How to “crunch” your data stored in HDFS?
HDFS stores huge amount of data but storing it is worthless if you cannot analyse it and obtain information.
Option #1 : Hadoop : the Map/Reduce engine
Hadoop Overview
Hadoop is a Map/Reduce framework that works on HDFS or on HBase. The main idea is to decompose a job into several and identical tasks that can be executed closer to the data (on the DataNode). In addition, each task is parallelized : the Map phase. Then all these intermediate results are merged into one result : the Reduce phase.
In Hadoop, The JobTracker (a java process) is responsible for monitoring the job, managing the Map/Reduce phase, managing the retries in case of errors. The TaskTrackers (Java process) are running on the different DataNodes. Each TaskTracker executes the tasks of the job on the locally stored data.
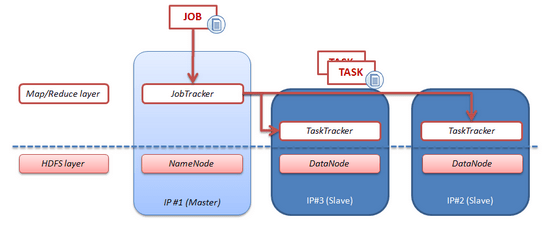
Hadoop also provides tools to supervise current jobs and hadoop engine (http://localhost:50030/jobtracker.jsp).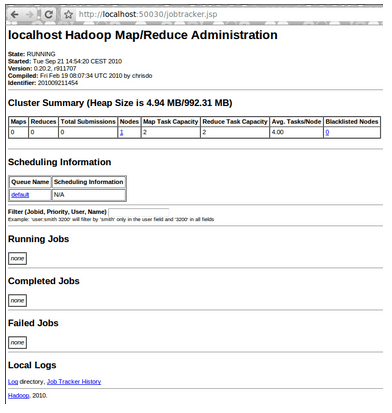
Data and process co- localization
HDFS and Hadoop have been designed to avoid data transit over the network and so, limiting the high-bandwith consumption. This pattern is often called “localization” and is frequently implemented in number of data or calculation grids. The main idea is that instead of moving the data from the storage layer to the application layer (and thus consuming bandwidth), the processes are pushed to the storage layer, closer to where the data is physically stored. In a certain way, this is what SQL does in the relational world.
Thus, each process works with the locally stored data.
Querying data using Hadoop
Let’s say you have the following sample stored in HDFS and you would like to get the total amount (CREDIT - DEBIT) of all these lines aggregated by currency (EUR, USD...).
GED EQSWAP John 13/09/2010 EUR 10000 Debit SG
GED EQSWAP John 15/09/2010 EUR 10200 Credit SG
GED SWAPTION John 14/09/2010 EUR 11000 Credit HSBC
GED SWAPTION John 15/09/2010 EUR 5500 Debit HSBC
GED SWAPTION John 16/09/2010 EUR 5500 Debit HSBC
GED SWAPTION John 15/09/2010 EUR 11000 Debit HSBC
GED SWAPTION John 16/09/2010 EUR 5500 Credit HSBC
GED SWAPTION John 17/09/2010 EUR 5500 Credit HSBC
IRD IRS Simon 13/09/2010 USD 10000 Debit SG
IRD IRS Simon 15/09/2010 USD 10200 Credit SG
IRD IRS Simon 14/09/2010 USD 11000 Credit BankofAmerica
IRD IRS Simon 15/09/2010 USD 5500 Debit BankofAmerica
IRD IRS Simon 16/09/2010 USD 5500 Debit BankofAmerica
...
Here is what you will have to write in Hadoop...
The Map phase : create maps in which the key will be the currency and the value the signed amount The Mapper will read the specified input file and call the map() method for each line of the file.
/**
* Key In, Value In, Key out, Value out
*/
public static class Map extends MapReduceBase implements Mapper {
public void map(LongWritable key, Text value, OutputCollector output, Reporter reporter) throws IOException {
String line = value.toString();
String[] lineAsArray = line.split("\t");
String currentCurrency = lineAsArray[4];
String amountAsString = lineAsArray[5];
String sens = lineAsArray[6];
DoubleWritable data = null;
if("Debit".equals(sens)){
data = new DoubleWritable(Double.parseDouble("-" + amountAsString));
}
else if("Credit".equals(sens)) {
data = new DoubleWritable(Double.parseDouble(amountAsString));
}
output.collect(new Text(currentCurrency), data);
}
}
The Reduce phase : sum all the operations grouped by currency The Reducer will then collect all the previously created map on the different nodes and do what you define in the reduce() method. The reduce() method is called for each key specified as output of the map. In our case, we have two different keys : the two distinct currencies. So the reduce() method is called twice with this kind of map
EUR -10000,10200,11000...
USD 10000,...
The “values” argument (see the code sample beside) of the reduce() method is the list of amount grouped by key. Hadoop has sorted the data this way for you :
//The reduce is called once per key in the output map of the map() function
public static class Reduce extends MapReduceBase implements Reducer {
public void reduce(Text key, Iterator values, OutputCollector output, Reporter reporter) throws IOException {
double sum = 0;
while (values.hasNext()) {
double amount = values.next().get();
sum += amount;
}
output.collect(key, new DoubleWritable(sum));
}
}
Run the job on Hadoop Then of course, you have to code the main class that specifies job configuration, can overwrite default xml configuration...
public class CurrencyAggregate extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception{
JobConf conf = new JobConf(CurrencyAggregate.class);
conf.setJobName("CurrencyAggregate");
//output of the Mapper
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(DoubleWritable.class);
conf.setMapperClass(Map.class);
conf.setReducerClass(Reduce.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(args[0]));
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
JobClient.runJob(conf);
return 0;
}
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run(new CurrencyAggregate(), args);
System.exit(exitCode);
}
Note : To develop your job, you can work locally using the Standalone Operations defined here. In that case, the master and slaves are configured as “local” and therefore, Hadoop uses the local file system and not HDFS.
You can then launch your job on Hadoop with the following command line (the first argument is the input file, the second one the folder where the results will be stored) :
$HADOOP_HOME/bin/hadoop jar ./Currency.jar org.CurrencyAggregate /tmp/cashflow-clean.txt /tmp/output10
and you get the following results in the folder /tmp/output10/part-00000
EUR 200.0
USD 200.0
Hadoop Installation & Configuration
To run Hadoop, you need a proper installation of HDFS. You also need to modify the mapred-site.xml file on all machines to define the JobTracker :
mapred.job.tracker
master:9001
Thus, you are able to define other properties in it : - mapred.local.dir , the local directory where temporary MapReduce data is stored. It also mahy be a list of directories. - mapred.map.tasks and mapred.reduce.tasks, the number of map or reduce tasks
Once the Hadoop cluster is configured, you can start Hadoop with the following command ( (HDFS must be running)
$HADOOP_HOME/bin/start-mapred.sh
Option #2 - Doing Map/Reduce can be complex, so we need a “DSL” : Hive or Pig
There are two high-level languages that have been developed to work on top of Hadoop: - Pig which provides a specific script language. Unfortunately, I do not have enough time to investigate this further for the moment. I will try to do so in a near future. - Hive which provides a limited SQL-like language (for instance, Date type is not supported...).
Hive Overview and Usage
Hive works on top of Hadoop and transforms Hive Query Langage statements into Map/Reduce jobs.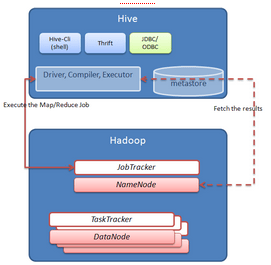
source : http://wiki.apache.org/hadoop/Hive/Design
The Driver, Compiler and Executor components are responsible for receiving, parsing the query and generating a set of map/reduce job, dfs operations... The metastore stores the information on the different “tables”, “columns” stored in the HDFS warehouse. This link provides a deep overview of Hive. Hive supports different data types : INT, STRING, DOUBLE.
So, you can define tables in the same way as you will think of tables in the relational paradigm. Hive does not manage Date type so you will have to use timestamp instead...Thus my previous file...
GED EQSWAP John 13/09/2010 EUR 10000 Debit SG
GED EQSWAP John 15/09/2010 EUR 10200 Credit SG
...
...has to be converted this way...
GED EQSWAP John 1284354000 EUR 10000 Debit SG
GED EQSWAP John 1284526800 EUR 10200 Credit SG
...
Then, you can create the table
CREATE TABLE cash_flow (BookID STRING, ProductID STRING, TraderID STRING, DueDate BIGINT,
Currency STRING, Amount DOUBLE, Direction STRING, Counterparty STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
LINES TERMINATED BY '\n' STORED AS TEXTFILE;
Load data into these tables from you local file system. The file will then be put into HDFS (typically in the folder /user/hive/warehouse) :
LOAD DATA LOCAL INPATH '/home/user/cash-flow/cashflow-clean.txt'
OVERWRITE INTO TABLE cash_flow;
from HDFS if your datas are already on HDFS
LOAD DATA INPATH '/data/cashflow-clean.txt'
OVERWRITE INTO TABLE cash_flow;
or without overwriting the datas
LOAD DATA LOCAL INPATH '/home/user/hive/build/dist/examples/files/ml-data/u_2.data'
INTO TABLE u_data;
note : I have still not tested it but Cloudera provides Sqoop: a tool designed to import relational database into Hadoop or even Hive...It also seems that Sqoop offers the capability to export Map/Reduce results into a relational database.
Select datas into these tables in SQL manner
Remember the sample written in option#1. You can then easily get the sum of all the operations ‘Credit’ grouped by currencies
select Currency, sum(Amount)
from cash_flow where Direction='Credit' group by Currency;
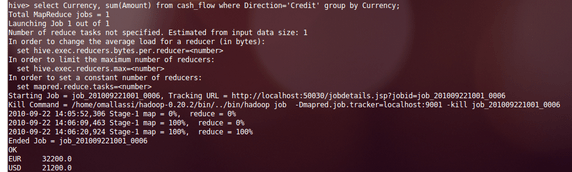
or filtering them by due date
select Currency, sum(Amount)
from cash_flow
where Direction='Credit' AND DueDate < = unix_timestamp('2010-09-15 00:00:00')
group by Currency;
You can then run the same query with the operation in “Debit” and you will get your balance. You can even join tables
SELECT cash_flow_simple.*,user_simple.*
FROM cash_flow_simple
JOIN user_simple ON (cash_flow_simple.TraderID=user_simple.UserID);
Hive provides other complex functions like sub queries, union, partitions, different relational, arithmetic or operational operators and mathematical or date functions...And in the case you have more specific needs, you can also define your own functions and extend Hive functionalities.
Hive clients : Hive-cli, JDBC, ODBC...
To connect to Hive, you have several options. The simplest one is certainly the Hive-Cli (or even the web client interface); a shell that enables you to query your HDFS. But moreover, you can use JDBC (need to start a Hive Server $HIVE_HOME/build/dist/bin/hive --service hiveserver) to connect to Hive : a way to build great user interface on top of your HDFS.
note : when writing these couple of lines, the trunk version of Hive does not compile with the version 0.21.0 of Hadoop. https://issues.apache.org/jira/browse/HIVE-1612. PreparedStatement are not implemented in the 0.7.0 version of the Hive JDBC Driver
Hive installation
Once again, Hive installation is not a big deal and all is well explained here Of course, you need the Hadoop distribution installed on the machines, define a couple of constants like HADOOP_HOME and HIVE_HOME... By default, Hive will store the data on HDFS in the folder /user/hive/warehouse
./bin/hadoop fs -mkdir /user/hive/warehouse
./bin/hadoop fs -chmod g+w /user/hive/warehouse
aka. the hive.metastore.warehouse.dir property that can be overridden in the hive-site.xml configuration file.
From an operational point of view, Adobe released a couple of puppet scripts to manage Hadoop cluster or dynamically add slave nodes.
Hadoop, Hive and Pig use-cases
There are several companies that use Hadoop and Hive or Pig to collect and analyse data. Of course, Yahoo! has one of the biggest data warehouse with more than 12 Petabytes of datas. Twitter collects 300Go per hours Facebook stores 12 To per day and provides an easier access to the data warehouse (200 persons / month use Hive) There are also "smaller" companies that use Hadoop. Last.fm uses Hadoop for site stats, chart, reporting, index search...Orbitz stores 500Go per day in Hadoop and provides lots of statistics by integrating the R-project. Research field is also using Hadoop (http://www.opensciencegrid.org/....).
Software companies are also deeply interested in Hadoop. IBM has developped a product based on Hadoop named IBM Infosphere BigInsights...Teradata has announced [https://blog.octo.com/teradata-cloudera-partenariat-autour-de-data-warehousing-et-de-hadoop/] its willingness to use Hadoop. Pentaho begins to offer an integration between Hive and its reporting or BI Suite.
Remember, noSQL is also about Business Intelligence...