Introduction à la Programmation Orientée Acteurs
Depuis le milieu des années 2000, l’augmentation de la puissance de calcul de nos ordinateurs ne passe plus par l’élévation de la fréquence des processeurs mais par la multiplication des cœurs de processeur au sein de nos machines.
Pour tirer parti de cette multiplication, un algorithme doit être parallèlisé, c’est à dire qu’il doit pouvoir diviser ses instructions et les répartir sur différents cœurs pour une exécution simultanée. De nombreux outils permettent d’implémenter un algorithme parallèle sur une machine, par exemple la librairie Task Parallelism Library (TPL) en .Net, abordé par Olivier Roux et Alexis Flaurimont ou encore le fork/join en Java étudié par Marc Bojoly et David Rousselie.
D’autres outils, implémentant par exemple le pattern Map/Reduce, permettent de distribuer le calcul vers des cœurs situés sur différentes machines.
Cet article présentera une introduction à la programmation orientée acteurs et les réponses qu’elle apporte à ces différents problèmes.
Cette programmation est issue d’un article paru en 1973, A Universal Modular Actor Formalism for Artificial Intelligence Carl Hewitt; Peter Bishop and Richard Steiger. Ericson, au milieu des années 80, implémente ce modèle en utilisant le langage Erlang pour la conception de systèmes téléphoniques robustes et distribués. Ce modèle est à présent repris, par Akka notamment, dont on utilisera la librairie version 1.2 en Java.
Cette implémentation donne à un acteur trois caractéristiques principales :
- Il possède un état interne.
- Il traite séquentiellement des messages stockés dans une queue.
- Il peut émettre des messages asynchrones à d’autres entités.
Dans cet article, l’implémentation d’un exemple simple permettra de mettre en avant certaines possibilités de cette solution.
Dans une première partie, on présentera le problème à traiter, puis on le modélisera selon la programmation orientée acteurs. Dans une deuxième partie, nous réaliserons une implémentation parallèle sur une unique machine puis, dans une troisième partie, nous distribuerons les calculs sur plusieurs nœuds.
1. Modélisation du problème
Exemple à implémenter
Réalisons un programme qui renvoie des images selon des dimensions demandées. Il reçoit la demande d’une image selon certaines dimensions (hauteur, largeur), charge l’image originale depuis le disque, réalise son redimensionnement et la transmet.
public byte[] Process(int imageNumber, int width, int height) {
byte[] imageBytes = loadImage(imageNumber) ;
byte[] resizedImage = createResizedImage(imageBytes, width, height);
return resizedImage ;
}
Le processus est déclenché de manière évènementielle, i.e. les demandes sont traitées au fur et à mesure et non accumulées pour être traitées par lot.
Cette contrainte rend difficile l’utilisation d’outils de parallélisation de boucle de type paralleleFor de la librairie TPL car on ne connaît pas initialement le nombre d’itérations à effectuer. Une implémentation du pattern Master/Worker ou le master empile des tâches dans une file d’attente consommée par les workers serait plus adaptée. C’est sur la base de ce pattern que nous allons modéliser ce problème en acteurs.
Modélisation du problème
Une modélisation possible en acteurs de notre exemple comporte quatre types d’acteurs : un « Producer » émettant les demandes, un « Reader » récupérant l’image depuis le disque dur, un « Resizer » redimensionnant l’image, et un acteur « Exit » réceptionnant l’image redimensionnée.

Le message partagé entre les acteurs contient ici le numéro de l’image à charger, les dimensions voulues, et l’image. On a volontairement pris soin de séparer les accès IO et les calculs de redimensionnement afin de bénéficier d’une plus grande souplesse lorsque l’on parallélisera l’implémentation. Pour reprendre l’analogie avec le pattern Master/Worker, on peut ici considérer que chaque acteur est le master de l’acteur qu’il précède.
2. Implémentation parallèle sur une machine
Implémentation naïve
Le message échangé est implémenté par une simple classe immuable sérialisable appelée ImageMessage.
Les différentes classes acteurs étendent l’interface UntypedActor et implémentent la méthode onReceive qui permet de traiter le message. Commençons avec le « Producer » qui recevra un startMessage pour démarrer l’envoi de dix demandes d’image.
public class Producer extends UntypedActor {
public void onReceive(Object message) throws Exception {
if (message instanceof StartMessage) {
//obtient une référence vers un acteur de type Reader.
ActorRef reader = registry().actorsFor(Reader.class)[0];
for (int i = 0; i < 10; i++) {
ImageMessage imageMessage = buildImageMessage();
//transmet le message
reader.tell(imageMessage);
}
}
}
La méthode registry().actorFor permet d’obtenir tous les acteurs démarrés d’un certain type sur cette JVM. L’envoi asynchrone d’un message s’effectue par la méthode actorRef.tell(Object message). Notons qu’une méthode d’envoi synchrone existe.
Selon le même principe, la logique du « Reader » est la suivante :
byte[] imageBytes = loadImage(imageMessage.getImageNumber());
registry().actorsFor(Resizer.class)[0].tell(new ImageMessage(imageBytes, imageMessage));
Celle du « Resizer » :
byte[] resizedImage = createResizedImage(imageMessage);
registry().actorsFor(Exit.class)[0].tell(new ImageMessage(resizedImage,imageMessage));
L’ « Exit » reçoit simplement les images traitées.
Il ne reste plus qu’à instancier tous ces acteurs par la méthode Actors.actorOf, à les démarrer grâce à la méthode start(), et à envoyer un startMessage au « producer ».
public static void main(String[] args) {
init();
registry().actorsFor(Producer.class)[0].tell(new StartMessage());
}
private static void init() {
Actors.actorOf(Producer.class).start();
Actors.actorOf(Reader.class).start();
Actors.actorOf(Resizer.class).start();
Actors.actorOf(Exit.class).start();
}
Premier constat : une implémentation asynchrone est plus complexe qu’une implémentation synchrone classique. En effet, en programmation synchrone, le résultat d’une méthode appelée est systématiquement renvoyé à la méthode appelante. Ici, il appartient au développeur de préciser à qui sera transmis le résultat de la méthode asynchrone.
On voit également que cette implémentation est relativement lourde à mettre en place par rapport à un paralleleFor, ou l’utilisation de Task de TPL.
Deuxième implémentation : multi-cœurs
Revenons à notre problème initial qui consiste à répartir les traitements sur les différents cœurs disponibles.
L’augmentation du nombre de « Reader » ne sert ici à rien car le goulet d’étranglement se situe au niveau du débit du disque dur.
L’opération de réduction du « Resizer » prend quatre fois plus de temps que la lecture du fichier faite par le « Reader ». Pour augmenter la performance, on va travailler sur deux dimensions : le nombre de « Resizer » et le nombre de cœurs utilisés. Augmentons le nombre de « Resizers » et utilisons un acteur de type « LoadBalancer » pour repartir les messages selon le schéma suivant :
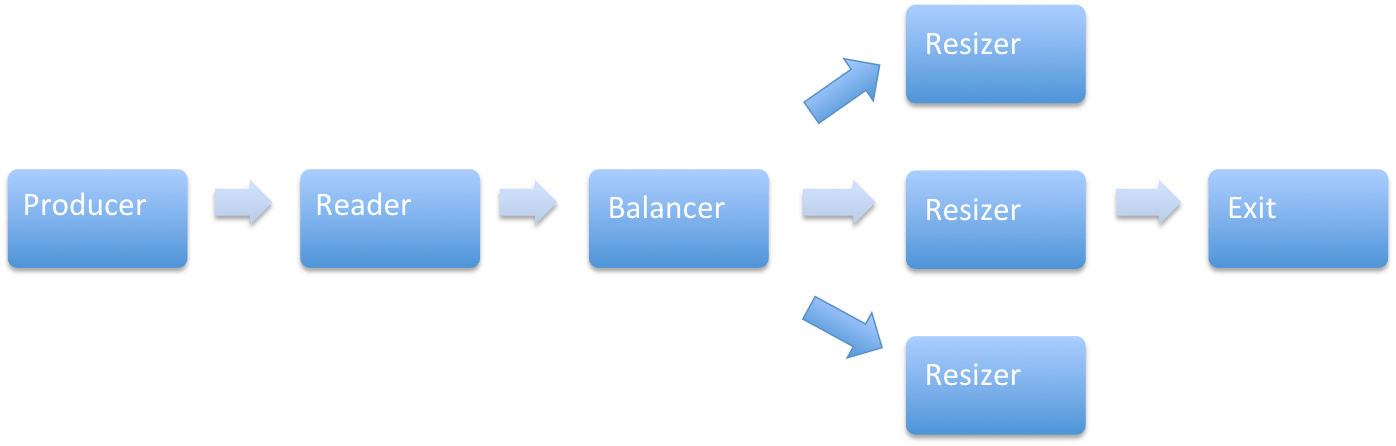
Voici le code du « Balancer » qui étend UntypedLoadBalancer et implémente seq(), méthode qui précise comment doivent être répartis les messages.
public class Balancer extends UntypedLoadBalancer {
private InfiniteIterator<ActorRef> infiniteIterator;
public InfiniteIterator<ActorRef> seq() {
if (infiniteIterator == null) {
//CyclicIterator permet au Balancer d'envoyer des messages
//équitablement répartis entre les resizers.
infiniteIterator = new CyclicIterator<ActorRef>(Arrays.asList(registry().actorsFor(Resizer.class)));
}
return infiniteIterator;
}
}
La multiplication des « Resizers » n’a pas d’intérêt s’ils se partagent le même cœur. Le paramétrage des cœurs, des threads et la liaison de ceux-ci aux acteurs s’effectue à l’aide des objets dispatcher fournit par Akka.
Ils se séparent en deux catégories principales:
- L’EventBasedDispatcher qui est basé sur un ThreadPoolExecutor . Il répartit les acteurs sur un pool de threads qui est construit automatiquement à partir du nombre de cœurs disponibles, du nombre maximal de threads autorisés, et de la configuration de la queue utilisée pour stocker les acteurs en attente. Ce dispatcher est plus adapté lorsque les acteurs ont des traitements courts à réaliser. En effet, un traitement long, ou un blocage IO, peut accaparer un thread et bloquer l’activation d’autres acteurs en attente.
- Le ThreadBasedDispatcher qui octroie un thread système par acteur. Le blocage d’un acteur ne retarde donc pas l’activation des autres acteurs.
Allouons un ThreadBasedDispatcher pour le Reader, afin que ses interruptions IO n’affectent pas les autres acteurs.
ActorRef reader = Actors.actorOf(Reader.class);
Dispatchers.newThreadBasedDispatcher(reader);
reader.start();
On notera ici que l’encapsulation de la lecture synchrone du « reader » par un objet acteur disposant de son propre thread, au sens où il n’est pas partagé avec d’autres acteurs et donc ne les bloque pas directement, la rend asynchrone pour les autres acteurs.
Finalement, allouons un EventBasedDispatcher pour les autres acteurs de la manière suivante :
MessageDispatcher messageDispatcher = configureDispatcher();
actorRef.setDispatcher(messageDispatcher);
actorRef.start();
La configuration de ce dernier permettra d’utiliser les quatre cœurs de la machine et de limiter le nombre maximum de threads à quatre. La taille de la file d’attente est choisie arbitrairement longue pour éviter les cas aux limites.
private static MessageDispatcher configureDispatcher() {
return Dispatchers.newExecutorBasedEventDrivenDispatcher("the_dispatcher")
.withNewThreadPoolWithLinkedBlockingQueueWithCapacity(1000)
.setCorePoolSize(4)
.setMaxPoolSize(4)
.build();
}
On voit ici que l’API propose un réglage fin permettant d’adapter la configuration au matériel et au problème posé. Notons également que la configuration par défaut place tous les acteurs sur un EventBasedDispatcher configuré pour utiliser tous les cœurs de la machine. Notre première implémentation était donc déjà multi-cœurs.
On comprend alors que les acteurs fournissent un cadre qui simplifie les problèmes de concurrence à traiter par le développeur. Ces problèmes qui deviennent rapidement complexes, voir l’article de Sofian Djamaa, sont ici en parti contournés par l’utilisation de messages immuables et par le non partage d’état entre les acteurs (les états des acteurs seront présentés ultérieurement).
« Let It Crash »
Un des points importants de la programmation orientée acteurs introduit par Ericson est sa tolérance à l’erreur. Cette faculté est assurée par un acteur particulier de type Superviseur. Celui-ci surveille le bon fonctionnement d’autres acteurs. En Java, il attrape les exceptions levées par les acteurs surveillés et peut les redémarrer suivant une des stratégies suivantes :
one for one : seul l’acteur levant une exception est redémarré. one for all : tous les acteurs supervisés sont redémarrés, cette stratégie est utilisée dans le cas de dépendance entre acteurs.
Par exemple, redémarrons notre « reader » lorsque celui-ci lève une exception IO :
public static Supervisor buildSupervisor() {
OneForOneStrategy oneForOneStrategy = new OneForOneStrategy(
//type d'exception prises en charge
new Class[]{IOException.class},
//nombre maximum de d'essai de redemarrage
100,
// temps maximum pour le redemarrage
5000
);
//creation de la strategie de supervision,
//aucun acteur à superviser initialement
SupervisorConfig supervisorConfig = new SupervisorConfig(oneForOneStrategy, new Supervise[0]);
Supervisor supervisor = Supervisor.apply(supervisorConfig);
return supervisor;
}
…
Supervisor supervisor = buildSupervisor();
//on applique le superviseur au reader
supervisor.link(reader);
L’utilisation des superviseurs peut aller beaucoup plus loin. Ainsi les superviseurs peuvent surveiller d’autres superviseurs ou démarrer eux-mêmes les acteurs qu’ils supervisent. On peut alors aboutir à un arbre de supervision qui permet de gérer l’application selon différents blocs fonctionnels comme le montre le schéma suivant :
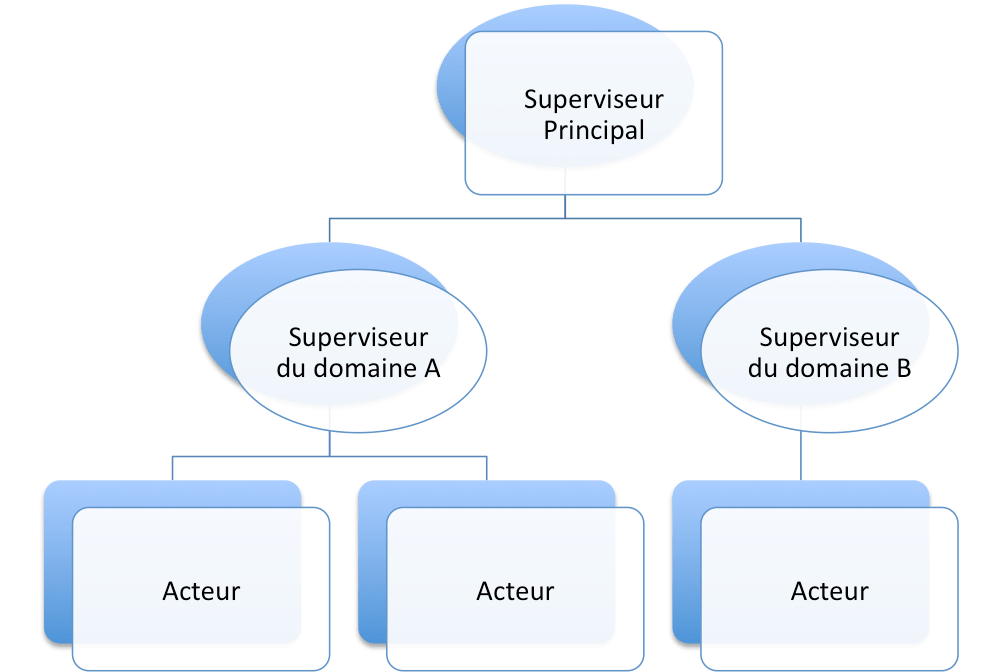
3. Implémentation multi-machines
Troisième implémentation : multi-noeuds.
Maintenant que le programme occupe tous les cœurs de la machine, distribuons le sur plusieurs machines. Le « producer » et « l’exit » seront placés sur une machine maitre, tandis que chaque machine esclave contiendra un « reader » et des « resizers ».
Schématiquement :
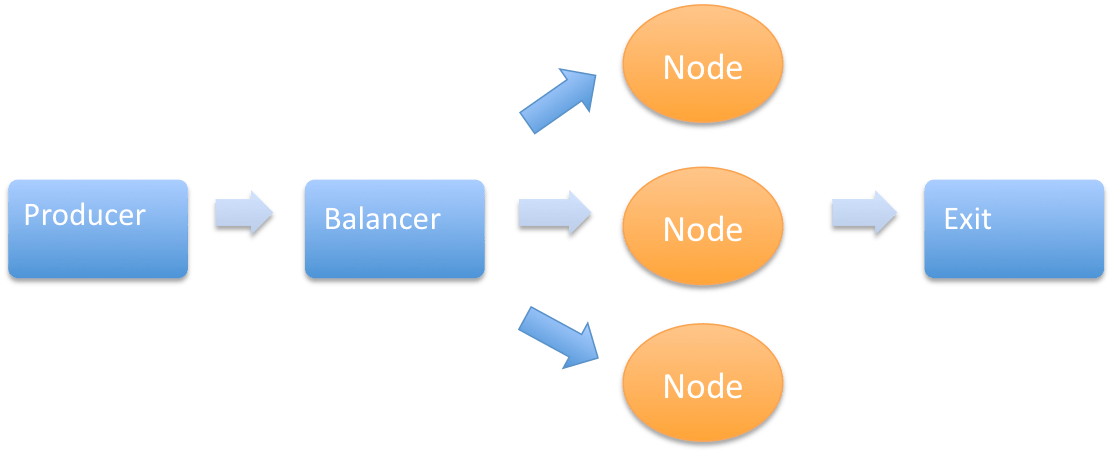
Techniquement, la sérialisation des messages est réalisée par Google Protocol Buffer et la partie réseau est assurée par JBoss Netty.
Du point de vue du développeur, la différence entre adresser des messages sur une même machine, et adresser des messages sur une machine distante réside dans la façon d’obtenir la référence vers l’acteur auquel on souhaite envoyer le message (Akka version 1.2).
Celui-ci doit être déclaré accessible depuis l’extérieur :
remote().start("localhost", 2552).register("reader-service", reader);
La référence est ensuite disponible sur les autres machines par la méthode remote().actorFor :
remote().actorFor("reader-service", "192.168.1.5", 2552);
On voit dans le cadre de cet exemple qu’une fois la complexité absorbée pour une utilisation mono machine, la distribution des calculs sur différents nœuds est relativement simple.
Dernière implémentation : utilisation de l’état interne d’un acteur.
Finalement, utilisons l’état interne d’un acteur pour gérer l’absence de fichier dans un nœud. Si un « reader » ne trouve pas l’image i, il le signale au « balancer ». Le « balancer » mémorise cette information et renvoie la demande de l’image i aux nœuds qui, a priori, ont l’image.
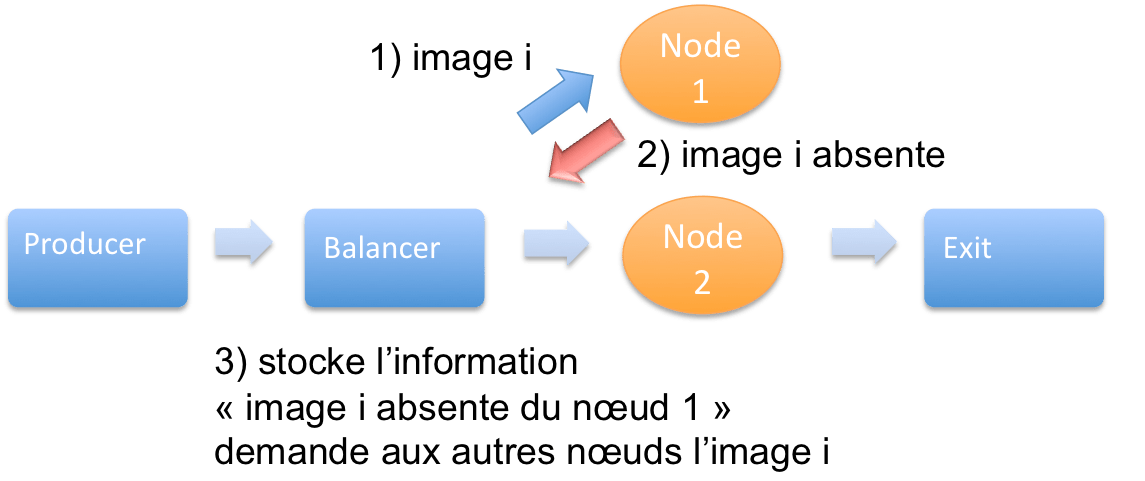
Ce cas d’utilisation met en avant le fait que la communication entre acteurs n’est pas unidirectionnelle. On voit également que l’utilisation d’états internes est utile pour changer dynamiquement le comportement de l’application. Attention néanmoins à l’augmentation de la complexité induite par ce changement.
Conclusion
La programmation orientée acteurs apporte des réponses aux problématiques de parallélisation et de distribution de calculs. Par le biais des superviseurs, elle propose un moyen de gérer les incidents. Les états internes permettent de « dynamiser » l’application au sens où le comportement peut changer au cours du temps (exemple de l’image absente d’un nœud). Et finalement, le système de dispatcher permet une gestion fine des ressources (cœur/ thread) utilisées.
Néanmoins le choix de ce paradigme s’avère plus lourd à mettre en place que la librairie TPL dans le cadre d'une implémentation mono-machine par exemple, et s’accompagne d’une augmentation de la complexité : coder en asynchrone n’est pas standard et l’utilisation d’états internes amène des difficultés supplémentaires.
Bruno Boucard au TechDays compare la programmation orientée acteurs avec d’autres solutions de parallélisation et de distribution en fonction du type d’algorithmes à implémenter. Il montre que les programmes composés de plusieurs étapes chainées et parallélisables (ici l’implémentation sans images manquantes), ou des programmes dont le traitement est irrégulié (ici l’exemple de l’image manquante) bénéficient le plus de ce type de programmation.