L’IA embarquée : entraîner, déployer et utiliser du Deep Learning sur un Raspberry (Partie 1)
Pour la deuxième année consécutive, OCTO Technology prend part à la course Iron Car avec son équipage Octonomous. Pour rappel, le but de la compétition est de réaliser trois tours de circuit avec une voiture de taille réduite le plus rapidement possible. Bien entendu, la voiture n’est pas radiocommandée ; une des règles de la compétition est précisément d’utiliser un réseau de neurones pour le pilotage de la voiture ! Le matériel autorisé, outre la voiture, est composé d’un Raspberry Pi et de sa caméra : la caméra fournit des images à partir desquelles le réseau de neurones doit inférer la commande de la voiture.
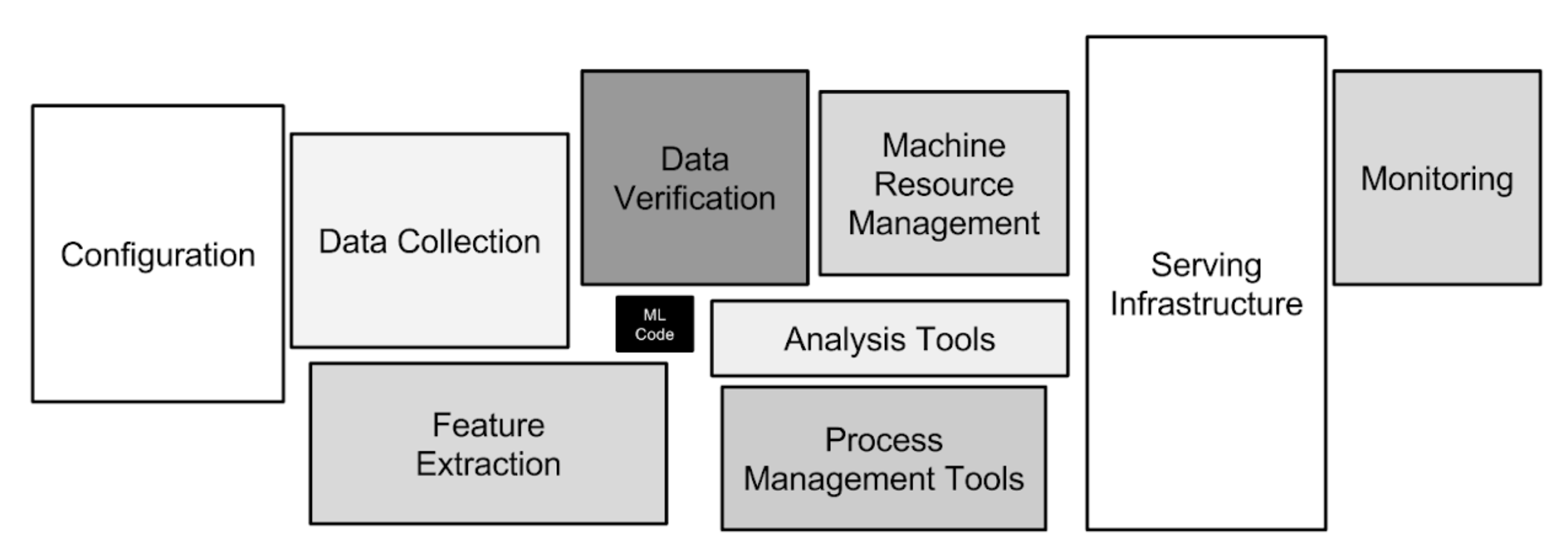
Ce cas d’usage, d’apparence simple, recèle de toutes les difficultés que propose la mise en production d’un modèle de Machine Learning. On pourrait penser de prime abord que la complexité réside dans la création d’un modèle de Deep Learning robuste et fiable, et que le reste est trivial. Bien sûr, il n’est pas évident de concevoir un tel modèle, cependant, comme l’illustre Google dans un papier intitulé Hidden Technical Debt in Machine Learning Systems, le modèle et sa complexité ne représentent qu’une brique élémentaire dans le schéma d’architecture proposé ci-dessous.
Pour illustrer ces subtilités, nous vous proposons d’étudier le cas d’usage de reconnaissance de dessins grâce à un raspberry. Pour cela, nous détaillerons l’approche en trois étapes pour autant d’articles : l’entraînement, le déploiement et enfin l’utilisation d’un modèle de Deep Learning.
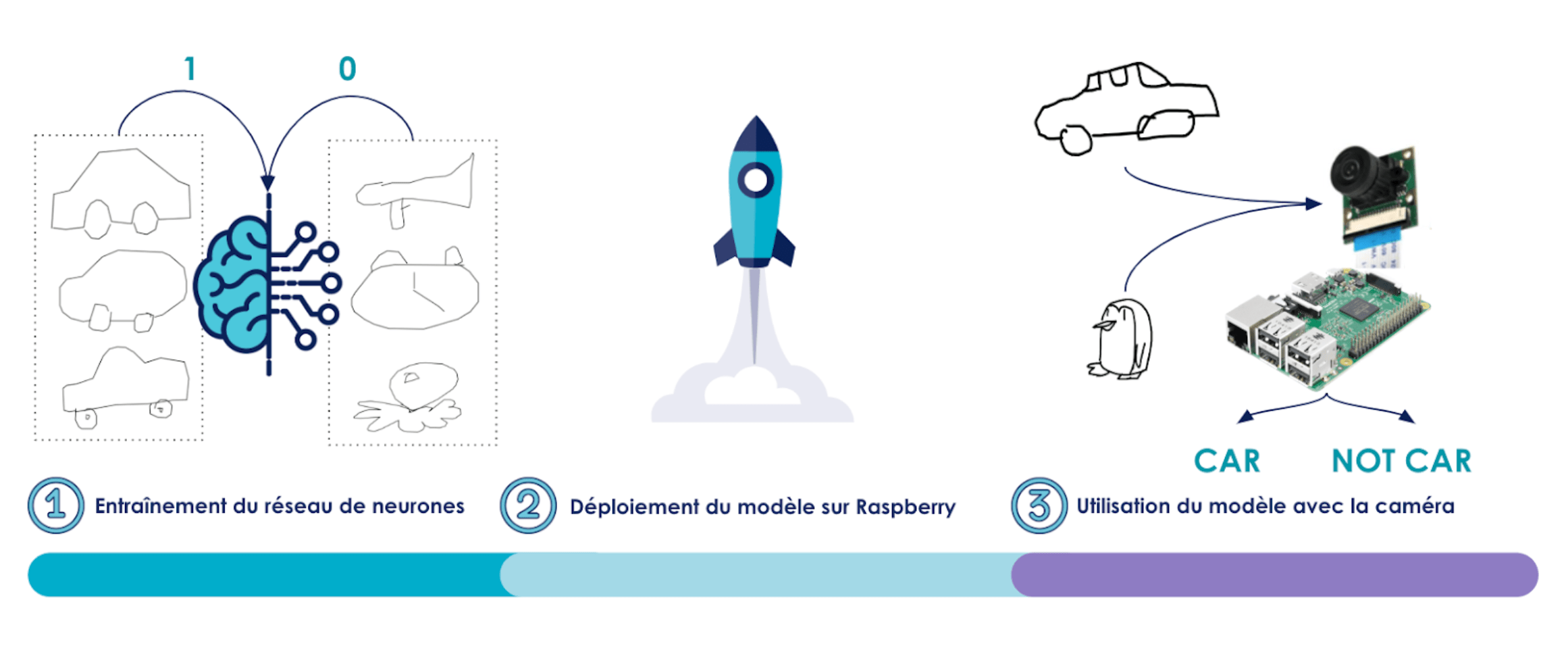
Partie 1 : entraîner un réseau de neurones
Des données propres et qualifiées sont la base d’un modèle
Certains connaissent peut-être le jeu QuickDraw racheté par Google il y a plusieurs années. Il s’agit de dessiner en moins de 20 secondes un dessin demandé, au format numérique. Il est illustré en fig.3

Fig 3 : Écran d’accueil de l’application QuickDraw
Ainsi, lorsqu’on me demande d’esquisser la Joconde, j’ai 20 secondes pour faire reconnaître au jeu mon ébauche.
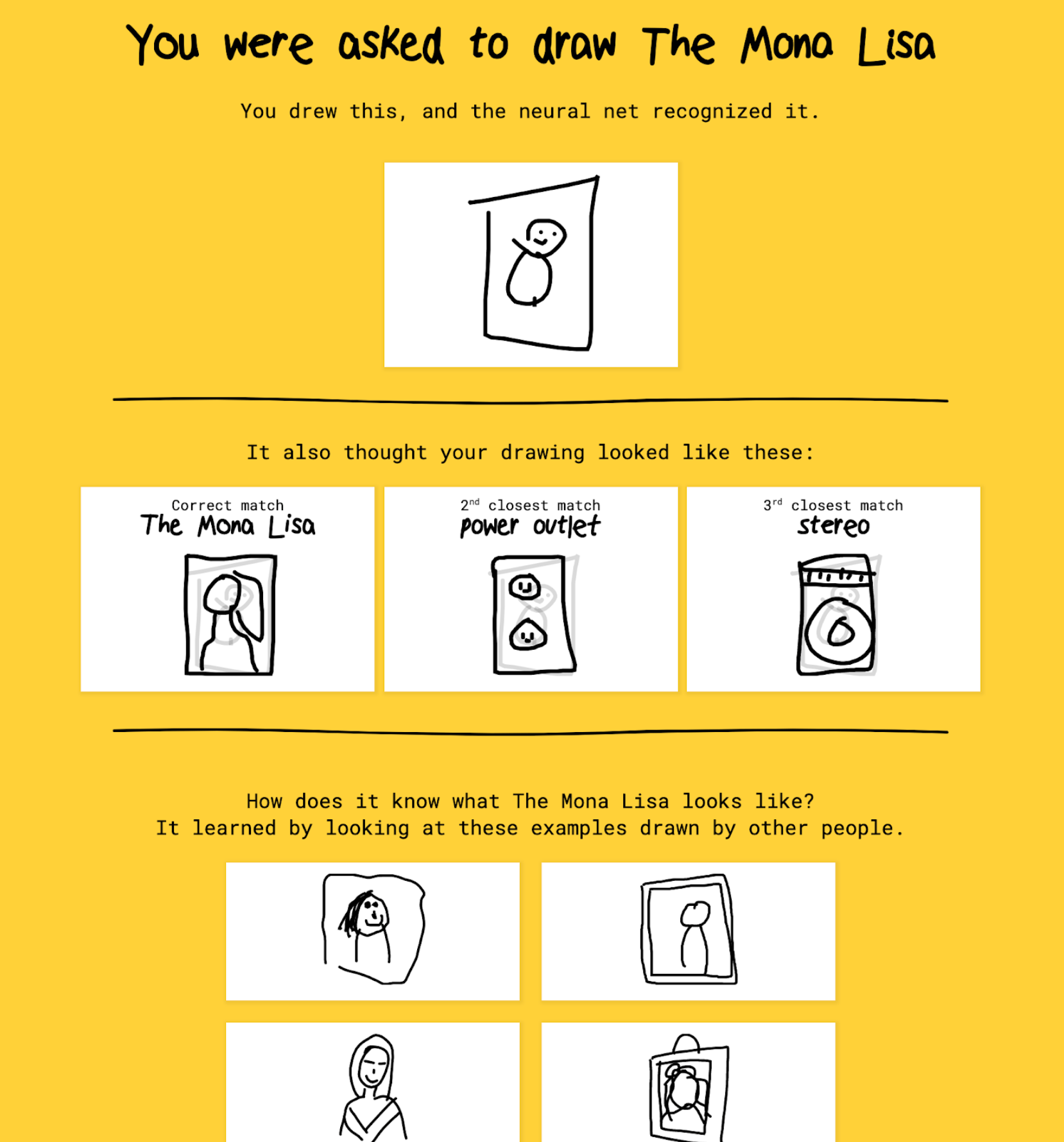
Fig 4 : Prédiction du modèle contenu dans l’application avec l’exemple de Mona Lisa
Un certain “neural net” a reconnu le chef-d’oeuvre. La ressemblance avec d’autres types de dessins, ici “power outlet” et “stereo” est aussi indiquée. Enfin, je peux admirer ce que d’autres ont été capable de faire en moins de 20 secondes (cf. fig 4).
Google a mis le dataset à disposition via sa solution cloud de stockage : Google Storage. On peut donc récupérer un ensemble de dessins numériques ainsi que le nom de ce qu’ils sont censés représenter : power outlet, stereo, Mona Lisa, … On dira que les dessins sont labellisés.
On se propose de récupérer ce dataset et de l’utiliser pour entraîner un modèle de Deep Learning qui déterminera, à partir d’un dessin, s’il s’agit d’une voiture ou non.
On utilise le sdk google cloud pour récupérer les données :

Il existe 344 fichiers binaires, soit autant que de catégories disponibles. De plus, Google nous propose un exemple de parser en python afin de décompresser le format de fichier.
Appliquons le parser à une catégorie, par exemple airplane, en extrayant la valeur image de l’objet drawing. On pourrait s’attendre à obtenir un tableau de valeurs de pixels ou une image. En réalité, le résultat est un peu plus riche : il s’agit d’une liste des différents traits qui composent le dessin. Chaque élément de cette liste est un tuple : la première coordonnée du tuple est l’évolution en abscisse du trait, et la seconde est l’évolution en ordonnée ! Par exemple, prenons une image composée de 4 traits :

Dans le standard fourni par Pillow, une librairie permettant de traiter des images facilement en Python, l’origine des coordonnées des pixels d’une image est en haut à gauche. Il semblerait que les images d’origine utilisent ce standard. En revanche, pour représenter l’image, nous utilisons Matplotlib pour qui l’origine des axes est en bas à gauche. Il convient donc de tracer le complémentaire à 255 (hauteur de l’image) pour l'ordonnée :

ce qui nous fournit le résultat suivant :
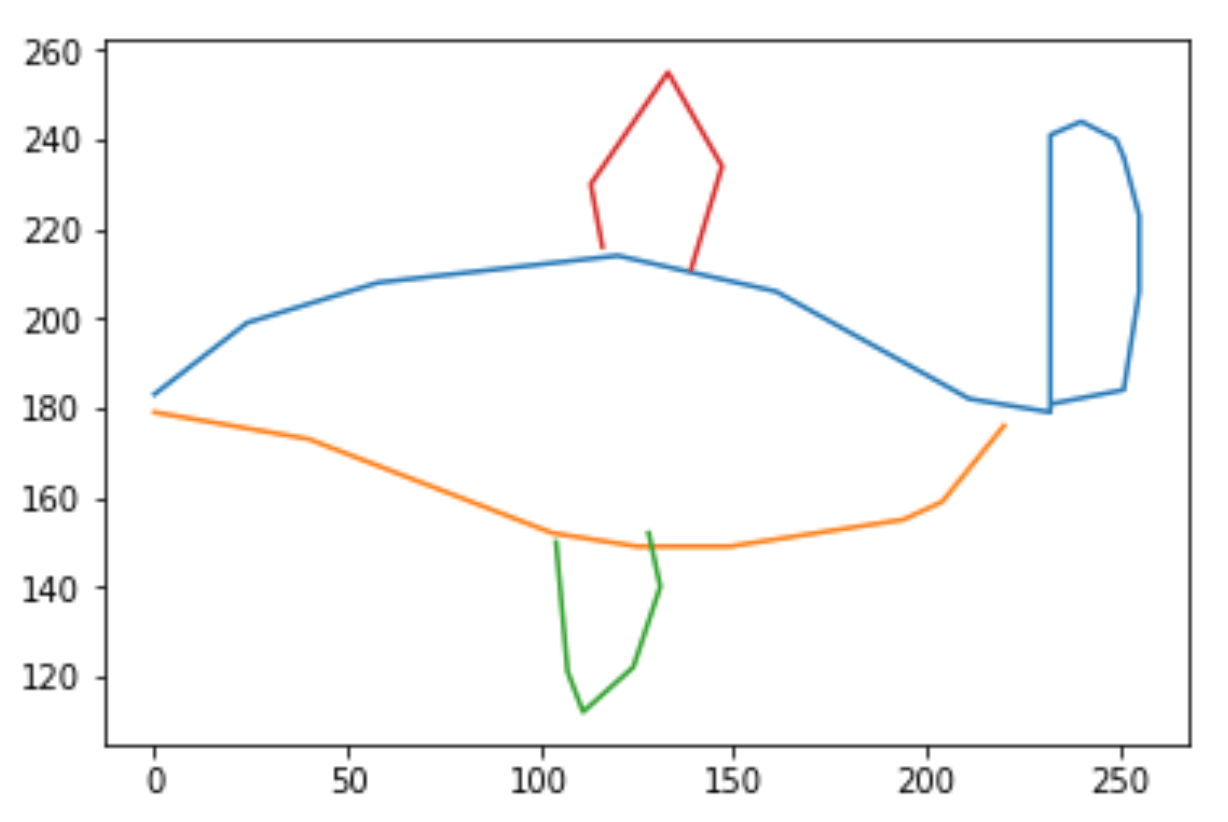
Fig 5. Représentation des traits d’une image de la classe airplane
Dans le dataset Quickdraw, il s’agit d’un avion. Nous appliquons ce traitement à l’ensemble des images pour toutes les catégories, en prenant soin de sauvegarder individuellement chacune des images avec un identifiant unique comprenant le label de l’image (par exemple airplane_1.jpg pour l’image de la fig.1). Les images sont sauvegardées en format JPEG, en noir et blanc.
Notons que cette représentation d’une image comme une séquence de points parmi les traits permet d’entraîner des réseaux de neurones à dessiner “à la manière” des dessins de QuickDraw, en utilisant des Generative Adversarial Networks (GAN). Ces modèles, bien que très intéressants, sont largement plus compliqués que celui que nous essayons de construire ! C’est pourquoi nous réduisons le dataset à de “simples” images.
Définir une architecture avec Keras
Lors d’un précédent article, nous vous avons expliqué comment utiliser les réseaux convolutifs pour des images. Nous allons appliquer directement ces principes, sans chercher à les justifier. Pour aller plus loin sur l’aspect théorique, vous pouvez référer par exemple au hors série n° 100 de Linux Mag : Le Deep Learning, de la théorie à la pratique.
D’un point de vue pratique, entraîner un réseau de neurones demande énormément de ressources. En revanche, le calcul d’une prédiction est moins gourmand. Nous pouvons ainsi utiliser le réseau de neurones entraîné sur une machine aux capacités aussi modestes qu’un Raspberry sans pour autant être capable d’entraîner ledit réseau directement sur le Raspberry.
A l’heure du cloud, il est aisé d’accéder à des machines virtuelles disposant de composants hardware utilisés spécifiquement pour l’entraînement de réseaux de neurones ! D’ailleurs, la plupart des cloud providers proposent des environnements déjà configurés. Par exemple, AWS a une AMI spéciale Deep Learning qui contient la plupart des frameworks d’entraînement de réseaux : Pytorch, MXNET, TensorFlow, Keras, etc...
Pour notre modèle, nous utiliserons les deux derniers avec la version 3.6 de Python (TensorFlow 1.12.0 et Keras 2.2.4). Nous comprendrons plus tard, lors de l’utilisation du modèle sur le Pi, pourquoi il est primordial de connaître l’environnement Python qui a généré le modèle entraîné. Nous utilisons cette AMI sur une EC2 qui dispose de cartes GPU, très utiles pour optimiser le calcul tensoriel qui est à la base de l’apprentissage des réseaux de neurones. En l’occurrence, il s’agit d’une instance p2.xlarge.
Pour le choix du réseau convolutionnel, nous proposons l’architecture décrite dans la fig. 6
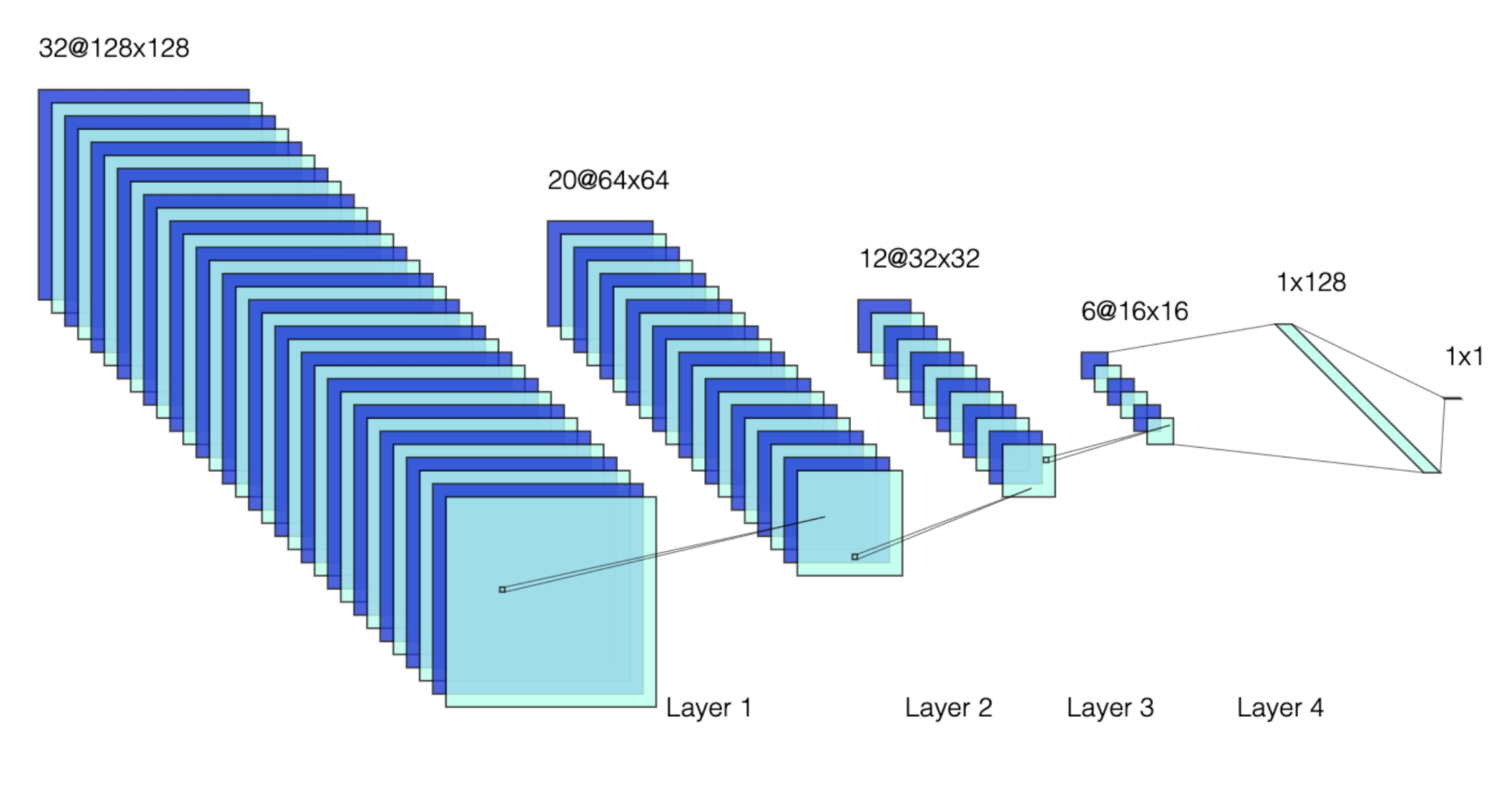
_fig.6 : Schéma d’architecture du réseau (_46841 paramètres)
Contrairement à ce que le schéma peut laisser penser, il s’agit d’une architecture très simple avec un nombre relativement faible de paramètres à déterminer (46841).
L'architecture est une cascade de couches de convolution (paramètres qui composent les matrices de convolution), alternées à du max_pooling (réduction de l’image en prenant le pixel d’intensité maximum dans un rectangle) ; c’est une stratégie usuelle lorsqu’il est question d’images. A noter que la sortie du réseau est composée de deux couches denses, afin de ne pas réduire la dimension de façon trop brusque et conserver suffisamment de degrés de liberté. Enfin, la sortie de la deuxième couche dense est bien d’une seule dimension ; le problème est une classification binaire (est ce que c’est un dessin de voiture ou non ?). Le modèle prédit donc la probabilité que le dessin représente une voiture.
Avec le framework Keras, une telle architecture se décrit comme suit en python
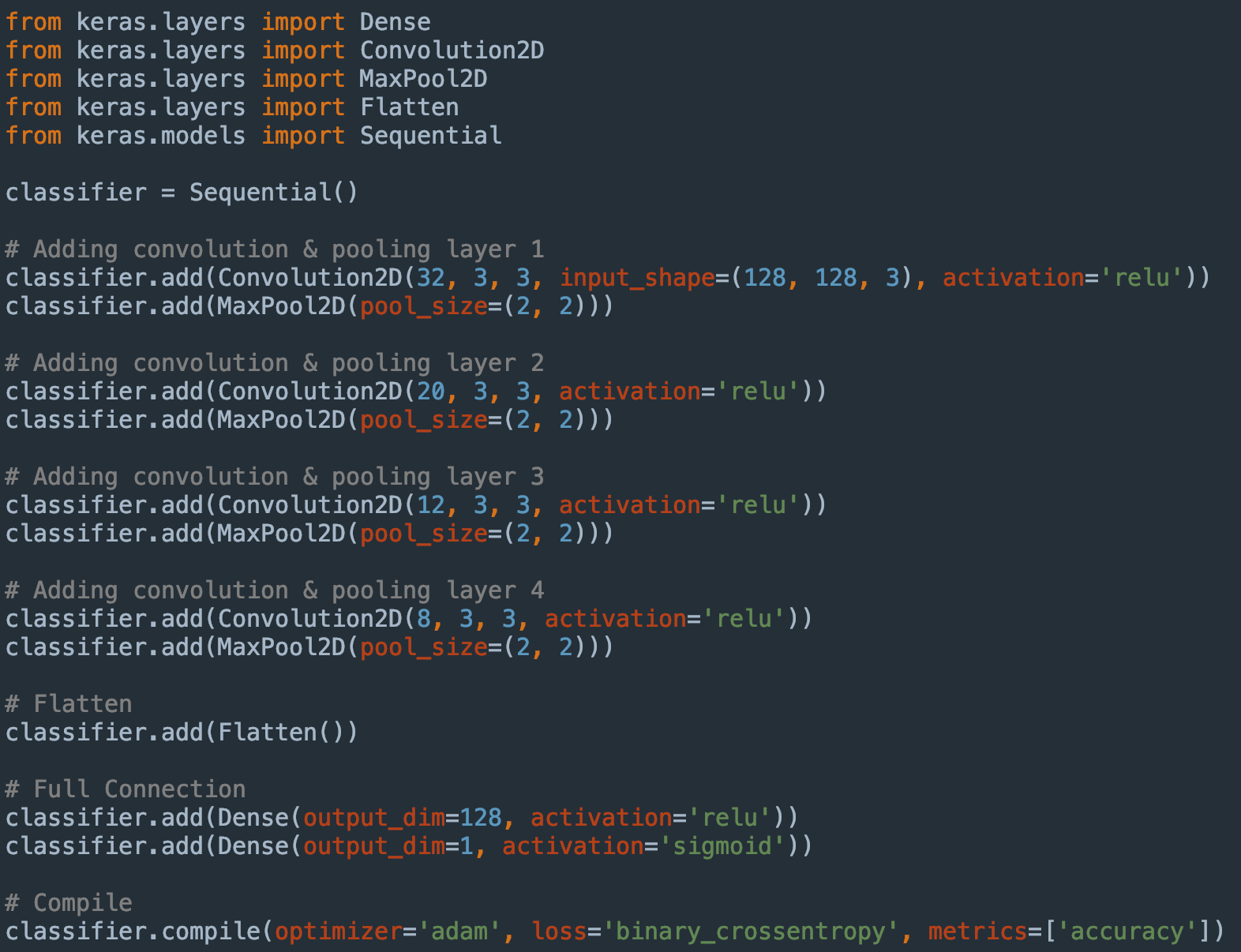
On voit la concision que permet le framework. Une ligne de code suffit pour ajouter une couche dans l'architecture de notre réseau. Maintenant que le modèle est construit, il nous faut l’entraîner à la détection de dessins de voiture.
Entraîner un modèle dans le cloud ? Un jeu d’enfant
L’entraînement d’un modèle de Deep Learning supervisé est découpé en plusieurs étapes :
- On initialise de manière aléatoire les paramètres du modèle
- On sépare les données labellisées à notre disposition en deux ensembles : train et test
- On évalue les prédictions du modèle pour l’ensemble des images présentes dans train (ensemble de prédiction noté Pred__train)
- On mesure l’erreur que fait le modèle en comparant Pred__train avec les vrais labels (0 ou 1 ~ voiture / pas voiture), notés y__train. Cette mesure de l’erreur se fait via une fonction coût, que l’on a renseigné ici par binary_crossentropy
- On diminue ensuite cette erreur en ajustant les valeurs des paramètres du réseau par descente de gradient (cf. Linux Mag)
- On évalue les prédictions de l’ensemble des images présentes dans test (noté Pred__test). On mesure l’erreur entre Pred__test et y__test, potentiellement avec une autre fonction coût. Si la mesure de l’erreur est jugée suffisamment faible, le modèle est dit entrainé, sinon on retourne à l’étape 3 avec les paramètres mis à jour
On comprend donc qu’il faut avoir une répartition train/test judicieuse et équilibrée. Si l’ensemble test est représentatif des données que j’aurais dans un environnement de production, alors la mesure de performance que j’ai sur l’ensemble test devrait correspondre à la performance que j’aurais en production.
Ici, on choisit de séparer les données de manière équitable et aléatoire :
- train est composé des deux tiers de l’ensemble d’images de voitures et des deux tiers de l’ensemble des images d’autres catégories. Cela représente 47768 images
- test est composé du tiers restant d’images de voitures et du tiers restant des images de chacune des catégories. Cela représente 23885 images
Les images n’étant pas toutes de la même taille, on décide de les redimensionner. Ces dimensions sont importantes, car elles conditionnent le nombre de paramètres en entrée du modèle. Il faut cependant que la dimension d’entrée permette une identification du dessin représenté. De manière empirique, nous avons déterminé que (128,128) semblait être un bon compromis.
Pour assurer une meilleure dynamique d’apprentissage tout en utilisant raisonnablement les ressources à notre disposition, il est fréquent de découper l’étape 3 décrite ci-dessus en paquets d’images; on parlera de batchs. Par exemple, on découpe l’ensemble des images de train en un nombre N de batchs de taille égale, disons 32 images. Pour chacun des batchs considérés, on évalue Pred__train sur ce batch, Pred__test sur l’ensemble des images du test. A partir de Pred__train, on calcule la fonction coût associée, et on effectue une mise à jour des paramètres du réseau. Au total, on effectue N mises à jour en série. Lorsqu’on a parcouru l’ensemble des batchs qui composent train, on dit qu’on a réalisé une epoch. Passer d’une epoch à une autre revient à passer de l’étape 6 à l’étape 3 décrites ci-dessus.
Nous en avons profité pour utiliser une feature de la bibliothèque Keras : la classe ImageDataGenerator, et la méthode associée fit_generator. Cette dernière nous permet de charger en mémoire uniquement les images du batch concerné par l’étape d’apprentissage. En effet, il existe deux stratégies pour utiliser les images lors de l’entraînement. La première consiste à charger les quelques 70 000 images du train et du test chargées dans des objets python (des tableaux de pixels en l’occurrence), ce qui nécessite un espace mémoire conséquent. La seconde en revanche, consiste à lire sur disque uniquement les images nécessaire au batch en cours, ce que permet très simplement la classe ImageDataGenerator. Cette méthode génère plus de lectures de données sur disque, mais permet d’allouer un maximum de mémoire aux calculs nécessaires à l’apprentissage.
Pour entraîner notre modèle, nous avons choisi une taille de batch de 32 images et 30 epochs.

À la fin de l’entraînement, qui a duré une trentaine de minutes, les performances du modèle sur test sont excellentes ! En effet, on mesure une précision de 99,66 %.
Il ne nous reste plus qu’à sauvegarder ce modèle pour pouvoir le déporter de la machine d’entraînement vers le Raspberry. Keras propose le format .h5 de sauvegarde pour l’objet python correspondant au modèle.

Le mot de la fin
En conclusion de cette première partie, nous avons vu que les frameworks actuels en python permettent aisément de décrire des architectures de Deep Learning.
Pour l’entraînement, il nous faut d’une part de la donnée riche, c’est à dire qualifiée et labellisée (c’est pourquoi nous utilisons directement le dataset de l’application QuickDraw). D’autre part, il convient d’avoir du matériel performant, rendant raisonnable le temps de calcul. Pour sa flexibilité et son coût moindre, nous avons choisi une solution cloud qui offre de plus un environnement déjà configuré et prêt à l’emploi.
Nous avons relevé les spécificités de cet environnement, notamment les versions de librairies Python, pour pouvoir ensuite utiliser le modèle sur une autre machine. Bien entendu, les paramètres que nous avons choisis pour notre modèle (nombre de couches neuronales, taille de batch, nombre d’epoch, …) sont le résultat d’un processus itératif dont nous faisons ici la synthèse : l’architecture que nous vous avons présentée est désormais entraînée et dispose de très bonnes performances ! 99,66 % du temps, elle est capable de distinguer une voiture d’un autre type de dessin provenant des données de QuickDraw.
Nous vous proposons dans une seconde partie de voir comment assurer un déploiement sans douleur sur une autre machine que la machine d’entraînement : un Raspberry Pi.