Intégration continue performante (Part #2)
Dans la première partie de ce billet, je mentionnais divers solutions (bonnes pratiques, outils) pour optimiser les performances du serveur d'intégration continue et faire face au nombre croissant de projets gérés par ce serveur.
Dans cette seconde partie, j'aborde un sujet récurrent lorsque l'on fait de l'intégration continue : les erreurs (compilation, tests, packaging) sur le serveur. Effectivement, mieux vaut découvrir ces erreurs en continue sur le serveur plutôt que la veille de la livraison. Mais, ne serait-ce pas mieux si on pouvait simplement les éviter ?
Unbreakable Build
La bonne pratique veut que l'on mette à jour le code en local et que l'on lance une compilation et les tests avant de commiter un fichier. Mais les bonnes pratiques ne sont pas toujours appliquées (manque de temps, oubli, manque d'expérience...). Par conséquent, il arrive que le code versionné ne compile pas ou ne passe plus les tests. On dit alors qu'il casse le build, qu'il empêche l'intégration continue de construire l'application. Et accessoirement, les autres développeurs sont également bloqués s'ils récupèrent ce code.
Mais alors comment ne pas casser le build ? Ou plus simplement, comment éviter de commiter du code qui ne fonctionne pas et ainsi avoir une application fonctionnelle livrable à chaque instant ? Respecter les bonnes pratiques ? Si c'était possible, je ne parlerai pas ici des "unbreakable builds" ou du "build check before commit", ou encore du "personal build"...
Des noms barbares pour dire qu'il faut effectuer l'intégration du code (merge, compilation, tests) au plus tôt : avant l'intégration continue et avant même de le commiter.
C'est ce que proposent certains outils comme TeamCity de JetBrains, Gauntlet de Borland, Pulse de zutubi :
Gauntlet est limité aux gestionnaires de sources (SCM) CVS, SVN et Starteam. Il propose le mécanisme de sandbox, à savoir une branche privée du SCM pour chaque développeur. Les commits se font dans cet espace tampon, où se déroule un build (compilation, tests... ce que vous voulez) et si tout se passe bien, le code est promu automatiquement sur la branche principale et sur toutes les sandbox. Si par contre, il y a un problème, le fichier est locké le temps que les corrections soient apportées. Attention, il ne gère que Ant, Maven n'est mentionné nulle part !
Pulse gère CVS, SVN et perforce. Son fonctionnement est légèrement différent : Le développeur soumet via une ligne de commande un personal build au serveur pulse. Techniquement, la commande fait un update du code en local, analyse les différences et soumet un patch au serveur. Le serveur utilise le code courant du SCM (dans un espace temporaire) auquel il ajoute le patch puis exécute un build. On choisit ensuite de commiter ou non le code en fonction du résultat du build.
Enfin, TeamCity m'a semblé plus complet, de par la gestion de multiples SCM ainsi que pour son intégration aux principaux environnements de développements (IDE). Malheureusement, le build personnel ne fonctionne pas avec tous les SCM sur tous les IDE et pas moyen de faire autrement que de passer par l'IDE : sur Eclipse, seul SVN est géré; IntelliJ est mieux servi avec Subversion, Perforce, CVS, Visual SourceSafe, ClearCase, StarTeam et enfin Visual Studio fonctionne avec TFS et SVN. Le fonctionnement est assez semblable à pulse.
On s'écarte quelque peu de l'intégration continue à proprement parler mais certains SCM tentent également d'apporter une solution pour disposer constamment d'un code qui compile :
Rational Clearcase UCM fournit un mécanisme de vues : chaque développeur code sur une vue (sorte de branche) qui lui est propre. Il peut commiter toutes les erreurs qu'il veut, ce code ne concerne que lui. Pratique pour ne pas déranger les autres pendant le développement. Mais au moment d'intégrer son code à la baseline (branche) principale, c'est une autre histoire, l'intégration continue étant généralement branché sur cette baseline.
Git et Mercurial, pour les plus connus, sont des gestionnaires de sources distribués, qui permettent de faire une copie du référentiel (équivalent au checkout en svn) et continuer à travailler sur une sorte de branche personnelle avant de merger avec le référentiel parent. On peut donc imaginer le schéma suivant :
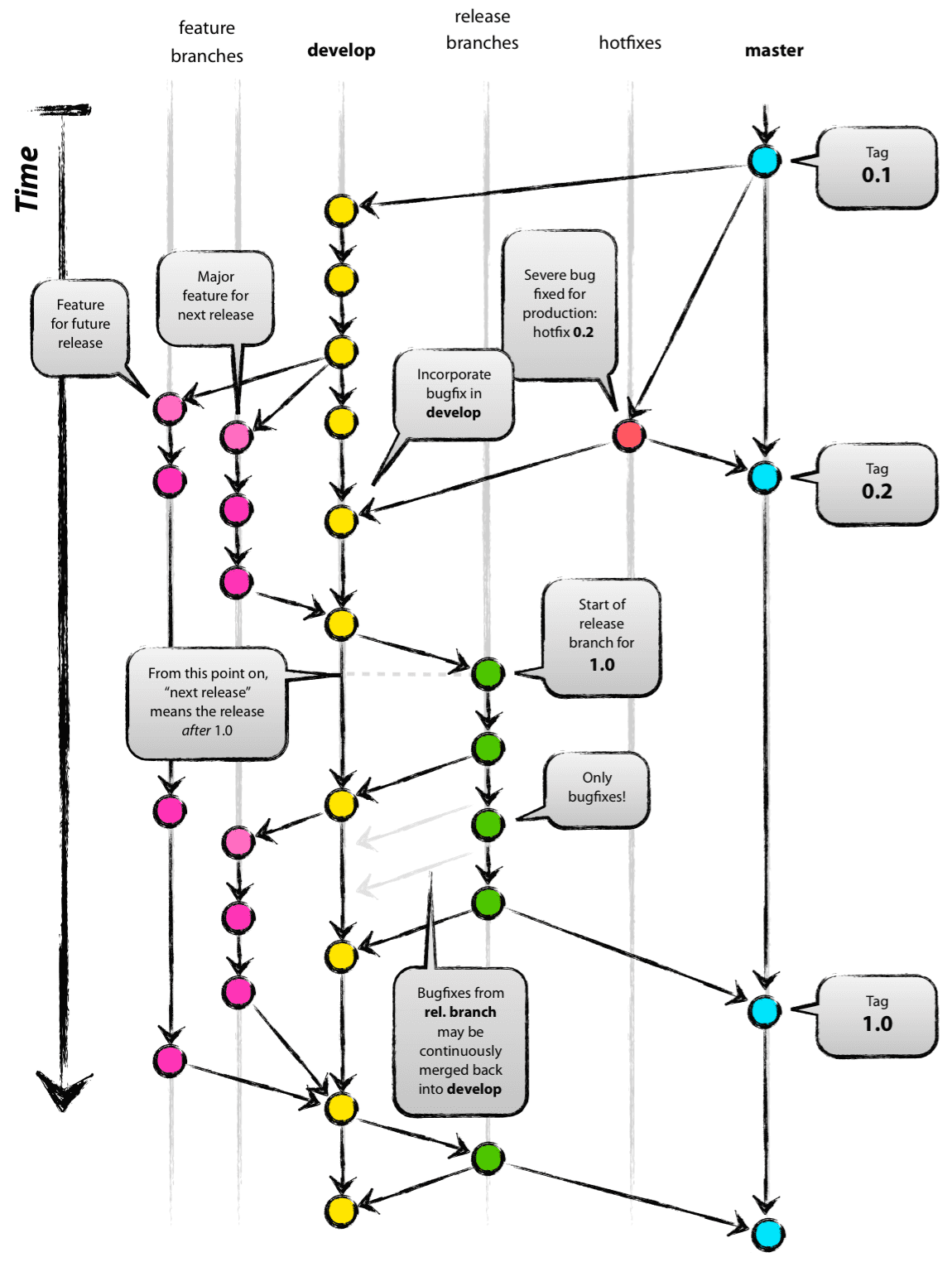
Même si les builds peuvent échouer sur l'intégration continue, le code dans le référentiel principal est censé compiler (éprouvé par l'usine de développement) et donc permettre de disposer d'une version opérationnelle de l'application.
Il n'existe pas aujourd'hui de solution miracle (gestion de tous les SCM ou SCM lui même adapté pour ce genre de choses) mais si c'est une volonté forte de conserver un gestionnaire de source "propre", mieux vaut disposer du bon outil au départ (SVN par exemple semble bien intégré à la plupart des serveurs d'intégration continue que nous venons de voir).
Dans la 3ème et dernière partie, je traiterai un sujet moins technique : l'industrialisation de cette pratique et comment l'exploiter pleinement depuis le développement jusqu'au déploiement.