How does it work? Docker! Part 2: Swarm networking
Hey there!
TL;DR
I hacked another thing together, this time in order to install a highly available Docker Swarm cluster on CoreOS (yeah, Container Linux), using Ansible.
The whole subject was way too long for a single article. Therefore, I’ve divided it into 5 parts. This is episode 2, regarding Swarm networking.
If you want to try it:
git clone https://github.com/sebiwi/docker-coreos.git
cd docker-coreos
make up
You will need Ansible 2.2+, Docker, Vagrant and Molecule
So what about networking then?
Right, networking. From a previous article on Kubernetes Networking:
“For each container that is created, a virtual ethernet device is attached to this bridge, which is then mapped to eth0 inside the container, with an ip within the aforementioned network range. Note that this will happen for each host that is running Docker, without any coordination between the hosts. Therefore, the network ranges might collide.
Because of this, containers will only be able to communicate with containers that are connected to the same virtual bridge. In order to communicate with other containers on other hosts, they must rely on port-mapping. This means that you need to assign a port on the host machine to each container, and then somehow forward all traffic on that port to that container. What if your application needs to advertise its own IP address to a container that is hosted on another node? It doesn’t actually knows its real IP, since his local IP is getting translated into another IP and a port on the host machine. You can automate the port-mapping, but things start to get kinda complex when following this model."
That’s why Kubernetes chose simplicity and skipped the dynamic port-allocation deal. It just assumes that all containers can communicate with each other without Network Address Translation (NAT), that all containers can communicate with each node (and vice-versa), and that the IP that a container sees for itself is the same that the other containers see for it”
Docker doesn’t do this. They just went nuts and decided to go crazy on the dynamic port-forwarding part. For this, they relied heavily on the existing Linux kernel’s networking stack. This is fairly cool, since the existing Linux networking features are pretty mature and robust already.
In order to provide its networking, Docker uses numerous Linux networking tools as building blocks to handle all of its forwarding, segmentation and management needs. Primarily, the most used tools are Linux bridges, network namespaces, virtual ethernet devices and iptables.
A Linux bridge is a virtual implementation of a physical switch inside of the Linux kernel. It forwards traffic basing itself on MAC addresses, which are in turn discovered dynamically by inspecting traffic.
A network namespace is an isolated network stack with its own collection of interfaces, routes and firewall rules. Network namespaces are used to provide isolation between processes, analog to regular namespaces They ensure that two containers, even if they are on the same host, won’t be able to communicate with each other unless explicitly configured to do so.
Virtual ethernet devices or veth are interface that act as connections between two network namespaces. They have a single interface in each namespace. When a container is attached to a Docker Network, one end of the veth is placed inside the container under the name of ethx, and the other is attached to the Docker Network.
Iptables is a package filtering system, which acts as a layer 3/4 firewall and provide packet marking, masquerading and dropping features. The native Docker Drivers use iptables in heavy amounts in order to do network segmentation, port mapping, mark traffic and load balance packets.
Now that you know all that, let’s talk about models.
Give me some CNM!
I talked to you about the Container Network Interface (CNI) when talking about Kubernetes on a previous article. Docker uses a different standard, called the Container Network Model (CNM) which is implemented by Docker’s libnetwork.
There are three main components of the CNM model: Sandboxes, Endpoints and Networks.
![]()
The Sandbox contains the configuration of the container’s network stack, such as interface management, IP and MAC addresses, routing tables and DNS settings. A Sandbox may contain endpoints from multiple networks.
The Endpoint connects a Sandbox to a Network. An Endpoint can belong to only one Network, and one Sandbox. It gives connectivity to the services that are exposed in a Network by a container.
The Network is a collection of Endpoints that are able to talk to each other. A Network consists of many endpoints. Each one of these components has an associated CNM object on libnetwork and a couple of other abstractions that allow the whole thing to work together nicely.
The NetworkController object exposes an API entrypoint to libnetwork, which users (like the Docker Engine) use in order to allocate and manage Networks. It also binds a specific driver to a network. The Driver object, not directly visible to the user, makes Networks work in the end. It is configured through the NetworkController. There are both native Drivers (such as Bridge, Host, None, Overlay, and MACVLAN) and remote (from plugin providers) that can be used for different situations depending on your needs. Basically the Driver owns a network and handles all of its management.
The Network object is an implementation of the Network component. It is created using the NetworkController. The corresponding Driver object will be notified upon its creation, or modification. The Driver will then connect Endpoints that belong to the same Network, and isolate those who belong to different ones. This provided connectivity can span many hosts, therefore, the Network object has a global scope within a cluster.
The Endpoint object is basically a Service Endpoint. A Network object provides an API to create and manage Endpoints. It can only be attached to one Network. It provides connectivity from and to Services provided by other containers in the Network. They are global to the cluster as well, since they represent a Service rather than a particular container.
The Sandbox object, much like the component described above, represents the configuration of the container’s network stack, such as interface management, IP and MAC addresses, routing tables and DNS settings. It is created when a user requests an Endpoint creation on a Network. When this happens, the Driver in charge of the Network allocates the necessary network resources, such as an IP address, and passes that information, labeled as SandboxInfo back to libnetwork, which will in turn use the specific OS tools to create the network configuration on the container that correspond to the previously mentioned Sandbox. A Sandbox object may have multiple Endpoints, and therefore, may be connected to multiple Networks. Its scope is local, since it is associated to a particular container on a given host.
As I said earlier, there are two basic type of Drivers: native and remote. Native Drivers don’t require any extra modules and are included in the Docker Engine by default.
Native Drivers include: Host, Bridge, Overlay, MACVLAN and None.
When using the Host driver, the container uses the Host’s network stack, without any namespace separation, and while sharing all of the host’s interfaces.
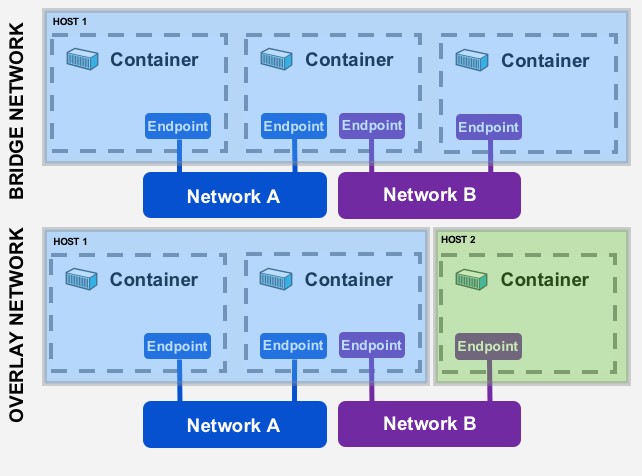
The Bridge driver creates a Docker-managed Linux bridge on the Docker host. By default, all containers created on the same bridge can talk to each other.
The Overlay driver creates an overlay network that may span over multiple Docker hosts. It uses both local Linux bridges and VXLAN to overlay inter-container communication over physical networks.
The MACVLAN driver uses the MACVLAN bridge mode to establish connections between container interfaces and parent host interfaces. They can be used to assign IP addresses that are routable on physical networks to containers.
The None driver gives a container its own network stack and namespace, without any interfaces. Therefore, it stays isolated from every other Network, and even its own host’s network stack.
Remote drivers are created either by vendors or the community. The Remote Drivers that are compatible with CNM are contiv, weave, calico (which we used on our Kubernetes deployment!) and kuryr. I won’t be talking about these since we will not be using them.
Different networks drivers have different scopes. We will talk about overlay networks, since they hold a “swarm” scope, which means that they have the same Network ID through the cluster, and which is what we wanted to explain in the first place.
Overlay Networks!
How come you don’t need a key-value datastore, you say? It’s all because of Docker’s Network Control Plane. It manages the state of Docker Networks within a Swarm cluster, while also propagating control-plane data. It uses a gossip protocol to propagate all the aforementioned information. It is scoped by Network, which is quite cool since it dramatically reduces the amount of updates a host receives.
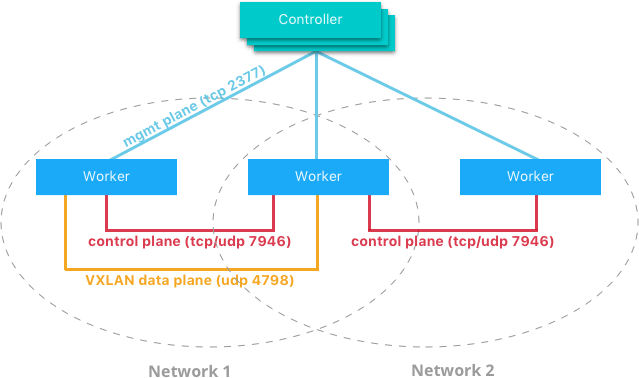
It is built upon many components that work together in order to achieve fast convergence, even in large scale clusters and networks.
Messages are passed in a peer-to-peer fashion, expanding the information in each exchange to an even larger group of nodes. Both the intervals of transmission and the size of the peering groups are fixed, which helps keeping the network usage in check. Network failures are detected using hello messages which helps to rule out both link congestion and false node failures. Full state syncs are done often, in order to achieve consistency faster and fix network partitions. Also, topology-aware algorithms are used in order to optimise peering groups using relative latency as criteria.
Overlay networks rely heavily on this Network Control Plane. It uses standard VXLAN to encapsulate container traffic and send it to other containers. Basically, VXLAN is an encapsulation format that wraps Layer 2 segments with an IP/UDP header, and then send it over Layer 3 networks. In this case, the Layer 2 frames come from a container. This “underlay” header provides transportation between hosts on the underlay network, while the overlay is the stateless VXLAN tunnel, that exists as point-to-multipoint connections between each host participating in the overlay network.
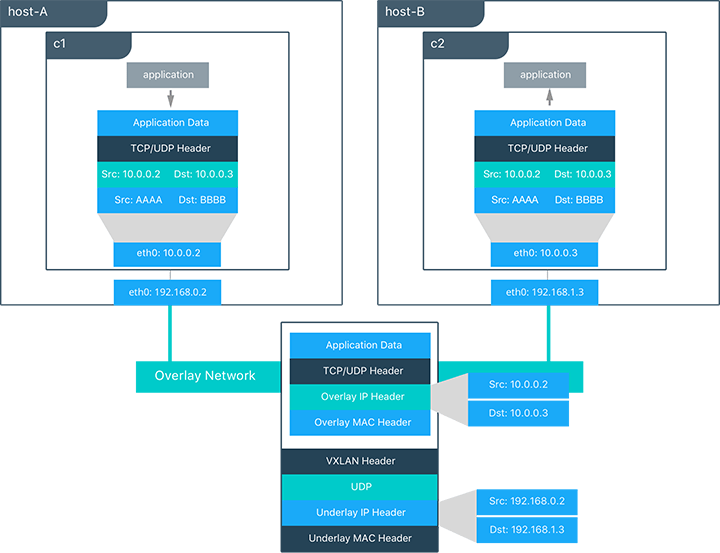
For example, in the previous diagram:
- c1 is sending c2 packets through a shared overlay network. What happens is that c1 does a DNS lookup for c2. They are both on the same overlay network, so the Docker Engine local DNS service resolves c2 to 10.0.0.3, its overlay address.
- C1 generates an L2 frame destined for the MAC address of c2.
- The overlay network driver then encapsulates the frame with a VXLAN header, with the physical address of host-B, which he knows by knowing the state and location of every VXLAN tunnel endpoint through the control plane.
- The packet is then sent and routed as a normal packet using the physical network.
- Finally, the packet is received by host-B, decapsulated by the overlay network driver, and passed on to c2.
This whole process seriously resembles the SDN protocol implemented by flannel, described on the Kubernetes networking part of its “How does it work” series, with flanneld replacing the overlay network driver. Neat, huh? Great minds think alike.
What about the driver itself? It automates all the VXLAN configuration needed for an overlay network. When creating the network, the Docker Engine creates the necessary infrastructure on each host. A Linux bridge is created for each overlay network, with its associated VXLAN interfaces. The overlay is only instantiated on hosts when a container that belongs to the network is scheduled on the host, preventing unnecessary spreading of the overlay networks when they are not needed.
When a container is created, at least two network interfaces are created inside of it: one that connects it to the overlay bridge, and the other to the docker_gwbridge. The overlay bridge is the ingress/egress point to the overlay network that the VXLAN encapsulates. It also extends the overlay across all the hosts that participate in this particular overlay. There is one per overlay subnet on each host, with the same name as the overlay network. The docker_gwbridge is the egress bridge for all the traffic that leaves the cluster. There is only one docker_gwbridge per host. Container-to-container traffic flows do not go through this bridge.
As I said before, overlay networks span multiple Docker hosts. They can be either managed by a Swarm cluster on Swarm Mode, or without it. Nevertheless, when you’re not using Swarm Mode, you will need a valid key-value store service (etcd, Consul or zookeeper) in order for the network to work properly. This mode of operation is not encouraged by Docker, and it might even be deprecated in the future (which further discredits the whole “we’re not deprecating Swarm Standalone” argument).
Cool stuff
That’s all for the networking part. I’ll talk to you about service discovery, load-balancing and security on the next one. Don’t go anywhere!