Implémenter une application web dans une fonction lambda (AWS)
Depuis 2015, le serverless ne cesse de prendre de l’ampleur. Un indicateur de cette expansion est la multiplication des providers serverless (AWS lambda, Google cloud function, Azure function, IBM openwhisk, etc.). Cet article n’a pas vocation à présenter ce qu’est le serverless, mais à démontrer comment une application web peut être hébergée sur le cloud AWS avec le service lambda, en lieu et place d’un hébergement sur un serveur d’application traditionnel.
body .gist .highlight { background: #202020; } body .gist tr:nth-child(2n+1) { background: #202020; } body .gist tr:nth-child(2n) { background: #202020; } body .gist .gist-meta { display:none; } body .gist .blob-num, body .gist .blob-code-inner, body .gist .pl-s2, body .gist .pl-stj { color: #f8f8f2; } body .gist .pl-c1 { color: #ae81ff; } body .gist .pl-enti { color: #a6e22e; font-weight: 700; } body .gist .pl-st { color: #66d9ef; } body .gist .pl-mdr { color: #66d9ef; font-weight: 400; } body .gist .pl-ms1 { background: #fd971f; } body .gist .pl-c, body .gist .pl-c span, body .gist .pl-pdc { color: #75715e; font-style: italic; } body .gist .pl-cce, body .gist .pl-cn, body .gist .pl-coc, body .gist .pl-enc, body .gist .pl-ens, body .gist .pl-kos, body .gist .pl-kou, body .gist .pl-mh .pl-pdh, body .gist .pl-mp, body .gist .pl-mp1 .pl-sf, body .gist .pl-mq, body .gist .pl-pde, body .gist .pl-pse, body .gist .pl-pse .pl-s2, body .gist .pl-mp .pl-s3, body .gist .pl-smi, body .gist .pl-stp, body .gist .pl-sv, body .gist .pl-v, body .gist .pl-vi, body .gist .pl-vpf, body .gist .pl-mri, body .gist .pl-va, body .gist .pl-vpu { color: #66d9ef; } body .gist .pl-cos, body .gist .pl-ml, body .gist .pl-pds, body .gist .pl-s, body .gist .pl-s1, body .gist .pl-sol { color: #e6db74; } body .gist .pl-e, body .gist .pl-ef, body .gist .pl-en, body .gist .pl-enf, body .gist .pl-enm, body .gist .pl-entc, body .gist .pl-entm, body .gist .pl-eoac, body .gist .pl-eoac .pl-pde, body .gist .pl-eoi, body .gist .pl-mai .pl-sf, body .gist .pl-mm, body .gist .pl-pdv, body .gist .pl-som, body .gist .pl-sr, body .gist .pl-vo { color: #a6e22e; } body .gist .pl-ent, body .gist .pl-eoa, body .gist .pl-eoai, body .gist .pl-eoai .pl-pde, body .gist .pl-k, body .gist .pl-ko, body .gist .pl-kolp, body .gist .pl-mc, body .gist .pl-mr, body .gist .pl-ms, body .gist .pl-s3, body .gist .pl-smc, body .gist .pl-smp, body .gist .pl-sok, body .gist .pl-sra, body .gist .pl-src, body .gist .pl-sre { color: #f92672; } body .gist .pl-mb, body .gist .pl-pdb { color: #e6db74; font-weight: 700; } body .gist .pl-mi, body .gist .pl-pdi { color: #f92672; font-style: italic; } body .gist .pl-pdc1, body .gist .pl-scp { color: #ae81ff; } body .gist .pl-sc, body .gist .pl-sf, body .gist .pl-mo, body .gist .pl-entl { color: #fd971f; } body .gist .pl-mi1, body .gist .pl-mdht { color: #a6e22e; background: rgba(0, 64, 0, .5); } body .gist .pl-md, body .gist .pl-mdhf { color: #f92672; background: rgba(64, 0, 0, .5); } body .gist .pl-mdh, body .gist .pl-mdi { color: #a6e22e; font-weight: 400; } body .gist .pl-ib, body .gist .pl-id, body .gist .pl-ii, body .gist .pl-iu { background: #a6e22e; color: #272822; } body .gist .gist-file, body .gist .gist-data { border: 0px; border-bottom: 0px; }
Cet article s’inscrit dans la série d’articles consacrés au serverless, dont le premier peut-être consulté ici.
Actuellement le serverless tend vers des architectures très découpées. Les retours d’expérience sur de telles architectures montrent qu’un grand nombre de lambda implique beaucoup de complexité. Est-ce qu’une architecture beaucoup plus traditionnelle ne serait pas envisageable dans une lambda, par exemple pour bénéficier des avantages du serverless sur une application existante ou pour limiter la complexification liée à un grand nombre de lambda. Cet article propose une implémentation à contre courant de l’état de l’art des applications serverless actuelles, avec pour objectif de voir s’il est possible de mettre en place d’autres approches pour contourner certaines difficultés. L’idée est donc de développer une application web destinée à une utilisation interne par des équipes métier.
Avant de rentrer dans les détails de l’implémentation, voici une petite présentation des outils et technologies utilisés pour cette démonstration. D’une part, il y a l’application web qui est codée en java 8 à l’aide du framework Spring, plus précisément la version 5 avec Springboot. Cette application est un simple CRUD sur une base de donnée. D’autre part, il y a le service managé pour exposer l’API de l’application qui est basé sur AWS API Gateway. Et enfin, il y a le service managé pour la base de données qui est basé sur AWS DynamoDB. Tous ces services sont fournis par AWS ce qui facilite grandement la configuration de la stack. Néanmoins, il est possible d’utiliser d’autres services managés (par exemple Kong coté exposition de l’API) ou encore d’exposer une API “maison”, mais cela nécessite plus de configuration.
L’objectif est donc d’implémenter une application web qui utilise Springboot comme framework web dans un environnement serverless.
Voici un schéma de la stack complète 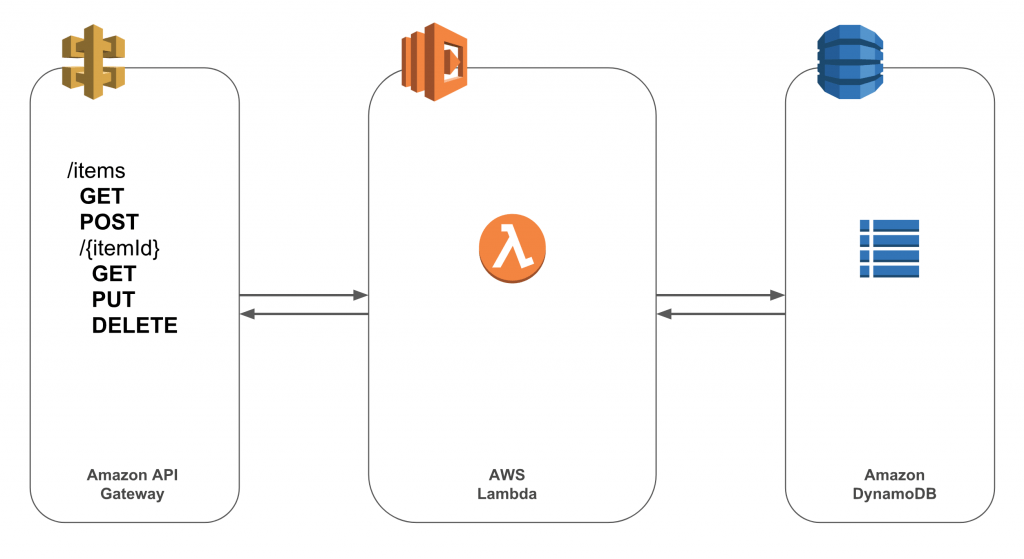
Ce schéma montre que l’application doit donc s’interfacer avec 2 services AWS. Pour la connexion à la base de données cela se fait simplement avec l’aide de Spring Data Dynamo qui va permettre de simplifier le code permettant d’ouvrir la connexion à la base de données et d’exécuter les opérations de lecture/écriture. Comme cette opération est exécutée depuis lambda, la configuration de DynamoDB dans l’application est très simple.
Voici à quoi cela ressemble
import com.amazonaws.services.dynamodbv2.AmazonDynamoDB;
import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClientBuilder;
import org.socialsignin.spring.data.dynamodb.repository.config.EnableDynamoDBRepositories;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
@EnableDynamoDBRepositories(basePackages = "com.octo.rnd.serverless")
public class DynamoDBConfig {
@Value("${amazon.dynamodb.region}")
private String amazonDynamoDBRegion;
@Bean
public AmazonDynamoDB amazonDynamoDB() {
return AmazonDynamoDBClientBuilder.standard()
.withRegion(amazonDynamoDBRegion)
.build();
}
}
Cela est un peu plus complexe coté API, puisqu’il faut que l’évenement envoyé par API Gateway soit correctement interprété par Spring.
Pour bien comprendre ce qui pose problème voici une brève explication sur l'interaction entre API Gateway et lambda.
API gateway récupère une requête HTTP envoyée par un client et fait une vérification sur les autorisations. Il s’agit ici des autorisations IAM qui définissent que API Gateway a les droits d’appeler la lambda et non pas d’une authentification applicative. Ensuite, la requête est remodelée dans un événement que la lambda va recevoir en entrée.
Schématiquement, le procédé est le suivant : 
Pour la réponse c’est le même principe en sens inverse, la lambda envoie un événement en sortie qui va être remodelé avant d’être envoyé vers le client sous la forme d’une réponse HTTP.
Lambda récupère un événement sous forme de flux en entrée, et ce flux est passé en argument d’une méthode handler. AWS mets à disposition des librairies qui permettent de formater ce flux d’entrée sous la forme d’une requête API Gateway avec AwsProxyRequest
par exemple. C’est donc à l’intérieur du handler qu’il faut gérer l’initialisation de Spring, la correspondance entre l'événement reçu et le servlet de l’application Spring. Dans ce cas, AWS-Labs propose une librairie appelée aws-serverless-java-container qui permet d’encapsuler une application Spring (mais aussi Jersey ou Spark) dans le handler d’une lambda. L’impact sur le code de l’application Spring est minime, il suffit de veiller à ne pas démarrer un serveur web HTTP (comme un Tomcat par exemple) à l’initialisation de Spring et d’ajouter quelques lignes de code dans le handler lambda.
Voici le code qui se trouve dans le handler
public class SpringLambdaHandler implements RequestStreamHandler {
private SpringBootLambdaContainerHandler handler;
private static ObjectMapper mapper = new ObjectMapper();
private Logger log = LoggerFactory.getLogger(SpringLambdaHandler.class);
@Override
public void handleRequest(InputStream inputStream, OutputStream outputStream, Context context)
throws IOException {
if (handler == null) {
try {
handler = SpringBootLambdaContainerHandler.getAwsProxyHandler(Application.class);
} catch (ContainerInitializationException e) {
e.printStackTrace();
outputStream.close();
return;
}
}
AwsProxyRequest request = mapper.readValue(inputStream, AwsProxyRequest.class);
AwsProxyResponse resp = handler.proxy(request, context);
mapper.writeValue(outputStream, resp);
}
}
Et l’extrait du pom.xml qui permet d’exclure Tomcat
Pour synthétiser, voici le schéma de l’architecture applicative de Spring implémentée dans une lambda avec une connexion à une base de données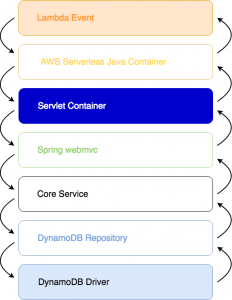
De cette manière, il est possible d’héberger une application monolithique sur le cloud AWS. Pour le déploiement, AWS propose l’utilitaire SAM qui permet de déployer des lambda assez simplement (plus simplement qu’avec CloudFormation en tout cas), et aussi de tester la stack en local. Cet article propose une implémentation pour démontrer qu’il est possible de déployer une application monolithique sur une plateforme serverless, mais n’est pas la seule architecture possible en serverless. Le choix de cette approche permet notamment de pouvoir récupérer l’existant, ainsi que d’éviter de complexifier l’architecture de l’application. Toutefois, il existe de nombreuses autres façons de concevoir une application serverless, qui seront l’occasion de publier d’autres articles.
Pour conclure, déployer une application monolithique dans une lambda fonctionne, la preuve s’il en faut est que des frameworks et/ou des librairies existent pour répondre à cette implémentation, cela permet entre autre de pouvoir reprendre un code existant. Cela permet aussi de retrouver des outils familiers des développeurs, notamment un framework comme Spring et les bonnes pratiques qui vont avec. Cela ne demande pas non plus de montée en compétences particulière. Le plus gros inconvénient à cette approche reste le temps de démarrage de la lambda. Cela sera l’occasion d’un autre article de la série sur le serverless, réflexion indispensable avant de répondre si cette idée est une bonne approche ou non.