How does it work? Docker! Part 1: Swarm general architecture
Hey there!
TL;DR
I hacked another thing together, this time in order to install a highly available Docker Swarm cluster on CoreOS (yeah, Container Linux), using Ansible.
If you want to try it:
git clone https://github.com/sebiwi/docker-coreos.git cd docker-coreos make up
You will need Ansible 2.2+, Docker, Vagrant and Molecule
Why?
Well, [I did the same thing with Kubernetes a while ago](http://Hey there! TL;DR I hacked another thing together, this time in order to install a highly available Docker Swarm cluster on CoreOS (yeah, Container Linux), using Ansible. If you want to try it: git clone https://github.com/sebiwi/docker-coreos.git cd docker-coreos make up You will need Ansible 2.2+, Docker, Vagrant and Molecule Why? Well, I did the same thing with Kubernetes a while ago, because I wanted to test all the different new Kubernetes features and have a local cluster to play with. I wanted to do and have the same thing with Docker in Swarm mode. I’m also planning on comparing both of them eventually. So I needed the whole prime matter first: installation procedures, general architecture, networking model, concepts and abstractions and so on. Finally, I thought it would be nice to explain how every Swarm component fit together, so everyone can understand what’s under the hood. I keep getting questions like “what is a Kubernetes and where can I buy one?” at work, and if it is “better than a Docker”. You won’t find the answer to the last question in this article, but at least you will (hopefully) understand how Swarm works. You can make up your own mind afterwards. Especially after reading both articles. Okay, you got me. What is a Swarm? Docker Swarm is Docker’s container orchestration and clustering tool. It allows you to deploy and orchestrate containers on a large number of hosts, while enabling you to do some other cool things in the way. There is usually mild confusion when talking about Swarm, which is relatively normal since the name has been used to refer to different things over the years. First, there was Docker Swarm, currently known as Docker Swarm Standalone. It basically allowed you to turn a pool of Docker hosts into a single, large, virtual Docker host. In this scenario, a discovery service or a key-value data store like Consul, etcd or Zookeeper was needed in order to obtain high availability on the manager nodes (I will discuss this point further later on in the series). Nowadays, and since Docker v1.12.0-rc1, there is something called Swarm Mode, which is included by default in the Docker Engine. Swarm Mode allows you to manage natively a cluster of Docker Engines. It is highly integrated with another toolkit developed by Docker, called Swarmkit, which removes the need of using a key-value data store for service discovery like you needed to do when using Swarm Mode Standalone: it is already included in Swarm Mode. Swarm me up So there’s two of them. Theoretically, Docker has no plans of deprecating Docker Swarm Standalone. From the Docker Swarm’s GitHub page: “Docker does not currently have a plan to deprecate Docker Swarm. The Docker API is backward compatible so Docker Swarm will continue to work with future Docker Engine versions.” Nevertheless, from the Docker Swarm’s overview page: “You are viewing docs for legacy standalone Swarm. These topics describe standalone Docker Swarm. In Docker 1.12 and higher, Swarm mode is integrated with Docker Engine. Most users should use integrated Swarm mode ... Standalone Docker Swarm is not integrated into the Docker Engine API and CLI commands.” Which means that even if they’re still maintaining Swarm’s Standalone, Swarm Mode is where their money is. Therefore, it’s what we’re going to be using for this project. Let us discuss architecture first. Docker architecture Before talking about Swarm, I’d like to talk about Docker itself. I’ve mentioned the Docker Engine quite a few times without actually describing what it really is. It is basically a client-server application with three major components: a command-line interface (CLI), a REST API and a server. - The server is a daemon process called dockerd. It listens for Docker API requests and manages all Docker resources, such as images, networks, containers and volumes. It can also communicate with other daemons to manage Docker services (more on this later) - The REST API is served by the Docker Engine, and it allows clients to talk to the daemon and control every aspect of it. It can be accessed with any HTTP client, but if you want to stay “official” there are many standard SDKs on many languages, and there is also the standard CLI - The command-line interface is the primary and most frequently used way of communicating with the server Not your regular engine Basically, you use the CLI to talk and interact with the Docker daemon, through the REST API. The daemon then creates all the necessary resources such as containers, networks and volumes. The client and the server may coexist on the same machine, or they may also be on different hosts. Docker is composed of many different things at an engine-level too. It is Docker’s plan to separate and release all of its infrastructure plumbing software, and they’re doing a great job so far. As of Docker 1.12, the Engine is decomposed and built upon two different tools: runC and containerd. First, runC is a CLI tool for running containers. The Docker Engine used to do that before. First by using LXC, and then with libcontainer. Nowadays, libcontainer is still used, but only by runC. Another cool thing about this is that runC is able to run Open Container Initiative (OCI) containers. OCI is a standardisation initiative which specify a common interface for containers images and container engines, effectively enabling any container build with a any OCI-compatible tool to run on any OCI-compatible engine. In other words, these are containers that abide by a de jure container standard. What is de jure, you say? Check it: De facto is a Latin phrase that means in fact (literally by or from fact) in the sense of "in practice but not necessarily ordained by law" or "in practice or actuality, but not officially established", as opposed to de jure. So basically, “De facto” is used, whereas “De jure” comes from a widely accepted standard or law. Cool, huh? This is great, since it will theoretically allow containers created with one engine to be run on a different engine. Therefore its name, Open Container Initiative.At the time of writing this article, the main OCI-compatible tools are Docker, and Rocket (Rkt). containerd is a daemon that uses runC to manage containers. It exposes a CRUD container interface using gRPC, with a very simple API. This way, all the container lifecycle actions (like starting, stopping, pausing or destroying containers) are delegated by the Docker Engine to containerd which uses runC to execute all its container-related actions. The Engine still manages images, volumes, networks and builds, but containers are now containerd’s territory. Like a layer cake There’s also another component called containerd-shim which sits between containerd and runC, acts as the container’s process parent and allow the runtime (runC) to exit after starting the containers. This whole thing is pretty funny, because the Docker Engine is not able to run containers by itself anymore: it delegates all these tasks to runC and containerd (and containerd-shim, somehow). That’s about it for the Docker architecture. Let’s talk about Swarm now. Swarm architecture and concepts A Swarm is created by one or many Docker Engines, which uses swarmkit for all the cluster-management and orchestration features. You can enable Swarm mode by either creating a new Swarm or joining an existing Swarm. When using Swarm, you don’t launch single containers, but rather services. But before talking about that, I need to talk about nodes. A node is just a Docker Engine that is a member of the Swarm. There are two types of nodes: Managers and Worker nodes. A Manager node receives a service definition and then it dispatches tasks to Worker nodes accordingly. They also do the orchestration and cluster management functions required to maintain the desired state of the swarm. There may be many Manager nodes on a Swarm, but there is only one leader, which is elected by all the other Manager nodes using the Raft algorithm and which performs all the orchestration tasks. THIS WILL HAVE AN EMBEDDED PLAYER ON THE FINAL ARTICLE https://asciinema.org/a/GpkVwipWeyutZySkYL7NpXPDs Worker nodes receive and execute tasks from Manager nodes. By default, Manager nodes are also Worker nodes, but they can be configured to not accept any workload (just like real-life managers) therefore becoming acting as Manager-only nodes. There is also an agent on every Worker node, which reports on the state of its tasks to the Manager (so basically, middle-management). That way, the Manager can maintain the desired state of the cluster. A service is the definition of one (or many) tasks to be executed on Worker nodes. When creating a service, you need to specify which container image to use, and which commands to execute inside the containers. A service may be global, or replicated. When the service is global, it will run on every available node once. When it’s replicated, the Manager distributes the given number of tasks on the nodes based on the desired scale number. This number may also be one. A task is just a container and the commands to be run inside of the container. It is the standard scheduling unit of Swarm. Once a task is assigned to a node, it can’t be moved to another node. It either runs on the selected node, or fails. So that’s about it for this first chapter. On the next episode, I’ll talk to you about Docker (and Swarm’s) networking model. Stay tuned!), because I wanted to test all the different new Kubernetes features and have a local cluster to play with. I wanted to do and have the same thing with Docker in Swarm mode. I’m also planning on comparing both of them eventually. So I needed the whole prime matter first: installation procedures, general architecture, networking model, concepts and abstractions and so on.
Finally, I thought it would be nice to explain how every Swarm component fit together, so everyone can understand what’s under the hood. I keep getting questions like “what is a Kubernetes and where can I buy one?” at work, and if it is “better than a Docker”. You won’t find the answer to the last question in this article, but at least you will (hopefully) understand how Swarm works. You can make up your own mind afterwards. Especially after reading both articles.
Okay, you got me. What is a Swarm?
Docker Swarm is Docker’s container orchestration and clustering tool. It allows you to deploy and orchestrate containers on a large number of hosts, while enabling you to do some other cool things in the way.
There is usually mild confusion when talking about Swarm, which is relatively normal since the name has been used to refer to different things over the years. First, there was Docker Swarm, currently known as Docker Swarm Standalone. It basically allowed you to turn a pool of Docker hosts into a single, large, virtual Docker host. In this scenario, a discovery service or a key-value data store like Consul, etcd or Zookeeper was needed in order to obtain high availability on the manager nodes (I will discuss this point further later on in the series).
Nowadays, and since Docker v1.12.0-rc1, there is something called Swarm Mode, which is included by default in the Docker Engine. Swarm Mode allows you to manage natively a cluster of Docker Engines. It is highly integrated with another toolkit developed by Docker, called Swarmkit, which removes the need of using a key-value data store for service discovery like you needed to do when using Swarm Mode Standalone: it is already included in Swarm Mode.

Swarm me up
So there’s two of them. Theoretically, Docker has no plans of deprecating Docker Swarm Standalone. From the Docker Swarm’s GitHub page:
“Docker does not currently have a plan to deprecate Docker Swarm. The Docker API is backward compatible so Docker Swarm will continue to work with future Docker Engine versions.”
Nevertheless, from the Docker Swarm’s overview page:
“You are viewing docs for legacy standalone Swarm. These topics describe standalone Docker Swarm. In Docker 1.12 and higher, Swarm mode is integrated with Docker Engine. Most users should use integrated Swarm mode ... Standalone Docker Swarm is not integrated into the Docker Engine API and CLI commands.”
Which means that even if they’re still maintaining Swarm’s Standalone, Swarm Mode is where their money is. Therefore, it’s what we’re going to be using for this project.
Let us discuss architecture first.
Docker architecture
Before talking about Swarm, I’d like to talk about Docker itself. I’ve mentioned the Docker Engine quite a few times without actually describing what it really is. It is basically a client-server application with three major components: a command-line interface (CLI), a REST API and a server.
- The server is a daemon process called dockerd. It listens for Docker API requests and manages all Docker resources, such as images, networks, containers and volumes. It can also communicate with other daemons to manage Docker services (more on this later)
- The REST API is served by the Docker Engine, and it allows clients to talk to the daemon and control every aspect of it. It can be accessed with any HTTP client, but if you want to stay “official” there are many standard SDKs on many languages, and there is also the standard CLI
- The command-line interface is the primary and most frequently used way of communicating with the server
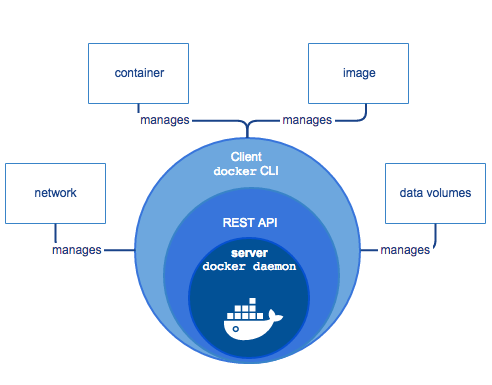
Basically, you use the CLI to talk and interact with the Docker daemon, through the REST API. The daemon then creates all the necessary resources such as containers, networks and volumes. The client and the server may coexist on the same machine, or they may also be on different hosts.
Docker is composed of many different things at an engine-level too. It is Docker’s plan to separate and release all of its infrastructure plumbing software, and they’re doing a great job so far. As of Docker 1.12, the Engine is decomposed and built upon two different tools: runC and containerd.
First, runC is a CLI tool for running containers. The Docker Engine used to do that before. First by using LXC, and then with libcontainer. Nowadays, libcontainer is still used, but only by runC. Another cool thing about this is that runC is able to run Open Container Initiative (OCI) containers. OCI is a standardisation initiative which specify a common interface for containers images and container engines, effectively enabling any container build with a any OCI-compatible tool to run on any OCI-compatible engine. In other words, these are containers that abide by a de jure container standard.
What is de jure, you say? Check it:
De facto is a Latin phrase that means in fact (literally by or from fact) in the sense of "in practice but not necessarily ordained by law" or "in practice or actuality, but not officially established", as opposed to de jure.
So basically, “De facto” is used, whereas “De jure” comes from a widely accepted standard or law. Cool, huh? This is great, since it will theoretically allow containers created with one engine to be run on a different engine. Therefore its name, Open Container Initiative.At the time of writing this article, the main OCI-compatible tools are Docker, and Rocket (Rkt).
containerd is a daemon that uses runC to manage containers. It exposes a CRUD container interface using gRPC, with a very simple API. This way, all the container lifecycle actions (like starting, stopping, pausing or destroying containers) are delegated by the Docker Engine to containerd which uses runC to execute all its container-related actions. The Engine still manages images, volumes, networks and builds, but containers are now containerd’s territory.
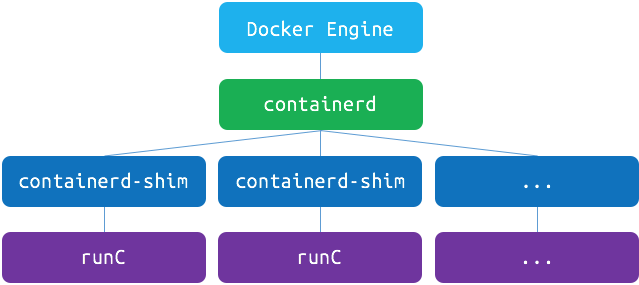
There’s also another component called containerd-shim which sits between containerd and runC, acts as the container’s process parent and allow the runtime (runC) to exit after starting the containers. This whole thing is pretty funny, because the Docker Engine is not able to run containers by itself anymore: it delegates all these tasks to runC and containerd (and containerd-shim, somehow).
That’s about it for the Docker architecture. Let’s talk about Swarm now.
Swarm architecture and concepts
A Swarm is created by one or many Docker Engines, which uses swarmkit for all the cluster-management and orchestration features. You can enable Swarm mode by either creating a new Swarm or joining an existing Swarm.
When using Swarm, you don’t launch single containers, but rather services. But before talking about that, I need to talk about nodes.
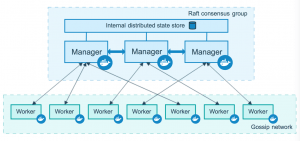
A node is just a Docker Engine that is a member of the Swarm. There are two types of nodes: Managers and Worker nodes. A Manager node receives a service definition and then it dispatches tasks to Worker nodes accordingly. They also do the orchestration and cluster management functions required to maintain the desired state of the swarm. There may be many Manager nodes on a Swarm, but there is only one leader, which is elected by all the other Manager nodes using the Raft algorithm and which performs all the orchestration tasks.
Worker nodes receive and execute tasks from Manager nodes. By default, Manager nodes are also Worker nodes, but they can be configured to not accept any workload (just like real-life managers) therefore becoming acting as Manager-only nodes. There is also an agent on every Worker node, which reports on the state of its tasks to the Manager (so basically, middle-management). That way, the Manager can maintain the desired state of the cluster.
A service is the definition of one (or many) tasks to be executed on Worker nodes. When creating a service, you need to specify which container image to use, and which commands to execute inside the containers. A service may be global, or replicated. When the service is global, it will run on every available node once. When it’s replicated, the Manager distributes the given number of tasks on the nodes based on the desired scale number. This number may also be one.
A task is just a container and the commands to be run inside of the container. It is the standard scheduling unit of Swarm. Once a task is assigned to a node, it can’t be moved to another node. It either runs on the selected node, or fails.
So that’s about it for this first chapter. On the next episode, I’ll talk to you about Docker (and Swarm’s) networking model.
Stay tuned!