How to hack Spark to do some data lineage
This article explores some key aspects of data lineage at the data set level, indicating how to hack the Spark engine to achieve this.
Data lineage, or data tracking, is generally defined as a type of data lifecycle that includes data origins and data movement over time. It can also describe transformations applied to the data as it passes through various processes. Data lineage can help analyse how information is used and track key information that serves a particular purpose.
Mastering the lifecycle of data monitoring has become a key issue for many IT systems using Big Data technologies and other distributed architectures. If in some cases this function can be facilitated by the presence of native tools on the platform and dedicated to data lineage (like Hadoop environments), however, the possibilities of the latter do not always meet all functional needs and fine granularity of lineage and functionally acceptable calculation times.
To take the example of two Open Source stacks that can perform data lineage in the Hadoop constellation, Apache Falcon and Apache Atlas, we realise the limits when it comes to being flexible in front of the diversity of functional needs and efficiency on perimeters with drastically different sizes.
Thus, Atlas, which is maturing (v0.8.1), performs global data lineage by scanning internal metadata of the stacks (HDFS, [Hive](https://cwiki.apache. org/confluence/display/Hive/Home) Metastore, HBase, Kafka,...). The granularity of the lineage is high, at the level of the data path, but without integrating all the information of the data lifecycle, such as the version. A dataset can keep indefinitely the same URI but its version can evolve over time, which is not managed by Atlas. It is mainly used to perform static lineage, which answers questions such as :"From which table is such other table an output?".
Falcon, also maturing (v0.10), serves mainly as a meta-orchestrator, which can generate data pipeline lineage information. The grain is natively limited to the data pipeline.
If the need is to precisely trace the life cycle of the data, e.g to the dataset's version, then answering the question: "Which data set and version another dataset is issued from?" becomes a very difficult architectural use case. This is referred to as dynamic data lineage, where tracking follows the lifecycle of the data as processing pipelines evolve in terms of functions and perimeter.
This article aims to present an effective way of answering this last question. This solution is based on the use of Apache Spark as a processing engine, in particular by exploiting the Logical Execution Plan tree. However, it remains open by design to be used by other treatment processes.
A little bit of theory
The main theoretical challenge of data lineage is to answer the question "which data has been used by which process to produce other data". Although the tracked object is the data itself, it is its metadata that will be used to establish this lineage. The concept usually adopted to solve this type of problem is based on the formulation of relationships between entities in the form of triples semantics. This concept is one of the pillars of the RDF standard (Resource Description Framework), a family of metadata model specifications used in particular to describe the links between resources of Semantic Web. It can also be found in many models such as the models which describe graphs.
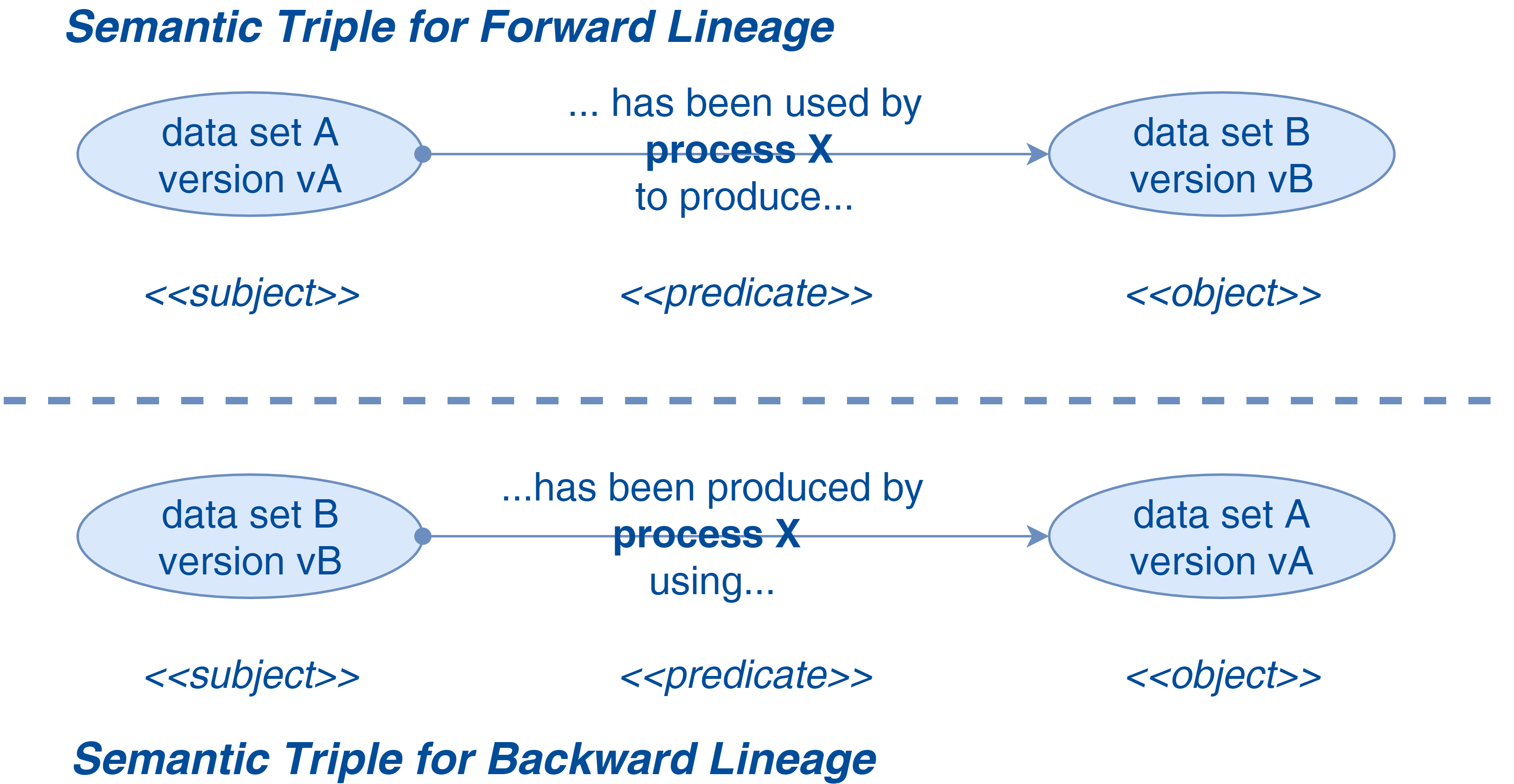
A triple semantics is a set of three entities that transcribe the relationship between them. It takes the form: subject --> predicate --> object. Applied to data lineage, it can be presented in two modes:
- The forward lineage, indicated for propagation analyses, uses a predicate that links data to those produced by a process using it.
- The backward lineage, more appropriate for tracking, uses a predicate that links data to those used to produce it through a process.
If we transpose these principles to the data processing in order to carry out a lineage with the granularity of the data set and its version, the triple semantics can be formulated as follows:"the data set B version vB was produced by the process X version vX using the data set A version vA". This is a backward lineage, the subject being the data set produced (B in vB version), the predicate (or the verb) being "was produced by the X process version vX using" and the object
Each product data set is connected to the source data sets via a process (and vice versa). This approach results in the construction of a cyclical graph oriented or DAG (that is, not containing a closed circuit), allowing to trace from each data set / version to all the data sets used for its generation.
It is interesting to note that in this case (especially at this granularity level), only the I/O of the processes are taken into account, it is not necessary to exploit the data manipulated internally. As seen above, this level of granularity (data set / version) also requires data dynamic lineage so that the implemented mechanism can follow the evolution of the versions without changing model or code.
One of the major difficulties that can be encountered is the management of the version of data set. A multitude of cases can exist and lead to a different strategy, depending on the use case and the architecture adopted. As an illustration of possible strategies, let's take an example where the version of each data set corresponds functionally to the data collected/processed during a given day and is materialized by a simple increment.
It is then possible to adopt two different data addressing strategies, corresponding to two architectural choices:
- The source data sets of different versions are addressed by version: this is the case in particular when the version of the data set to be used by a process is known at launch in a direct or indirect way (provided by a Scheduler operating precise rules of deduction of the version)
- The source data sets of different versions are addressed indiscriminately: this case is more complicated to manage. Without a strategy of transmitting version information to the generated data sets, this ends up in a situation where the generated data sets are going to come from all versions of source data sets (see figure below). A solution based on the following principles can be adopted:
- The version of the data sets generated by a process is, during its execution, calculated according to the versions of the of the source datasets. It is then identical, by version of of the source datasets, for all generated datasets
- In the source group of a process, a single data set, which will be called "reference data set" for the process, must be chosen to port the "reference"version . It is the latter that is propagated as a single version of the generated data sets.
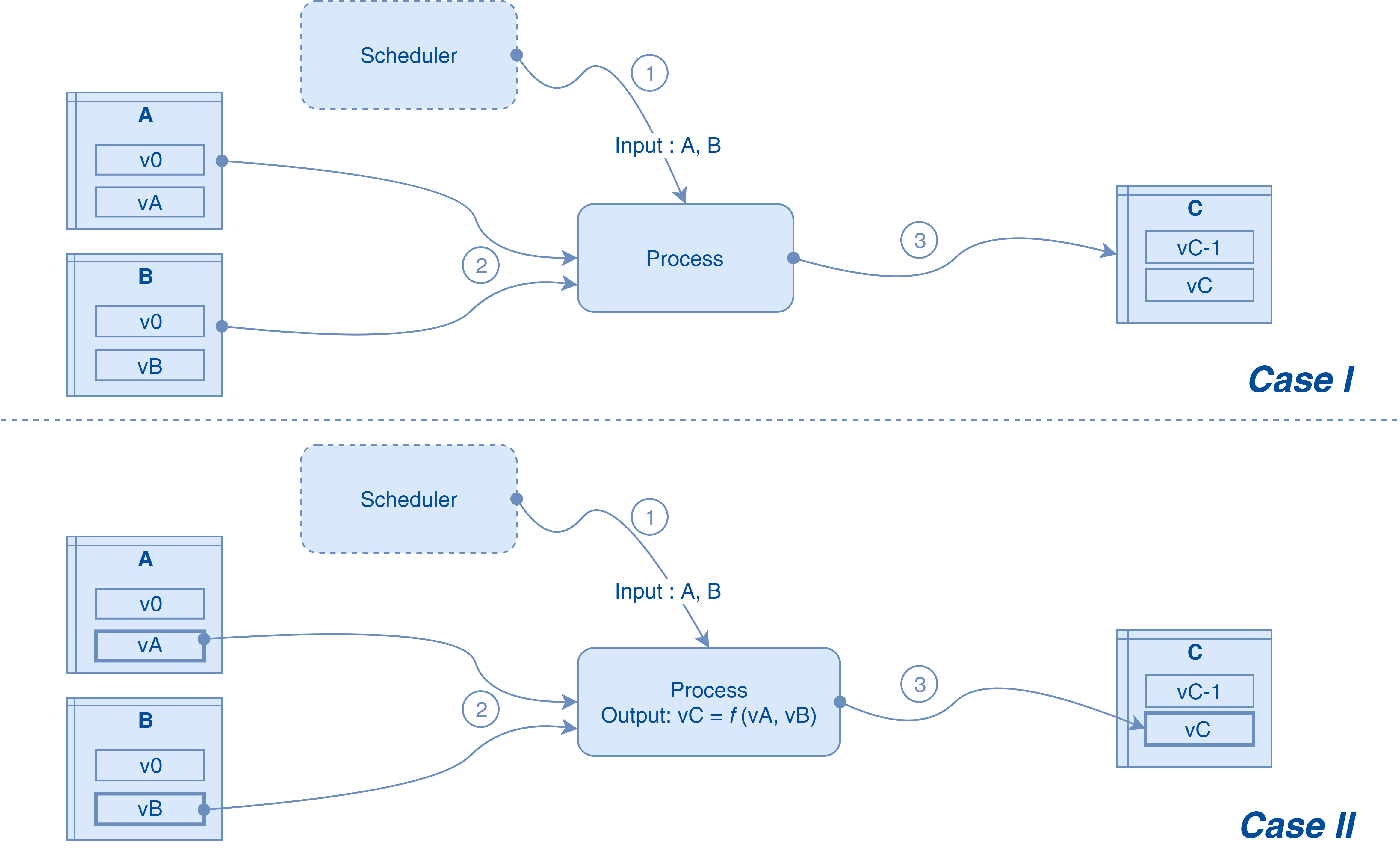
In Case I, the source data sets A and B are addressed without reference to the version. The generated data set C is then dependent on all versions of the data sets A and B. We return to a static lineage situation. In Case II, the source data sets A and B are addressed by version, the vC version of the generated data set C is then calculated according to vA and vB. In our case, we designate a reference data set, e. g. A, and a simple calculation function: vC = vA.
Treatment of a typical case
The following proposal is the result of work carried out in a client's IS, within the framework of a PoC, to provide a solution presenting:
- Minimum footprint for existing and future applications (development effort, maintainability, refactoring, overhead processing,...)
- Remaining compatible with an existing kernel running Spark, without taking risks by integrating exogenous stacks.
- Highly available, resilient, scalable, evolutive, reactive, decoupled, and CQRS compliant architecture of the overall architecture
Functionally, the customer's main motivation was to respond to a legal constraint to allow a full audit of the data origin at the data set level. Operationally, it is a question of obtaining perfect control of the impact perimeter of an action on a data set stamped as critical to ensure a re-generation in all circumstances.
Simplification
Not all of these topics can be addressed in this article. I propose a simplified vision of the problem, focused on the problem of lineage while keeping in mind the constraints mentioned above. The entire demo source code used is available here.
Thus, in this very simplified use case:
- Data sets are read on HDFS and persisted on the same file system.
- The data sets clients-vX and products-vY are used by a first Spark driver (BusinessDriver_One) to produce a composition of this data materialized in the data set namesAndProducts and persisted in the container of the same name. Here, X and Y denote the version of the data set.
- A second driver Business_Driver_Two is responsible for generating from this last data set an aggregated view forming the data set productSummary.
- The drivers are Spark batchs that are potentially released several times a day.
Let's choose the second release propagation strategy mentioned above for our example. The content of the data sets can also change over time, as new versions of the recordings can be written. In this case, it makes sense to include the version of the data set in the record data model, as follows in the case of the data set clients-v15:
{"name":"Bike":"surname":"Mike","product-id":"B12","quantity":"1","version":"15"}
{ "name":"Poll":"Poll","surname":"Kevin":"product-id":"R23","quantity":"2","version":"15" }
It will therefore be necessary to adapt the lineage and persistence mechanism to take into account the possible values of this version. For example, in our case, we chose to use the version as one of the downstream partitioning keys for input files (i. e., namesAndProducts and productSummary) to allow data purge operations based on the data set version.
Datasets lifecycle also means unambiguous identification in the IS of any process instance. This implies that static identification of a process (by the driver class name for a very simplistic example) is not enough. Each instance, i. e. Each effective launch of each driver will have to be uniquely identified. In this example, this instance will be identified by an Run Id compounded with the driver identifier.
Our example is then described in the following diagram:
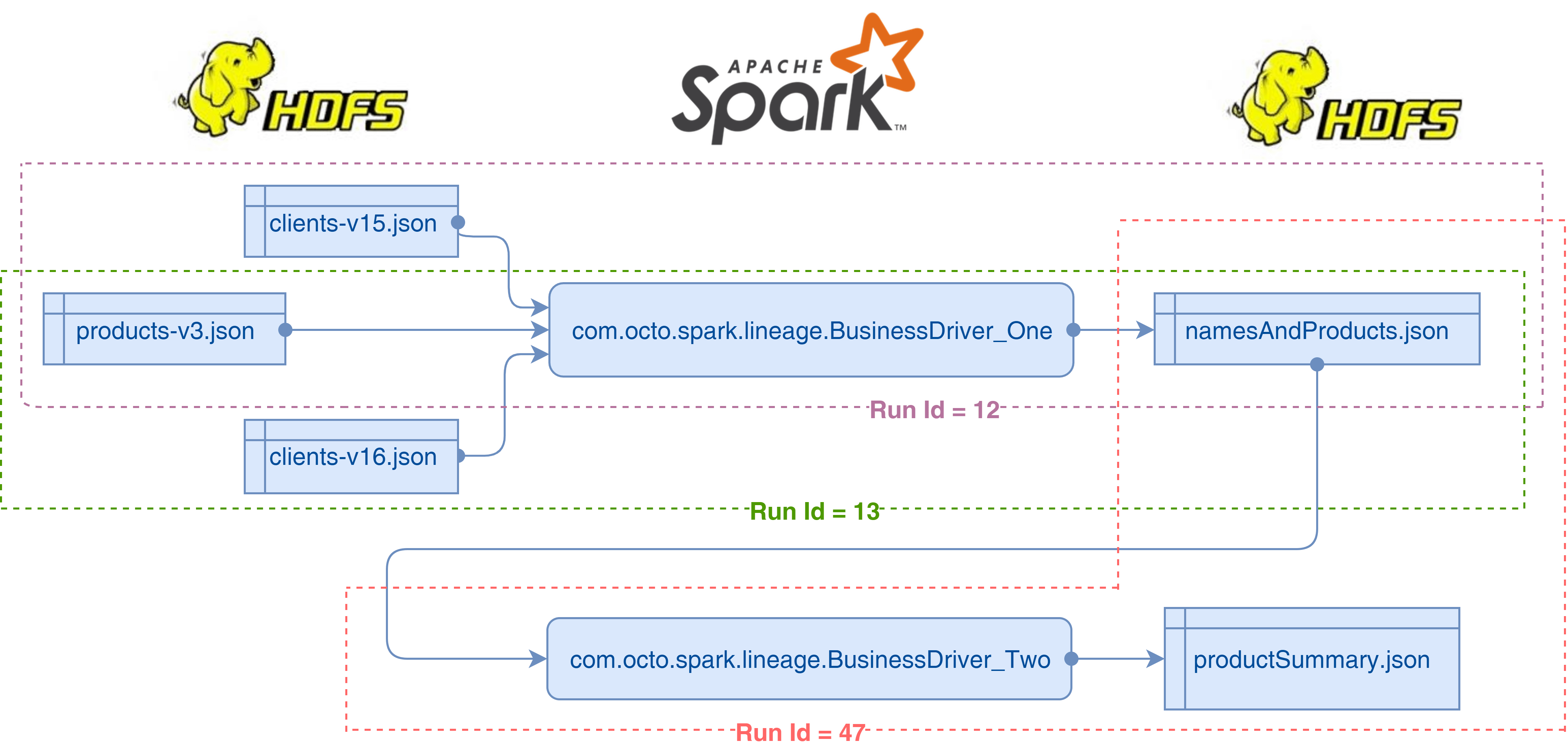
In Run Id 12, the files clients-v15. json and products-v3. json are processed by BusinessDriver_One and then persist in namesAndProducts. json. In the Run Id 13 a new client version is integrated. The Run Id 47 of BusinessDriver_Two intervenes after these two runs to produce an aggregated view of namesAndProducts in productSummary. json.
Spark as a local provider of metadata for lineage
In order to generate lineage information dynamically, the idea is to exploit certain features of the Spark processing engine. Indeed, in one of the phases of preparation of the execution of the treatments in a distributed way, this engine builds in particular a DAG of the transformations carried out which it formalizes in a logical execution plan, which makes it a lineage of the transformations. Since these transformations use input data sets and generate output data sets, we just have to find a way to use this DAG to meet our need to trace the data sets.
In Spark-based industrial processing applications, such as those developed for the Data Hub, the most widely used data containers are the RDD. Since Spark version 2.0, the use of DataFrame and DataSet is growing with the maturity of Spark SQL. In either case, operating the DAG will be done differently.
Use of RDD
On an RDD instance, there is a function toDebugString () that provides a String describing the transformation DAG to obtain this RDD:
(2) ShuffledRDD[29] at reduceByKey at BusinessDriver_One. scala: 46[]
+- (2) UnionRDD[28] at union at BusinessDriver_One. scala: 46[)
| MapPartitionsRDD[13] at map at BusinessDriver_One. scala: 20[)
| MapPartitionsRDD[7] at rdd at AppCore. scala: 52[)
| MapPartitionsRDD[6] at rdd at AppCore. scala: 52[)
| MapPartitionsRDD[5] at rdd at AppCore. scala: 52[)
FileScanRDD[4] at rdd at AppCore. scala: 52[)
| MapPartitionsRDD[27] at map at BusinessDriver_One. scala: 22[)
| MapPartitionsRDD[21] at rdd at AppCore. scala: 52[)
| MapPartitionsRDD[20] at rdd at AppCore. scala: 52[)
MapPartitionsRDD[19] at rdd at AppCore. scala: 52[)
FileScanRDD[18] at rdd at AppCore. scala: 52[)
This function is intended for debugging and does not provide structured information. I have reproduced the exact logic of Spark 2 to provide, through a RDD parameter, the lineage tree of these treatments. This gives for the same RDD (see function >RDDLineageExtractor. lineageTree ()):
(2) ShuffledRDD[29] at reduceByKey at BusinessDriver_One. scala: 46[]
UnionRDD[28] at union at BusinessDriver_One. scala: 46[)
MapPartitionsRDD[13] at map at BusinessDriver_One. scala: 20[)
MapPartitionsRDD[7] at rdd at AppCore. scala: 52[])
MapPartitionsRDD[6] at rdd at AppCore. scala: 52[])
MapPartitionsRDD[5] at rdd at AppCore. scala: 52[])
FileScanRDD[4] at rdd at AppCore. scala: 52[)
MapPartitionsRDD[27] at map at BusinessDriver_One. scala: 22[)
MapPartitionsRDD[21] at rdd at AppCore. scala: 52[])
MapPartitionsRDD[20] at rdd at AppCore. scala: 52[])
MapPartitionsRDD[19] at rdd at AppCore. scala: 52[])
FileScanRDD[18] at rdd at AppCore. scala: 52[)
This function can then be used in a centralized code, such as the generic kernel of applications (here symbolized by the class AppCore), to be invoked for each action (typically an I/O) of any executed driver. The lineage information, including the processing tree, is then generated by invoking the same function (here lineSparkAction()) when reading a JSON, just after building the corresponding RDD and writing an RDD, just before its persistence:
def writeJson (rdd: RDD[_ < Row], outputFilePath: String): Unit = {
lineSparkAction (rdd, outputFilePath, IoType. WRITE)
val schema = rdd. take (1)(0). schema.
spark. createDataFrame (rdd. asInstanceOf[RDD[Row]], schema). write. json (outputFilePath)
}
def readJson (filePath: String): RDD[Row] = {
val readRdd = spark. read. read. json (filePath). rdd
lineSparkAction (readRdd, filePath, IoType. READ)
readRdd
}
The lineage function has three responsibilities: to generate the processing tree by the function lineageTree() , to generate the meta data of the data set (whether it is input or output, everything depends on the direction of the I/O) by analyzing the RDD and the target container and, finally, to produce the lineage messages by exploiting all these data. In our case, and for the sake of simplicity, these messages are also persisted on HDFS. However, one can imagine many other patterns beyond the scope of this article.
private def lineSparkAction (rdd: RDD[_ < Row], outputFilePath: String, ioType: IoType. Value) = {
val rddLineageTree: TreeNode[String] = RDDLineageExtractor. lineageTree (rdd)
val datasetMetadata: (String, String) = getDatasetMetadata (rdd, outputFilePath)
val processInformation: String = processId
produceLineageMessage (rddLineageTree, datasetMetadata, processInformation, ioType)
}
Use of DataFrame (or DataSet)
When using Spark SQL DataFrame (or DataSet), the task is greatly simplified. Since Spark version 2, processing lineage information is provided directly from the DataFrame API. For a given DataFrame, the inputFiles () method returns a table of the data sources used to generate this DataFrame. Therefore, it is sufficient to intercept only the outputs to generate the lineage information. The immediate impact is that fewer lineage messages are generated.
def readJsonDF (filePath): DataFrame = {
spark. read. json (filePath)
}
def writeJson (df: DataFrame, path: String, lineData: Boolean = true, saveMode: SaveMode = SaveMode = SaveMode Overwrite): Unit = {
if (lineData) lineSparkAction (df, path, IoType. WRITE)
df. write. mode (saveMode = saveMode). json (path)
}
Keep in mind: "Depending on the source relations, this may not find all input files". The designer/developer must verify that the various data sources used are well traced.
Contents of lineage information
The generated lineage messages must contain the information needed to build in detail the semantic triples needed to build the data set lineage graph. A sufficient but not exhaustive list of information to be included is:
- Univocal process definition
- Full name of the driver class
- Run Id
- Application domain identifier (e. g. group-id maven)
- Application module identifier (e. g. application-id maven)
- The version of the application
- Univocal definition of the data sets
- Identifier (e. g. table name)
- URI (e. g. full URL on HDFS)
- version (the version of the data set with the target granularity)
- I/O type (read or write) I/O type
- initial lifecycle status
- Springs and wells (sink) lineage
- In the case of an I/O in writing:
- The "destination" of the treatment generating the lineage message (so-called well or sink), corresponding to the root of the lineage tree
- The "origins" of the processing generating the lineage message (sources), corresponding to the leaves of the tree
- In the case of a read I/O
- Sources only (leaves of tree)Sources only
- In the case of an I/O in writing:
The lifecycle status being precisely a meta-data that will evolve with the functional lifecycle of the data set (e. g. go from a "given" state to "critical data").
In our case, the identification of the process in the lineage messages has been simplified to its strict minimum. Thus, only the class name and the Run Id run are used. The rest of the information to be identified in the method lineSparkAction () is not a technical challenge.
+----------------+------+--------------------------------------------+---------+-----------------------------------------------------------------+------------------------------------------------------------------------------------------+-------+------------------------------------------------------------------------------------+-------+
|datasetName |ioType|producer |reference|sinks |sources |status |uri |version|
+----------------+------+--------------------------------------------+---------+-----------------------------------------------------------------+------------------------------------------------------------------------------------------+-------+------------------------------------------------------------------------------------+-------+
|namesAndProducts|WRITE |com.octo.spark.lineage.BusinessDriver_One$13|false |(1) MapPartitionsRDD[29] at map at BusinessDriver_One.scala:52 []|FileScanRDD[4] at rdd at AppCore.scala:45 [],FileScanRDD[16] at rdd at AppCore.scala:45 []|Initial|data-lineage-spark-demo/src/main/resources/examples/generated2/namesAndProducts.json|16 |
|namesAndProducts|WRITE |com.octo.spark.lineage.BusinessDriver_One$12|false |(1) MapPartitionsRDD[29] at map at BusinessDriver_One.scala:52 []|FileScanRDD[4] at rdd at AppCore.scala:45 [],FileScanRDD[16] at rdd at AppCore.scala:45 []|Initial|data-lineage-spark-demo/src/main/resources/examples/generated2/namesAndProducts.json|15 |
|productSummary |WRITE |com.octo.spark.lineage.BusinessDriver_Two$47|false |(1) MapPartitionsRDD[13] at map at BusinessDriver_Two.scala:28 []|FileScanRDD[4] at rdd at AppCore.scala:50 [] |Initial|data-lineage-spark-demo/src/main/resources/examples/generated2/productSummary.json |16 |
|namesAndProducts|READ |com.octo.spark.lineage.BusinessDriver_Two$47|true | |FileScanRDD[4] at rdd at AppCore.scala:50 [] |Initial|data-lineage-spark-demo/src/main/resources/examples/generated2/namesAndProducts.json|16 |
|products-v3 |READ |com.octo.spark.lineage.BusinessDriver_One$12|false | |FileScanRDD[16] at rdd at AppCore.scala:45 [] |Initial|data-lineage-spark-demo/src/main/resources/examples/raw/products-v3.json |3 |
|products-v3 |READ |com.octo.spark.lineage.BusinessDriver_One$13|false | |FileScanRDD[16] at rdd at AppCore.scala:45 [] |Initial|data-lineage-spark-demo/src/main/resources/examples/raw/products-v3.json |3 |
|clients-v15 |READ |com.octo.spark.lineage.BusinessDriver_One$12|true | |FileScanRDD[4] at rdd at AppCore.scala:45 [] |Initial|data-lineage-spark-demo/src/main/resources/examples/raw/clients-v15.json |15 |
|clients-v16 |READ |com.octo.spark.lineage.BusinessDriver_One$13|true | |FileScanRDD[4] at rdd at AppCore.scala:45 [] |Initial|data-lineage-spark-demo/src/main/resources/examples/raw/clients-v16.json |16 |
+----------------+------+--------------------------------------------+---------+-----------------------------------------------------------------+------------------------------------------------------------------------------------------+-------+------------------------------------------------------------------------------------+-------+
One quickly realizes the incomplete side of messages: many messages (those in reading) do not include "sinks". In this case, in order to build the lineage graph, it is necessary to carry out a consolidation step. It consists of linking source nodes to well nodes by analyzing the graphs built from messages.
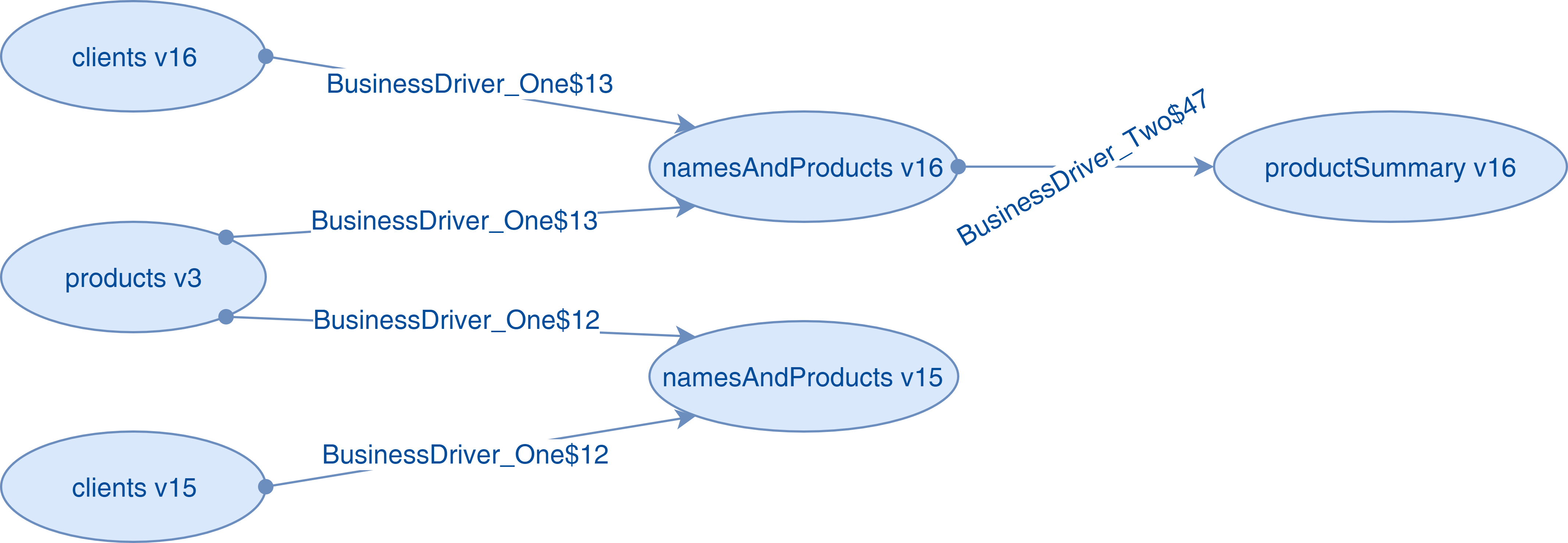
Once this consolidation step is completed, and once the graph has been constructed (class LineageGraphGenerator), we obtain the following lineage for our example:
Node[0]--->[Dataset: namesAndProducts, Version: 16] has been produced by:
[com. octo. spark. lineage. BusinessDriver_One$13] using:[Dataset: products-v3, Version: 3]
[com. octo. spark. lineage. BusinessDriver_One$13] using:[Dataset: clients-v16, Version: 16]
Node[1]--->[Dataset: namesAndProducts, Version: 15] has been produced by:
[com. octo. spark. lineage. BusinessDriver_One$12] using:[Dataset: products-v3, Version: 3]
[com. octo. spark. lineage. BusinessDriver_One$12] using:[Dataset: clients-v15, Version: 15]
Node[2]---->[Dataset: productSummary, Version: 16] has been produced by:
[com. octo. spark. lineage. BusinessDriver_Two$47] using:[Dataset: namesAndProducts, Version: 16]
Presented graphically (by truncating class names for readability), this corresponds to the following:
Exploitation of the lineage graph
This lineage graph can then be used to manage the data lifecycle at the data set level. For example, suppose that only the data set productSummary in version 16 should be retained in the long term because it is considered as a critical data by the business. In parallel, we want to delete in a purge process the older versions of the data sets clients and products. To what extent can this deletion be achieved without jeopardizing the possibility of recovery (as in the case of a PRA) of the data productSummary?
The answer to this question is to carry out an impact analysis on the lineage graph. This analysis is based on the identification of connected components (connected components) by implementing the algorithm of the same name using a graphically oriented database engine. The engine used in our case (always in the class LineageGraphGenerator) being Neo4j, via a very simplistic integration for the needs of the article. This algorithm then provides a subgraph that allows you to know all the connected data sets / source versions with productSummary in version 16, i. e. clients v16 and products v3.
This is where the attribute "status" added to the data model of the lineage messages comes in. By default, all nodes are assigned the "Test"value. If a data set is declared "critical" by the business line, a specific department will have to update the corresponding node in the graphical database accordingly. The same service will request this database to get the connected data sets and tag them as "critical". The purge service will have to systematically check the status of a data set / version and not delete it if its status is "critical".
The subject is vast and involves profound impacts, both on the architectural level, development management and data governance. In this article, however, we have cleared some of the key aspects of data lineage at the data set level, namely the following:
- the possibility - for the moment - to implement in-house the solution if the tracking granularity is relatively fine
- the theory on which to base the thinking
- the possibility of using Spark's interesting features to integrate this logic in the central parts of processing applications
- how they can fit into the code with the treatment of a typical case
- version management strategy for data sets
- the structure of the lineage message structure
- the exploitation of these messages to build the lineage graph
- an exploitation track of the graph