Infrastructure as a Template : 85M d'utilisateurs avec une équipe de 5 personnes. Compte-rendu du talk de Mikael Robert à la Duck Conf 2025
Mikael Robert nous raconte son voyage de 4 ans pour gérer l’infrastructure supportant l'application Yubo. Basé en France, Yubo est un réseau social pour les d'jeunes (un terme de vieux me direz-vous) de la Gen Z dont le mode d'interaction est des vidéos en live. Ce réseau social prend le contre-pied de X, Meta en investissant sur la modération pour créer un climat de confiance et de sûreté ! La modération repose sur l'IA et du Machine Learning, en cas de doute un arbitrage humain intervient. Chaque décision améliore les algorithmes pour les futures situations similaires (note : je me demande si la modération inclut aussi la suppression de fake news ?).
En 2021, l'infrastructure de Yubo, c'est :
- 85 millions d'utilisateurs
- 140 pays
- une disponibilité en 24/7 toute l'année
- 10k requêtes/seconde en moyenne
- 400 microservices
- qui persistent leur données dans 40 clusters de base de données
- ... dans 11 technologies différentes
- déployés sur une infrastructure hybride sur GCP et du Bare Metal (pour leur service de streaming vidéo maison).
Malgré des déploiements manuels, le rythme permet la release de 2 fonctionnalités par semaine.
A l'exception du service de streaming vidéo, tout est déployé dans un cluster Kubernetes donnant le plus gros cluster GCP en France en termes de workload et trafic en 2021 sans avoir d'Ops pour le gérer. Autant dire que les performances, la sécurité, l'industrialisation et la carte bancaire étaient en PLS. Un record à la fois impressionnant et effrayant.
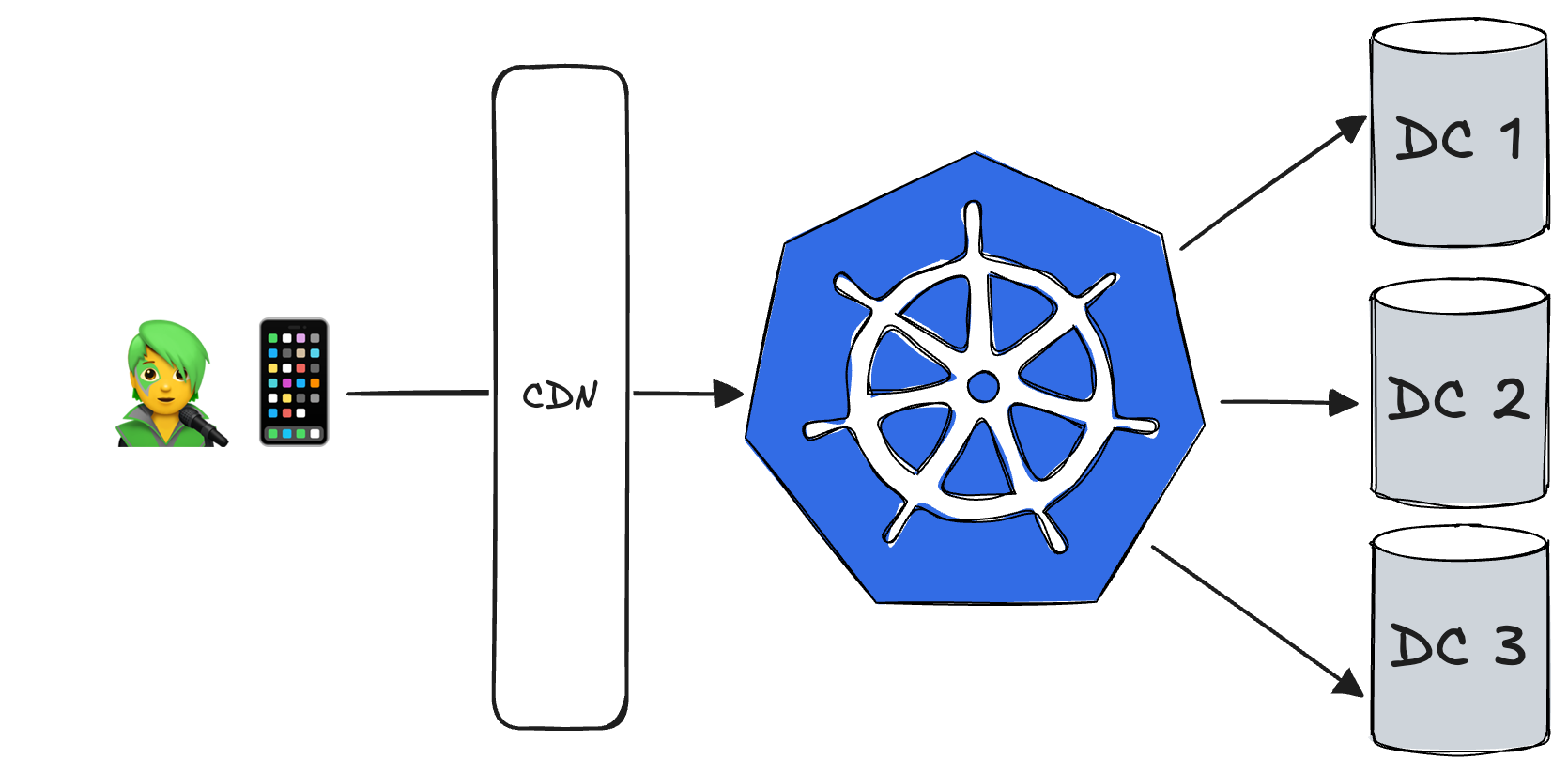
Maintenant que le contexte de départ est clair, Mikael nous d’aborder les points suivants dans le coeur de la présentation
Soutenir le passage à l’échelle par
- Une évolution de l'organisation avec les Ops
- La mise en place d’une CI/CD avec des standards d’entreprise
- La configuration de code d’infrastructure par les équipe de dev
- L’autonomisation des équipes dans la gestion des données par feature
- L’application d’un standard d’entreprise sur les workflows de Machine Learning
Les astuces utilisées pour tirer parti des solutions d'observabilité en SaaS et self-hosted.
Automation at Scale aka le plan de survie dans un monde de 85M d'ados
Structurer l'organisation
"Les contraintes poussent à innover là où les gros budgets se contentent d'exécuter."
Leur idée disruptive : mettre les Ops et les Data Eng dans la même équipe ! #AdopteUnOps
L'équipe Ops était mise dans la boucle en fin de cycle de release des fonctionnalités arrivant en production. Résultat : les bases étaient mises à mal. La vision globale du système n'est pas forcément claire pour toutes les équipes. Exemple : le trafic ne vient pas que des usagers finaux mais aussi des algorithmes de modération avec des pics de 300k requêtes/seconde sur les bases de données.
Je reviens sur un chiffre : "11 technologies différentes de base de données". Yubo a donné l'autonomie du choix des technologies des bases de données adaptées aux besoins des Data Eng. Cette réorganisation a sûrement ramené la responsabilité d'opérer ces technologies en mettant toutes les compétences nécessaires pour assurer le BUILD et le RUN dans la même équipe. Ah, c'est beau de revenir à la base du DevOps ❤. Résultat : l'infra est impliquée dans le produit. Les informations de conception sont partagées en amont et l'optimisation des clusters est portée au sein de l'équipe de DATA/RUN.
Adopter le paradigme GitOps et un poste de commandement
Déployer manuellement depuis un poste de développement ça marche mais ça ne passe pas à l'échelle, ce n'est pas résilient au niveau de l'équipe, ce n'est pas traçable, ...
Avec une palanquée de dépôts Git et du copier/coller dans les processus de déploiement, Argo CD a été salutaire pour soulager la charge et complexité du déploiement apportant un nouveau standard de déploiement continu.
Historiquement, les pipelines de déploiement continu se déclenchent sur des événements (modifications de code, tag git, merge, déploiements manuel, ...). La pipeline doit donc avoir accès à l’infrastructure pour la configurer et en cas d’échec, il faut relancer les étapes.
L’implémentation GitOps avec ArgoCD inverse l’approche : c’est l’infrastructure qui accède régulièrement au code source pour se synchroniser.
“Le code est la source de vérité”
Un Data Center pour les gouverner tous
Root DC : un Data Center central permettant de piloter le provisioning et la configuration de l'infrastructure et des applicatifs sur le Cloud et Bare Metal. La configuration du Root DC est restreinte à l'équipe d'infrastructure. Ce Root DC offre les services d’orchestration (Argo Workflow) lui-même piloté par un ArgoCD.
Cette approche a permis à Yubo de piloter leur infrastructure hybride depuis un point unique et d'engager des chantiers de migration pour se sortir progressivement des DC Bare Metal.
Organiser le patrimoine d'infrastructure
Mettre en Production rapidement pour tester l'adoption d'une fonctionnalité quitte à prendre des raccourcis, fait partie de la culture. Si le test est concluant, l'industrialisation pourrait se faire a posteriori (ou pas du tout). Leur philosophie est de faire en sorte que le déploiement facilite l'expérimentation tout en respectant les caractéristiques d'architecture (sécurité, observabilité, compliance, ...).

Un dépôt de code d'infra a beau être ouvert à des PR, si la connaissance des technologies sous jacentes (Kubernetes, Argo Workflow, Terraform, GCP, conf de DB) n'est pas un acquise, la contribution des dev team ne restera qu'un vœu pieux. La charge cognitive extrinsèque peut s'accompagner d'une abstraction pour être réduite :
- le développement d'opérateur Kubernetes pour augmenter l'intégration à Kubernetes
- le remplacement de Terraform par Config Connector : une solution managée sur GCP où la topologie d’infrastructure est décrite dans des manifestes Kubernetes.
Tout ceci a réduit la configuration à un seul langage : YAML. Ce dernier est accessible aux dev team et a réduit le ticket d'entrée d'ouverture des PR sur l'infra. Les dépôts de code d'infrastructure font maintenant office de CMDB (Configuration Management Database) !
Dans ce contexte, la définition d'un service se fait à deux endroits :
- service.git : un dépôt de code pour l'application avec sa configuration de développement
- service-k8s.git : un second dépôt de code pour la définition de l'infrastructure, les manifestes de déploiement, la configuration des bases de données, la configuration des services d'observabilité, ... Toute cette configuration est multi environnements ici.
Les équipes de dev sont maintenant autonomes grâce à la CMDB et une abstraction de la complexité des technologies sous-jacentes.
L’équipe infra de Yubo adopte une approche centrée développeur : tout est pensé pour réduire les frictions avec l’infrastructure, qu’il s’agisse de la complexité technique ou de la disponibilité des Ops. Et ce n’est qu’un début : l’équipe développe un portail pour pousser plus loin l’Infrastructure as a Service.
"Une CI, c'est une CI"
Avec un nombre élevé de dépôts de code couplé à un rythme de release très fréquent en production, par où commencer pour mettre en place des pipelines de CI ? L’équipe infra de Yubo a pris le parti de standardiser tous les workflows de CI en 5 étapes : Build, Test, Package, Version, Push.
Si le workflow est standardisé, les dev team peuvent venir définir la pipeline de CI via un fichier de configuration. Ce dernier sera ingéré par un moteur de templating générant un workflow Argo. Une fois encore, l'approche de CMDB est utilisée !
Ma réflexion sur cette approche : cette standardisation de pipeline me fait penser à la proposition Pierre SMEYERS avec le projet Open Source https://to-be-continuous.gitlab.io. Habituellement, j'ai pour habitude d'accompagner les dev team pour co construire le workflow de CI/CD selon leurs besoins et façon de travailler. Cet accompagnement se fait dans le temps afin que les équipes s'approprient petit à petit la pipeline. L'objectif étant de les rendre autonomes dans l'évolution et la maintenance sur le périmètre applicatif et qu'elles comprennent les grandes étapes du Déploiement Continue.
Data at Scale, "les DBs, j'en mange au petit déj"
Résumons les contraintes de Yubo dans le contexte des bases de données :
- un trafic élevé (pic de 300k requêtes/seconde)
- 11 technologies de base de données différentes
- peu de personnes pour les opérer
- une exigence forte de résilience
Un choix rationnel s’est imposé : l’autonomie dans la gestion des données a été privilégiée à la centralisation dans une seule source de vérité.
La duplication est acceptée, les bases de données sont dédiées par feature (n'oubliez pas que leurs features se multiplient comme des petits pains et qu'ils peuvent vite décommissioner une feature non adoptée).
La communication entre deux features (ou domaines) au sein du système se fait par chorégraphie avec l'utilisation du pattern CDC (Change Data Capture) : chaque mise à jour en base va émettre un événement dans un topic Kafka.
Machine Learning at Scale
Opérer un modèle de ML en production implique souvent des ajustements ou rollback suite à la réalité de la production : un drift entre les données d'entraînement et celles sur lesquelles le modèle s’exécute, une dégradation des performances, ...
La réponse apportée vient avec une nouvelle étape dans la standardisation de la CI : l'entraînement du modèle avec un Data Lake alimenté par le CDC.
- Développement du modèle de ML par les équipes
- Partage du modèle dans un gestionnaire d'artéfacts (https://mlflow.org)
- Déploiement du nouveau modèle en production avec une stratégie de canary release
- Observation des performances du modèle pour décider de la généralisation du déploiement ou du rollback
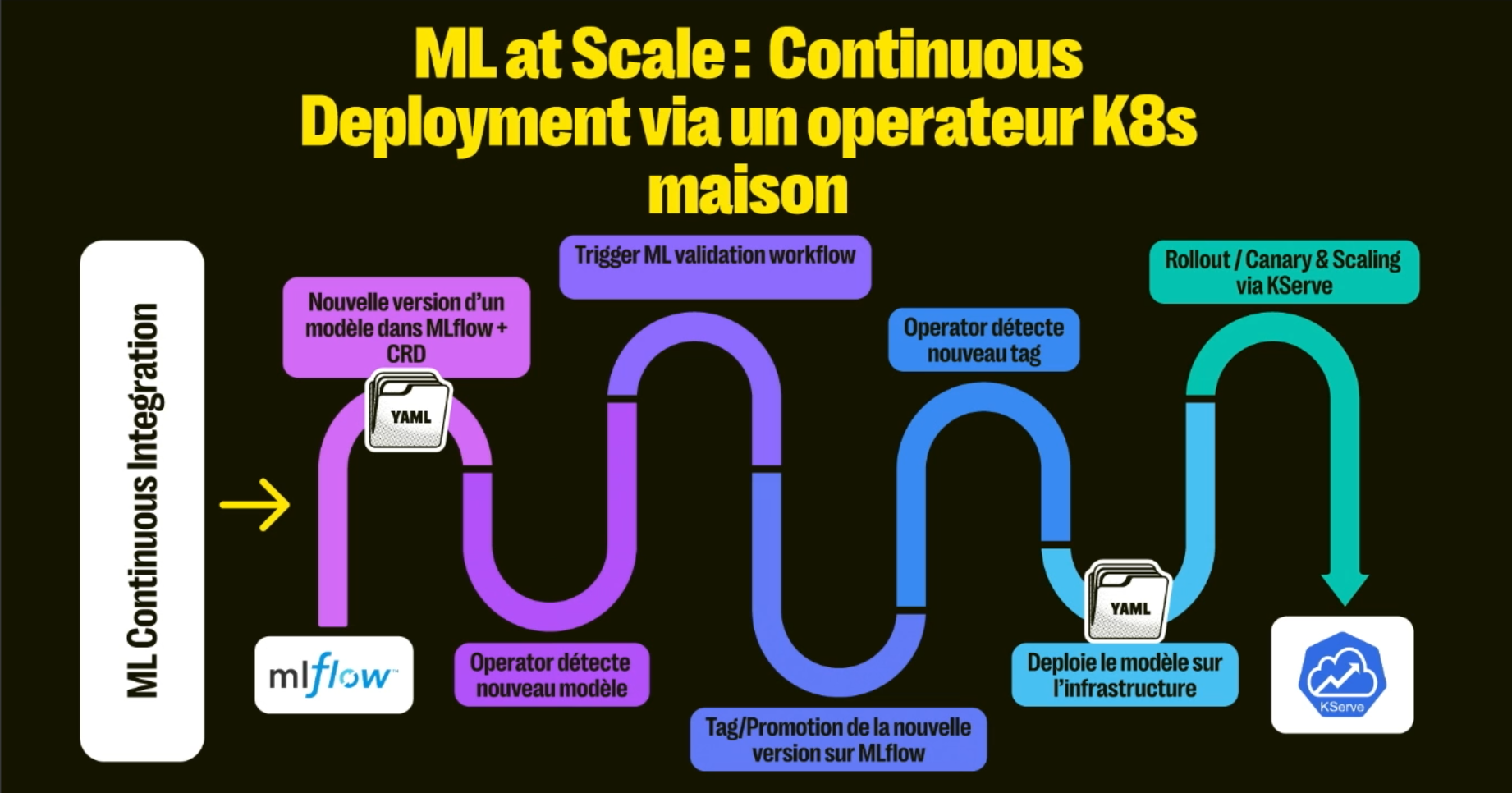
Pour en apprendre plus sur comment opérer du Machine Learning en production, retrouvez notre publication Culture MLOps.
Et si nous devions lancer une nouvelle application ?
Ah, si ça ce n'est pas une demande d’une personne qui foisonne d'idées ☺️
Le premier chemin, une option techniquement simple : copier du code d'infra existant. Efficace, bête et méchant. Mais les erreurs de copier/coller ne pardonneront pas et le coût restera élevé pour l'évolutivité et la maintenance. Finalement, l’équipe infra a choisi la voie de l'ingénierie avec une nouvelle couche d'abstraction dans le rapport entre l'infrastructure et le templating : ajouter un identifiant pour relier le composant d’infrastructure à l’application. L’identifiant devient un paramètre de configuration et de templating !
"Je template, tu templates, il template, nous templatons, ..."
L'observabilité chez Yubo
Les défis de l'équipe face à cette infra titanesque :
- gérer la volumétrie et le trafic de la télémétrie
- optimiser le coût de stockage
- déployer automatiquement des dashboards accessibles aux équipes
- avoir le bon ratio signal/bruit pour éviter l'alert fatigue
Si les plateformes d'observabilité en SaaS assurent un bon catalogue de service avec une bonne disponibilité, c'est le prix de la volumétrie de données qui pose problème.
Build or Buy ? Les deux mon capitaine ! Yubo tire le meilleur des deux mondes avec des plateformes en SaaS et une plateforme OpenSource self-hosted. La télémétrie est envoyée dans un flux en Y (dual shipping) sur les deux plateformes. Les données sont échantillonnées (sampling) pour la partie SaaS limitant ainsi les coûts.
Les équipes produits n'avaient pas besoin de la donnée en temps réel ni d'avoir une granularité à la seconde près. Cette hypothèse de travail a permis d'implémenter une stratégie d'échantillonnage pour les plateformes en SaaS de type Decaying Sampling : plus la donnée est vieille, moins elle est précise. C'est ingénieux encore une fois !
A mon sens, les points faibles (mais acceptés) de cette approche sont :
- deux technologies qui répondent à la même fonction dans le SI (mais si vous avez suivi le nombre de technos de base de données, ce n'est un sujet chez Yubo 😛*)*
- le système n'est plus observable via un point d’entrée unique, il faut utiliser le bon point d'entrée selon le use case (analytics, production, exploration de la donnée en profondeur)
En définitive
La gestion de l’infra chez Yubo et la maturité de leur plateforme est impressionnante ! Tant sur le plan technologique que dans l'approche très pragmatique vis à vis de leurs contraintes :
- réunir les Data Eng et Ops pour obtenir des bases de données performantes, aka "killer database"
- donner une forte autonomie et les responsabilités associées dans le choix des technologies
- adopter la chorégraphie pour autonomiser les microservices
- standardiser les pratiques de CI/CD
- les grandes étapes de la CI sont identiques
- ArgoCD apporte le cadre de la CD
- fournir le bon niveau d'abstraction pour autonomiser par
- de la configuration et du templating
- le développement d'opérateur Kubernetes
- limiter les coûts des stack d'observabilité en SaaS et utiliser une stack self-hosted selon le besoin
Une présentation intéressante et inspirante dont je vous recommande le replay de la conférence. Encore bravo aux équipes de Yubo pour le chemin parcouru en 4 ans !