Industrial document classification with Deep Learning
Knowledge is a goldmine for companies. It comes in different shapes and forms: mainly documents (presentation slides and documentation) that allow businesses to share information with their customers and staff. The way companies harness this knowledge is central to their ability to develop their business successfully.
One of the common ways to ease the access to this document base is to use search engines based on textual data. At OCTO, we have decided to use optical character recognition (OCR) solutions to extract this data, since they have offered a strategy with a good coverage compatible with any PDF, even the scanned ones. The problem with this approach is that the extracted text usually has a poor quality with spelling mistakes and non preserved formatting. This bad quality limits the level of the search engine results: this level was acceptable when the number of documents was lower, but is no more compatible with the increased number of documents we experience today. As a result, OCR based search engines no longer allow companies to exploit their knowledge base in a coherent and productive way.
We believe that those limits can be overcome when we take advantage of the documents’ visual features along their textual data since nowadays documents are usually visually augmented with images and charts to illustrate ideas.
In this article, our work focuses on OCTO’s knowledge base with the classification of its presentation slides: a type of documents designed for visual presentations.
Dataset
OCTO’s knowledge base gathers more than 1,5 million slides. It is daily fed with new documents that consultants create to illustrate ideas for our clients.
To prepare the dataset, we started by interviewing some of our consultants to identify classes with high value to the company. Each class corresponds to a distinct typology of slide that has a real usefulness to our core business. We considered that each slide can be associated with only one class. After that, we started labeling the dataset documents. However, because the manual labeling can be very tedious, we developed a web application to speed up the process. But one problem remained: how to recognize the slides that do not belong to any of the identified classes? One idea we had was to group the remaining classes in a new class « Other ».
The final dataset is composed of 6 different classes with 500 samples each (3000 slides in total).

For each class, we used 400 samples to train our model, 50 samples for validation and the remaining 50 samples to test its accuracy.
What model should we use ?
In Deep Learning, there are many types of networks to choose from: multi-layer perceptron (MLP), convolutional neural network (CNN), recurrent neural network (RNN), etc. Many of these networks are flexible enough to be used with different types of data (text, image, etc.). However, each of them has some characteristics that helps it get the best accuracy when used with the appropriate type of data in the appropriate context.
In our case, we chose to use a CNN model because it is highly suited for image classification tasks. In fact, this type of network uses some interesting operations like Convolutions to detect low (edges, textures, etc) and high level (objects, etc) patterns in images.
Let’s stimulate some neurons
To evaluate our model, we used the accuracy metric along with the confusion matrix (this metric gave us a more detailed information about the model classification performance on each class).
We started by training a simple CNN architecture (MobileNet v1_1.0_224) but we quickly realized that we were limited by the size of our training data. After all, 3000 samples were not enough for the model to learn to correctly classify our dataset. In fact, our model had more than 4 million parameters that needed to be optimized. Yet, since they were randomly initialized, it requires a huge amount of images (tens of thousands) to find the proper weights that learn useful and sufficiently abstract features.
To increase the size of our dataset, one of the possible techniques is to use data augmentation (cropping, zooming or flipping images). However, because our documents are mainly presentation slides, they always have the same form. So this technique will not generate new valid samples and will only make it difficult for the model to learn.
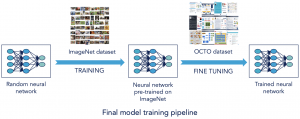
At this stage, since we can not increase the size of our dataset, we choose to simplify the training of our model by transferring knowledge from another model (base model) that has already been trained on a related domain: image classification. This technique is called Transfer Learning.
«Transfer learning is the improvement of learning in a new task through the transfer of knowledge from a related task that has already been learned.» - Transfer Learning, Lisa Torrey and Jude Shavlik, 2009
With this technique our model can benefit from the knowledge of the base model by starting training from its already learned features and using our dataset to fine-tune them for our new classification goal.
«In transfer learning, we first train a base network on a base dataset and task, and then we repurpose the learned features, or transfer them, to a second target network to be trained on a target dataset and task. This process will tend to work if the features are general, meaning suitable to both base and target tasks, instead of specific to the base task.» - How transferable are features in deep neural networks?, Jason Yosinski et al, 2014
We choose to transfer knowledge from a pre-trained MobileNet network: a CNN model trained on ImageNet dataset (1,2 million images). We added to this base model a simple model (top model) consisting of 2 dense layers.
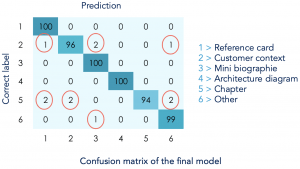
After training our top model, we reached an accuracy of 98%. In fact, our model correctly classifies all the Project reference card, Mini biography and Architecture diagram documents but still makes some errors when it comes to Customer reference card, Chapter and Other documents. For example, it confuses some of the Customer reference card slides with Mini biography, Project reference card and Other slides.
Why Transfer Learning significantly improved our model accuracy?
We were curious about the impact of Transfer Learning on our model accuracy. So we investigated its effect on the high level features of the base and top model.
We started by computing the representation of our dataset images using MobileNet and our top model respectively. Then we created a 2D representation of their bottleneck features (the last activation maps before the fully-connected layers) by reducing their dimension from 1024 to 2 using T-SNE algorithm. Finally, we plotted the slides in the 2D space.
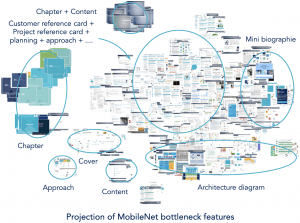
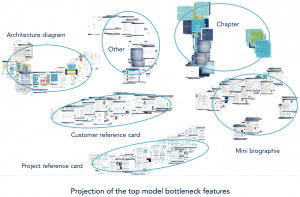
Simply put, the top model specializes in our dataset by separating documents that are visually similar if they do not belong to the same class and gathers documents that belong to the same class even if they are visually different. For example, before fine-tuning Chapter and Content classes were grouped together (Content belongs to the class Other) and after fine-tuning they were seperated.
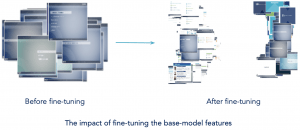
Do we have the perfect model?
Even with a limited amount of images, we managed to make a model classifying nearly all documents correctly (98 % accuracy on the testing set). Nevertheless, our model still have some limits.
Model limits
Confusion between classes (visual features of a class incorporated into another)
When a document belonging to class A includes some illustrations that contain visual features of class B, the model will struggle to identify its class. Indeed, if we had enough samples in the training dataset illustrating this situation, the model would not fall into this trap.
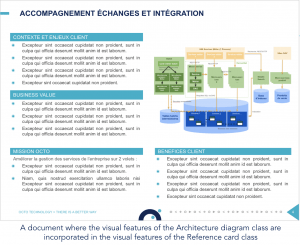
Different classes with the same visual features
Our model relies only on visual features of documents to classify them. Therefore, if we have some classes with the same visual features, our model can not determine the visual discriminators that separates them for the simple reason that they do not exist.
Poor visual features
When a class does not have any specific visual characteristics or have fewer of them, our model can not learn to classify it. For example, if we train it to classify semantic classes (Blockchain, IoT, etc), it will not succeed because this type of classes relies mostly on textual features and not visual ones.
Not all visual features are covered in the training dataset
When some of the visual features of a class are not present / covered in the training set.

In this example, the 2 slides belong to the Mini biography class. The model correctly classifies the 1st but not the 2nd because it belongs to the new template which is not sufficiently covered in the training set.
Possible improvements
We believe that these limits can be overcome when we expand the model feature resources by taking advantage of the textual data of documents along with their visual properties.
In fact, each class has textual features in the form of keywords. For example, the class Customer reference card always includes the keywords: context, demand, request, approach, etc..
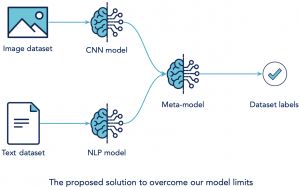
Moreover, our improved solution can be composed of 3 models:
- CNN model for visual features.
- NLP model for textual properties.
- Meta-model that uses the CNN or NLP model to classify the documents.
As a result, for each class, the meta-model will learn to privilege the appropriate features whether they are visual, textual or the combination of both of them. For instance, if we have a class « Blockchain », the proposed model may give 80% importance to the textual properties and only 20% for visual features.
To wrap up
We managed to create a deep learning model that classifies industrial documents (slides) perfectly for classes with a strong visual identity. However, for this handcrafted successful proof of concept to not just be confined to a research lab, it should be deployed into production. Nevertheless, this step needs some reflection because the industrialization of such AI powered systems comes with a number of hurdles if we don’t follow the good practices of implementation and integration.
If you want to learn more about the industrialization of Artificial Intelligence products, check out this presentation of our Big Data Analytics team where they share their knowledge about the organisational, methodological and technical patterns to adopt for the creation of practical and sustainable AI products.
To go further
CNN:
- Andrej Karpathy blog
- Classification d’images: les réseaux de neurones convolutifs en toute simplicité
Transfer Learning: