HTTP caching with Nginx and Memcached
Deploying an HTTP cache in front of web servers is a good way to improve performances. This post has two goals :
- present the basics of HTTP Caching
- present the new features I have implemented in the Memcached Nginx module to simplify HTTP caching
Cache? What is it ?
Caches are used to improve performances when accessing to a resource in two ways:
it reduces the access time to the resource, by copying it closer to the user. Some examples: the L2 cache of a microprocessor, a database cache, a browser cache, a CDN, ...
it increases the resource building speed, by reducing the number of accesses. For example, instead of building the homepage of your blog at each request, you can store it in a cache. This scenario will be the topic of this post.
The HTTP cache
Architecture
The HTTP cache is usually placed in front of your web server. The architecture look like that :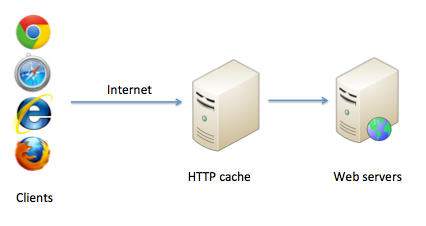
For a given URL, the HTTP cache asks the page to the web server the first time it is queried and store it for the following requests, which allows to reduce the server load and increase the site speed: the page is no longer dynamically rendered, but just taken out of the cache.
There are lot of HTTP cache implementations. The best known are :
How it's work?
The HTTP cache relies on the HTTP cache headers, used by the client browser, to work out how long the copy of a page can be kept. For example, if your web server asks for a given URL with an HTTP header containing: Expires: Thu, 31 Dec 2037 23:55:55 GMT, it knows this resource will not be modified before the 31 December 2037, which allows this resource to be queried only once, and stored until its expiration date.
In addition to Expires, some others HTTP headers are involved in cache mechanisms, like Cache-Control and Vary. Please consult the RFC 2616 for more details. Unfortunately, caching is a bit more complex as different browsers/reverse proxy/HTTP caches do not manage HTTP headers exactly in the same way.
The simplified HTTP cache architecture is :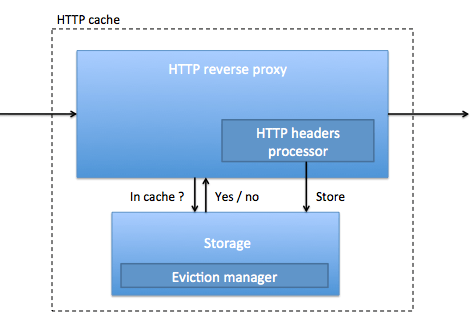
Note that the HTTP cache store not only the URL data (ie. the web page content), but also the HTTP headers, expiration times and other meta-data.
Some implementations allow us to configure caching without using HTTP headers, if you can not or do not want to modify your application. For example, see the varnish VCL. However, I invite you to use HTTP headers that are standard and more simple to deploy (it is all in the application).
In the above implementations, Varnish and Squid are daemons, running independently of the web server. Both tools make caching in memory or disk. Apache2 and Nginx will be able to do HTTP caching, directly in the web server process. The performance difference is not huge (at least for Nginx). However, having separated cache processes have other benefits: it allows sharing the cache across multiple applications, or to use other features like load balancing or routing of some URLs on specific servers.
Limitations
This cache system works well. But some use cases are difficult to implement. An example: my website displays a ranking computed every 3 minutes by an external daemon. This daemon stored the ranking in a web page, which is loaded in Ajax. To implement that, the simplest solution is to write a file on disk which will be served by the web server, as a static page. One problem is that the file contains only data: no meta data, such as the expiration time of the resource. We would prefer to place directly our ranking in the HTTP cache, and specifying the expiration time. Such a solution is actually quite difficult to implement, as the ranking is updated by an external daemon and the cache is filled by the web server.
For this feature, we will use an architecture like :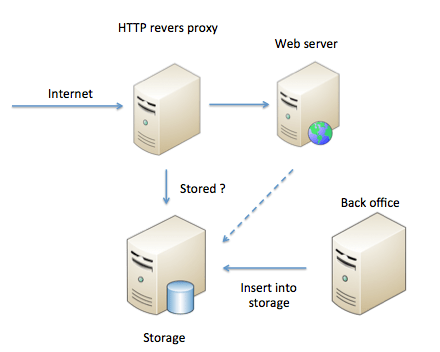
In this architecture, for each incoming HTTP request (or only for a specific URL pattern), the HTTP reverse proxy asks the storage if it has data for this URL. If so, the HTTP reverse proxy sends data back to the client. If not, the HTTP reverse proxy sends the request to the web server backend. In this architecture, the storage is not filled by the HTTP reverse proxy but, for instance, by another server which executes background business process (like the back office server) or by the web server, which fills the storage in addition to render HTML pages, while processing some specific requests.
This architecture can been seen as an “exploded” HTTP cache: the reverse proxy part and the storage are split, and the automatic storage filling by HTTP headers analyze is removed.
This architecture is only relevant if the cost of resource generation exceeds the cost needed to retrieve it from storage. This is often the case: a query to a storage like Memcached is much faster than any database call. And you can design your website to have only some URLs in cache: /cache for example, to avoid unnecessary calls to the cache.
This feature is today very important: your website speed impacts directly your business. "Amazon found every 100ms of latency cost them 1% in sales". That's why you have to speed up your website, for instance, by doing some long processing in background like sending an email, calculating a ranking, rendering a PDF invoice ...
The asynchronous job mechanism is now integrated in some web frameworks, like Rails and its delayed jobs.
Nginx / memcached module
The Nginx / Memcached module allows you to setup the previous architecture, using Nginx as a HTTP reverse proxy, and Memcached as storage. (Note: memcached is often used as shared HTTP session storage)
The module Nginx memcached works very well. But it has a big limitation: it can not store HTTP headers with data. For example, pages served by Nginx via Memcached storage have the default Nginx Content-Type. Moreover, it is quite difficult to store multiple type of data in Memcached : CSS, JS, images, HTML, json ... You can add some specifics HTTP headers, but only in Nginx configuration. These headers will be shared by every resources served by Nginx/Memached, unless you put lot of ugly "if" in the configuration.
Note that the Nginx / Redis module has the same problem.
That is why, I have modified the Nginx / Memcached module to store HTTP headers directly in Memached. To use it, you only have to insert in Memcached something like :
EXTRACT_HEADERS
Content-Type: text/xml
<toto></toto>
Nginx will send back a page which contains just <toto></toto>, but with and HTTP header Content-Type: text/xml.
While modifying the Nginx / memcached module, I also add some extras features:
- Honor
If-Modified-SinceHTTP header, by replying304 Not modifiedif resource on Memcached contains an appropriateLast-Modifiedheader. - Hash keys used in Memcached, to get around the Memcached hash max key size (250 chars)
- Memcached insertion via Nginx, on a specific URL. It allows you to use the cache with a simple HTTP client, instead of a Memcached client. which is useful to share data accross multiple servers : the same HTTP load balancers can be used for reading and writing into the cache.
- Memcached purge via Nginx, on a specific URL, which, as above, allows purging Memcached with a simple HTTP client, like curl.
- Partial Memcached purge using Memcached's namespaces. Useful when you cache data for multiple domains, and when you have to purge only one.
Here is an example of Nginx configuration, in which Nginx watches if there is data in Memcached for every URL, before sending requests to backends web servers :
location / {
error_page 404 = @fallback;
if ($http_pragma ~* "no-cache") {
return 404;
}
if ($http_cache_control ~* "no-cache") {
return 404;
}
set $enhanced_memcached_key "$request_uri";
set $enhanced_memcached_key_namespace "$host";
enhanced_memcached_hash_keys_with_md5 on;
enhanced_memcached_pass memcached_upstream;
}
location @fallback {
proxy_pass http://backend_upstream;
}
This module is open source and is available on github. It is used in production at fasterize, with all features, and works very well.
I hope this module will be usefull for you !