Initier un datalab, rien à voir avec ce que j'imaginais ! - Compte rendu du talk de Frédéric Petit à la Duck Conf 2019
Datalab, datalake, Big Data, IA… Les buzz words autour de la donnée sont foison, et l’on s’accorde sur le fait que la donnée est au cœur même de nos systèmes d’information. Mais lorsqu’il s’agit concrètement de mettre en place une plateforme data, tout ne se passe pas forcément comme prévu... Frédéric Petit, responsable de l’architecture et des données d’entreprise chez MNT, nous raconte comment il a pu initier un datalab avec son équipe, en nous partageant notamment les obstacles qu’ils ont dû surmonter.
Contexte et amorce du projet
Dans le contexte initial de MNT, la donnée occupe déjà une place importante. Le système existant permet d’analyser des données et de calculer un certain nombre d’indicateurs à forte valeur ajoutée. Même si le système est fonctionnel, les inconvénients sont multiples : le calcul des indicateurs et des statistiques prend du temps (plusieurs heures) et n’est donc effectué que de façon hebdomadaire ou mensuelle, le système de calcul est un ETL peu évolutif et les statistiques sont analysées manuellement a posteriori pour faire de la prédiction. En un mot : les indicateurs reflètent les données du passé.

MNT a donc la volonté de passer sur un système avec une meilleure fraîcheur que celle permise par les batchs hebdomadaires, et s’intéresse à l’IA pour pouvoir fournir des scénarios stratégiques de prédiction. Frédéric et son équipe s’attellent donc à ce chantier d’envergure.
Étude et réflexions préliminaires
Mais quelles données d’entreprise utiliser ? Est-ce en phase avec la stratégie ? Quel est le ROI d’une telle solution ? Avant de démarrer le projet à grande échelle, ils lancent une expérimentation afin de répondre à ces questions essentielles qui leur permettront de trouver des sponsors internes.
L’équipe décide de se fixer un plan d’action et définit les grands axes de cette expérimentation :
- la gouvernance de la donnée, qui regroupe les étapes de collecte de la donnée, son analyse ainsi que la mise en corrélation,
- le machine learning,
- le big data, qui consiste au passage à l’échelle avec le traitement de gros volumes.
La principale volonté partagée par l’équipe est d’expérimenter avant de passer à l’échelle. Elle s’est donc fixée une série d’objectifs incrémentaux à passer pas à pas : se former aux technologies, expérimenter pour voir ce qu’il est possible de faire avec les données de l’entreprise afin de développer une communauté autour du datalab et valoriser ce qui aura été mis en œuvre. Ces étapes ont permis à l’équipe de gagner en confiance sur ce qu’elle était capable de réaliser. Pour poursuivre l’expérimentation, l’équipe a identifié plusieurs cas d’usage sur lesquels se concentrer :
- la recommandation de contrats aux personnes,
- l’attrition, dans une optique de qualité de service,
- la détection de fraude.

Mise en pratique : difficultés et apprentissages
Passée cette première phase d’étude en chambre, l’équipe a dû faire face à ses premières difficultés :
- l’accès à la donnée est compliqué, par exemple pour des questions de réglementation ou de donnée enfermée dans des progiciels qui ne mettent pas d’API à disposition,
- les données ne sont pas toujours de qualité, avec des applications qui ont chacune leur norme,
- la source de vérité de la donnée n’est pas toujours facilement identifiable,
- l’historisation des changements est une source de complexité, car les formats ont parfois été amenés à changer au cours du temps,
- la disponibilité des intervenants n’est pas toujours garantie, le datalab étant une expérimentation, il n’est pas prioritaire,
- la consommation de jeux de données de plus en plus volumineux est compliquée sur une infrastructure sous-dimensionnée.
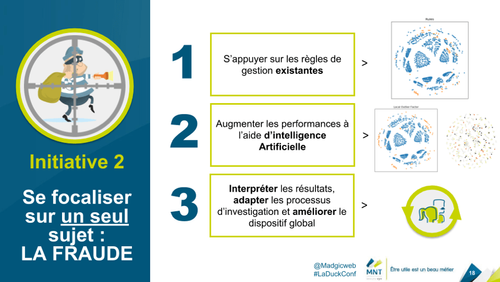
Pour pouvoir avancer et traiter les sujets au fur et à mesure, ils ont dû prioriser et faire un choix : il n’était pas possible de traiter toutes les difficultés et avancer sur les 3 cas d’usage en même temps. Ils ont donc décidé de se focaliser sur la lutte contre la fraude, ce qui leur a permis :
- de se former, notamment à la data science,
- d’élaborer des algorithmes pertinents en expérimentant techniquement,
- d’itérer sur les développements, main dans la main avec le métier, pour proposer un service qui a du sens,
- de valoriser leur outil, car leur moteur de détection de fraude est utilisé et permet de détecter de nouveaux cas de fraude.
Ces conclusions ont permis à l’équipe de trouver des sponsors, et aujourd’hui la plateforme est en train de passer à l’échelle. Ce n’est pas la fin de l’histoire, d’autres défis restent à relever : sécuriser les accès aux données ou encore s’assurer que la donnée utilisée est la plus fraîche possible. Mais ces prochains chantiers sont aujourd’hui abordés sereinement, car l’équipe maîtrise ses outils.
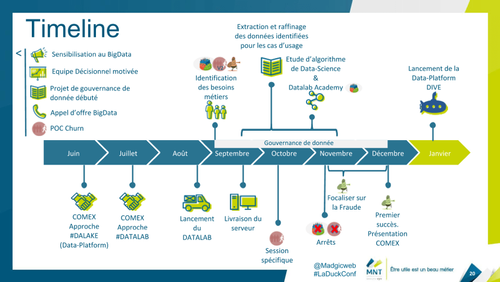
L’expérience de Frédéric et de son équipe permet de souligner que pragmatisme est le maître mot dans le cheminement de ce type d’expérimentation : identifier rapidement les données disponibles et traiter les sujets un par un, en allant crescendo dans la difficulté leur a permis de surmonter les obstacles petit à petit. Et enfin, l’association avec le métier a été primordiale pour pouvoir proposer une offre de service qui a du sens.