Intégration continue performante (Part #1)
Alors que l'intégration continue fait son bonhomme de chemin dans les développements en entreprise, plusieurs constats peuvent être fait.
La généralisation de cette pratique n'est pas égale chez tout le monde :
Chez certains, des usines de développement (plus communément appelées Software Factory) fleurissent par ci par là sous l'impulsion de développeurs chevronnés ou d'expert techniques mais se cantonnent la plupart du temps au développement d'un projet. Résultat : pas d'uniformisation (utilisation d'outils redondants, de méthodologies variées...) mais les équipes sont contentes de leurs usines car elles rendent le service attendu.
Chez d'autres, une seule usine d'entreprise existe (ou est censé exister). Résultat : l'usine croule sous le nombre de projets (configurés plus ou moins anarchiquement), la durée des builds augmente et les équipes finissent par remonter une petite usine dans leur coin pour pallier à la lenteur du serveur.
Au milieu de ça, il y a ceux qui sont dans le premier cas et qui veulent industrialiser. La plupart du temps, ils n'ont pas les moyens nécessaires (support aux équipes, serveur suffisamment puissant) et surtout ils manquent cruellement d'appui des supérieurs et/ou de la production. Résultat : l'usine est peu ou pas utilisée, les projets ne sachant parfois même pas qu'il en existe une centralisée.
Et enfin à l'extrême, il y ceux qui n'en ont pas du tout. Résultat : ils se passent d'une pratique, qui, si elle est mise en œuvre correctement, apporte énormément tant sur la productivité que sur la qualité des applications.
L'industrialisation de cette pratique amène donc les limitations suivantes (pas vraiment nouvelles [1]) :
Le serveur d'intégration ne tient pas la charge lorsque de nombreuses applications y sont construites.
Malgré tous les apports de l'intégration continue, il arrive encore trop régulièrement de casser le build si un développeur peu rigoureux omet de publier un fichier, en ajoute un qui ne compile pas ou qui ne passe pas les tests... bref l'intégration se fait encore trop tardivement !
L'intégration continue ne fait pas partie intégrante du cycle développement / production d'applications, en tout cas pas suffisamment pour être exploité au mieux par toutes les équipes projets.
Ce billet (1er d'une série de 3) traitera des performances des serveurs d'intégration continue.
Performances et disponibilité de l'intégration continue
Un build simple (compilation + tests unitaires) ne devrait pas prendre plus de 10 minutes. Si l'on rajoute les tests fonctionnels (fitnesse, greenpepper, ...), les tests d'interface (selenium, watij, ...), on arrive effectivement à des temps déraisonnables mais pourtant nécessaires d'une demi-heure à une heure. Lorsque le nombre de projets construits par l'usine augmente et que les builds se lancent en parallèle, il n'est pas rare de voir doubler ou tripler ces laps de temps et ne parlons pas des gros projets. Il m'est arrivé de voir un build (inachevé) de 700 minutes ! Difficile ensuite de convaincre son manager du gain en productivité et en qualité grâce à l'intégration continue...
Java consommateur de ressources, serveurs mal proportionnés, tests mal écrits sont autant de raisons à ces lenteurs. Plusieurs solutions peuvent être envisagées :
• Avant d'ajouter 8 Go de RAM et 4 dual core, il peut être bon de réorganiser les builds :
Les tests unitaires sont ils vraiment unitaires ? La configuration spring/hibernate est elle chargée à chaque test ? Les tests unitaires doivent être les plus courts possibles, ne pas faire appel aux entrées/sorties, limiter le chargement des données au maximum... on pourrait consacrer un billet à ce sujet !
Les tests fonctionnels et d'interface doivent-ils vraiment être exécutés à chaque commit ? ne peut on pas se contenter de les lancer 2-3 fois par jour ou la nuit ? Généralement, ce genre de tests implique un déploiement sur un serveur, l'exécution de scripts sql d'init, le lancement d'un navigateur pour les tests d'IHM, que sais-je encore... Pas sûr que ce soit utile de sortir cette armada pour vérifier que votre nouveau DAO (Data Access Object) ne casse pas tout... les tests unitaires (voire d'intégration) devraient suffire.
Pareil concernant les indicateurs qualités et autres rapports, dashboard, site, etc. Une fois par nuit sera amplement suffisante pour avoir un beau compte rendu au petit matin. Préférer les plugins (checkstyle, findbugs, ...) directement au niveau de l'IDE pour avoir ces indicateurs sans alourdir l'usine.
On peut également travailler sur les timers (cron), de manière à lisser l'activité du serveur tout au long de la journée, revoir les dépendances entre les projets pour limiter les enchaînements de builds, supprimer les projets qui ne sont plus en développement... bref maintenir l'usine propre !
• Vous pouvez ensuite ajouter les 8 Go de RAM, les dual core et les disques 10000 trs/min, la jvm vous en sera reconnaissante. Disons que disposer d'un vrai serveur, et non d'un poste de travail dans un coin de l'open space a vraiment son intérêt.
• D'autre part, il y a de plus en plus de serveurs d'intégration continue (payants pour la plupart) qui fournissent une fonctionnalité intéressante : le build distribué. Les outils fonctionnent tous sur le même principe : des agents installés sur d'autres serveurs prennent à leur charge certains builds et fournissent le résultat au serveur principal.
Pour le moment, ces outils ne permettent pas de détecter une surconsommation des ressources et il faut donc les assister en configurant des agents "dédiés" à un environnement particulier (os, version du jdk, version de Maven...) ou en précisant directement quel build s'exécutera sur quel agent.
Bamboo d'Atlassian et Pulse de zutubi distribuent les builds en fonction des compatibilités entre le build et l'agent (ex : un projet Maven 2.0.6 avec le jdk 1.4 sur un agent ayant ces caractéristiques). Si vous n'avez que des projets Maven 2.0.9, jdk 1.5, l'intérêt est assez limité. On peut cependant s'en tirer en jouant sur les noms des jdk, les noms des "builder" (Maven)... et en répartissant les projets sur ces différentes config :
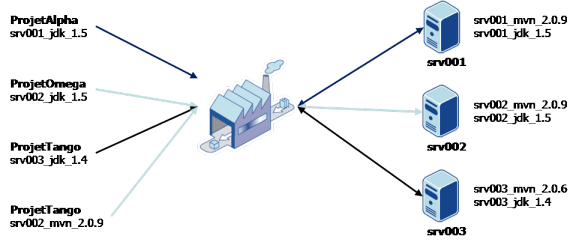
D'autres, comme TeamCity de JetBrains (l'éditeur d'IntelliJ IDEA) et Hudson (gratuit) permettent de spécifier directement quel build s'exécutera sur quel agent, fonctionnalité bien pratique pour disperser équitablement la charge sur les différents serveurs sans se compliquer la tâche :
• Il y a également tout intérêt à distribuer les tests, car aujourd'hui, plus que la compilation ou le packaging, ce sont bien eux qui prennent le plus de temps et de ressources. Pour le moment, il n'y a pas beaucoup d'outils qui proposent ce genre de fonctionnalités : GridGain pour JUnit, SeleniumGrid ou Greenpapper (remote agents) pour les tests d'interface web. Malheureusement, pour l'heure, il n'est pas simple de les utiliser en intégration continue. Je pense tout de même que c'est une piste à approfondir et si les outils parviennent à distribuer les builds, il fait nul doute que ce sera possible avec les tests.
• Outre le serveur lui même, si l'on utilise un repository d'entreprise (référentiel de librairies tels que artifactory, archiva ou nexus), qui permet de stocker l'ensemble des api utilisées au sein de l'entreprise (proxy vers le repo Maven) ainsi que les projets / frameworks créés en interne, il faut veiller à la disponibilité de cet espace de stockage. En effet, le serveur d'intégration continue se base sur ce référentiel pour construire les packages et donc sans librairies, la plupart des builds échoueraient. Au delà de ça, c'est surtout au niveau du poste de travail des développeurs que le risque est le plus élevé : songez au temps perdu par un développeur qui ne peux plus compiler son application, alors quand il y a des dizaines voire des centaines de développeurs qui comptent sur ce référentiel pour travailler, on imagine bien l'importance de ce composant. On doit donc garantir la haute disponibilité de cet espace (redondance, cluster... les éléments habituels).
Voilà quelques solutions pour amortir la charge du serveur d'intégration continue. Toutefois, si le build distribué ne convient pas ou si malgré tout, le serveur peine, il faudra certainement songer à mettre en place plusieurs usines (dédiés à des lignes métier par exemple, ou à certains gros projets stratégiques). Dans ce dernier cas, conserver la main sur les différentes instances permettra de ne pas en multiplier inutilement le nombre.
Dans le prochain épisode, nous parlerons des builds incassables...
[1] : Vincent Massol mentionnait déjà les build incassables, et les build distribués en 2004, preuve que ces pratiques (tests, intégration continue, agilité) entrent difficilement dans les entreprises (Françaises notamment).