I have tested Amazon Athena and have gone ballistic
![]()
If Athena only evokes this (traumatic, isn't it?) scene to you, you'll be disappointed: this blog post is dedicated to Amazon Athena, the latest analytic tool recently announced at Re:invent 2016.
What is Athena?
Athena is self defined as a "Serverless Interactive Query Service". Let's detail.
"Interactive Query Service": easy to figure out, there are already plenty of tools that are able to interactively query data sources. Toad, Hive or Business Objects are all interactive query services, in their own kind.
The freshness resides in the Serverless adjective. After Lambdas, which are defined as serverless computing services, Athena provides an all-in-one query service without the burden of setting up clusters, frameworks and ingestion tools directly on top of S3 with a pay-per-query model.
Athena allows to query very large sets of data in S3 with SQL-like language, from within the Athena console.
How does it work?
This is the beauty of Athena, it takes 3 easy steps to be able to query your data on S3:
- Create a database to hold your data
- Create the tables to match the files format stored on S3 (several formats are available: CSV, Json, Parquet, etc.)
- Query!
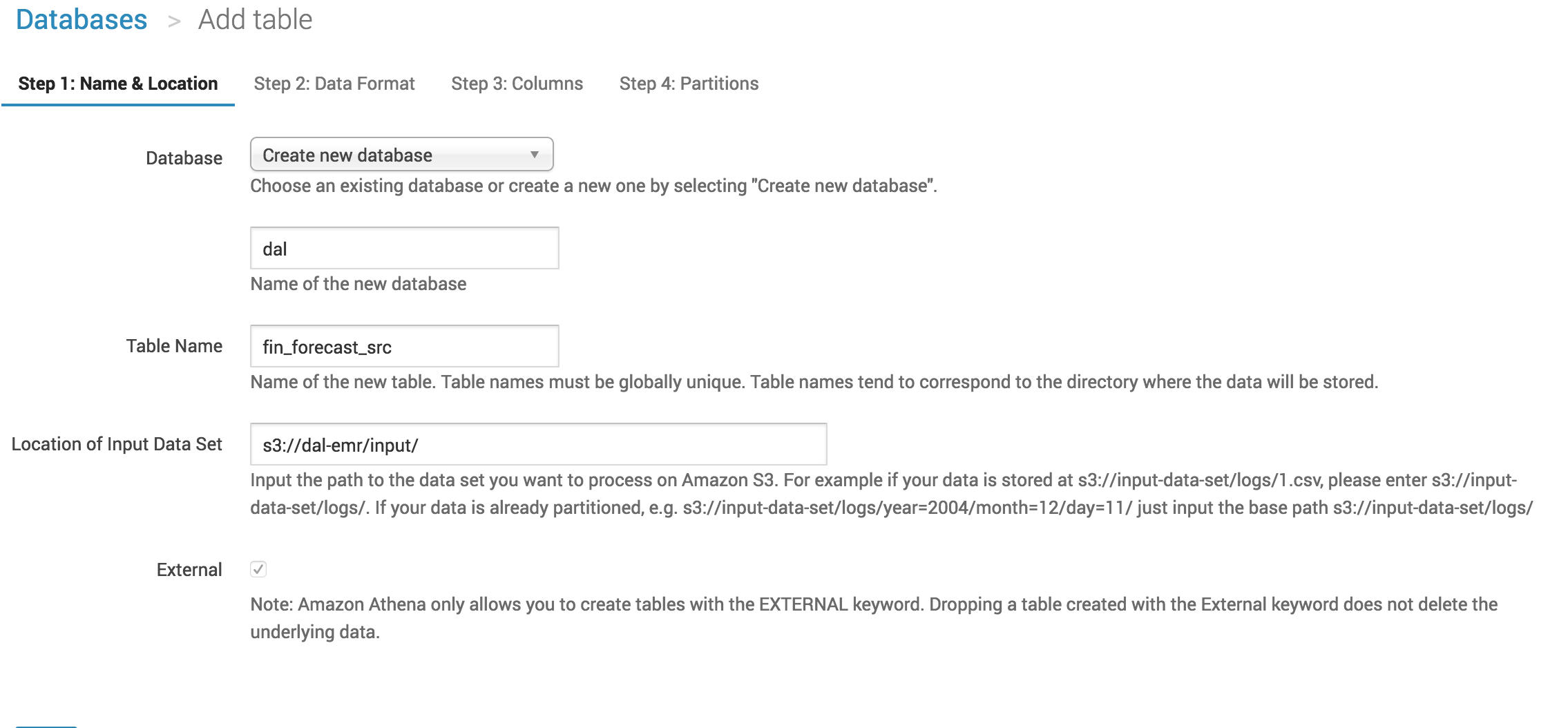
Cheat tip: don't forget the / at the end of the S3 url.
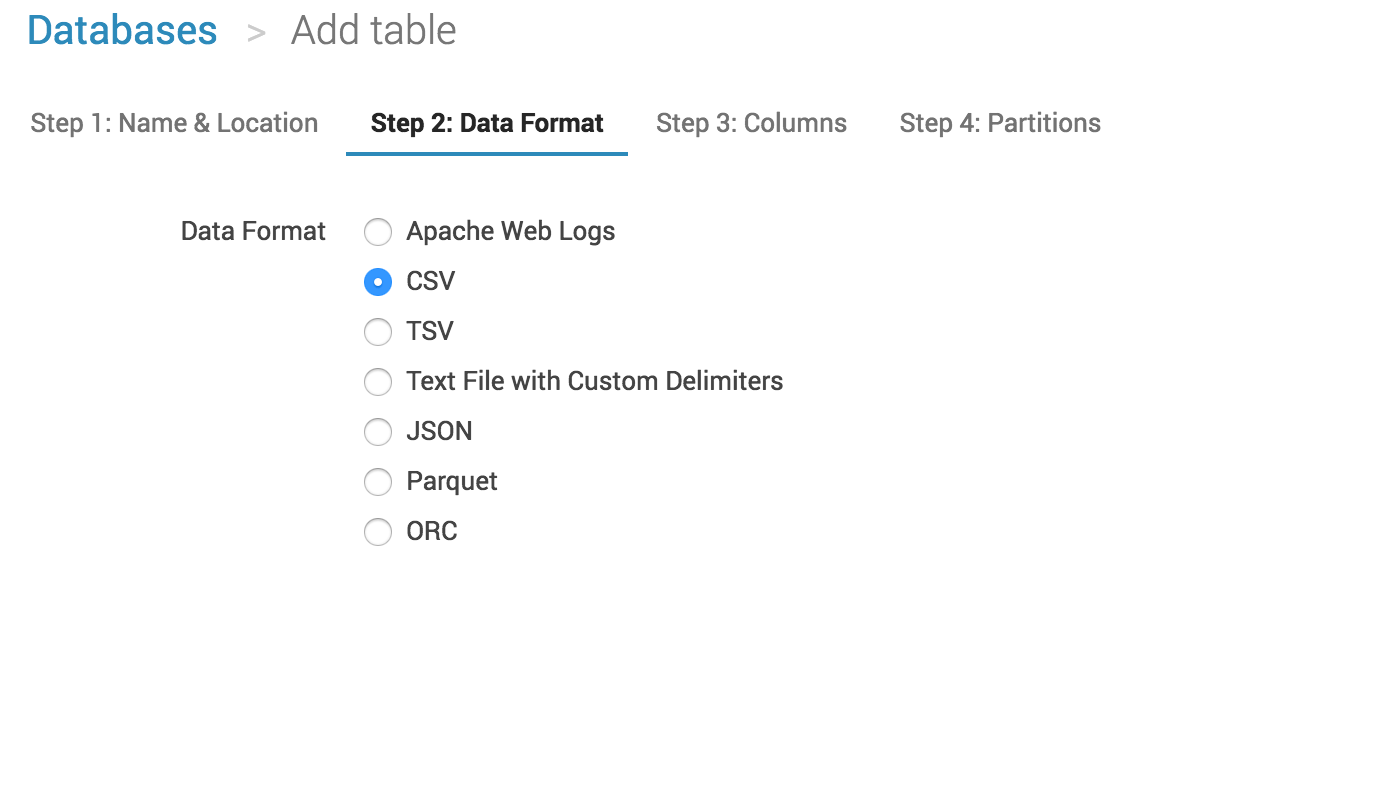
Then comes the flaw. Athena was supposed to be the Goddess of Wisdom, this is what reminded me of this terrible picture of Athena wounded by a golden arrow right in the heart: you have to manually declare each column with its type. Like in 1998.
I had a proper and nice DDL -Data Definition Language- to upload with my 19 columns (only!) but I had to define each column one by one, to finally find out that her majesty Athena was building it for me.
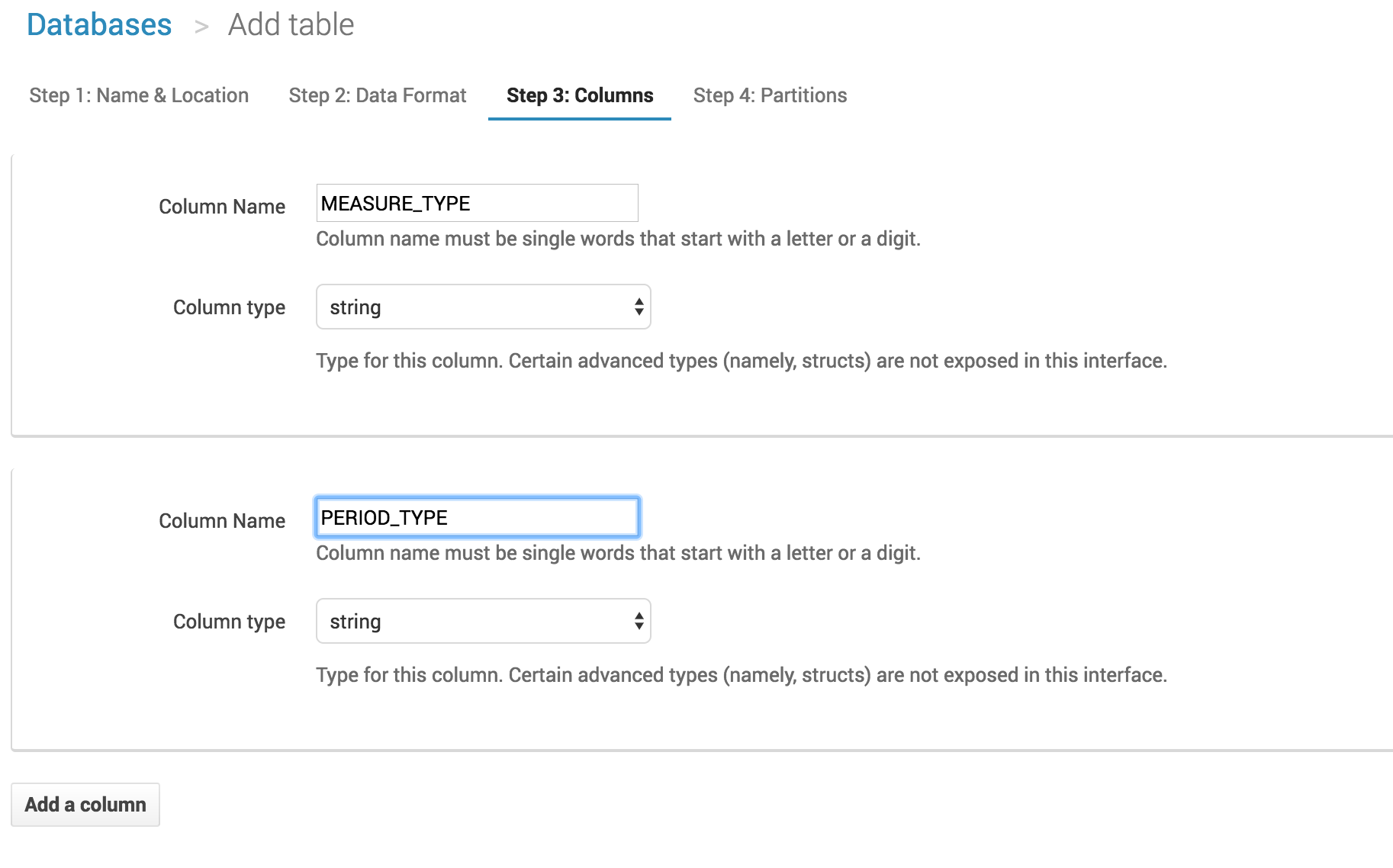
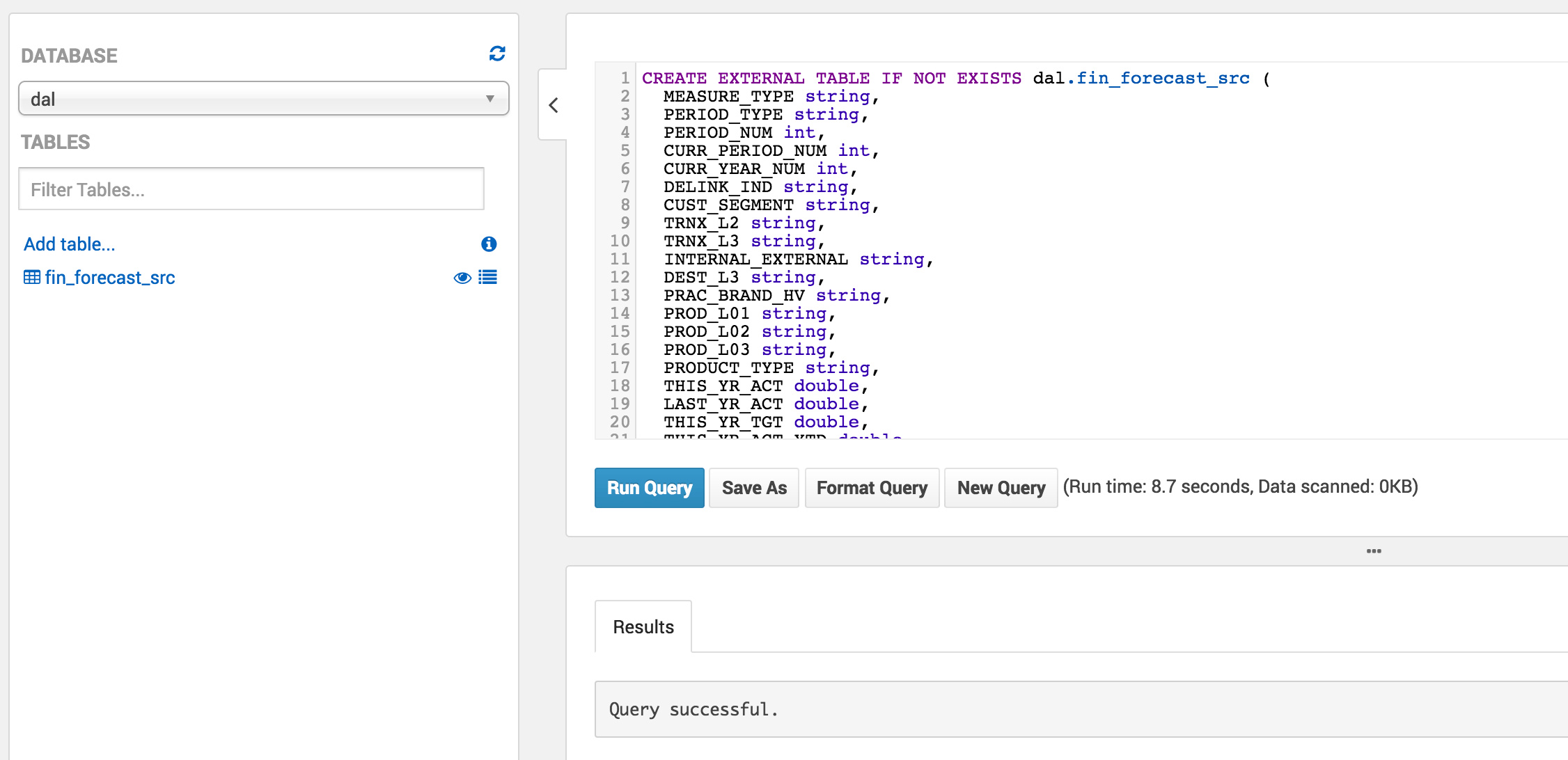

But after a few more clicks, you're ready to query your S3 files! It's really fast, and can naturally be compared to an EMR instance running Hive queries on top of S3 in terms of performance.
As one would expect, queries are processed in the background, making the most of parallel processing capabilities of the underlying infrastructure. Under the hood, Athena uses Apache Presto to process data in the background.
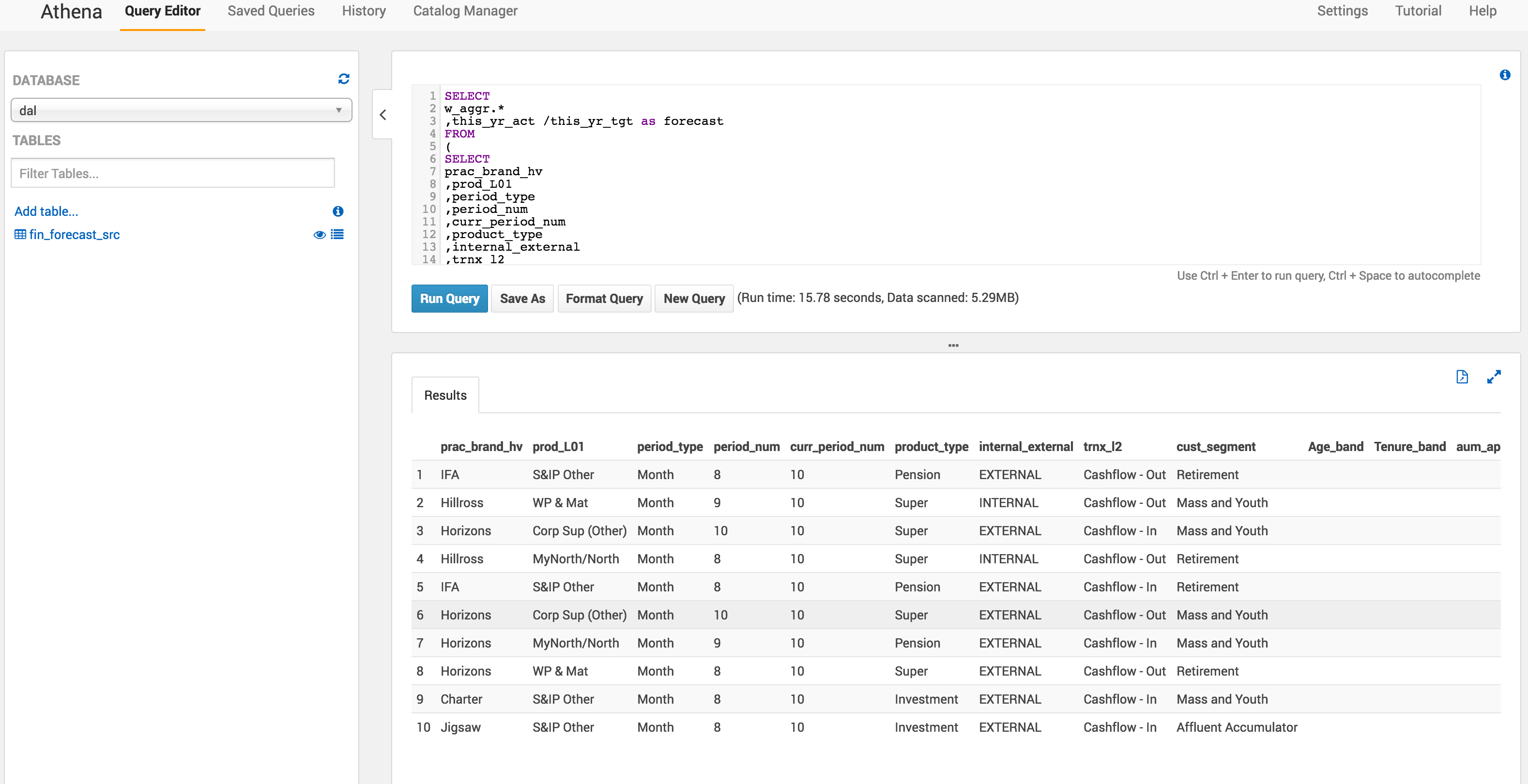

The other features of Athena are:
- Saved queries: for frequent queries
- History: history of all queries, and this is where you can download your query results
- Catalog Manager: very simple database and table manager

Now compare these operations to:
- the setup of an ephemeral EMR cluster on 3 m3.xlarge instances
- the creation of a dedicated step for Hive (or equivalent) to create the table and execute the query
- the termination of the cluster when the processing is over
- ... and the automation of these 3 steps when you run saved queries frequently...
When is it suitable for me?
Of course, Athena is not the panacea for all use cases. It is "just" a query service in a console: you cannot plug it to any publishing layer (Business Objects, Tableau or even d3.js data visualisation framework), there is no way to use Athena APIs so far, or to parameterize queries, and it works only on top of S3.
Amazon did not shoot itself in the foot though: companies will always need EMR clusters to process data. But they innovated to provide easy-to-use straightforward query services for these use cases:
- Unfrequent querying of archived data: legacy system's structured data are stored and archived in S3 but must be queried regularly (once a week for ex) for auditability or regulatory purposes. Instead of setting up a temporary RDS instance to store the data so it can be queried, Amazon Athena makes it immediately available
- Easy exploration: provided you have the proper rights, you are now able to test your queries against a vast amount of data for $5 per terabyte. No need to call the BI team to set up a EMR cluster for you, or to extract data for you with multiple back-and-forth when defining the query.
- (Manual) pipeline for demonstrating model/reporting: now you can extract and process data directly from your S3 repository, it is very simple to download the generated csv file to connect to any visualisation or drill-down capable tool to demonstrate a model or a report without having it industrialised
If your company lands all its data into S3 as a datalake, it must be tempting to think that Amazon Athena could query it all. However, permissions and rights in corporate companies in general do not allow such queries across all domains and groups, if only Athena could query multiple buckets at the same time. Don't jump too fast on the conclusion then: it won't be your natural enterprise wide query tool.
The actual limits
As said previously, Athena is powerful though lacks of several features:
- No integration with Amazon existing services (besides the infrastructure ones, eg. security)
- No API yet, and no possibility of passing parameters to queries
- Exports in CSV files only
- Data must reside in S3, in one single bucket
But If I was Athena's Product Manager, I would be proud of my MVP (if it is): feedbacks from actual users will stream in and enhancements will be made quickly.
Conclusion
If Athena is tantamount to War or Wisdom, Amazon Athena is almost perfect for instant queries on top of S3. It's fast, it's relatively cheap, it's easy to use. Beside the lack of DDL upload feature, that Amazon may add or improve in the future, it's the ultimate replacement for an EMR cluster when simple querying S3 and will be the watershed in this space as Lambdas are for ephemeral, stateless and quick processing to EC2.
Next steps for Athena should be its APIsation: with APIs and the ability to parameterize queries, Athena would probably sort out 50% of common BI actual problems and that would be the killer app for Amazon.
It's available in Virginia region at the moment, but no doubt it will be deployed everywhere around the world swiftly. Stay tuned to make the most of this product soon!
IMPORTANT EDIT - 06/12
Thanks to Rudy Krol who alerted me, the conclusion should be amended: jdbc is available for Athena as described here.
Let's query everything!