Implémente moi un CNN
L’éco-système en Machine Learning et en particulier en Deep Learning s’est enrichi ces dernières années et les outils proposés sont de plus en plus haut niveau. Tant et si bien qu’il n’est plus toujours nécessaire d’avoir une connaissance approfondie des modèles pour mener à bien un projet de Data Science. Cette multitude de solutions a l’avantage de rendre le machine learning accessible à un plus grand nombre mais au détriment de la compréhension théorique. En effet, le Deep Learning n’est plus le domaine réservé des chercheurs comme c’était encore le cas il y a une petite dizaine d’années seulement. Cependant, bien qu’elle ne soit plus obligatoire, la connaissance théorique des modèles de réseaux de neurones est un plus dans la boîte à outils du data scientist qui lui permet d’avoir une meilleure maîtrise du sujet et une certaine indépendance par rapport aux solutions haut niveau des écuries GAFAM (acronyme pour les géants de la tech Google - Amazon - Facebook - Apple - Microsoft).
Aujourd’hui je vous propose de revenir aux racines du Deep Learning et de voir ensemble pourquoi CNN (Convolutional Neural Network) rime maintenant avec détection d’objets et classification d’images (entre autres).
Le but de cet article est de donner tous les outils nécessaires pour implémenter soi-même ses réseaux de neurones à la maison. Pour cela, j’évoquerai des notions d’algèbre linéaire et de calcul différentiel de la façon la plus pédagogique qui m’est possible.
Dans cet article nous allons avoir besoin de quelques notations mathématiques dans les équations:
Les lettres en minuscule représentent des nombres, ex: x
Les lettres en gras représentent des vecteurs, ex: x
Les lettres en majuscule représentent des matrices, ex: X
R est l’ensemble des nombres réels
Rn est l’ensemble des vecteurs de réels de taille n
Rnxm est l’ensemble des matrices réelles à n lignes et m colonnes.
Dans le texte, les variables sont representées par des lettres en gras.
Le neurone
Le Deep Learning est basé sur la notion de neurone artificiel. Il faut donc commencer par maîtriser ce concept avant de s’attaquer à des notions plus abstraites.
Un neurone artificiel est une unité de calcul qui combine des signaux en entrée pour produire un signal de sortie de plus haut niveau.
Concrètement ?
Plus simplement, représentons-nous un barrage vers lequel coulent différents tuyaux.
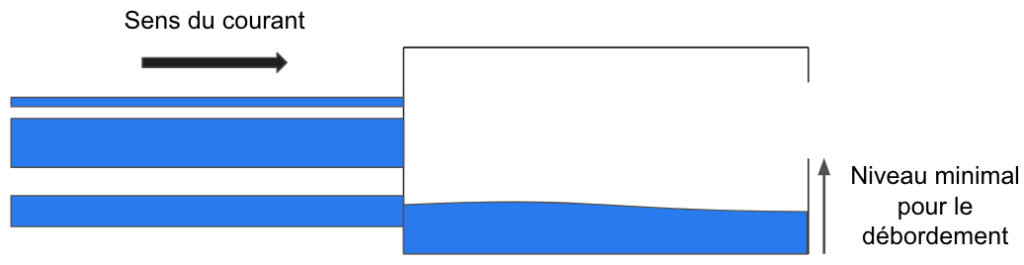
Figure 1: Schéma d’un barrage pour l’analogie avec un neurone artificiel
Notez que tous les tuyaux n’ont pas la même largeur, cela aura son importance.
L’eau va arriver dans le barrage et au-delà d’un certain niveau, le barrage va déborder et l’eau va passer dans le ruisseau suivant.
Maintenant remplacez l’eau par le mot “signal” et vous obtenez un neurone artificiel ! (On parle ici de signal au sens de la théorie de l’information de Shannon).
Un réseau de neurones est la combinaison de plusieurs milliers (voire millions) de ces neurones. Le but de l’apprentissage est de régler la taille de chaque tuyau pour que l’eau circule le mieux possible jusqu’à la fin. Plus la circonférence du tuyau est importante plus le signal qu’il transmet est essentiel à la “bonne prédiction” (nous verrons juste après ce qu’on entend par “bonne prédiction”).
Si l’on apporte un peu de formalisme mathématique, on peut représenter un neurone par la formule suivante, avec o le volume d’eau en sortie du neurone, i les volumes d’eau en entrée, w la circonférence des tuyaux et f la manière dont le neurone combine les arrivées d’eau.:
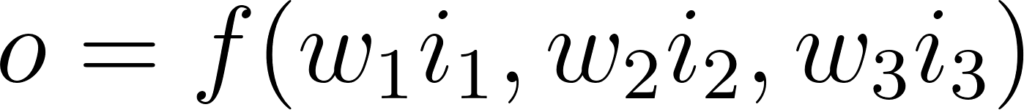
Figure 2: Formalisation d’un neurone à 3 entrées
Celle-ci ne doit pas faire peur au lecteur. Conceptuellement, il s’agit de la même chose que le dessin ! Nous apportons simplement le formalisme mathématique pour manipuler plus facilement les objets.
L’union fait la force
Pourquoi combiner des milliers de neurones ? Un seul ne suffirait pas ?
Cela dépend, premièrement avec un seul neurone il n’y a que deux options possibles: soit l’eau déborde (le neurone est suffisamment excité pour que le signal passe), soit elle ne déborde pas (les signaux d’entrée n’excitent pas suffisamment le neurone). Un unique neurone nous permet donc simplement de classer des données d’entrée en 2 catégories (présence/absence d’un objet dans une image par exemple) avec plus ou moins de certitudes (plus le volume d’eau en sortie est important, plus on est confiant sur la présence de l’objet). Pourtant on a très souvent besoin de classer des images dans de multiples catégories (par exemple le jeu de données CIFAR100 comporte 100 catégories dont chien, chat, voiture, cheval, bateau, etc…). C’est pourquoi on utilise autant de neurones en sortie d’un réseau qu’il y a de catégories.
Dans ce cas, pourquoi atteint-on des millions de neurones ? Dans l’exemple de CIFAR100 on utilise des réseaux gigantesques pour “seulement” une centaine de catégories.
C’est une excellente question qui va nous permettre de gagner un peu plus en abstraction. Les réseaux de neurones se limitent rarement à une entrée et une sortie, mais contiennent une multitude de “couches cachées”. Pour comprendre l’utilité des couches cachées, posons un problème simple: reconnaître s’il y a un chien dans une image.

Figure 3: Image de la catégorie “chien” (source GEO)
J’espère que tout le monde sera d’accord sur le fait qu’il y a effectivement un chien dans cette image. Mais comment en arrive-t-on si vite à cette conclusion ? Le cerveau humain excelle à la reconnaissance d’objets et de visages (tellement que nous en voyons là où il n’y en a pas, voir la paréidolie). Mais nous sommes bien souvent incapables de retracer notre raisonnement tant il est instinctif. Voici maintenant comment un ordinateur se représenterait la même image:
![]()
Figure 4: Représentation d’une image 8 bits en niveaux de gris comme tableau de pixels, toutes les valeurs sont des intensités de pixels entre 0 et 255 (voir cet article)
Difficile de voir le chien là-dedans…
Par contre, si nous reprenons notre comparaison du barrage, nous pouvons voir ces nombres comme des volumes d’eau en entrée. Le but de notre réseau de neurones est d’ajuster la taille des tuyaux de telle sorte que si ces nombres représentent effectivement un chien, le barrage déborde.
En théorie, il est possible de détecter la présence d’un chien dans une image avec un unique neurone. Cependant c’est extrêmement complexe, difficile à atteindre en pratique, et instable.
En effet, quand nous reconnaissons un chien, nous combinons instinctivement différentes caractéristiques de l’image qui correspondent à nos amis à quatre pattes: un museau, des oreilles, un pelage, une queue, etc… Nous hiérarchisons intuitivement différents concepts à partir d’un amas de pixels.
C’est un peu la même chose pour un réseau de neurones. Sauf que s’il ne comporte qu’un unique neurone, celui-ci doit intégrer d’un coup tous les concepts qui constituent un chien. Il doit faire cela uniquement à partir d’un tableau de nombres comme la figure 2. Cette tâche semble extrêmement compliquée, voire impossible.
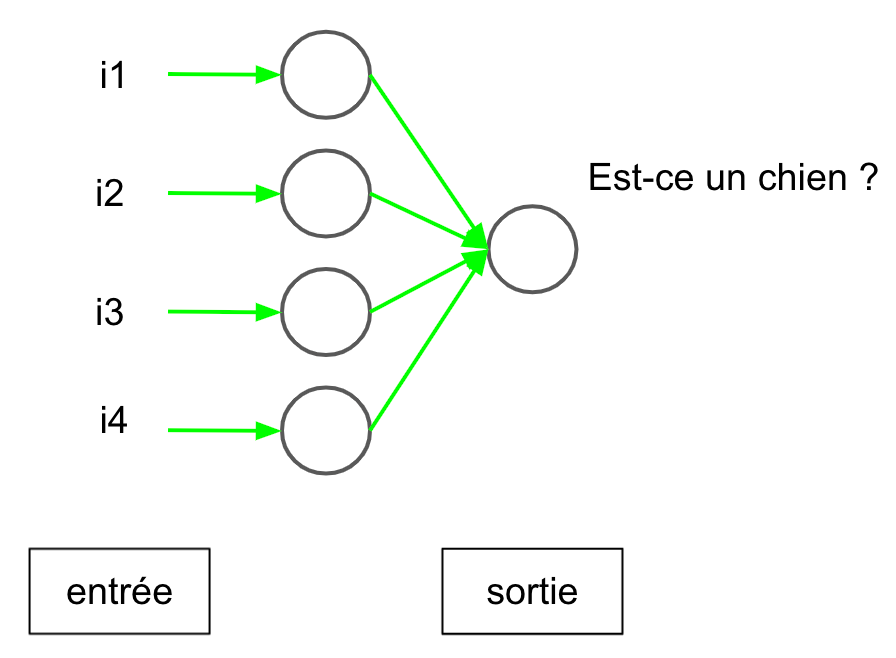
Figure 5: Schéma d’un réseau feed forward sans couche cachée
C’est pourquoi on utilise des couches cachées. Celles-ci vont permettre au réseau de neurones de hiérarchiser les concepts petit à petit, à partir du plus haut niveau d’abstraction (le tableau de nombres). Par exemple, les neurones de la première couche vont apprendre ce qu’est une ligne horizontale, une ligne verticale, une ligne diagonale (en effet ça parait évident pour un être humain mais il faut commencer par là), la couche suivante va combiner ces lignes pour apprendre ce qu’est un carré, un triangle, un cercle, et les couches suivantes vont apprendre des concepts de plus en plus concrets à partir des couches précédentes jusqu’à la dernière qui va apprendre des concepts comme “oreille”, “museau”, ou encore “pelage”, etc…
Cette décomposition hiérarchique est essentielle au Deep Learning. C’est elle qui permet de s’affranchir d’une partie du feature engineering qui devait être fait pour les modèles de machine learning classique, où le data scientist devait lui-même transformer la donnée brute pour en extraire un signal pertinent pour son modèle.
Tenue formelle exigée
Maintenant que nous avons évoqué les concepts du Deep Learning, nous allons avoir besoin d’un peu de formalisme mathématique. Il s’agit simplement d’une mise en forme des concepts que nous avons évoqués précédemment.
Nous pouvons représenter le signal de sortie d’un neurone i, que nous noterons oi, en fonction des n signaux d’entrées, que nous noterons ik, de la manière suivante:
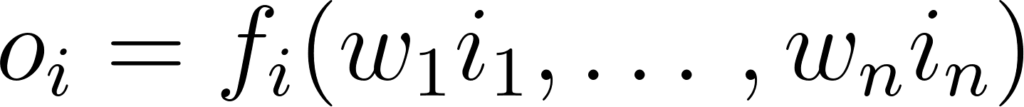
Figure 6: formalisation d’un neurone à n entrées
où fi représente la manière dont le neurone combine les signaux d’entrée. Dans le cas classique, fi va simplement multiplier chaque entrée par un poids wk (la circonférence du tuyau) et les additionner, puis appliquer un filtre: si la somme pondérée est supérieure à un certain seuil, le signal passe, sinon le neurone reste inactif.
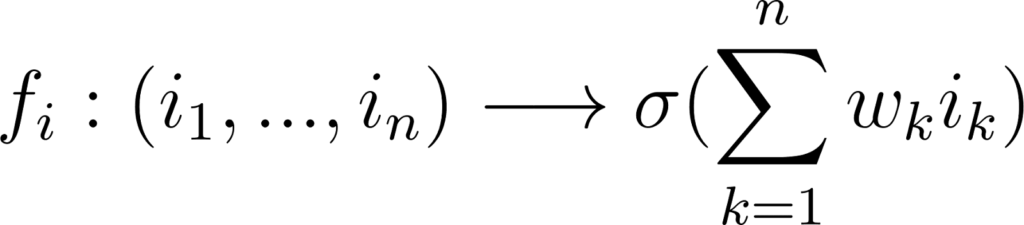
Figure 7: généralisation de la formule avec n entrées
Encore une fois, cette formule ne doit pas faire peur. C’est simplement la formalisation de ce dont nous venons de parler.
𝝈 est une fonction filtre. Ces filtres sont extrêmement importants. En fait, ce sont eux qui introduisent la non-linéarité qui fait toute la magie des réseaux de neurones et les rend capables d’approximer une très grande variété de fonctions. Sans ces filtres, la succession des couches connectées pourrait être remplacée par une couche unique et le réseau ne serait qu’une régression linéaire.
La fonction la plus fréquemment utilisée est appelée ReLU (pour Rectified Linear Unit) et ressemble à ceci:
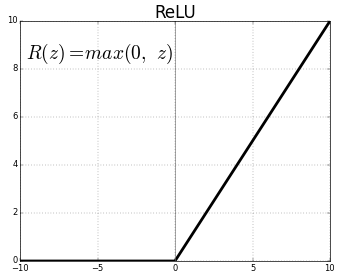
Figure 8: Courbe d’un filtre ReLU (source ICHI.PRO)
Comment interpréter cette courbe: si la somme est négative, le neurone ne s’active pas, sinon il laisse passer le signal.
C’est là que nous atteignons la limite de notre comparaison avec le barrage, car un volume d’eau négatif n’a pas de sens. Dans la réalité, les poids wk (les circonférences des tuyaux) peuvent être négatifs. En effet, ils représentent “l’importance” d’un signal pour la prédiction et il arrive qu’un signal ait une importance négative. En effet, si le but est de reconnaître un chien, la présence de moustaches de chat contribue négativement à la prédiction et donc son poids sera négatif (l’intensité de ce signal est inversement proportionnelle à la probabilité de présence d’un chien).
Si nous voulons représenter la sortie de tous les neurones d’une couche, nous obtenons ceci:
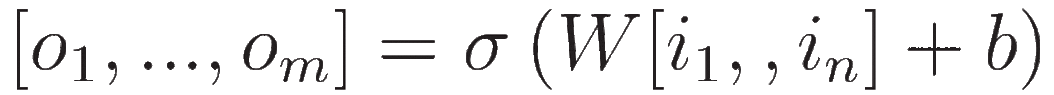
Figure 9: sortie d’une couche complètement connectée
Où W est une matrice dont chaque ligne représente les poids d’un neurone et b est une constante qui permet d’ajuster la sortie, qu’on appelle biais.
On appelle ce genre de couche, complètement connectée (en anglais, fully connected), car chaque neurone est connecté à tous les neurones de la couche précédente (tous les i). La succession de ces couches crée un réseau de neurones que l’on appelle à propagation avant (en anglais feed-forward, car l’eau ne coule que dans un sens, tout droit). On peut les schématiser ainsi:
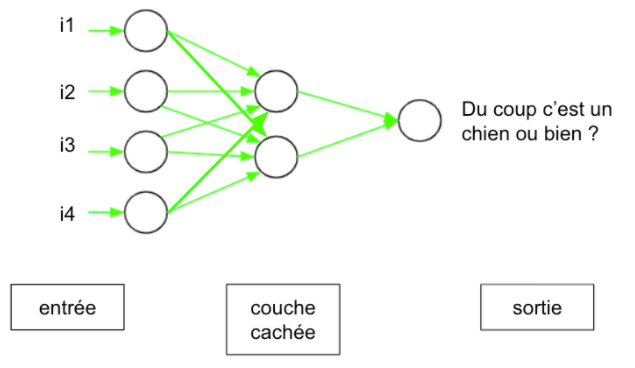
Figure 10: Schéma d’un réseau feed forward avec une couche cachée
What goes around, comes around: la rétro-propagation
Attardons-nous un peu sur ces réseaux de couches complètement connectées. Pour que l’écriture soit plus fluide et par abus de langage, je les appellerai dans la suite de l’article réseau complètement connecté, par opposition aux réseaux de convolutions (les fameux CNN) que nous verrons ensuite. Cette partie a son importance car nous allons commencer à exposer les limites des réseaux linéaires dans la reconnaissance d’image et comment les CNN les surmontent.
Nous avons vu dans la partie précédente comment un signal partait d’une image, représentée comme un tableau de nombres, pour être hiérarchisé et enrichi, jusqu’à donner une prédiction. C’est ce qu’on appelle la **propagation avant (**ou forward propagation dans la langue de Shakespeare).
Celle-ci peut être représentée ainsi pour un réseau de N couches connectées:
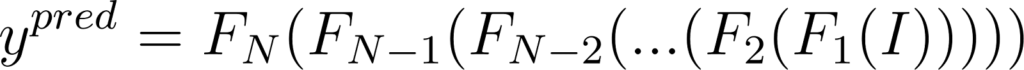
Figure 11: Expression de ypred à partir de l’entrée du réseau
On l’écrit plutôt comme suit pour alléger la notation:
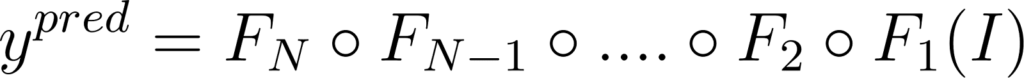
Figure 12: Expression de ypred avec la notation composition de fonctions ∘
J’ai évoqué plus haut le but de l’apprentissage qui est “d’ajuster la circonférence des tuyaux”, ou, avec le formalisme que nous avons introduit, de trouver les poids wk qui permettent de combiner les signaux de la meilleure façon. Nous allons définir dans cette partie ce qu’est “la meilleure façon”.
Le signal doit être rétro-propagé, soit aller de la sortie du réseau jusqu’à l’entrée. On peut voir cela comme une évaluation afin de permettre au réseau de s’améliorer.
Dans un premier temps, les poids sont choisis aléatoirement et le réseau propage le signal vers l’avant. On lui présente ensuite une série d’images et on lui demande si elles contiennent un chien. Comme les poids ne sont pas ajustés, il est très probable que le réseau se trompe souvent. A chaque fois qu’il se trompe, un évaluateur le lui dit, le réseau va donc ajuster ses poids afin de corriger le tir.
Cet évaluateur est ce qu’on appelle une fonction objectif. Elle attribue un score en comparant la sortie du réseau de neurone et la vérité. Dans la suite de l’article, elle sera notée L. Pour la classification d’image, on utilise fréquemment l’entropie croisée. Son expression exacte n’est pas importante à ce stade mais je la donne ici à titre d’information:
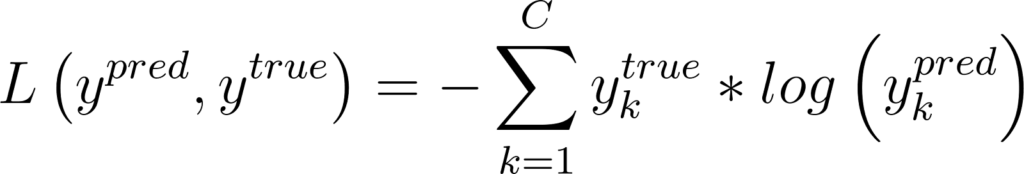
Figure 13: Expression de l’entropie croisée entre un vecteur de prédictions et le vecteur de labels
Où C est le nombre de catégories.
Echecs et maths
Je vais ici introduire le formalisme de la rétro-propagation. Cette partie nécessite de l’algèbre linéaire et du calcul différentiel. C’est la partie la plus complexe mais aussi la plus importante de cet article pour qui veut comprendre le cœur du Deep Learning.
Comme nous l’avons vu plus haut, l’idée du Deep Learning est de partir d’une unité de calcul élémentaire très simple (le neurone) et d'agréger ces unités afin de produire un modèle de plus en plus complexe. On peut dire qu’il fonctionne selon l’adage “diviser pour mieux régner”. La rétro-propagation utilise des notions d’optimisation et donc de calcul différentiel. Afin d’ajuster les poids du réseau il faut calculer leur gradient en fonction de l’objectif. Je m’explique.
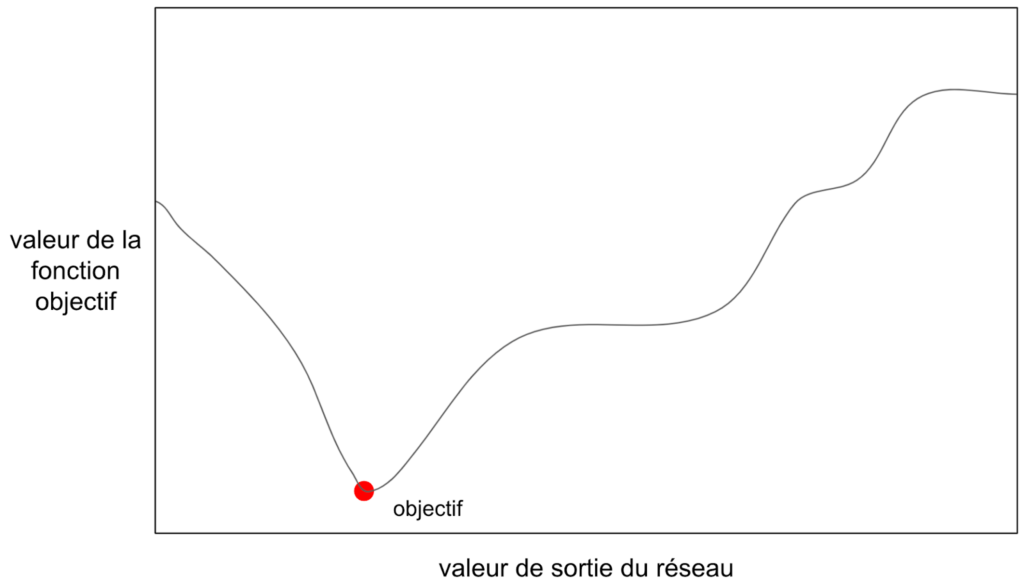
Figure 14: Courbe de la fonction objectif en fonction de la sortie du réseau
Voici une courbe qui représente notre fonction objectif. Elle représente donc en quelque sorte l’erreur de notre réseau. Notre but est de minimiser l’erreur et donc d’arriver au point rouge. À noter que pendant l’entraînement, on ne connaît rien de cette courbe. Si on pouvait évaluer toutes les valeurs de sortie possibles du réseau, on pourrait l’obtenir, mais cela nécessiterait une quantité beaucoup trop importante de calculs et le but de l’optimisation est au contraire d’arriver au point rouge avec le moins de calculs possibles. Lors de la première itération, on ne connaît que le point bleu.
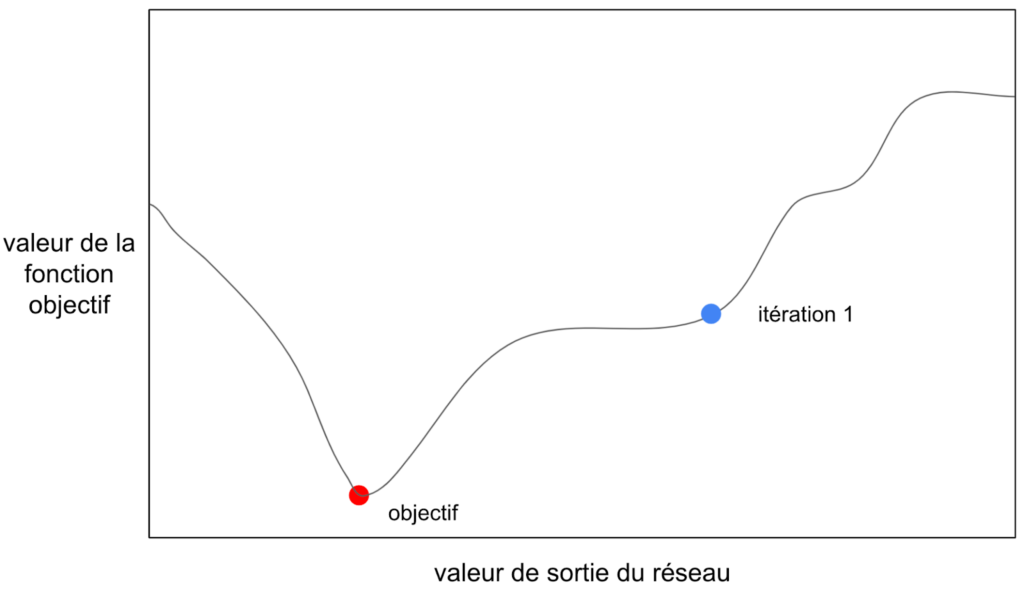
Figure 15: Courbe de la fonction objectif en fonction de la sortie du réseau, le seul point connu est le point bleu
Au début, les poids sont choisis aléatoirement et la valeur de sortie du réseau est loin de l’objectif.
Pour se rapprocher le plus vite possible du minimum, il faut déterminer le sens dans lequel on doit aller. Pour cela on doit répondre à la question “Comment évolue ma performance si je change mes poids ?”. Si j’ajoute 1 à mon poids, quelle est l’influence sur la performance ? Et si j’enlève 1 ? Ou 10 ? Ou 34,875 ?
C’est cela un gradient, un ratio qui permet d’évaluer l’évolution d’une variable en fonction d’une autre. C’est l’extension en plusieurs dimensions de la notion de dérivée qu’on voit au lycée. On l’écrit ainsi:
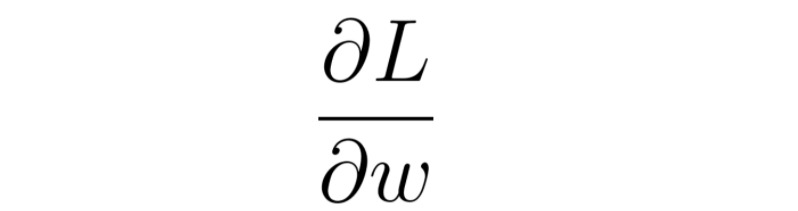
Figure 16: Notation de la dérivée partielle de la fonction objectif par rapport à un poids du réseau
Comment le lire: gradient de L par rapport à w. (NDA: pour être rigoureux il s’agit ici d’une dérivée partielle. Dans le cadre de cet article je ne rentrerai pas dans les détails, on peut confondre les deux notions).
En l'occurrence le gradient est un vecteur et voici sa représentation:
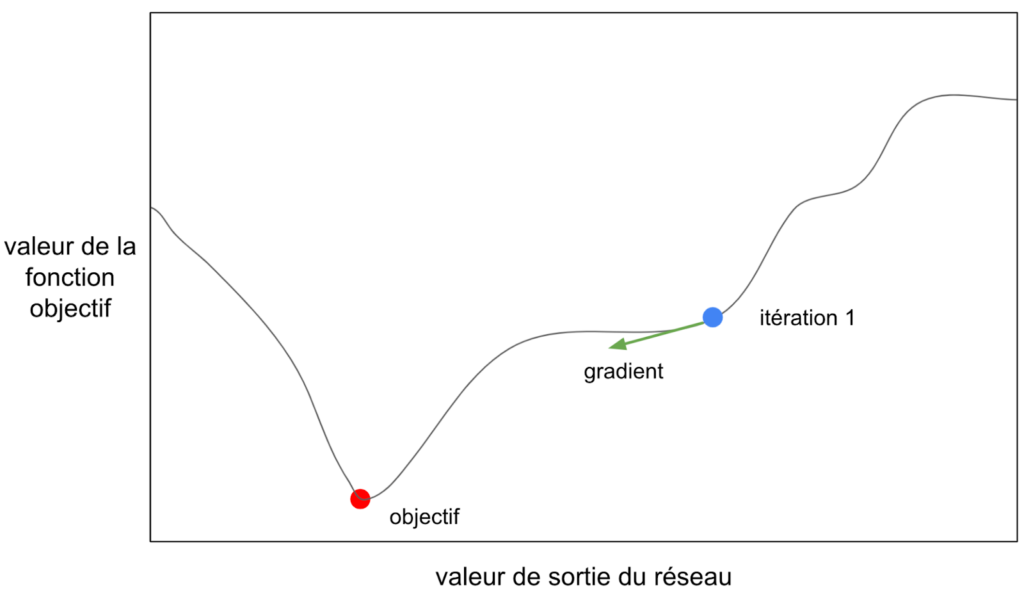
Figure 17: Représentation du gradient à l’itération 1
Grâce à ce gradient on va pouvoir changer le poids pour s’approcher de l’objectif. On va appliquer un schéma d’optimisation:
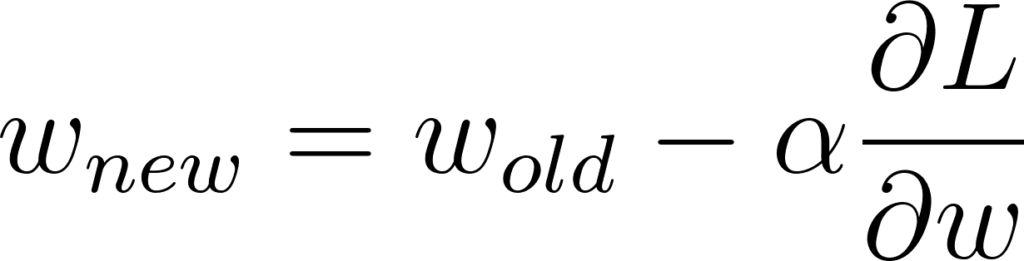
Figure 18: Descente de gradient d’ordre 1
Si vous avez déjà manipulé des librairies comme PyTorch ou TensorFlow vous avez dû voir passer les termes RMSProp, SGD, ou Adam. Ce sont en fait différents schémas d’optimisation. Ici j’ai noté le plus simple, SGD (NDA: les puristes pourraient me reprocher qu’il n’y pas de notion de stochasticité ici. C’est vrai qu’il y a dans SGD la notion d’espérance de la fonction objectif que je n’ai pas abordée ici pour ne pas alourdir le discours).
On pourrait se dire qu’il suffirait de calculer le gradient de par rapport à tous les poids du réseau de neurones. Effectivement, cela marcherait théoriquement mais dans les faits les calculs seraient extrêmement lourds. L’idée fondatrice du Deep Learning est d’utiliser le gradient chaîné. Par exemple imaginons:
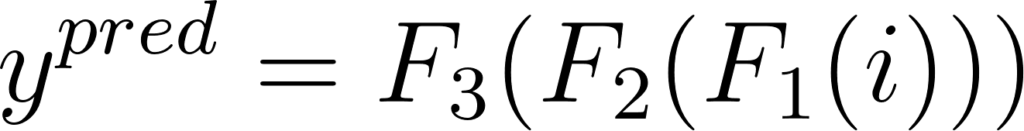
Figure 19: Expression de la succession de trois couches
On définit également ytrue comme le vrai label de i. Dans l’idéal, ytrue=ypred.
On va noter W les poids de F3, G les poids de F2 et P les poids de F1. La fonction objectif est L telle que le score soit:
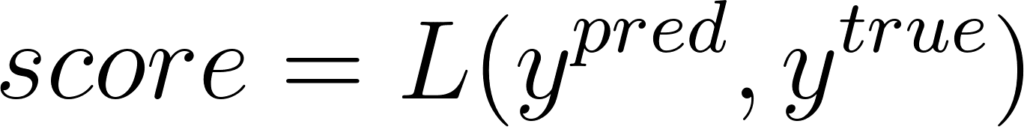
Figure 20: Expression du score de la prédiction
Alors pour optimiser pi on doit calculer:
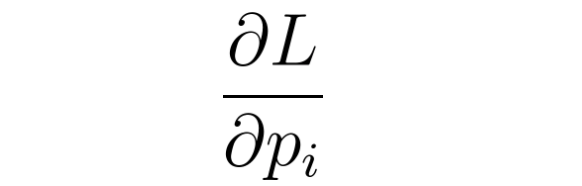
Figure 21: Dérivée partielle de la fonction objectif par rapport à un poids de la couch
Sauf que l’expression de L en fonction de pi peut être compliquée. Or la règle du gradient chaîné dit que:
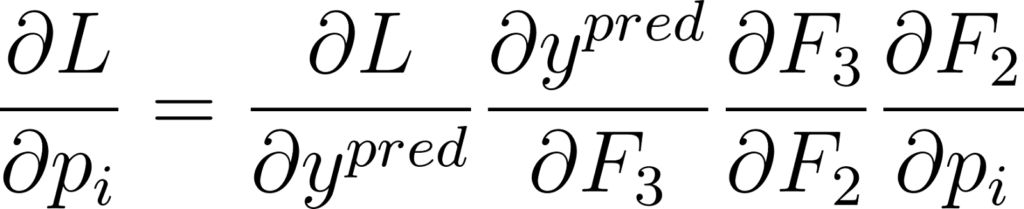
Figure 22: Application du gradient chaîné à un réseau à 3 couches
Ce qui simplifie énormément le calcul. On peut commencer par calculer le premier terme, puis le second, etc… La règle du gradient chaîné justifie le nom rétro-propagation: on propage les gradients dans le sens inverse du signal.
Application aux couches complètement connectées
Je détaille les calculs de cette partie dans l’annexe.
Dans le cas d’une couche complètement connectée nous devons trouver les gradients des poids W et des biais b afin de les ajuster:
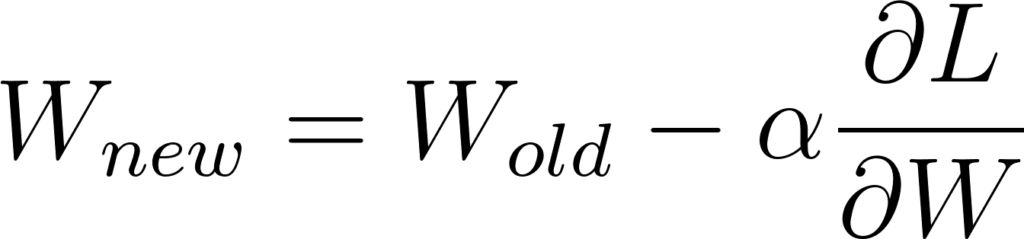
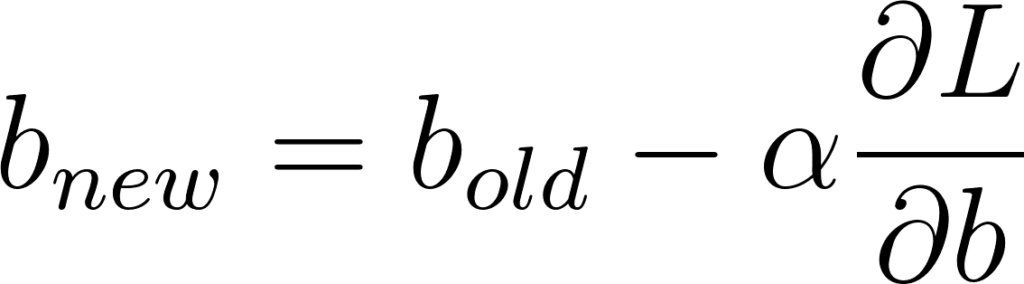
Figure 23: SGD appliqué à la matrice de poids et au vecteur de biais
Avec les calculs en annexe on trouve:
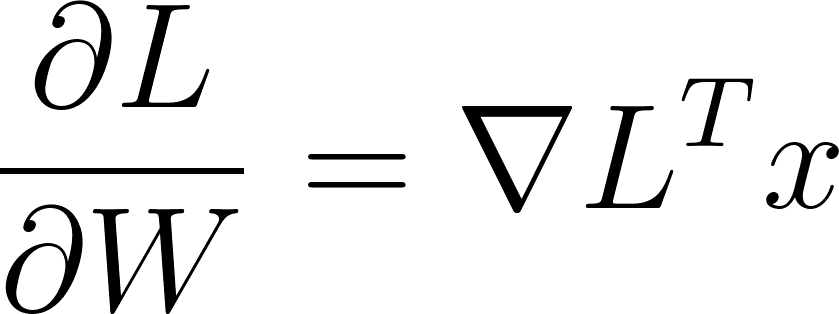
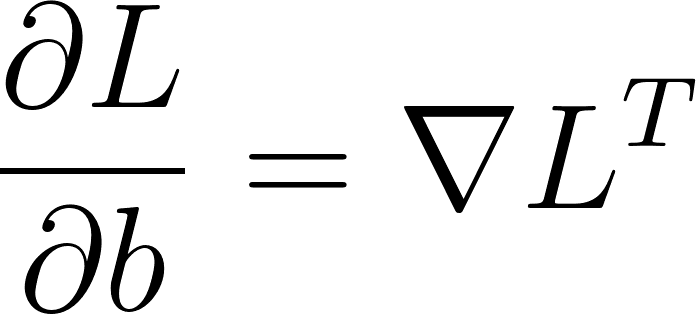
Figure 24: Expression des dérivées partielles en fonction du gradient rétro-propagé
Où ∇L est le gradient rétro-propagé et x sont les entrées de la couche.
Connecté mais plus branché
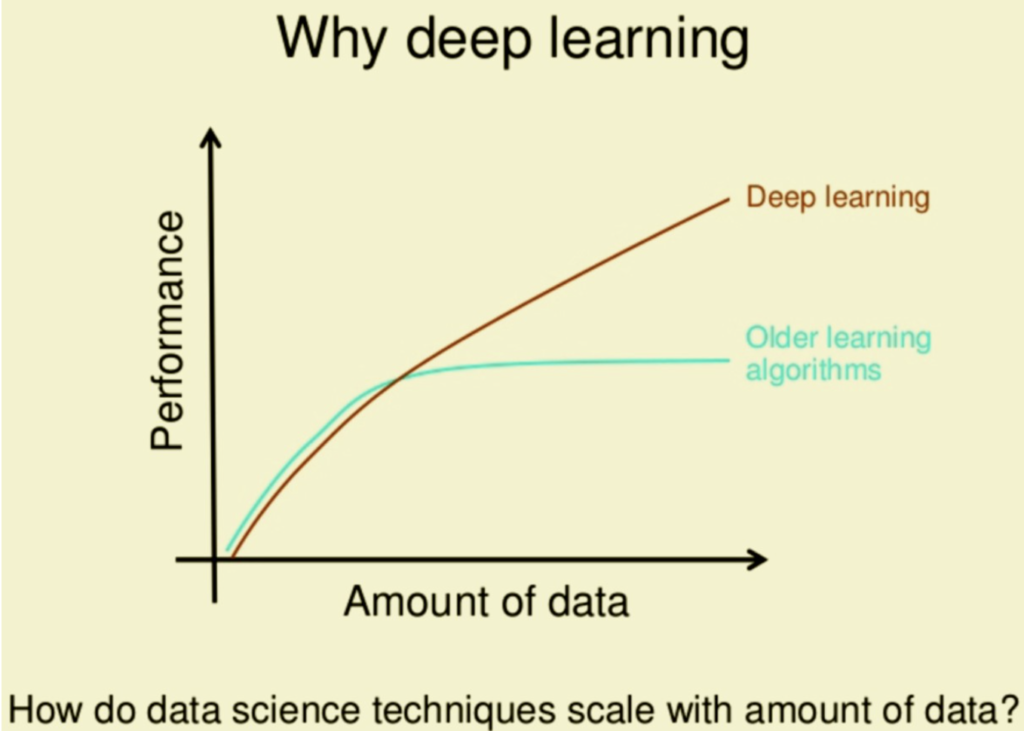
Figure 25: Advantages of deep learning over traditional machine learning
Dans les années 2000, l’augmentation de la puissance de calcul et l’accessibilité à de très gros volumes de données ont contribué à la popularité des réseaux linéaires. Cependant on peut leur adresser quelques critiques, en particulier en vision, qui ont expliqué leur déclin au profit des CNN.
Premièrement, ils ont beaucoup de paramètres qu’il faut entraîner. Cela demande une grosse puissance de calcul. L’utilisation de machines de plus en plus performantes et en particulier des GPU a permis de pallier ce problème mais on est en droit de se poser la question de leur optimalité.
Deuxièmement, quand on les applique aux images, les réseaux linéaires montrent très vite leurs limites. Ils sont bien adaptés pour traiter des données tabulaires structurées mais les images sont des données non structurées. Pour qu’un réseau complètement connecté traite une image il faut commencer par "aplatir" celle-ci, c'est-à-dire transformer le tableau de nombres en 2 dimensions en un vecteur en 1 dimension. Cela permet de combiner les pixels de toute l’image. Mais quelques illustrations valent mieux qu’un long discours.
Imaginons une petite image 4x4 et une matrice de poids d’une couche linéaire de la même taille:
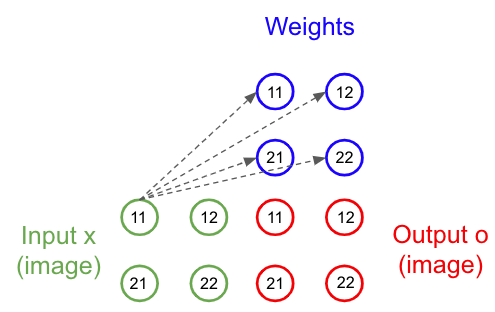
Figure 26: Schéma d’une couche linéaire appliquée à une image en deux dimensions
Au niveau purement mathématique, le calcul fonctionne, on peut faire le produit matriciel entre l’image et les poids. Cependant si on y regarde de plus près quelque chose ne fonctionne pas.
En effet, o11 et o12 ne prennent en compte que la première ligne de l’image, et o21 et o22 que la deuxième. Or l’intérêt d’une couche connectée est de connecter tous les neurones de la couche précédente à chaque neurone de la couche suivante. Ce n’est pas le cas ici, on ne traite l’image que ligne par ligne, or même si elle peut contenir du signal, il se passe assez peu de choses dans une seule ligne de pixels....
Pour appliquer une couche connectée à une image, il faut donc la mettre en une seule dimension (dans certaines librairies on trouve une fonction Flatten pour cela).

Figure 27: Schéma d’une couche linéaire appliquée à une image “aplatie”
Avec cette petite manipulation, la couche relie bien tous les pixels de l’image aux neurones suivants. Ici on ne représente qu’une seule colonne de la matrice de poids mais dans la réalité il y en a beaucoup plus.
Pour résumer, chaque colonne de la matrice de poids représente un filtre. Par exemple, une colonne peut détecter les lignes verticales, une autre les lignes horizontales, etc… Nous verrons cette notion de filtre plus en détail avec les CNN.
Les réseaux linéaires peuvent donc être utilisés sur des images moyennant une petite manipulation.
Mais est-il vraiment nécessaire de prendre en compte tous les pixels de l’image pour chaque neurone de sortie ? La structure des couches connectées nous y force mais cela semble être un gâchis de ressources. En effet, un pixel est très corrélé aux pixels voisins, mais peu à ceux de l’autre bout de l’image.
![]()
Figure 28: Illustration de l’utilité des pixels en fonction de leur distance à la zone d’intérêt (source GEO)
Sur l’image ci-dessus vous n’avez besoin que de regarder une petite zone pour reconnaître l’oreille, mais le reste de l’image (par exemple l’herbe) ne vous sert à rien. Or une couche connectée va “regarder” toute l’image pour chaque détection. Elle va donc non seulement perdre du temps mais également de la mémoire (beaucoup des poids sont inutiles, dans l’exemple ci-dessus, les poids associés aux pixels de l’herbe vont être quasiment nuls, ils risquent même d’introduire des erreurs).
Ainsi même s’ils en sont capables, les réseaux linéaires ne sont pas bien adaptés au traitement d’images. L’histoire aurait pu s’arrêter là et l’humanité aurait continué à chercher désespérément du signal dans des brins d’herbe pour reconnaître les oreilles d’un chien, mais une solution est arrivée au début des années 2010.
Trêve de circonvolutions
Lors du challenge de reconnaissance d’images sur le jeu ImageNet en 2012, AlexNet a dominé la compétition. AlexNet est l’un des premiers CNN entraîné sur GPU, il ne comportait “que” 5 couches de convolution. Depuis, la puissance de calcul et les améliorations d’architecture permettent d’entraîner des modèles comme ResNet avec plus d’une centaine de couches, mais le cœur de ces architectures, la couche de convolution, est resté le même (du moins conceptuellement).
La couche de convolution apporte une réponse élégante aux limitations de la couche connectée que nous avons vu précédemment. Elle ne nécessite plus d'aplatir l’image, et elle ne considère plus toute l’image à chaque fois. L’idée fondamentale est d’utiliser de petits filtres (qu’on appelle souvent kernel) pour la détection, et de les réutiliser sur toute l’image. Là où la couche connectée apprend d’immenses filtres (de la taille de l’image d’entrée) complexes et qui mêlent plusieurs concepts, la couche de convolution apprend de tous petits filtres (on choisit souvent 3x3) spécialisés sur un seul concept et les fait “glisser” sur l’image.
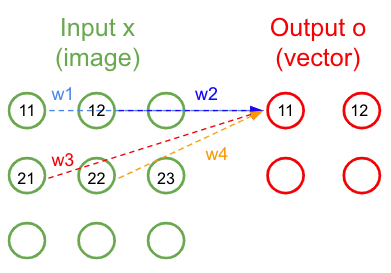
Figure 29: Schéma d’un kernel 2x2 appliqué à un patch 2x2 de l’image
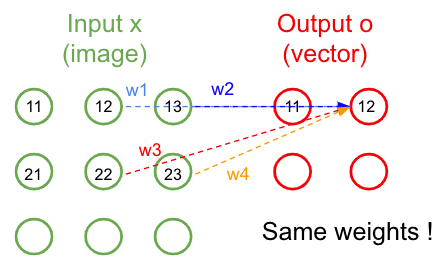
Figure 30: Schéma du même kernel 2x2 appliqué au patch voisin de l’image
De cette façon, les poids sont partagés et on ne s’intéresse qu’aux pixels voisins.
On gagne ainsi la propriété d’invariance à la translation (en anglais shift invariance). Si on translate un objet dans une image, une couche connectée doit ré-apprendre les filtres, alors qu’une couche de convolution fait juste glisser son filtre déjà prêt.
Encore une fois, une image vaut mieux qu’un discours:
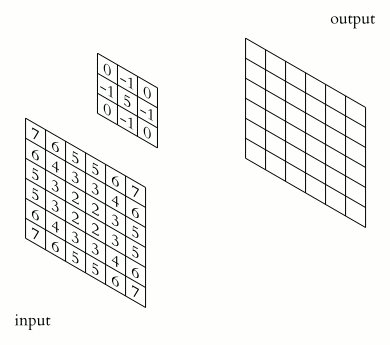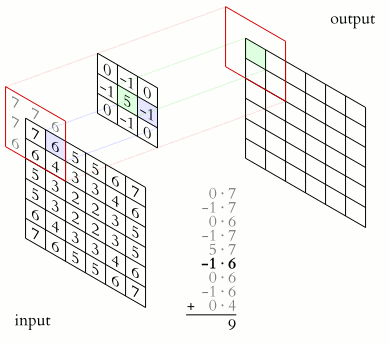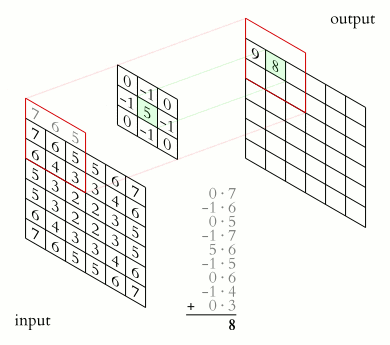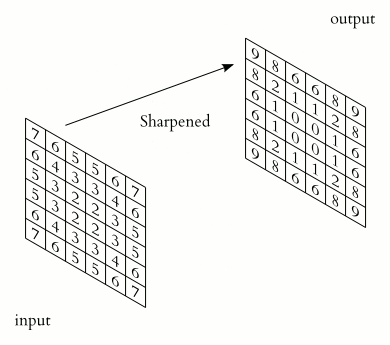
Figure 31: Illustration d’un kernel 3x3 qui “glisse” sur une image (source TowardsDataScience)
Lors de la propagation avant le filtre “glisse” sur l’image et ne considère que les pixels voisins.
Et la formalisation d’une couche de convolution est la suivante:
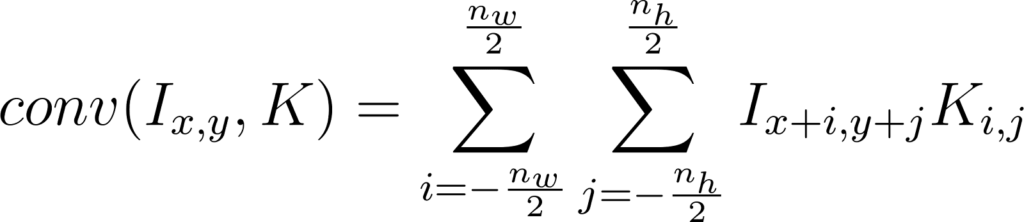
Figure 32: Expression du pixel de sortie (x,y) d’une couche de convolution en fonction de l’image et du kernel
Où K est un kernel, et I l’image d’entrée sous forme de tableau de nombres en 2 dimensions, nw est la largeur de l’image, nh est la hauteur de l’image, et le couple x et y les coordonnées d’un pixel.
Une convolution peut en cacher une autre
Je détaille les calculs de cette partie dans l’annexe.
Qui veut implémenter son propre CNN en kit à monter chez soi doit comprendre la théorie qu’il y a derrière. Je vais reprendre le schéma simple avec une image 3x3 et un kernel 2x2
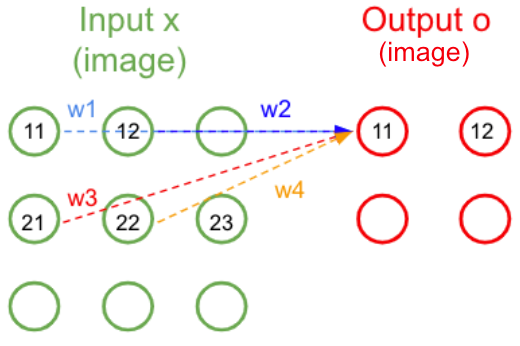
Figure 33: Schéma d’un kernel 2x2 appliqué à une image 3x3
Dans ce cas, la propagation avant se formalise comme ceci:
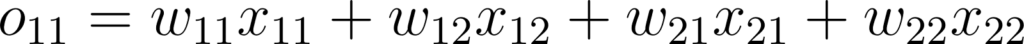
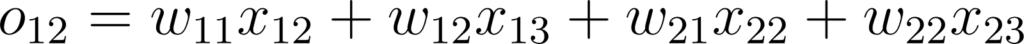
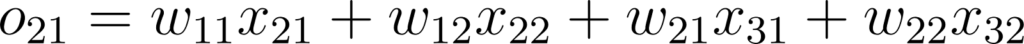
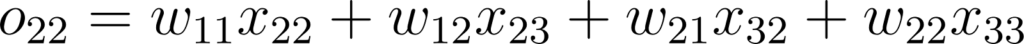
Figure 34: Expression des valeurs de sortie d’une couche de convolution 2x2
La rétro-propagation est également une convolution ! Pour le détail du calcul je vous donne rendez-vous en annexe mais on obtient ceci:
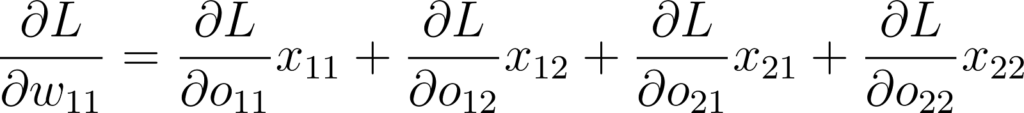
Figure 35: Expression de la dérivée partielle d’un poids du kernel
Qu’on peut schématiser de cette façon:
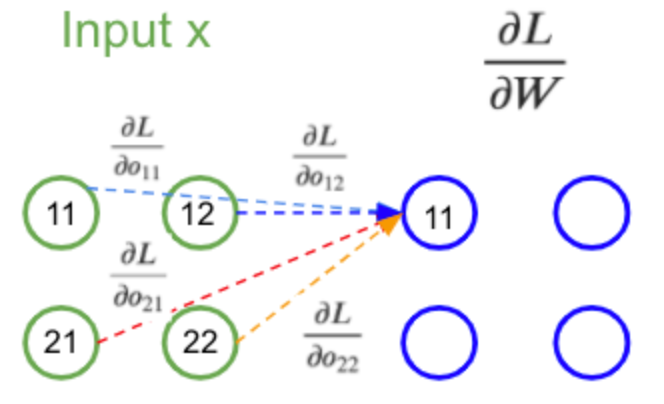
Figure 36: Schéma du calcul de la dérivée partielle du kernel pendant la rétro-propagation
Il s’agit du même calcul que la propagation avant, excepté les poids du filtre qui sont cette fois ci égaux aux dérivées partielles rétro-propagées.
Output
Merci d'avoir lu cet article ! Nous avons commencé par revoir les notions élémentaires du Deep Learning, puis nous avons expliqué les différents problèmes et limitations qui ont mené à la création des CNNs. Il était nécessaire de s'arrêter un moment sur les réseaux de couches complètement connectées afin d'exposer leurs limites pour mettre en valeur les forces des CNNs. Nous avons vu que la structure des couches de convolutions les rend particulièrement adaptées au traitement d'images.
Cependant les filtres d'une couche de convolution vont passer sur toute l'image pour reconnaître un objet, alors qu'un humain se concentre naturellement sur celui-ci et ignore le reste. Cela peut être problématique si l'objet est petit et que l'image contient beaucoup d'informations qui risquent de perturber le réseau (essayer d'entraîner un CNN sur mécanismes d'attention répondent à ce problème et permettent aux CNNs de se focaliser sur les parties les plus importantes d'une image et ainsi d'améliorer leurs performances.
Vous avez maintenant toutes les clés pour implémenter vous-mêmes un réseau de neurones dans le langage de votre choix. Je n'ai volontairement pas présenté ma propre implémentation dans le corps de l'article afin d'être agnostique au langage de programmation, mais vous pouvez trouver mon implémentation complète en Python ici. Vous trouverez les détails des calculs en annexe ainsi que des exemples d'implémentations pour les différentes couches dont nous avons parlé.
Dans un prochain article, je parlerai des filtres d’une couche linéaire et d’une couche de convolution et je comparerai les implémentations et performances (en entraînement et inférence) des deux librairies les plus populaires du marché: PyTorch et TensorFlow. Nous reviendrons également sur les mécanismes d'attention.
Annexe
Dans cette partie je vais rentrer en profondeur dans les notions mathématiques abordées dans l’article et je vais détailler les calculs.
Ces notions ne sont pas nécessaires pour utiliser des réseaux de neurones et des librairies telles que PyTorch ou TensorFlow. Cependant, elles sont utiles pour comprendre ce qui se passe réellement sous le capot d’un réseau de neurones.
Le gradient chaîné
La base du Machine Learning est d’optimiser les paramètres d’un modèle afin de minimiser une fonction de coût (ou maximiser une fonction objectif). Imaginons un réseau de neurones à 3 couches F1, F2 et F3, dont les paramètres sont respectivement P1, P2, et P3. La succession des 3 couches F3 ∘ F2 ∘ F1 est notée F. L’objectif est de minimiser une fonction de coût L. Notons y les labels des échantillons et X les données. Alors le but de l’apprentissage est:
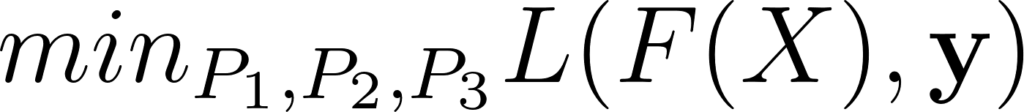
Annexe 1: Problème d’optimisation d’un réseau à 3 couches
Alors nous voulons calculer:
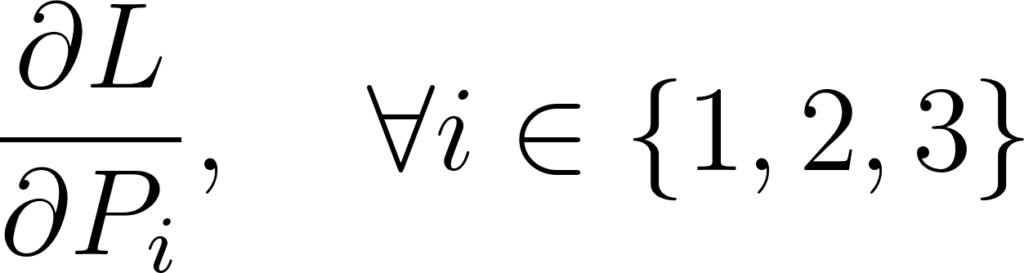
Annexe 2: Dérivées partielles des poids des couches
Il n’y a pas de forme fermée pour résoudre le problème (comme l’équation normale pour une régression linéaire), sauf dans de très rares exceptions. C’est pourquoi nous utilisons une méthode d’optimisation itérative comme une descente de gradient.
De même, il est impossible de faire le calcul du gradient sur tout le dataset d’entrée (sauf très petits volumes de données). C’est pourquoi nous utilisons des batchs. L’hypothèse nécessaire est que les échantillons dans les batchs soient iid, il faut donc choisir aléatoirement les échantillons dans le dataset afin que les propriétés statistiques du batch soient aussi proches que possible de celles du dataset entier. Cela est dû au fait qu’on ne fait pas réellement une descente de gradient mais une descente de gradient stochastique (le S de SGD).
La règle du gradient chaîné spécifie:
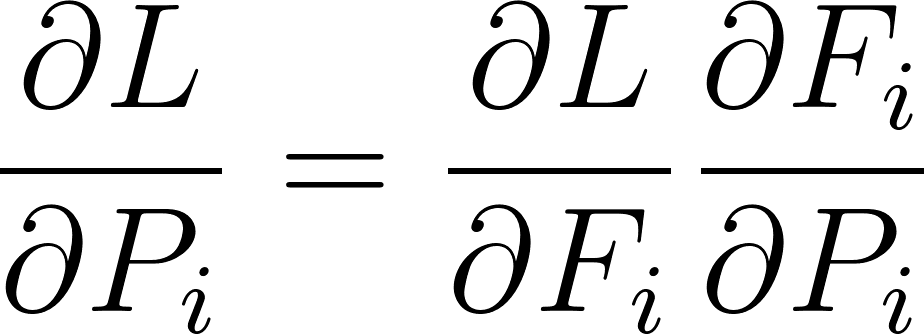
Annexe 3: Gradient chaîné appliqué aux poids
Ce qui veut dire qu’on a besoin du gradient de la couche suivante pour calculer le gradient de la couche courante. Les gradients sont propagés à l’envers d’où le nom rétro-propagation.
Dans notre cas ∂L/∂Fi est le gradient rétro-propagé et ∂Fi/∂Pi est le gradient local de la couche. La règle du gradient chaîné permet de diviser le calcul d’un gradient global en de multiples calculs de gradients locaux, ce qui est bien plus simple.
Calcul différentiel
Comme nous l’avons vu, la base du Deep Learning est de calculer le minimum d’une fonction. Pour cela on utilise les dérivées partielles de cette fonction par rapport à chaque paramètre du modèle. Il est possible de calculer les dérivées partielles de notre fonction coût L par rapport à chaque poids pris individuellement p. Cependant on peut calculer directement la dérivée par rapport à la matrice de poids P.
Considérons une fonction:
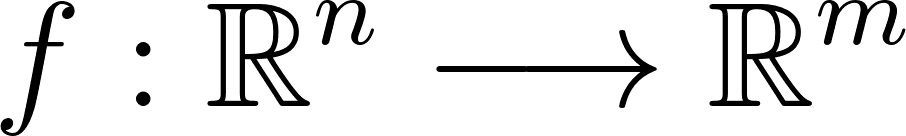
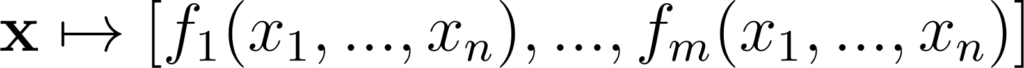
Annexe 4: Fonction d’un espace de n dimensions dans un espace de m dimensions
On pourrait calculer la dérivée de f par rapport à chaque élément xi mais ce serait lent. Nous allons plutôt calculer sous forme matricielle. L’élément de base des dérivées matricielles est la Jacobienne:
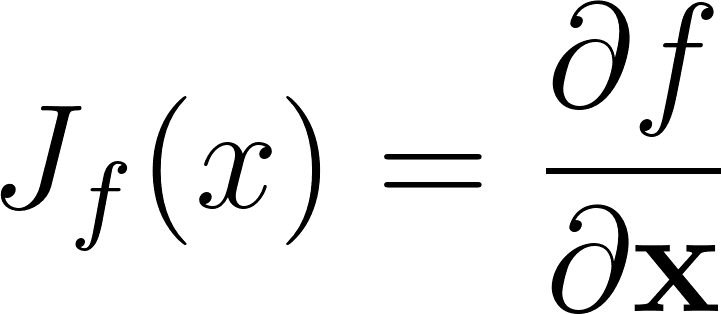
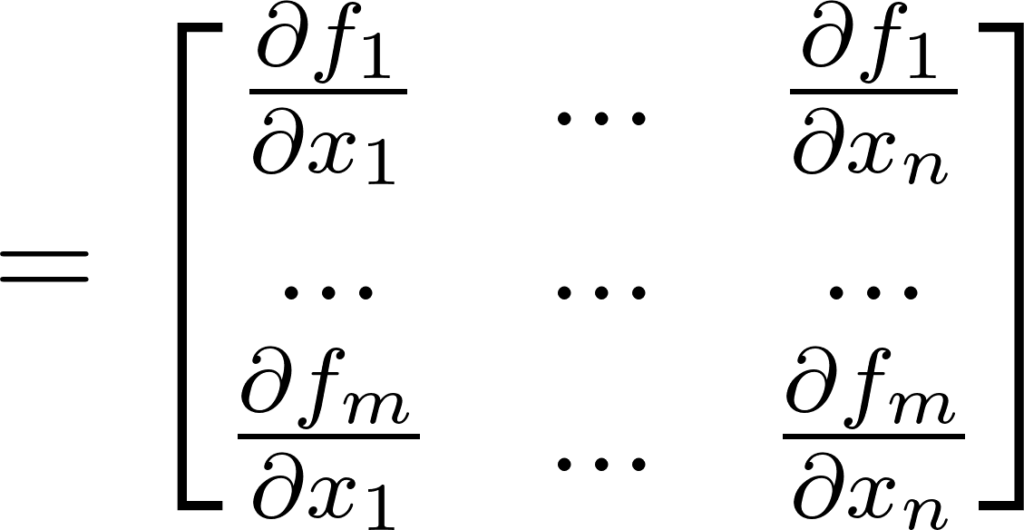
Annexe 5: Matrice Jacobienne de la fonction f
Le nombre de lignes de la Jacobienne est égale à la dimension de l’espace de sortie, le nombre de colonnes est égale à la dimension de l’espace d’entrée. Dans ce cas c’est donc Rmxn.
Pour une fonction g : x ⟼ g∘f(x), on a:
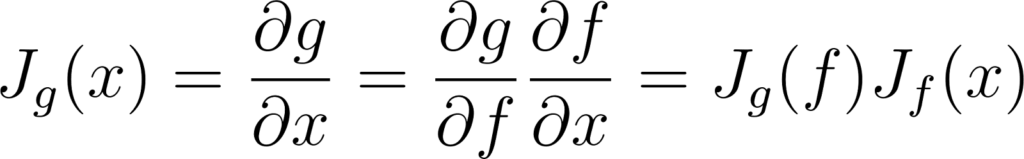
Annexe 6: Décomposition de la matrice Jacobienne d’une fonction conjuguée
L’application du gradient chaîné revient donc à multiplier les Jacobiennes.
Les tenseurs
Dans la réalité, ni les Jacobiennes, ni les matrices de poids des couches ne sont réellement des matrices, ce sont des tenseurs. Les tenseurs sont la généralisation des matrices au-delà de 2 dimensions. Par exemple, une image n’est pas vraiment représentée comme un tableau de nombres. En effet, il y a 3 canaux, rouge, bleu, et vert, dans une image. Elle est donc représentée par un cube, soit un élément de Rnxmx3.

Annexe 7: Décomposition de l’image du chien selon les 3 canaux RGB (source GEO)
L’entraînement d’un réseau de neurones est en fait un calcul de produits tensoriels (extension du produit matriciel) qui “coulent” dans le sens inverse du signal. C’est probablement là l’origine du nom de la librairie TensorFlow.
Détails du calcul pour une couche complètement connectée
- Propagation avant
La propagation avant d’un signal contenu dans un vecteur est la suivante:
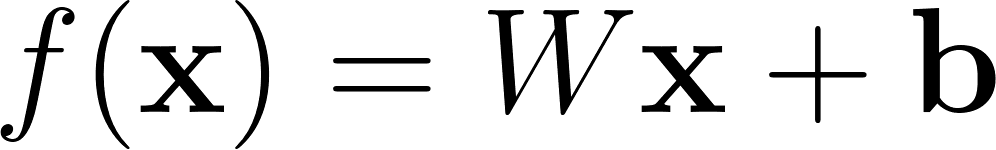
Annexe 8: Propagation avant d’une couche complètement connectée
Voici une implémentation possible:

Annexe 9: Implémentation de la propagation avant d’une couche complètement connectée
L’entrée x est gardée en mémoire car elle est nécessaire pendant la rétro-propagation.
- Rétro-propagation
Une couche complètement connectée comporte deux paramètres W et b, on doit donc calculer ∂L/∂W et ∂L/∂b.
Selon le gradient chaîné:
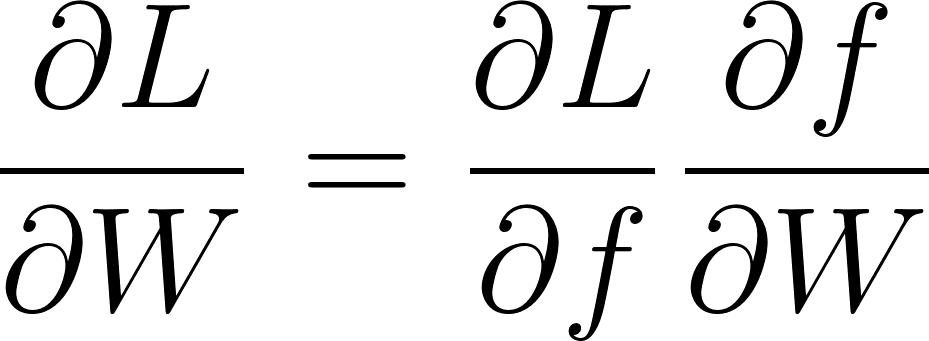
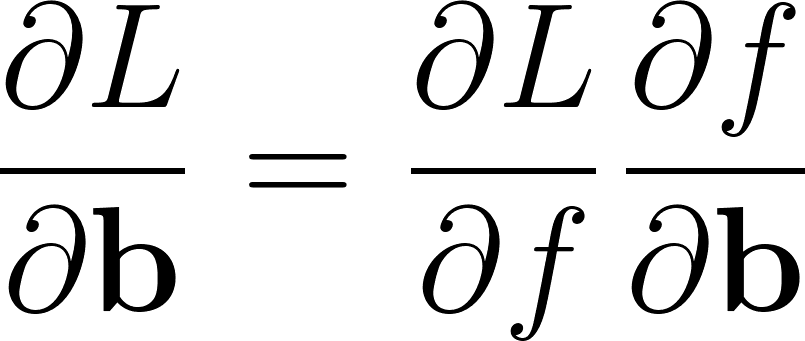
Annexe 10: Application du gradient chaîné aux paramètres d’une couche complètement connectée
∂L/∂f est rétro-propagé par la couche suivante.
Premièrement, nous allons factoriser les optimisations des deux paramètres en une seule. On ajoute un 1 à la fin de x, qu’on notera maintenant x* et on ajoute une colonne à W qui est égale à b, on notera la nouvelle matrice W*. On peut donc réécrire f:
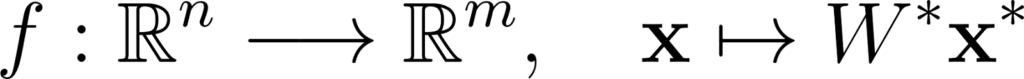
Annexe 11: Factorisation d’une couche complètement connectée à un seul paramètre
Si l’on veut maintenant calculer la dérivée partielle par rapport à ce nouveau paramètre factorisé, on considère f comme une fonction de R(n+1)xm dans Rm. La Jacobienne sera donc de dimension Rmx****(n+1)xm, c’est donc un tenseur d’ordre 3.
On calcule la dérivée élément par élément afin de se représenter le calcul. Considérons d’abord la fonction:
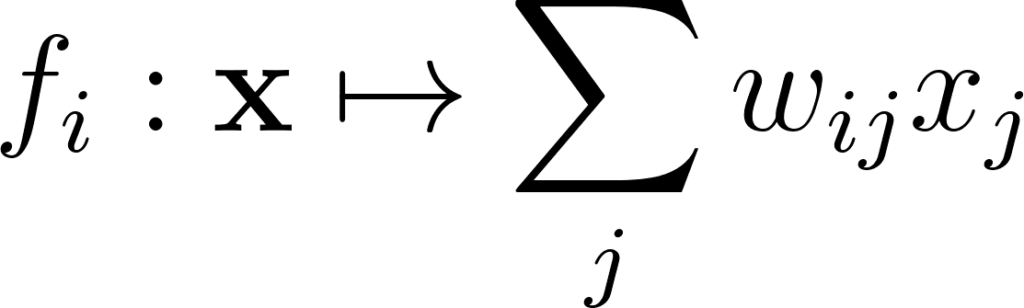
Annexe 12: Fonction de la somme pondérée des entrées d’une couche
Qui est un élément de la matrice f(x). Considérons aussi un poids wkl.
Pour ce calcul, nous allons avoir besoin du symbole de kronecker. Celui-ci est défini comme ceci:
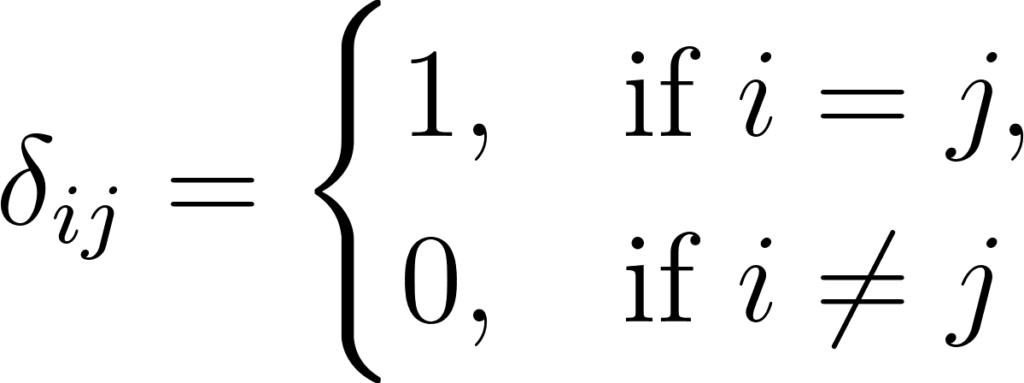
Annexe 13: Définition du symbole de kronecker
Alors:
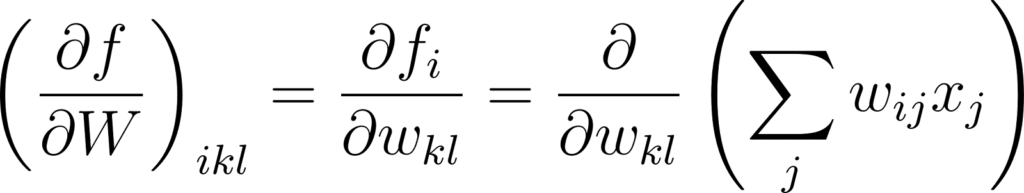
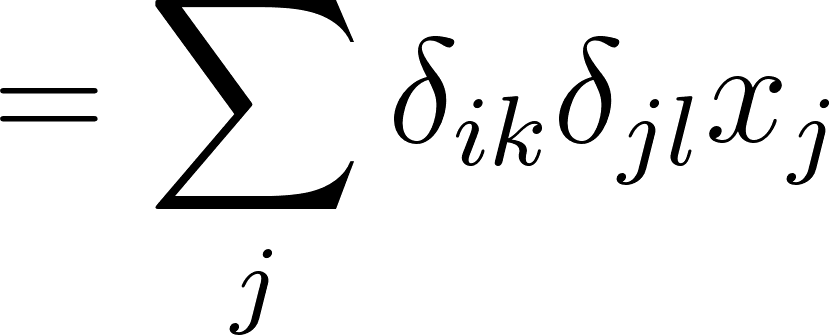
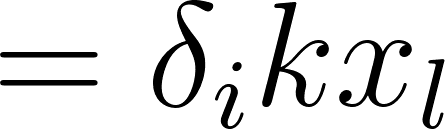
Annexe 14: Dérivée partielle d’un élément de la matrice de poids d’une couche complètement connectée
À partir de cette formule, on peut déduire la représentation de la Jacobienne. C’est un cube dont chaque couche est une matrice diagonale égale à un élément de x:
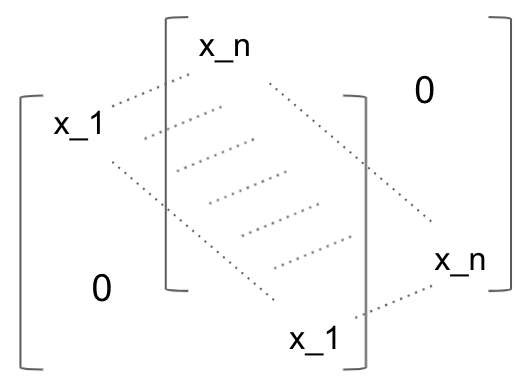
Annexe 15: Schéma de la matrice Jacobienne d’une couche complètement connectée
On peut donc calculer les éléments de qui est un tenseur d’ordre 4:
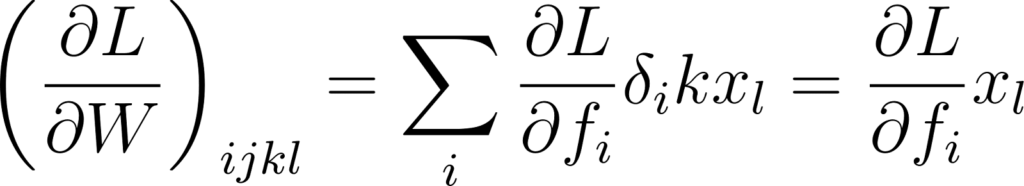
Annexe 16: Dérivée partielle de la fonction objectif par rapport à la matrice de poids d’une couche complètement connectée
On peut représenter cela de façon matricielle, il s’agit du produit scalaire entre le gradient rétro-propagé ∂L/∂f et l’input x de la couche:
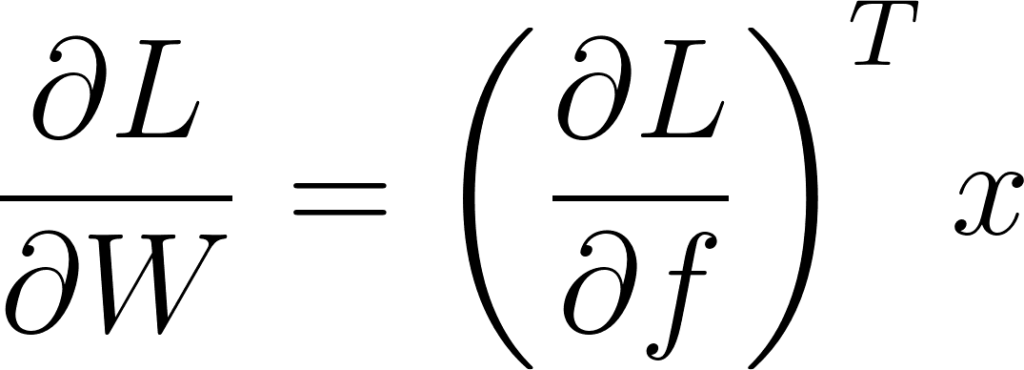
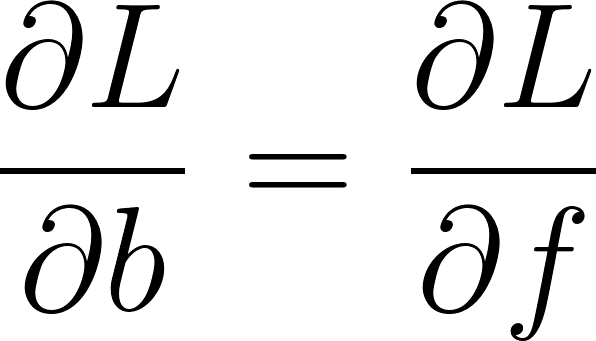
Annexe 17: Expression des dérivées partielles de la fonction objectif en fonction des paramètres d’une couche complètement connectée
Voici une implémentation possible:
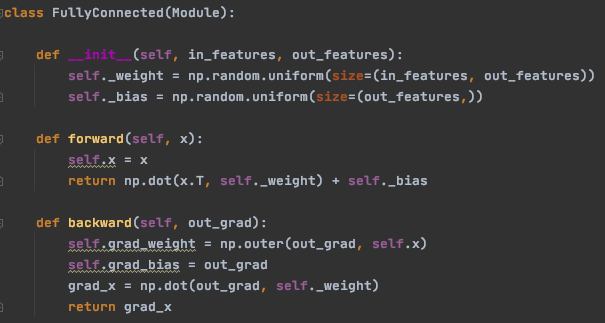
Annexe 18: Implémentation de la rétro-propagation d’une couche complètement connectée
La rétro-propagation doit retourner le gradient rétro-propagé pour que les couches précédentes puissent l’utiliser à leurs tours.
Détails du calcul pour une couche de convolution
- Propagation avant
L’entrée d’une couche de convolution est une matrice X (ou un tenseur), et la sortie est une matrice O (ou un tenseur). Les paramètres sont un ou plusieurs kernels. Dans un soucis de simplicité, considérons ici un unique kernel K, de taille 2x2. Le premier élément de O est donc:
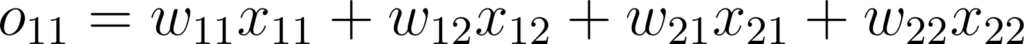
Dans le cas général on peut écrire:
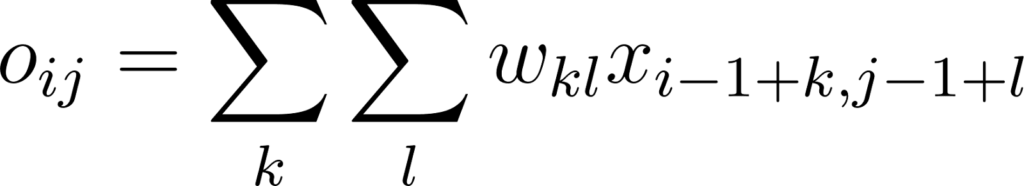
Annexe 19: Expression d’une sortie d’une couche de convolution sous forme de somme
On peut le voir comme le produit scalaire entre le kernel vectorisé W ∈ Rk×l et le voisinage du pixel de coordonnées (i, j) vectorisé x ∈ Rk×l:
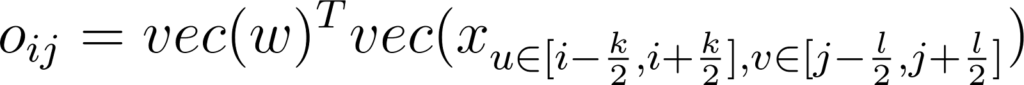
Annexe 20: Expression d’une sortie d’une couche de convolution sous forme de produit scalaire
Cette astuce est implémentée dans l’algorithme im2col.
Voici une implémentation possible:
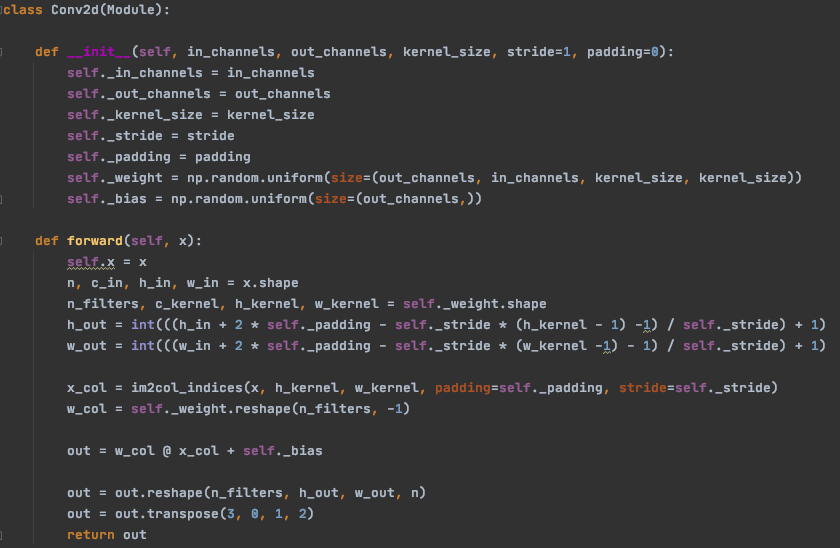
Annexe 21: Implémentation de la propagation avant d’une couche de convolution
De même que pour la couche linéaire, l’entrée est gardée en mémoire pour la rétro-propagation.
- Rétro-propagation
La dérivée partielle ∂O/∂W est un tenseur d’ordre 4. Elle est relativement complexe à calculer et à visualiser. Cependant on remarque que:
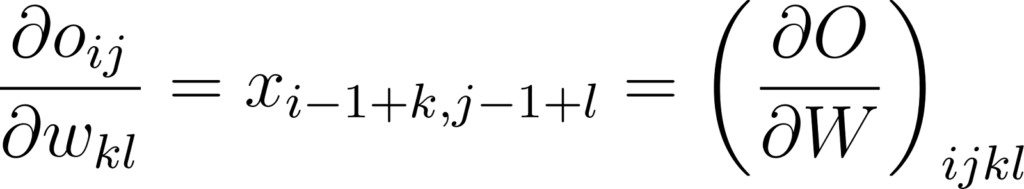
Annexe 22: Dérivée partielle d’un élément de la sortie d’une couche de convolution par rapport à un poids du kernel
Ce qui nous intéresse vraiment ici, c’est de mettre à jour chaque poids wkl du kernel. Pour cela on a besoin de la dérivée partielle ∂L/∂W. Avec la règle du gradient chaîné on a:
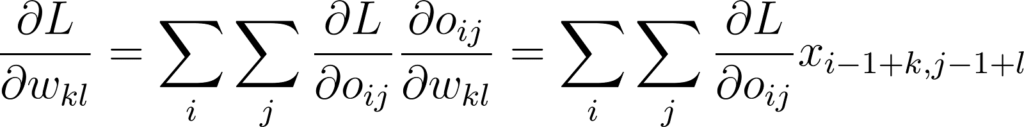
Annexe 23: Dérivée partielle de la fonction objectif par rapport à un poids du kernel
Qu’on peut réécrire ainsi dans notre cas:
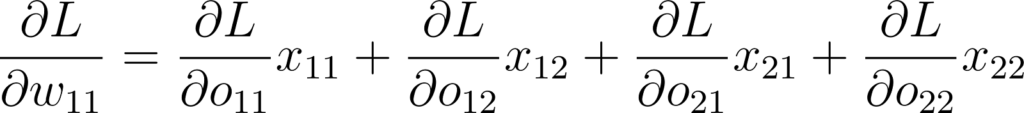
Annexe 24: Expression de la dérivée partielle dans le cas d’un kernel 2x2
Cette dernière formule ressemble énormément à la convolution de la propagation avant. Sauf qu’à la place des poids du kernel on a les dérivées partielles par rapport à la sortie. On peut la représenter ainsi:
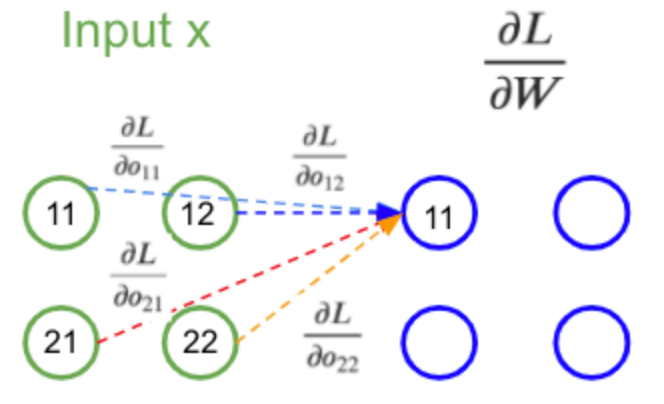
Annexe 25: Schéma du calcul de la dérivée partielle de la fonction objectif par rapport au kernel pendant la rétro-propagation
Ainsi, on peut calculer les dérivées partielles de la même façon qu’on a fait la propagation avant avec l’astuce im2col.
Voici une implémentation possible:
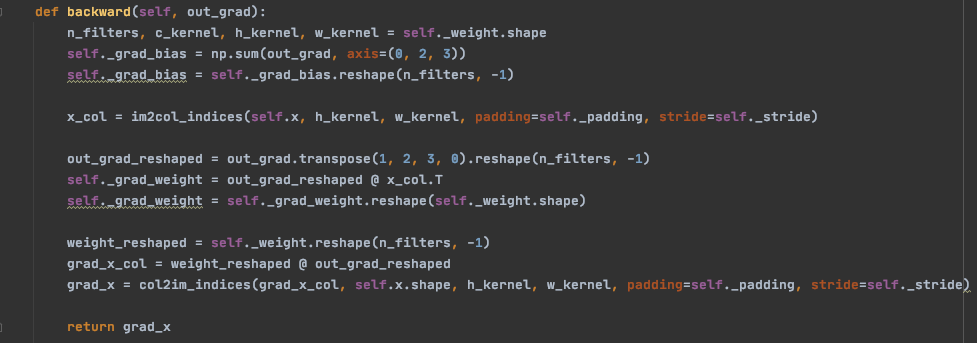
Annexe 26: Implémentation de la rétro-propagation d’une couche de convolution
Dérivée partielle de la fonction objectif
J’ai beaucoup parlé des dérivées partielles locales de chaque couche, mais pour que cet article soit complet il faut aborder le début de la rétro-propagation, la dérivée partielle de la fonction objectif elle-même.
Considérons donc l’entropie croisée pour C classes:
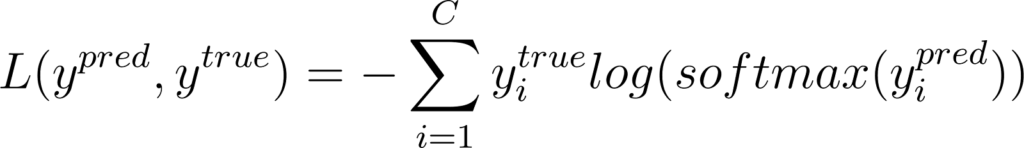
Annexe 27: Expression de l’entropie croisée
La fonction softmax permet d’obtenir des probabilités à partir des sorties du réseau de neurones.
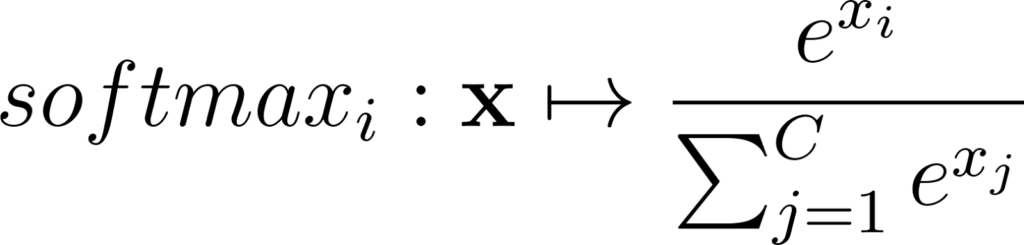
Annexe 28: Expression d’un élément d’un vecteur softmax
Si l’on reprend l’analogie du barrage, nous avons C niveaux d’eau en sortie du réseau. Notons ces niveaux θ~i, ~ ∀i ∈ {1,...,C}, nous avons alors:
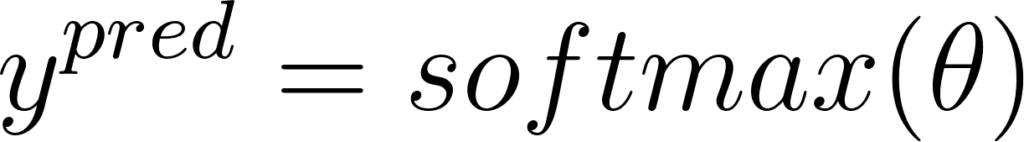
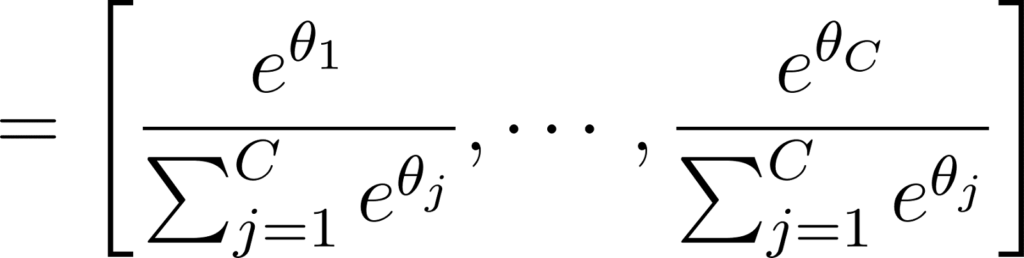
Annexe 29: Probabilités à partir du softmax des sorties d’un réseau de neurones
Calculons alors la dérivée partielle de L en fonction de θk:
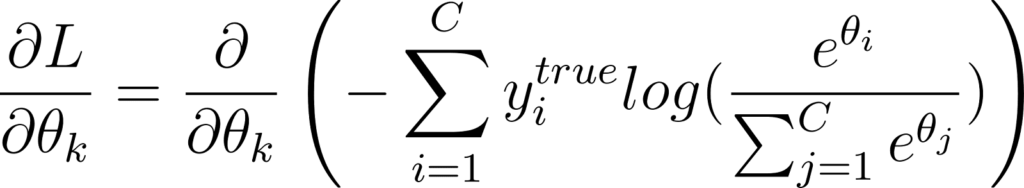
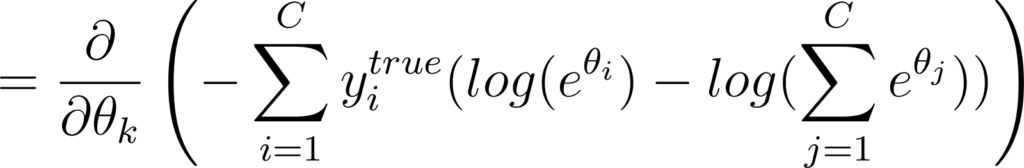
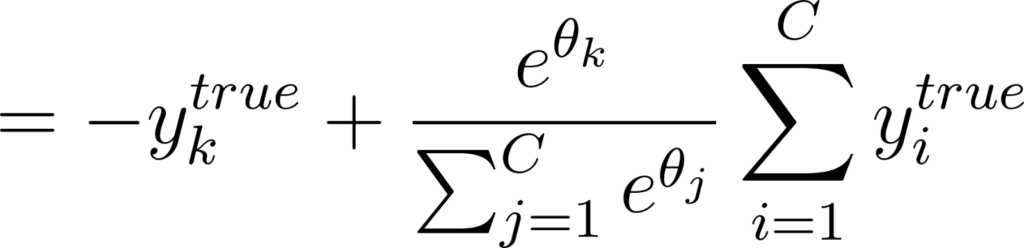
Annexe 30: Calcul de la dérivée partielle de l’entropie croisée par rapport à une sortie d’un réseau de neurones
Or ytrue est un vecteur de probabilités, sa somme est donc égale à 1. On en déduit que:
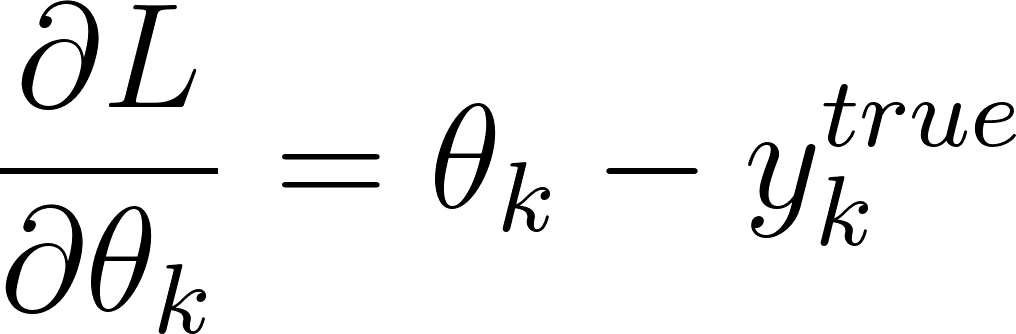
Annexe 31: Expression de la dérivée partielle par rapport à une sortie du réseau de neurones
Donc:
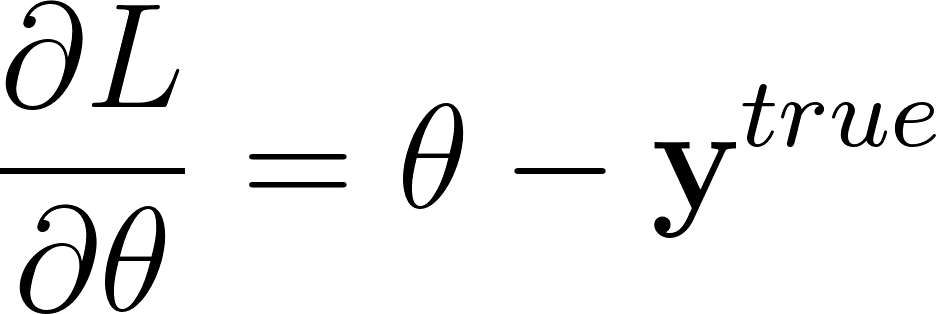
Annexe 32: Expression de la dérivée partielle sous forme vectorielle
Cette dérivée partielle est le premier élément du gradient chaîné pour la rétro-propagation.
Voici une implémentation possible:
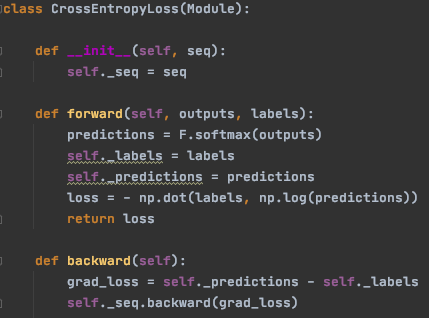
Annexe 33: Implémentation de l’entropie croisée