Introduction à CoreML

Avant de rentrer dans l’analyse de CoreML, cette article propose une introduction au Machine Learning puis la réalisation d’un projet de bout en bout avec CoreML.
I.Introduction au Machine Learning
On assiste depuis quelques années à une accélération de l’utilisation des techniques de Machine Learning dans des domaines variés avec un impact grandissant sur l’expérience utilisateur. Pourtant les principaux algorithmes utilisés ont plusieurs décennies d’existence, c’est l’augmentation des capacités de calculs des ordinateurs et de stockage qui rend possible aujourd’hui cette démocratisation du Machine Learning.
Machine Learning algorithms MindMap
Le Machine Learning est un sous-ensemble de l’Intelligence Artificielle dont le but est de permettre à des ordinateurs d’apprendre par eux-mêmes. Un algorithme de Machine Learning permet d’identifier un pattern à partir de données et de construire un modèle décrivant leurs comportements, afin d’être capable de faire des prédictions sans en avoir explicitement programmé les règles.
On distingue 2 grandes familles de Machine learning : supervisé et non supervisé.
I.1 Machine Learning supervisé
Lorsqu’on utilise du ML supervisé, les données en entrée sont associées à des libellés. Par exemple, lorsque l’on va vouloir utiliser du Machine Learning pour réaliser de la reconnaissance d’images, on va utiliser des milliers d’images associées avec leurs catégories (ou ce qu’elles représentent). L’algorithme va alors apprendre la relation entre ces images et ce qu’elles représentent. Par la suite, cette relation sera utilisée pour catégoriser de nouvelles images. Un autre exemple : la prédiction de l’évolution du prix au m² dans une ville ou un quartier en fonction de données sociales, démographiques, politiques, ...
On distingue 2 usages pour le ML supervisé : la régression et la classification.
La régression consiste à estimer une variable continue (c’est-à-dire qu’il n’y a pas de discontinuité dans la valeur que la variable peut prendre) à partir de données d’entrée. C’est le cas de la prédiction de l’évolution du prix au m².
A l’inverse, les algorithmes de classification permettent de prédire une valeur discrète : associer un libellé à une donnée parmi une liste finie de possibilités.
I.2 Machine Learning non supervisé
A l’inverse du Machine Learning supervisé, dans le cas du ML non supervisé, les données en entrée ne sont pas libellées. L’objectif d’un tel algorithme est de structurer de nouvelles données en entrée à partir d’un jeu de données sans label.
Un des exemples d’utilisation du ML non supervisé est la recommandation de produits que l’on retrouve sur Amazon ou de vidéos similaires sur Youtube ou encore Netflix. Ces usages utilisent les algorithmes de “Clustering” dont l’objectif est de regrouper les données en groupes homogènes (appelés clusters).
I.3 Utilisation du ML supervisé
Lorsque l’on dispose de données que l’on souhaite utiliser avec un algorithme ML supervisé, une première étape consiste à déterminer les features à utiliser.
Une feature est un attribut de la donnée, elle peut être numérique (ex : Revenu annuel d’un individu) ou catégorielle (ex : Métier). Sa détermination est une étape indispensable pour :
- Simplifier le modèle obtenu et faciliter son interprétation par ses utilisateurs
- Réduire le temps de construction du modèle
- Eviter les phénomènes liées à un nombre de dimensions de données important (Curse of dimensionality) qui ont un impact sur les performances de l’algorithme
- Eviter les phénomènes de overfitting (Sur-apprentissage), entraînant une trop grande liberté dans le choix du modèle
Le ML supervisé se réalise en plusieurs étapes :
- Entrainement du modèle (Training)
- Test du modèle
- Utilisation du modèle pour la prédiction
Avant de construire le modèle, on divise les données d’entrée en deux parties : une première pour entraîner l’algorithme utilisé et une deuxième pour tester celui-ci.
Les données d’apprentissage ont une valeur connue pour la variable à estimer et sont utilisées en entrée d’un algorithme ML (dépendant du besoin) : c’est la construction (l’entrainement) du modèle.
Puis on vérifie ses performances, en l’utilisant avec la deuxième partie des données. Les valeurs ainsi obtenues seront comparées aux valeurs réelles, connues pour valider la performance du modèle.
Enfin, une fois le modèle construit, on l’utilisera sur de nouvelles données dont on ne connaît pas la valeur de la variable à estimer. On pourra également améliorer ce modèle, notamment en réitérant l’étape de construction en intégrant de nouvelles données.
II.Machine Learning avec CoreML
L’intégration de CoreML se fait en 2 étapes :
- Construction du modèle, hors de l’application
- Utilisation du modèle avec le framework CoreML, dans l’application
II.1 Librairie coremltools
Le Framework CoreML prend un charge un format spécifique, créé pour l’occasion par Apple. Afin d’exporter des modèles dans ce format, Apple fournit une librairie permettant de convertir un modèle existant vers le format CoreML : coremltools.
coremltools est une librairie Python s’utilisant avec différentes librairies de machine learning :
- caffe (Deep Learning)
- keras (Réseaux de neurones)
- libsvm (Classification)
- sklearn (Multiples algorithmes de Machine Learning)
CoreML ne supporte cependant pas tous les algorithmes intégrés dans ces librairies, il supporte uniquement les algorithmes de Machine Learning supervisés.
Pour obtenir un modèle à intégrer dans une application iOS, il faudra donc dans un premier temps passer par une de ces librairies pour créer un modèle puis l’exporter avec coremltools. On obtiendra alors un fichier (avec par convention une extension mlmodel) que l’on pourra importer dans un projet Xcode.
De la même manière qu’avec un modèle appris en Python, le modèle CoreML dispose d’une méthode predict qui prend en entrée une donnée sous une certaine structure, et qui ressort une prédiction sous une autre structure. Ces structures sont notamment visibles par l’intermédiaire des classes générées par Xcode.
A noter qu’il existe d’autres outils, non mis à disposition par Apple, permettant de convertir d'autres modèles vers CoreML. C'est le cas notamment pour ceux issus de TensorFlow.
II.2 Framework CoreML
Le Framework CoreML permet à partir d’un modèle (fichier mlmodel) de réaliser des prédictions dans une application iOS.
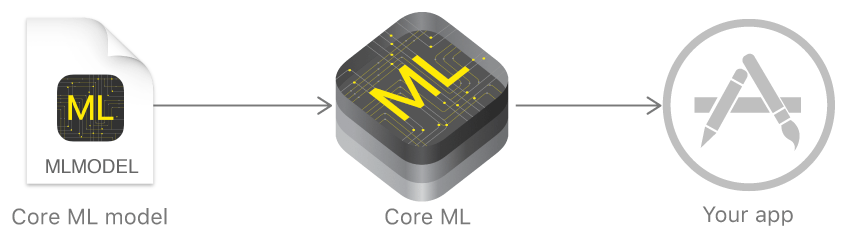
L’utilisation de CoreML ne nécessite pas de configuration particulière lors de la création du projet. Pour l’utiliser, il suffit d’importer un fichier mlmodel dans son projet (A noter que l’on peut en ajouter plusieurs dans un même projet pour utiliser plusieurs modèles).
Après l’import du modèle, Xcode va générer 3 classes Swift :
- Une classe représentant le modèle CoreML (Pour un modèle MonModel.mlmodel, la classe se nommera MonModel). Cette classe permettra d’initialiser le modèle pour être utilisé dans l’application et propose des méthodes permettant de réaliser des prédictions.
- Une classe représentant les entrées du modèle implémentant le protocol MLFeatureProvider correspondant à une collection de valeurs de features (Pour un modèle MonModel.mlmodel, la classe se nommera MonModelInput)
- Une classe représentant les sorties du modèles implémentant le protocol MLFeatureProvider (Pour un modèle MonModel.mlmodel, la classe se nommera MonModelOutput)
Afin de tester l’intégration de CoreML dans une application, nous allons poursuivre en utilisant un use case simple : la prédiction du succès d’une campagne KickStarter. Dans la suite de cet article, un modèle de prédiction sera construit, à partir d’un dataset contenant des données de campagnes passées, et l’utiliser dans une application iOS avec CoreML.
III.Construction du modèle avec Python et coremltools
Pour la construction du modèle ML, nous disposons d’un ensemble de données concernant des campagnes KickStarter passées (~110 000 campagnes, issues de la plateforme Kaggle). Ces données comprennent les caractéristiques de chaque projet KickStarter tel que le but à atteindre, la date de démarrage, la deadline etc. mais aussi le statut final de la campagne (si l’objectif de contribution a été atteint ou pas).
Nous utiliserons comme features, la durée du projet KickStarter, le nombre de contributeur ainsi que le but à atteindre.
Le modèle sera construit à partir de la librairie sklearn, librairie python dédié au machine learning.
NB : Avant de pouvoir utiliser cette librairie dans un script python, il faut l’installer sur son poste de développement
pip install -U scikit-learn
La première étape de la construction du modèle est de déterminer l’algorithme à utiliser.
III.1 Déterminer l’algorithme à utiliser
Nous avons des données en entrée (caractéristiques des projets KickStarter) que l’on associe à un libellé (Succès du projet) : il s’agit de ML supervisé. Le libellé que l’on cherche à prédire a une valeur discrète : nous allons utiliser un algorithme de classification.

Sklearn algorithm flowchart - Source : http://scikit-learn.org/stable/tutorial/machine_learning_map/index.html
Nous allons maintenant tester plusieurs algorithmes de classification afin de déterminer celui qui fournit les meilleurs résultats. Pour cela, pour chaque algorithme de cette famille, nous allons construire le modèle puis mesurer sa performance.
Import des données:
En chargeant les données depuis notre dataset CSV, on obtient alors un Dataframe que l’on va manipuler pour ajouter la feature calculée duration et supprimer les colonnes inutiles.
#Lecture des donnees depuis le dataset CSV dataframe = pandas.read_csv('../data/kickstarter.csv') #On calcule la duree du projet KickStarter pour chaque ligne dataframe['duration'] = dataframe['deadline'] - dataframe['launched_at'] #On supprime les colonnes inutiles dataframe = dataframe.drop(['project_id', 'name', 'desc', 'keywords', 'country','currency', 'disable_communication', 'deadline', 'launched_at', 'state_changed_at','created_at'], axis=1) #Creation d'une matrice de features X = numpy.array(dataframe.drop(['final_status'],1)) #Creation d'une matrice de libelle final y = numpy.array(dataframe['final_status'])
Comparaison des algorithmes
Pour chaque algorithme, nous utilisons une technique de cross-validation K-Fold pour obtenir un score et ainsi déterminer le meilleur algorithme à utiliser. Cette technique permet de ne pas “gaspiller” une partie des données du dataset pour construire un dataset de tests. En effet, la technique k-Fold consiste à découper les données en k parties et à mesurer le score de l’algorithme k fois en utilisant les k-1 parties des données pour construire le modèle et à le tester avec les données restantes. 
K-Fold Cross validation
models = [] models.append(('LR', LogisticRegression())) models.append(('LDA', LinearDiscriminantAnalysis())) models.append(('KNC', KNeighborsClassifier())) models.append(('DTC', DecisionTreeClassifier())) models.append(('NB', GaussianNB()))
results = [] names = [] for name, model in models: #Selection des indices pour la cross validation kfold = model_selection.KFold(n_splits=10, random_state=7) #Calcul des scores cross_val_results = model_selection.cross_val_score(model, X, y, cv=kfold, scoring=’neg_log_loss’) results.append(cross_val_results) names.append(name)
Le score déterminé par cross-validation correspond à la moyenne des k scores obtenues qui correspond elle-même au score calculé par chaque algorithme. Lorsqu’on utilise la métrique log_loss, plus le score est proche de 0 meilleur est l’algorithme.
Le graphe ci-dessous montre le résultat de la comparaison des 5 algorithmes (pour chaque algorithme, le score est compris dans l’écart-type obtenu par la cross-validation) :
L’algorithme obtenant les meilleurs résultats pour notre use case est le LogisticRegression, c’est donc celui-ci sera utilisé pour construire le modèle CoreML.
A noter qu'on ne cherche pas ici à optimiser ici les paramètres de l’algorithme retenu (ce qui permettrait d’en améliorer les performances).
Par ailleurs, nous ignorons ici volontairement un risque lié à la cross-validation : dans le cas où le temps est une variable importante pour le modèle alors il y a un risque d'introduire une leak temporelle qui aurait pour impact d'obtenir des résultats trop optimistes lors du choix du modèle.
III.2 Construction du modèle
Nous allons maintenant écrire un script permettant la création du modèle et son export CoreML.
L’étape d’import de données est la même que dans le script précédent.
Initialisation et entrainement du modèle
On initialise le modèle et on l’entraine avec les données d’entrées : les 3 features (durée, objectif et nombre de contributeurs) et les données de sortie : succès de la campagne.
A noter que notre modèle a déjà été testé dans l’étape précédente (cross-validation), on utilisera donc l’intégralité des données sans réserver une partie pour le tester.
#Initialisation de l'algorithme logisticRegression = LogisticRegression() #Entrainement du modele a partir des donnees logisticRegression.fit(X, y)
Conversion du modèle vers CoreML
A présent, nous allons convertir le modèle entrainé au format CoreML. La librairie coremltools permet cette conversion ainsi que le renseignement d’informations sur les entrées - sorties du modèle qui seront utilisables dans le projet Xcode.
#Conversion du modele au format CoreML coreml_model = coremltools.converters.sklearn.convert(logisticRegression, ['goal', 'backersCount', 'duration'], ['prediction', 'precision']) coreml_model.author = 'OCTO Technology' coreml_model.license = 'Unknown' coreml_model.short_description = 'KickStarter success prediction using LogisticRegression' coreml_model.input_description['goal'] = 'Goal of the project.' coreml_model.input_description['backersCount'] = 'Contributors count for the project.' coreml_model.input_description['duration'] = 'Duration of the project.' coreml_model.output_description['prediction'] = 'Prediction of the success for the project' #Sauvegarde du fichier mlmodel coreml_model.save('KickStarterMLModel.mlmodel')
Le fichier KickStarterMLModel.mlmodel ainsi obtenu pourra être utilisé dans un projet iOS pour utilisation du modèle.
IV.Utilisation du modèle CoreML dans iOS
Un projet iOS utilisant CoreML ne nécessite pas de configuration particulière, si ce n’est que de cibler iOS 11 ou plus.
L’application iOS pour illustrer cet article est relativement simple : elle contient un écran qui liste les campagnes KickStarter avec pour chaque campagne, son nom ainsi que quelques informations relatives à celle-ci. La couleur de l’arrière plan de chaque cellule changera en fonction de la prédiction du succès : rouge si un échec est prédit, vert dans le cas contraire.
IV.1 Import du modèle
Une fois le projet créé et la récupération de la liste des projets KickStarter réalisée (sans prédiction pour le moment), nous importons le fichier KickStarterMLModel.mlmodel dans Xcode, comme n’importe quelle ressource.
En sélectionnant le fichier importé, on accède aux détails du modèle (on retrouve les informations ajoutées lors de la conversion du modèle avec coremltools). On peut également accéder à la définition des classes générées par Xcode lors de l’import du fichier mlmodel dans le projet.
Détails du modèle CoreML importé dans le projet
Xcode a généré les 3 classes représentant :
- les entrées du modèle :
class KickStarterMLModelInput : MLFeatureProvider { /// Goal of the project. as double value var goal: Double /// Contributors count for the project. as double value var backersCount: Double /// Duration of the project. as double value var duration: Double var featureNames: Set { get { return ["goal", "backersCount", "duration"] } }
func featureValue(for featureName: String) -> MLFeatureValue? { if (featureName == "goal") { return MLFeatureValue(double: goal) } if (featureName == "backersCount") { return MLFeatureValue(double: backersCount) } if (featureName == "duration") { return MLFeatureValue(double: duration) } return nil } init(goal: Double, backersCount: Double, duration: Double) { self.goal = goal self.backersCount = backersCount self.duration = duration } }
- les sorties du modèle :
class KickStarterMLModelOutput : MLFeatureProvider { /// Prediction of the success for the project as integer value let prediction: Int64 /// precision as dictionary of 64-bit integers to doubles let precision: [Int64 : Double] var featureNames: Set { get { return ["prediction", "precision"] } }
func featureValue(for featureName: String) -> MLFeatureValue? { if (featureName == "prediction") { return MLFeatureValue(int64: prediction) } if (featureName == "precision") { return try! MLFeatureValue(dictionary: precision as [NSObject : NSNumber]) } return nil }
init(prediction: Int64, precision: [Int64 : Double]) { self.prediction = prediction self.precision = precision } }
- le modèle permettant de réaliser les prédictions :
class KickStarterMLModel { var model: MLModel
init(contentsOf url: URL) throws { self.model = try MLModel(contentsOf: url) }
convenience init() { let bundle = Bundle(for: KickStarterMLModel.self) let assetPath = bundle.url(forResource: "KickStarterMLModel", withExtension:"mlmodelc") try! self.init(contentsOf: assetPath!) }
func prediction(input: KickStarterMLModelInput) throws -> KickStarterMLModelOutput { let outFeatures = try model.prediction(from: input) let result = KickStarterMLModelOutput(prediction: outFeatures.featureValue(for: "prediction")!.int64Value, precision: outFeatures.featureValue(for: "precision")!.dictionaryValue as! [Int64 : Double]) return result }
func prediction(goal: Double, backersCount: Double, duration: Double) throws -> KickStarterMLModelOutput { let input_ = KickStarterMLModelInput(goal: goal, backersCount: backersCount, duration: duration) return try self.prediction(input: input_) } }
IV.2 Prédiction
On créé une classe qui représente un projet KickStarter, au delà des attributs du projet (nom, objectif, etc), elle possède un attribut predictedSuccess qui sera mis à jour via notre modèle CoreML.
var identifier: Int! var name: String! …. var predictedSuccess: Bool?
La mise à jour s’effectuera par l’intermédiaire d’une méthode predictSuccess qui prend en paramètre le modèle CoreML (pour des raisons de performance, le modèle n’est chargé qu’une seul fois dans l’application).
func predictSuccess(model: KickStarterMLModel) { //Predict success using the CoreML model let prediction = try? model.prediction(goal: goal, backersCount: Double(backersCount), duration: duration) //Save result in predictedSuccess attribute if let success = prediction?.prediction { predictedSuccess = success == 1 } }
L’API de KickStarter nous permet d’obtenir la liste des projets par page de 10. Pour chaque appel à l’API (qui se fait au fur et à mesure du scroll de l’utilisateur dans la liste des projets), on met à jour la prédiction du succès de la campagne. Afin de ne pas bloquer l’UI, la prédiction via CoreML s'effectue en background.
private func loadProjects() { self.isLoadingProjects = true kickStartProjectsRepository.getNextProjects() { result in self.isLoadingProjects = false self.tableView.reloadData() } }
func getNextProjects(completionHandler: @escaping (Result<[KickStarterProject]?>) -> Void) { let page = (lastResponse?.page ?? 0)+1 let url = "https://www.kickstarter.com/projects/search.json?page=\(page)" Alamofire.request(url).responseObject { (response: DataResponse) in ... self.lastResponse = response.result.value let newProjects = self.lastResponse?.projects newProjects?.forEach { self.projects.append($0) } //Predict success for each projects in background DispatchQueue.global(qos: .background).async { newProjects?.forEach { $0.predictSuccess(model: self.mlModel) } DispatchQueue.main.async { //Call Handler in main queue completionHandler(Result.success(newProjects)) } } } }
Rendu final de l’application
IV.3 Quelques observations
Temps de prédiction :
La prédiction du succès d’une campagne prend entre 3 et 10 ms sur nos tests sur iPhone 7. Un temps relativement faible mais qu’il ne faut pas généraliser. En effet le temps de prédiction dépendra d’une multitude de facteur : nombre d’entrées, type de données à prédire, algorithme utilisé, taille du dataset initial, …
Difficile donc de prédire l’impact de l’utilisation importante de CoreML sur la batterie car cela dépend du modèle. On peut bien sûr imaginer que l’impact sera négligeable dans notre cas d’utilisation relativement simple mais plus important sur des uses cases de reconnaissance d’image par exemple.
Taille du modèle :
Le fichier .mlmodel ajouté au projet pèse 500Ko, taille assez faible mais qui dépend également du type de modèle. On trouve par exemple sur le site https://coreml.store (mettant à disposition des modèles CoreML prêts à être intégrés dans des applications), des modèles de plusieurs dizaines de Mo.
Mise à jour du modèle :
On a vu que Xcode génère les classes permettant l’utilisation du modèle lors de l’import de celui-ci dans le projet, on pourrait croire que cela rend impossible la mise à jour du modèle sans passer par une mise à jour de l’Application. Ce n’est pas tout à fait exacte.
En regardant l’initialisation du modèle KickStarterMLModel, on voit qu’il dispose d’une méthode init prenant en paramètre une URL, on dispose donc d’un point d’entrée pour initialiser un objet KickStarterMLModel avec un autre fichier.
Cependant l'initialisation n’attend pas l’URL vers un fichier .mlmodel mais vers un fichier .mlmodelc qui est un format interne (compilé) à CoreML utilisé par le framework.
En effet, lorsque l’on importe un fichier .mlmodel, Xcode le compile, créant ainsi un fichier .mlmodelc et génère les classes pour l’utiliser.
Apple fournit également une méthode permettant la compilation du modèle durant l'exécution d’une application_._ On pourra donc mettre à jour le modèle via cette méthode après avoir téléchargé un fichier .mlmodel à jour.
let compiledUrl = try MLModel.compileModel(at: modelUrl) let model = try MLModel(contentsOf: compiledUrl)
La seule limitation, qui peut être bloquante selon les usages, est que l’interface du modèle (entrées, sorties) ne peut pas changer. En effet, la compilation au sein de l’application va créer un nouveau fichier .mlmodelc mais les classes permettant l’utilisation du modèle (générées par Xcode lors de son import) resteront les mêmes. Lorsque l’on souhaitera mettre à jour son modèle en ajoutant des variables, il faudra donc passer par une mise à jour de l’application.
Conclusion
L’intégration du Machine Learning par Apple sur iOS est intéressante : elle repose sur des solutions open-source éprouvés par la communauté Data Science.
L’effort d’intégration, une fois le modèle construit, est quasiment négligeable.
L’arrivée de solutions mobiles de Machine Learning (CoreML, TensorFlow, etc.) provoque un intérêt certain dans la communauté, mais quels sont les uses cases pour les utilisateurs finaux de nos applications ?
Parmi les uses cases mis en avant par Apple, on retrouve ceux liés aux traitements automatiques du langage et traitement d’images : face tracking, détection de visages, paysages, détection de texte dans une image, détection de forme, scan de code barre, object tracking, etc.
Ces usages sont intéressants techniquement mais il est difficile d’en déduire de nouvelles fonctionnalités dans les applications les plus utilisées.
Le réel gain pour l’utilisateur final se situe au niveau de l’amélioration de l’expérience utilisateur. Le machine learning réalisé localement va permettre de lui fournir des applications plus intelligentes : gain de temps, propositions pertinentes, prédiction de comportement, aide à la navigation, ...
On peut se demander de l’intérêt de passer par une solution locale plutôt qu’une solution côté Serveur/API. Mon point de vue est que cela dépend des uses cases.
Lorsque qu’on peut techniquement intégrer du ML localement et que cela présente un intérêt pour l’expérience utilisateur, c’est forcément positif.
Rien n’empêche d’avoir une solution serveur et une solution plus souple côté mobile pour le même usage, uniquement pour améliorer l’expérience. Prenons l’exemple d’un formulaire de souscription dans lequel l’utilisateur doit uploader un document d’un certain type, on pourra utiliser sur mobile un modèle ML pour vérifier la validité du document mais également disposer d’une solution côté API effectuant cette vérification afin de sécuriser la souscription via l’API.
Il y a d’autres uses cases où l’intégration est forcément côté mobile : la détection de numéros de carte bancaire à partir de la caméra pour pré-remplir un champ dans un parcours d’achat.
Et d’autres sont forcément côté serveur/API : un algorithme de recommandation de contenus basés sur la consommation des autres utilisateurs pourrait difficilement être intégré localement.
La réponse à la question “doit-on intégrer du ML côté API ou côté mobile” passera donc entre autres par une interrogation sur l’expérience utilisateur.
Le code source du projet est disponible ici : https://github.com/gdesmaziers/KickStarterPrediction.