calcule la similarité des objets par rapport aux notes des utilisateurs. (N.B. : on regarde leur similarité d’un point de vue notation et non sur ce que sont vraiment les objets).
Pour calculer la similarité entre deux articles on prend le vecteur des deux objets, on conserve uniquement les composantes qui sont non vides pour les deux, et on calcule le cosinus de l’angle entre les deux vecteurs.
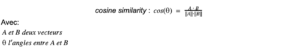
En appliquant une moyenne pondérée de façon similaire au FC User-User on peut retrouver la note pour une paire item-user.
Pour conclure sur les Algorithmes de filtrage collaboratif
Ces deux façons de faire fonctionnent très bien lorsque l’on est capable de réunir assez de données sur les notes des utilisateurs. De plus, elles sont relativement faciles à mettre en place tant que l’on a de quoi gérer des données. La différence entre ces deux FC se trouve au niveau de la scalabilité. Là où le FC User-User va se complexifier très vite plus il y a d’utilisateurs à cause du calcule des plus proches voisins, le FC Item-Item n’aura pas ce problème, la note moyenne d’un objet ne changera jamais beaucoup pour une nouvelle note utilisateur. De plus il donnera même en moyenne de meilleurs résultats.
Il va de soi que de tels modèles sont inutilisables pour le blog Octo. D’une part on est incapable de maintenir un suivi utilisateur pour répertorier les notes, et d’autre part il n’existe tout simplement aucun moyen de notation par utilisateur des articles sur le blog. (Ce qui, au passage, pourrait être une bonne feature à étudier). Ne parlons même pas des problèmes de stockage des données et calculs des similarités sur téléphone, bien de sécurité des données avec la RGPD.
Algorithmes basés sur des règles
Ces algorithmes cherchent à établir des règles générales et de les appliquer afin d’atteindre leur but. Dans le cas de la recommandation d’articles on pourrait imaginer des règles telles que “recommander les articles les plus récents” ou “recommander les articles les plus consultés”
A/B testing
Le Test A/B est une technique de marketing qui consiste à proposer plusieurs variantes d'un même objet qui diffèrent selon un seul critère (par exemple, la couleur d'un emballage, méthode de diffusion d’une publicité) afin de déterminer la version qui donne les meilleurs résultats auprès des consommateurs (wikipedia/Test_A/B). C'est une technique particulièrement employée dans la communication en ligne où il est maintenant possible de tester auprès d'un échantillon de personnes plusieurs versions d'une même page web, d'une même application mobile, d'un même e-mail ou d'une bannière publicitaire afin de choisir celle qui est la plus efficace et de l'utiliser à large échelle.
Les algorithmes du bandit se basent sur le A/B testing
Choisissons un ensemble de stratégies commerciales. A un temps t, l’une de ces stratégies est celle qui donne les meilleurs résultats lorsqu’on l’applique à nos clients. C’est The One Size Fits All Method. Or, rien ne nous garantit que cette stratégie restera la meilleure à un temps t+1. Pour vérifier si c’est toujours le cas a t+1, il nous faut alors essayer toutes les autres stratégies (c’est l’exploration) mais aussi continuer d’utiliser notre meilleure stratégie à la majorité de notre population (c’est l’exploitation). En pratique on choisira notre stratégie optimale avec une probabilité P, et aléatoirement l’une des autres stratégies avec une probabilité 1 - P.
Le problème du bandit à plusieurs bras (multi-armed bandit) est un framework qui nous permet alors d’utiliser notre method one-size-fits-all et de tester en continu si l’une de nos autres stratégies est plus efficace que l’actuelle.
Pour ce faire, on définit une fonction de reward μ (cela peut être par exemple le nombre de fois qu’une personne clique sur un article) qui dépend du bras (la stratégie) et de l’itération à laquelle nous sommes. Ceci étant dit, on peut alors définir le regret comme suit:

Le but lors de l'implémentation de l’algorithme du bandit est alors de minimiser notre regret. Il existe deux algorithmes de références qui sont chargés de trouver ce minimum de la fonction de regret et qui sont epsilon-greedy et UCB1.
Il existe une sous-catégorie des algorithmes du bandit que l’on appelle algorithme du bandit contextuel (Contextual bandit). On peut le considérer comme un hybride présenté plus haut. A la différence d’un bandit classique qui choisira sa population d’exploration de façon aléatoire. Le bandit contextuel possédera en amont, par exemple, un classifieur sur sa population pour faire émerger des profils et ainsi appliquer l’algorithme du bandit à des sous populations.
Quelques références pour cette partie_:_ aspect théorique : Introduction aux algorithmes de bandit - Rémi Munos aspect un peu plus technique : Multi-armed bandit implementation
Algorithmes basés sur le contenu
Le contenu peut représenter bon nombre de choses. Dans le cas d’un article de blog, ça peut être:
- Le titre
- Les mots qui composent le document
- Les Catégories ou Tags
- Le nom de l’auteur
- etc.
Les algorithmes basés sur le contenu sont ceux qui paraissent le plus évident au premier abord. Si on se met à lire un article sur le sujet du DevOps en Data Science il y a de très grandes chances pour que l’on soit intéressé par un autre article traitant du DevOps ou de la Data Science ou des deux à la fois. C’est de ce genre de modèles que traite cette partie.
Il existe de nombreuses approches pour effectuer de la comparaison de documents en se basant sur leur contenu textuel. Ces approches peuvent être statistiques avec des approches telles que l'analyse sémantique latente (LSA / PLSA) ou l’analyse sémantique explicite (ESA), ou bien vectorielles avec des méthodes de Bi-clustering ou de Vecteurs Sémantiques. Mais dans un souci de concision et de clarté je n’aborderai pas toutes les approches dans cet article (pour plus de détails cf: la section 3.2 de cet article ).
J’ai choisi de présenter ici une implémentation de l’approche faisant appel aux Vecteurs Sémantiques.
Text embedding avec Doc2Vec
Doc2Vec est une implémentation d’embedding de documents de la librairie Gensim qui se base sur celle de Word2Vec (pour plus de précision sur Word2vec et sur ce qu’est l’embedding cf:https://fr.wikipedia.org/wiki/Word_embedding).
Doc2Vec permet d’obtenir une représentation numérique de documents (contre une représentation numérique de mots pour Word2vec). On fournit à l'algorithme des documents de taille (en nombre de mots) variable et on obtient en sortie un vecteur de taille fixe. Le modèle analyse les mots contenus dans les documents (il pourrait d’ailleurs être intéressant de choisir soi-même le dictionnaire de mots pour l’algorithme). Des poids sont attribués à chaque mot au travers de tout le corpus et des poids sont attribués à chaque document du corpus en fonction des mots qu’il contient. Une fois que l'entraînement du modèle est fait, on peut en fonction des poids des mots établir celui de tout nouveau document. En effectuant une mesure de distance (cosine similarity) de tous les documents entre eux on peut déterminer leur similarité.
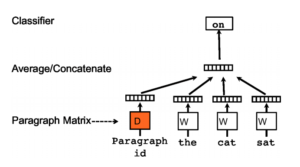
Doc2Vec est un modèle de réseau de neurones à une couche cachée et peut être décliné en deux façons :
- PV-DM model (pour Distributed Memory version of Paragraph Vector) qui est similaire au CBOW utilisé par Word2vec. A partir d’un ensemble de mots (le contexte) on peut en déduire le mot qui va suivre.
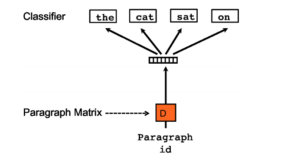
- PV-DBOW (pour Distributed Bag of Words version of Paragraph Vector) similaire au Skip-Gram utilisé par Word2vec. A partir d’un mot on peut déduire la phrase (le contexte) qui va suivre.
On se retrouve au final avec une matrice de poids relativement légère et avec laquelle il est facile de faire des calculs de distances. Ce qui est très intéressant lorsqu’on dispose de peu de puissance pour effectuer les inférences et que l’on ne dispose pas de beaucoup d'espace sur notre machine. Néanmoins, l'entraînement du modèle peut être long et coûteux sur des gros datasets, comme c’est le cas sur un téléphone.
Modèle hybride
Les modèles hybrides, comme leur nom l’indique se basent sur plusieurs approches de recommandation à la fois. Le but est de pallier les inconvénients d’une approche et de proposer des recommandations plus fines.
Ces modèles peuvent se baser sur n’importe quel type de données disponible. Par exemple des métadonnées sur un article (catégorie(s), auteur, date de publication, etc.). Le but est d’utiliser des techniques de machine learning classiques, comme un Fuzzy C-means sur des utilisateur, afin de faire ressortir des clusters ou des points communs non explicites. On peut alors, sur ces nouvelles connaissances, appliquer les autres méthodes de recommandation énoncées dans l’article.
On peut par exemple utiliser les deux méthodes de filtrage collaboratif à la fois. On choisit alors le meilleur résultat de l’une des méthodes, ou de fusionner l’ensemble des recommandations.
Si on dispose d’une bonne méthode d’évaluation, on peut même imaginer appliquer un algorithme du bandit afin de déterminer la technique de recommandation optimale
Pour conclure à propos des algorithmes basés sur le contenu
Comme on l’a vu, avec ces types d’algorithmes on peut se baser directement sur le contenu dont on dispose. On s'affranchit d’ajouter une couche de travail sur des métriques extérieures au média que l’on traite (i.e. : articles de blogs, musiques, produits etc.).
Ce qu’il faut retenir sur les algorithmes de recommandation
Les algorithmes de recommandation (d’articles ou autre) se résument bien souvent par une mesure de similarité entre deux choses (du contenu, des utilisateurs, etc.). Ils ne font pas tous appels aux même métriques, ou concepts mathématiques. Ainsi, l’implémentation et l’infrastructure dépendent du modèle. Il nous incombe alors de faire le choix du modèle qui correspond le mieux à notre use case.
Dans notre cas, l’utilisation d’un modèle capable de fonctionner entièrement sur mobile a énormément contraint nos choix. Il n’est pas évident d’évaluer la pertinence des algorithmes tant les méthodes de mesure du feedback utilisateur ne sont pas explicites. L’absence de système de notation et de données utilisateurs m’a directement écarté tout modèle qui y faisait appel (filtrage collaboratif). La nécessité d’une infrastructure fonctionnelle extérieure au téléphone a exclu la solution des algorithmes comme celui du bandit. Finalement, le filtrage basé sur le contenu m’a paru être la solution la plus pertinente au vu de nos contraintes techniques. De plus, la volonté d’explorer ce que l'embedding avait à offrir a arrêté mon choix sur le modèle Doc2Vec. Cette solution nous permet de nous baser entièrement sur ce que le blog d’Octo a de mieux à nous offrir, ses articles.