How Can Domain-Driven Design and Hexagonal Architecture Improve Data Product Development in Practice?
What we want: to build a data product
When trying to build business intelligence dashboards, AI models or any other products based on data, you need to have access and know what you consume. If there are any inconsistencies in your results, you need to understand where they are from. The sources of these data products are other data products (or data as a product) that are part of what we could call the data supply chain [1].
Just as manufacturers sell physical goods in raw (wheat), curated (well-packed flour) or transformed forms (bread), data teams could sell their data products in an organization's market place in different levels of transformations. For downstream consumers, it is important to understand the characteristics of their inputs because when they build something out of what you propose, everything needs to fit well together. Would you buy from a provider that can't describe some basic characteristics of their product, how they are made, where the materials come from and give you some important guarantees? Probably not, and it may even be impossible on some regulated products (Personally Identified Information constraints as an obvious example).
In data, you would usually create a document called a data contract that will contain all key information that the user will need. Going a bit further, we can use this to also document the data transformations that were made. By documenting transformation rules, data product consumers can then understand better what they consume without having the feeling to consume a black box. This may increase adoption and confidence. Therefore, the data contract not only holds the characteristics but also the recipe. We will see below how to use it during the build and how it could help you. I don’t find data contracts very practical if they’re created after the build, since doing them retrospectively is tedious and there’s a risk they won’t be up to date. You can use them as recipes to guide you building the data product [2].
Now, I will suppose that we have the problem of developing software in order to create a data product. The software can be made of Python, a series of DBT models or any other languages. When it comes to software development, we usually like to separate what is technical to what is business oriented, the domain. When thinking about data products and not data artifacts, the goal is not anymore to fill a technical data lake with “technical” data. I have the conviction that a lot of terms that were reserved to technical become part of the domain, to cite a few: tables, data schemas, primary keys. We could say that they are part of the data governance domain. They are keys inside the domain vocabulary because we are precisely building a data product.
Identify your problem and clarify your domain objects
State-of-the art software is generally made of Domain-Driven Design or at least gets some inspiration from it.
Domain-Driven Design (DDD) is an approach to building systems that model the real-world business domain as closely as possible. A central principle is the ubiquitous language which is a shared vocabulary used by both technical and business teams to describe data and processes consistently. This language guides naming conventions and documentation, ensuring that technical artifacts stay aligned with business meaning.
DDD introduces the idea of bounded contexts, which define clear boundaries for each domain or subsystem. In data terms, a bounded context might correspond to a specific data product or data domain (in the sense of Data Mesh). Within each context, we model entities (objects with identity, such as a customer or order), value objects (immutable attributes without identity, such as an address or currency), aggregates (groups of entities and value objects that act as a single consistency unit), and services (domain-specific operations that don’t naturally belong to an entity). I found that this article summarizes some “rules” when trying to implement DDD in code and, if you are a developer, it can help you grasp the concepts clearly [3]. It was designed as a prompt context for AI coding agents but also serves a good reference for actual human developers.
These concepts help structure data systems around business meanings rather than technical constraints.
Domain-Driven Design can become a powerful tool when it is aligned with your code architecture. To some extent your code infrastructure should (or debatably will, either you want it or not) be representative of your ways of working as it may range from purely intuitive to strictly organized. I think that one of the biggest challenges in a team is the organization: when you are educated enough about different code architecture or design patterns, the implementation becomes technical details. The harder part is to define exactly what you have to build and how you will build them as a team. Are you going to document transformation rules as domain objects? Do you have a good understanding of source and target systems as well as data models for input and output? Are the business assertions for the output table well defined? How do you want the data quality to be monitored? Who will look at it? At which stage are you going to generate it? And so on.
Domain-Driven Design on its core can help with that. For instance, you can bring a few key people with different expertise (representative from Chief Information Officer, business, architect, data governance, analysts...) and animate an event-storming. An event-storming is a collaborative workshop used to explore and model complex business domains by mapping out domain events (significant occurrences within the system) to visualize workflows, uncover domain knowledge, and identify bounded contexts. Do it first with data governance to define data products vocabulary and workflows properly. After these kinds of sessions, you will probably get a first version of your full data flow from system ingestion to some key dashboards and understand some critical elements. Then you can reiterate later to zoom on specific areas as you build. If this kind of workshop is too difficult to organize you can still start implementing ubiquitous language and understand the business needs by interviewing key persons. A very important part is to align with the data governance as they will give you most of the data domain vocabulary. Business representatives, even if they are targeted to be the future data owners, generally need to be coached or educated with data product terms and you can make the link between their vocabulary and data product terms (a business rule can become a data quality rule or a data transformation rule for instance).
Data governance domain
The goal of mapping the data governance domain is to define as much as possible what data products are and what you expect from them in the context of your organization. The vocabulary and framework that we define in this step can be shared among the different data teams to standardize concepts and build a common methodology.
Here is a simplified data product and governance process that I have imagined:
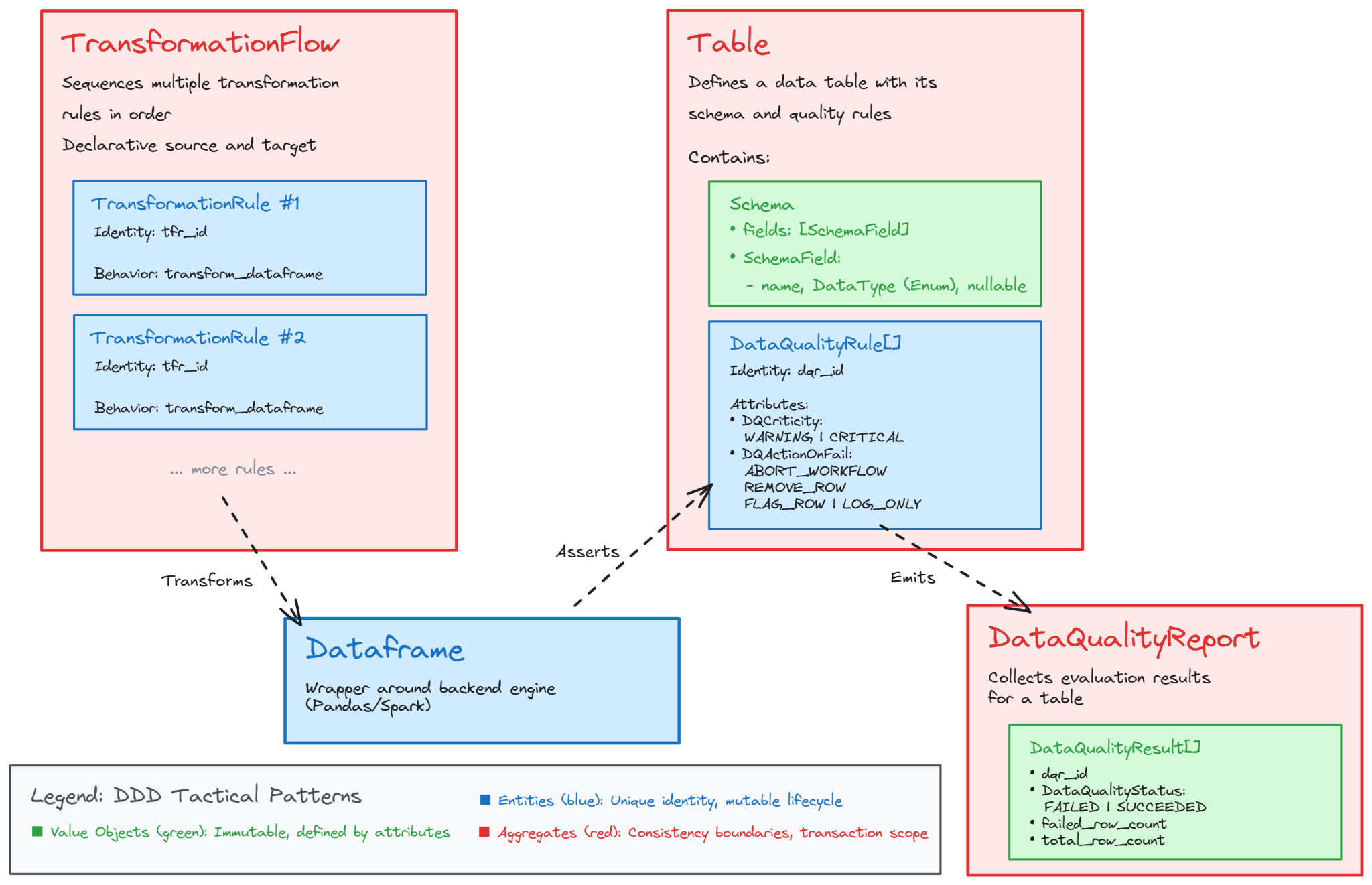
The central element is the Table which describes the data schema and a set of data quality rules that the data must follow. During the processing, the data is stored in an object called the Dataframe. A dataframe is an abstraction around data that represents it as a tabular data structure with columns and rows (like a CSV or Excel tab). Inside the Dataframe, the processing and storage optimization is easy and managed by an engine such as Pandas or Spark.
The Dataframe gets its data from a Data Source (called repository in a DDD context) and will be written in a Table. In the meantime it goes through a Transformation Flow which is a list of ordered Transformation Rules. A Transformation Flow is defined to describe how the Dataframe must be transformed from a given Data Source to a Data Target (Table). Before effectively writing to the Table, we check the Dataframe compatibility with it and generate a Data Quality Report that can be published in a separate table.
In this process example, the data quality is evaluated as the data is written because I wanted to showcase how data quality terminology can live inside the code. This can allow for rejection rules and to ensure that no invalid data actually enter the table. Other data quality rules can be assessed after the write with tools such as Great Expectations or the datacontracts cli [4].
We can summarize this domain knowledge inside the code in a file called domain_vocabulary.yaml that contains the ubiquitous language. Putting documentation near the code can help as a linguistic bridge between developer and business. Indeed, the code should use those terminologies as much as possible to avoid understanding gaps. It can be combined with tools inside your IDE that will give you hints on the domain object definitions (you can look at Contextive [5]). I didn’t follow any standard format for this example.
domains:
- name: "data_governance"
description: "Universal domain covering data quality, schema management, and architectural patterns. These concepts apply across all business domains."
ddd_patterns:
value_objects:
- name: DataQualityStatus
description: "Status of a data quality evaluation (FAILED, SUCCEEDED)."
purpose: "Represents the outcome of DQ rule execution."
values: "FAILED or SUCCEEDED"
- name: DQCriticity
description: "Severity level of a data quality rule (WARNING, CRITICAL)."
purpose: "Determines the impact level when DQ rules fail."
values: ["WARNING", "CRITICAL"]
- name: DQActionOnFail
description: "Action to take when a data quality rule fails."
purpose: "Defines system behavior on DQ rule failure."
values: ["ABORT_WORKFLOW", "REMOVE_ROW", "FLAG_ROW", "LOG_ONLY"]
- name: DataQualityResult
description: "Result of a single data quality rule evaluation."
purpose: "Encapsulates the outcome of evaluating one DQ rule against a dataset."
attributes:
- dqr_id: "ID of the evaluated rule"
- status: "DataQualityStatus"
- failed_row_count: "Number of rows that failed the rule"
- total_row_count: "Total number of rows evaluated"
- error_message: "Optional description of the failure"
...
A retail data product domain
For the rest of the article, I will take a very simple example of building a products / consumers / marketing campaign data product. The business goal is to analyze the marketing campaigns from different sources and to have a unified view to understand what works and what does not by computing a Return Of Investment for each marketing campaign. Here we will focus on the data product providing the data analysis team. Maybe the final product will be a BI dashboard but the data could also be used for other data products at any stage. Maybe another use case will simply use the unified ad cleaned view of orders or payments for instance. The data product that we build can bring value at different maturity levels (do you remember the wheat / flour / bread example above?).
The data will be available in a data platform which is the infrastructure and environment that makes it possible to operate data products in a consistent, scalable, and secure way.
To build the data product, we need to understand what assertions need to be true with the data product and what transformations are required. Also, you need to understand the availability constraints. Let's say that after a first event storming session or series of interviews, we get the following result:
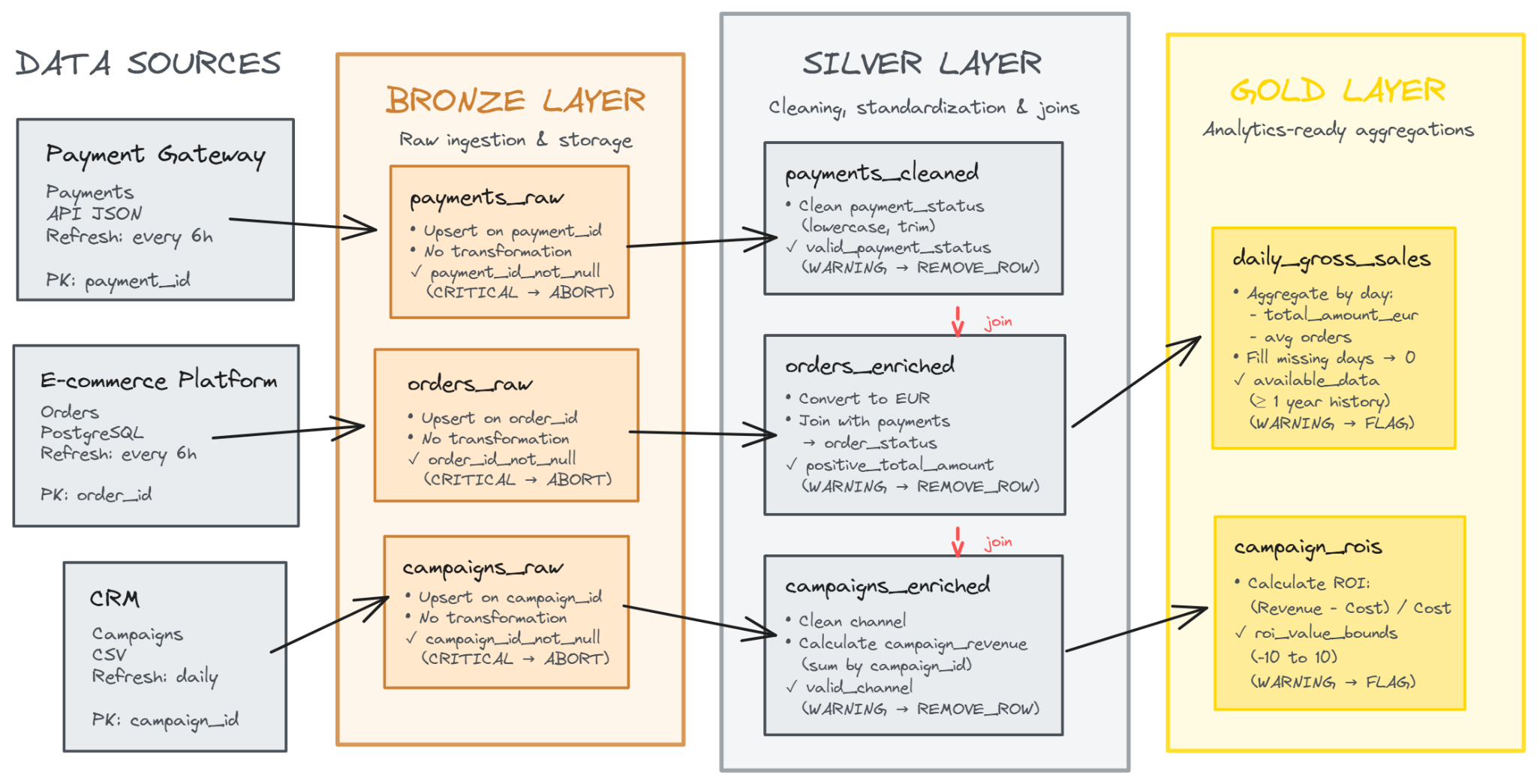
We identified three sources that are exposed in a variety set of format:
- an API to get the payment data as JSON,
- the E-commerce platform that expose a PostgreSQL that we can query,
- CRM that will be ingested as a CSV file because a connection could not be made between the data platform and the on-premise system. A temporary script is exporting the data and uploading it to a secured cloud storage that the data platform can access. In the meantime the integration team is working on their Integration Platform as a Service (iPaaS) tool to set up a proper landing area.
After the data ingestion we want the format to be consistent and will be in Delta table format for this example. The data processing will be done in Spark because there is a huge volumetry of daily orders.
We have decided to use a Medallion Architecture. The Medallion Architecture is a multi-layered data design pattern that organizes data into three quality tiers which are Bronze, Silver, and Gold, to progressively improve data quality, structure, and business value as it flows through the data platform.
On the right of the diagram, you can see the campaign ROI table. To compute it we need to do the merge of different tables because we need to join the campaign data to actual sales. For some reason the orders don’t contain the order status so obtain it from the payment status (failed or success) because we want to only consider orders that were successful.
In the meantime we do some cleaning and check data quality assertion on different levels. For instance we filter our invalid data that have invalid payment status and log the unexpected value as a data quality rule. We decide to completely abort the workflow if some data has missing primary key because we don’t want to process corrupted data.
As we did for the data governance framework we can define the domain vocabulary in a file inside the code repository:
domains:
- name: "retail_data_domain"
description: "Business domain for e-commerce retail operations, organized using medallion architecture."
medallion_architecture:
bronze_layer:
description: "Raw data ingestion with minimal transformation, critical validation only."
validation_strategy: "CRITICAL rules with ABORT_WORKFLOW - stop processing on validation failure."
data_quality_rules:
- name: OrderIdNotNullRule
description: "Validates that order_id is never null in raw order data."
criticity: "CRITICAL"
action_on_fail: "ABORT_WORKFLOW"
business_rationale: "Order ID is the primary key for all downstream processing."
- name: ValidCustomerIdRule
description: "Validates that customer_id follows expected format."
criticity: "CRITICAL"
action_on_fail: "ABORT_WORKFLOW"
business_rationale: "Invalid customer IDs break customer analytics."
- name: NonNegativeAmountRule
description: "Ensures total_amount is not negative."
criticity: "CRITICAL"
action_on_fail: "ABORT_WORKFLOW"
business_rationale: "Negative amounts indicate data corruption."
transformation_rules:
- name: RawDataIngestionRule
description: "Minimal transformation for raw data ingestion."
transformation_type: "ingestion"
purpose: "Preserve raw data structure with basic type conversion."
tables:
- name: OrdersRaw
description: "Raw orders from system, unprocessed."
schema_enforcement: true
primary_key: "order_id"
refresh_frequency: "Every 4 hours"
...
Now we will explicit all data quality rules and transformation steps for all levels in a data contract file. It will hold all of our business understanding and can be used both for build and for downstream consumers. The data contract can be then processed in your deployment pipeline to export relevant information into your organization documentation tools (data market place or data governance). In this way of working the data contract is set up to date as each new rule is built to ensure that it holds the most up to date information. Here is an extract of a first data contract we could get (non-standard format):
data_product:
name: "sales_analytics"
domain: "retail"
owner: "data.team@shoply.com"
version: "1.0.0"
description: "Data product describing consolidated e-commerce sales (orders, payments, campaigns)."
sources:
- name: "orders"
system: "E-commerce platform"
format: "PostgreSQL"
refresh_rate: "every 6 hours"
contract:
schema:
order_id: string
order_date: date
...
primary_key:
- order_id
foreign_keys:
- customer_id
- campaign_id
- name: "payments"
...
- name: "campaigns"
...
transformations:
bronze:
description: "Raw ingestion and storage of source data in the data lake."
tables:
- name: "orders_raw"
rules:
- "Upsert on order_id since last execution."
- "No modification: types specified in the contract are preserved."
quality_rules:
- name: "order_id_not_null"
description: "Each order must have a unique non-null identifier."
level: "critical"
action_on_fail: "abort_workflow"
depends_on:
- "sources.orders"
...
silver: ...
gold: ...
output:
tables:
- name: "sales_gold_daily"
description: "Daily aggregated view of consolidated sales."
refresh_rate: "daily"
columns:
- date: date
- total_sales: double
- avg_order_value: double
- name: "campaign_rois"
description: "Analytical table by marketing campaign, calculating profitability (ROI)."
refresh_rate: "daily"
columns:
- campaign_id: string
- channel: string
- revenue: double
- campaign_cost: double
- roi: double
So we have now a detailed file documenting everything needed to build the data product.
From drawings and documentation to code
The concepts I will introduce can be generalized. The how is not that important but the why and the what are keys. If you are wondering where to start, I think you should start organizing your ways of working and try to understand as much as possible what you need to do and why. This will more or less naturally have a positive impact on your code architecture (and by the way a good code architecture won't save a disorganized team and project).
The concept remains true if you are building a DBT pipeline, DuckDB pipeline, Spark pipelines with Snowflake, Factory or Databricks. I will study the more flexible one: Python. Each language or framework imposes a view of how to think, some sort of paradigm (DBT will make you think about data models). Designing Python tasks will allow you all the flexibility you want and to make all the decisions. The data engineer has more responsibility and needs to build his own vision and constraints. This is the riskier one and maybe the most interesting to study here.
Domain and purely business-oriented concerns
I will try to be somewhat radical in my implementation and follow DDD and hexagonal concepts as much as I can and with the limitation of my own knowledge on the different concepts. I have prepared a code repository that accompanies this article so you can project yourself better with a full implementation of the ideas described here. All design choices must be the result of team discussion and compromises. Your team organization will most likely be unique. You may define the transformation rules as pure domain objects or not, your POs and business people may or may not want to validate code or the documentation that accompanies it.
Defining the data governance objects aka the general framework
Here I am defining a data governance domain which will be used as a general framework for the data products. For instance, here are a few class definitions that I have used:
@dataclass
class Table:
table_name: str # Unique identifier for this table
data_quality_rules_to_check: list[DataQualityRule]
schema: Schema # Mandatory schema to define and enforce structure
primary_key_column: Optional[str] = None
enforce_schema_on_evaluation: bool = False # Whether to automatically enforce schema during evaluation
def evaluate_dataframe_compatibility(self, dataframe: Dataframe) -> DataQualityReport:
"""
Evaluate if the dataframe meets all data quality rules for this table.
"""
# If enforcement is enabled, enforce schema on the dataframe
if self.enforce_schema_on_evaluation:
dataframe.enforce_schema(self.schema)
# Evaluate all data quality rules
dq_report = DataQualityReport(table_name=self.table_name)
for dqr in self.data_quality_rules_to_check:
dq_report.add_a_data_quality_result(dqr.evaluate_dataframe(dataframe))
return dq_report
@dataclass
class DataQualityRule(Protocol):
"""
Entity representing a data quality rule with unique identity.
"""
dqr_id: str # Unique identifier for this rule
criticity: DQCriticity
action_on_fail: DQActionOnFail
@abstractmethod
def evaluate_dataframe(self, dataframe: Dataframe) -> DataQualityResult:
"""
Evaluate the dataframe and return the associated data quality result.
"""
@dataclass
class TransformationRule(Protocol):
"""
Entity protocol representing a transformation rule.
"""
tfr_id: str # Unique identifier for this transformation rule
@abstractmethod
def apply(self, dataframe: Dataframe):
"""
Apply the transformation rule to the dataframe (in-place modification).
Args:
dataframe: The dataframe to transform
"""
@dataclass
class TransformationFlow:
"""
Aggregate root representing a sequence of transformation rules.
"""
transformation_flow_name: str # Unique identifier for this flow
ordered_transformation_rule: list[TransformationRule]
def apply(self, dataframe: Dataframe):
"""
Apply all transformation rules in sequence to the dataframe.
This is the main operation of the aggregate - it coordinates the
execution of all transformation rules in order.
Args:
dataframe: The dataframe to transform (modified in place)
"""
for tr in self.ordered_transformation_rule:
tr.apply(dataframe)
Defining the data product domain using the general framework
Then I can use this framework to create my data product. I need to create classes that inherit from the framework classes. With inheritance, child classes will inherit from behaviors of their parent classes. This means that we don’t need to rewrite the evaluate_dataframe_compatibility for our child Table. Another property is that a child class can act as a parent class from the class user perspective. For instance, the inheritance enforces that any Data Quality Rule has an evaluate_dataframe that can be called by the Table class without having the knowledge on which Data Quality Rule it is really using. This concept is called polymorphism and remains true for protocols or interfaces.
We isolate in this type of class definitions all the business logic that can therefore be understood and also be very precisely tested.
Let’s consider for instance the CampaignsEnriched table and all domain objects that we need to define.
First the table with its associate data quality rule:
class CampaignsEnriched(Table):
"""
Enriched campaigns with:
- Standardized channel names (lowercase, no spaces)
- Calculated revenue per campaign from orders
- Valid channels: email, sms
"""
def __init__(self):
super().__init__(
table_name="campaigns_enriched",
data_quality_rules_to_check=[
ValidChannelRule()
],
schema=Schema(
fields=(
SchemaField(name="campaign_id", data_type=DataType.STRING,
description="Unique campaign identifier"),
SchemaField(name="channel", data_type=DataType.STRING,
description="Cleaned marketing channel: email or sms"),
SchemaField(name="cost", data_type=DataType.DOUBLE,
description="Total campaign cost"),
SchemaField(name="start_date", data_type=DataType.DATE,
description="Campaign start date"),
SchemaField(name="end_date", data_type=DataType.DATE,
description="Campaign end date"),
SchemaField(name="campaign_revenue", data_type=DataType.DOUBLE,
description="Total revenue generated by this campaign (sum of order amounts)"),
),
primary_key=("campaign_id",)
),
)
class ValidChannelRule(DataQualityRule):
"""Validates that marketing channel belongs to the allowed set of values."""
def __init__(self):
super().__init__(
dqr_id="valid_channel",
criticity=DQCriticity.WARNING,
action_on_fail=DQActionOnFail.REMOVE_ROW
)
def evaluate_dataframe(self, dataframe: Dataframe) -> DataQualityResult:
valid_channels = {'email', 'sms'}
if "channel" not in dataframe.get_column_names():
return DataQualityResult(
dqr_name=self.dqr_id,
status=DataQualityStatus.FAILED,
action_fail=self.action_on_fail,
dq_criticiy=self.criticity,
message="channel column not found"
)
# Count rows with invalid channels BEFORE action
invalid_count = dataframe.count_rows_where('channel', 'not_in', valid_channels)
if invalid_count == 0:
return DataQualityResult(
dqr_name=self.dqr_id,
status=DataQualityStatus.SUCCESSED,
action_fail=self.action_on_fail,
dq_criticiy=self.criticity,
message="All channels are valid"
)
else:
# REMOVE_ROW action: Remove invalid rows from dataframe
if self.action_on_fail == DQActionOnFail.REMOVE_ROW:
dataframe.filter_rows_by_value_in_set('channel', valid_channels)
return DataQualityResult(
dqr_name=self.dqr_id,
status=DataQualityStatus.FAILED,
action_fail=self.action_on_fail,
dq_criticiy=self.criticity,
message=f"Found {invalid_count} invalid channels - rows removed"
)
We model our data quality rule to not only be an observation of the data but that can act on it, in this case, we remove invalid rows because it is a business requirement.
There are also domain objects to specify all the transformation rules that are defined by the business. We have the transformation rules that are unitary transformations that can be reused in multiple transformation flows.
For example, I will do something like:
class CleanChannelRule(TransformationRule):
"""Cleans marketing channel names by converting to lowercase and trimming spaces."""
def __init__(self):
self.tfr_id = "clean_channel"
def apply(self, dataframe: Dataframe):
"""Clean channel: lowercase and trim spaces"""
…
class CalculateCampaignRevenueRule(TransformationRule):
"""Calculates total revenue per campaign by summing order amounts."""
def __init__(self, orders_df: Dataframe):
self.tfr_id = "calculate_campaign_revenue"
self.orders_df = orders_df
def apply(self, dataframe: Dataframe):
"""Do the join and calculate campaign revenue by summing total_amount_eur per campaign_id"""
…
class EnrichCampaignsTfFlow(TransformationFlow):
"""
Transformation flow for enriching campaigns with revenue calculation.
"""
def __init__(self, orders_df: Dataframe):
super().__init__(
transformation_flow_name="enrich_campaigns",
ordered_transformation_rule=[
CleanChannelRule(),
CalculateCampaignRevenueRule(orders_df)
]
)
A hexagonal architecture to orchestrate the domain objects
So far we only talked about domain concerns. We have written a lot of code and written a lot of documentation but you may not see the link with any data flows yet. Indeed, we have not defined where the program starts. We need now to tackle the environment and the application sections.
For this I like to use the hexagonal architecture design. You can find a lot of existing documentation on hexagonal architecture that will probably explain better than me. For instance this one: [6]. Let me try in a nutshell.
The core idea is that your business logic should not depend on infrastructure (database, framework, APIs, ...). That means that any changes to your infrastructure should not imply any changes on your business logic code. The two are strictly segmented. The business logic code will explain what it needs for the infrastructure (get this data for example) and define interfaces that we call ports. Then, it can use any class that implements the port, the (secondary) adapters. The business code does not need to know anything about what is happening inside it. The business code is only dependent on the ports and not of their implementations.
The business code is generally split into what are called use cases that will correspond to tasks in an ETL in our case. The use cases are the core orchestrators of your application and manage the defined domain objects.
A section called primary adapters or entrypoints is the one responsible to map the environment and application by implementing the correct adapters for each. The entrypoints are the entry door, where the control flux of your software starts.
Even if it does not represent a hexagon, here is a diagram that tries to summarize this in our case.
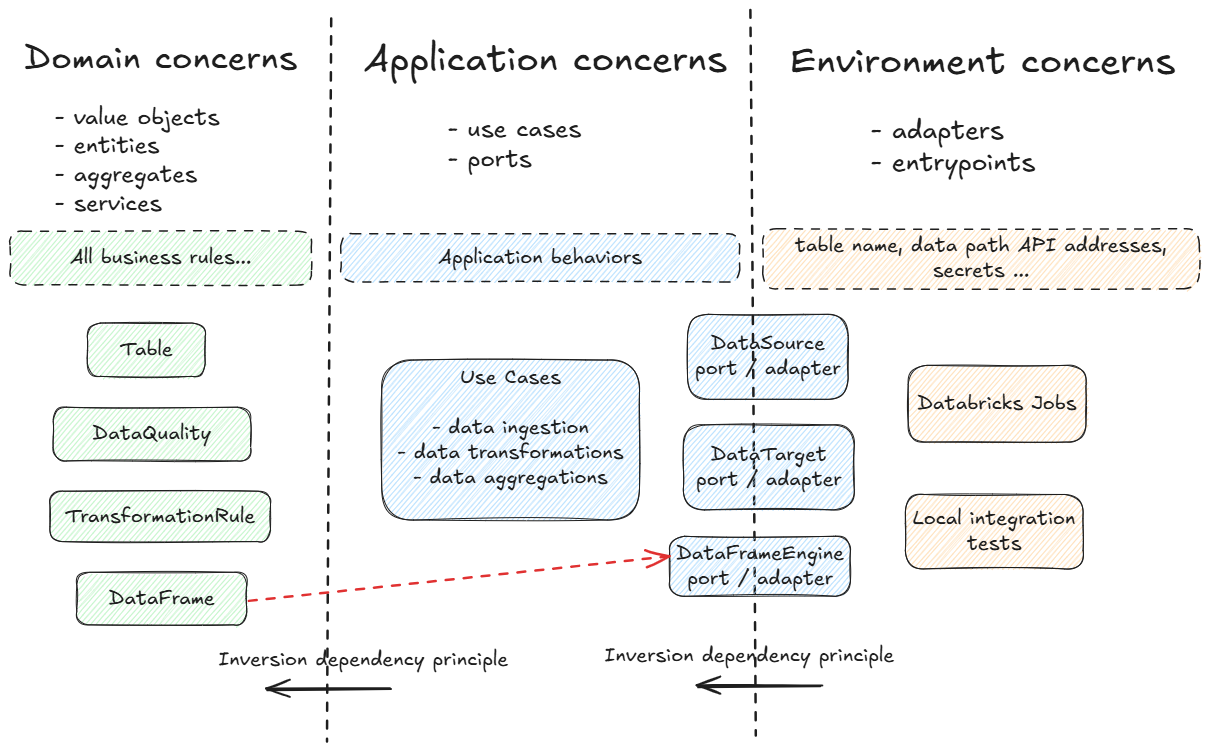
I use a special entity called a DataFrame, which somewhat is an intruder into the domain layer because it introduces application-level concerns. The main reason is that, depending on data volume, we often cannot (or should not) load all data into memory.
More concretely, every piece of code we write in a big data context is interpreted by a driver node, whose role is to plan and orchestrate distributed computations across a cluster. To achieve this, each data operation must leverage the big data engine. If it doesn’t, the driver executes the computation locally, bypassing the cluster entirely. This would make large-scale or distributed computation impossible, since all processing would happen in-memory on the driver rather than being parallelized across worker nodes.
From a design perspective, domain-layer checks should avoid depending on frameworks that implicitly force in-memory resolution. An alternative design could rely heavily on user-defined functions (UDFs) to delegate computations, leaving the application layer responsible for invoking them within the DataFrame engine. However, this was not the approach adopted here.
Therefore, in essence, the data don’t exist within the same context as the driver that runs the domain section. The data stays outside of the driver and in a way, outside of the domain context. The DataFrame acts as a bridge between the two: it manages data that live in the environment while preserving the domain vocabulary, and it allows the actual computation to be delegated to external workers rather than performed locally.
I have introduced a DataFrameEngine port which may complexify each data operation because they need to be declared in the port/adapter. This ensures the application/domain code section is independent of the framework. It allows me to write tests with a dataframe engine that is different from the production one. It also gives me flexibility to choose between two engines that can lead to significant speed increase depending on the size of the data. The engine can change but the code won’t and it allows to unify the code base to a single framework. Alternatively, you could directly use your engine with the "DataFrame" if you know that you will not change and it will simplify the code complexity.
Implementing our example with DDD and hexagonal architecture
Data source
The data source is responsible for creating a dataframe in a unified way. The actual source can be a SQL table, a CSV file or an external API. Putting an abstraction here allows us to avoid dependency between the source type (that is likely to change in our example) which is part of the environment and the transformation logic. This means that we can exactly test our transformation logic with an in memory data source.
For the port:
class DataSource(Protocol):
def fetch(
self,
dataframe_engine: Type["DataFrameEngine"],
) -> Dataframe: ...
For the adapter:
class InMemoryDataSource:
def __init__(self, data: list[dict]):
self._data_as_dataframe = PandasDataFrameEngine.create_from_list_of_dict(data)
def fetch(
self,
dataframe_engine: Type["DataFrameEngine"],
) -> Dataframe:
if dataframe_engine==PandasDataFrameEngine:
backend_df = self._data_as_dataframe
else:
backend_df = dataframe_engine.create_from_list_of_dict(self._data_as_dataframe.collect(), self._data_as_dataframe.get_schema())
return Dataframe(
backend_dataframe=backend_df
)
Data target
The logic is similar to Data Target. We can argue that the data target is not likely to change in our scenario as we expect it to always be Delta tables. This is true but the environment configuration will change whether we are in development, preproduction or production and we don’t want our software to change depending on the environment and this architecture can help enforce this configuration segregation implementation [7].
There are also cases where we need a human in the loop to validate data before publication. In that case we can define a Data Target that will export the data to an Excel and manage the technical details to generate the file, send it by email or drop it where expected. We would not want this specific logic to pollute the data transformation code and separate it allows also for specific unit and integration tests.
For the port:
class DataTarget(Protocol):
def upsert(self, dataframe: Dataframe, primary_key_column: str) -> None:
pass
For the adapter:
class InMemoryDataTarget:
def __init__(self, data: list[dict]):
self._data_as_dataframe = PandasDataFrameEngine.create_from_list_of_dict(data)
def upsert(self, dataframe: Dataframe, primary_key_column: str):
self._data_as_dataframe.concat(dataframe.get_backend_dataframe())
self._data_as_dataframe.deduplicate_on_column(primary_key_column)
Dataframe engine
I will give you only an extract of the port for this one, we need to define all operations that need to be done with the data. It can get big but will enforce the data developers to split data manipulation logic in small steps that can be unit tested easily.
class DataFrameEngine(Protocol):
@staticmethod
def create_from_list_of_dict(
data: list[dict],
schema: Optional[Schema], # Because Python types are ambiguous and need to be linked with real schemas
) -> DataFrameEngine:
...
def collect(self) -> list[dict]:
...
def get_column_names(self) -> list[str]:
...
def filter_rows_by_value_in_set(self, column: str, valid_values: set) -> None:
...
Use Case
Because I expect my use cases to be very similar (import data from a source, apply the transformation flow, get the data quality report, save to the data target), I used a template design pattern. This approach lets me define a common workflow in a base class and delegate the implementation of particular steps to subclasses, ensuring consistency and minimal code duplication while keeping flexibility.
class BaseETLUseCase(ABC):
"""
Base class for ETL use cases following the Template Method pattern.
"""
def __init__(
self,
data_target: DataTarget,
dataframe_engine: Type[DataFrameEngine],
):
self._data_target = data_target
self._dataframe_engine = dataframe_engine
@abstractmethod
def fetch_data(self) -> Dataframe:
"""
Fetch data from source(s).
"""
pass
@abstractmethod
def get_target_table(self) -> Table:
"""
Get the target table definition (domain aggregate).
"""
pass
def get_transformation_flow(self) -> Optional[TransformationFlow]:
"""
Get the transformation flow to apply (if any).
"""
return None
def execute(self):
"""
Execute the ETL workflow.
"""
# 1. Fetch data
# 2. Apply transformations (if any)
# 3. Validate data quality
# 4. Write to target
...
Then most of my use case implementations can use it and are quite light. Let’s build the last piece to create the enriched campaign table:
class EnrichCampaigns(BaseETLUseCase):
"""
Silver Layer: Enrich campaign data by calculating revenue per campaign.
"""
def __init__(
self,
campaigns_source: DataSource,
orders_source: DataSource,
campaigns_enriched_target: DataTarget,
dataframe_engine: Type[DataFrameEngine],
):
super().__init__(campaigns_enriched_target, dataframe_engine)
self._campaigns_source = campaigns_source
self._orders_source = orders_source
def fetch_data(self) -> Dataframe:
"""Fetch campaigns data (main dataframe)."""
return self._campaigns_source.fetch(self._dataframe_engine)
def get_transformation_flow(self) -> Optional[TransformationFlow]:
"""Get the transformation flow for enriching campaigns with revenue."""
orders_df = self._orders_source.fetch(self._dataframe_engine)
return EnrichCampaignsTfFlow(orders_df)
def get_target_table(self) -> Table:
"""Get the CampaignsEnriched table definition."""
return CampaignsEnriched()
Entrypoint
The last thing is to deal with the environment configuration and instantiation of adapter classes. The entry points are where the control flow starts and you can expect to see a main method there. Following the control flux of the program starting from the entrypoint can help you understand the role of each element.
For instance we have the following integration test for the EnrichCampaigns use case:
# Given
campaigns_data = [
{"campaign_id": "camp_1", "channel": " EMAIL ", "cost": 100, "start_date": "2023-01-01", "end_date": "2023-01-31"}
]
orders_data = [
{"order_id": "ord_1", "campaign_id": "camp_1", "total_amount_eur": 150},
{"order_id": "ord_2", "campaign_id": "camp_1", "total_amount_eur": 100}
]
# We instantiate the adapter using the environment (here our data test, for a production environment in Databricks, it would instantiate DeltaDataSource and DeltaDataTarget with proper table name and data path from a configuration)
campaigns_source = InMemoryDataSource(data=campaigns_data)
orders_source = InMemoryDataSource(data=orders_data)
target = InMemoryDataTarget(data=[])
# When
EnrichCampaigns(
campaigns_source=campaigns_source,
orders_source=orders_source,
campaigns_enriched_target=target,
dataframe_engine=PandasDataFrameEngine
).execute()
# Then
result = target._data_as_dataframe.collect()
assert len(result) == 1
assert result[0]["channel"] == "email" # Should be cleaned
assert result[0]["campaign_revenue"] == 250 # Sum of orders
Wraps-up
As I mentioned above, I have built an example repository that may be used as a template or for inspiration. It was the field of numerous experimentation and the result of months of research. I also experimented with Copilot and I was surprised by its capacity to implement transformation rules just by reading the documentation (data_contract.yaml and domain_vocabulary.yaml). A next approach would be to be even more spec-driven to skyrocket your productivity with agent assistants.
The example repos has the following code architecture:
.
├── README.md
├── databricks.yaml
├── docs/
├── domain_vocabulary.yaml
├── hexagonal_ddd_data_engineering_demo
│ ├── adapters
│ │ ├── delta_data_source.py
│ │ └── ...
│ ├── application
│ │ ├── ports
│ │ │ ├── data_source.py
│ │ │ └── ...
│ │ └── use_cases
│ │ ├── base_etl_use_case.py
│ │ ├── bronze
│ │ │ ├── ingest_campaigns.py
│ │ │ └── ...
│ │ ├── gold
│ │ │ └── ...
│ │ └── silver
│ │ └── ...
│ ├── domain
│ │ ├── data_governance
│ │ │ ├── aggregates
│ │ │ │ ├── data_quality_report.py
│ │ │ │ ├── table.py
│ │ │ │ └── transformation_flow.py
│ │ │ ├── entities
│ │ │ │ ├── data_quality_rule.py
│ │ │ │ ├── dataframe.py
│ │ │ │ └── transformation_rule.py
│ │ │ └── value_objects
│ │ │ ├── data_quality_result.py
│ │ │ ├── data_quality_status.py
│ │ │ ├── dq_action_on_fail.py
│ │ │ ├── dq_criticity.py
│ │ │ └── schema.py
│ │ └── retail_data_domain
│ │ ├── bronze
│ │ │ ├── aggregates
│ │ │ │ ├── tables.py
│ │ │ │ └── transformation_flows.py
│ │ │ └── entities
│ │ │ ├── dq_rules.py
│ │ │ └── transformation_rules.py
│ │ ├── gold
│ │ │ └── ... # same structure
│ │ └── silver
│ │ └── ... # same structure
│ └── entrypoints
│ └── databricks
│ └── ...
├── pyproject.toml
└── tests
└── ...
Additional note: we are defining here the class of each table and transformation rules directly. We could also use a Factory approach parsing directly the data contract to create the correct classes for each table for each data product. It makes sense because we have a duplication of information that we could avoid. Updating the data contract, i.e. the documentation, would lead to a direct change in the domain behavior. To do this you have to define a list of reusable data quality rules and data transformation rules and use them. I did something similar for one of my clients that wanted to empower business users and product owners. I did it on a specific configuration file, separated from the data contract and with an User Interface to create the configuration. A config parser then takes the role of the factory to instantiate each data sources, data targets and also domain objects such as transformation flows and data quality rules.
Appendix: let's compare two extremes
We could rewrite everything we did for the enrich campaign use case as a very simple Python script. It would look something like this:
from pyspark.sql import SparkSession
import pyspark.sql.functions as F
# Create Spark session with hardcoded config
spark = SparkSession.builder \
.appName("CampaignEnrichment") \
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") \
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog") \
.getOrCreate()
# Hardcoded paths
campaigns_path = "/data/bronze/campaigns_raw"
orders_path = "/data/silver/orders_enriched"
output_path = "/data/silver/campaigns_enriched"
# Read data directly
campaigns_df = spark.read.format("delta").load(campaigns_path)
orders_df = spark.read.format("delta").load(orders_path)
# Transform: Clean channel names
campaigns_df = campaigns_df.withColumn(
"channel",
F.lower(F.trim(F.col("channel")))
)
# Transform: Calculate revenue per campaign
campaign_revenue = orders_df \
.groupBy("campaign_id") \
.agg(F.sum("total_amount_eur").alias("campaign_revenue"))
# Join campaigns with revenue
campaigns_enriched = campaigns_df.join(
campaign_revenue,
on="campaign_id",
how="left"
).fillna({"campaign_revenue": 0.0})
# Data quality check: Validate channels
valid_channels = ["email", "sms"]
invalid_count = campaigns_enriched.filter(
~F.col("channel").isin(valid_channels)
).count()
if invalid_count > 0:
print(f"WARNING: Found {invalid_count} rows with invalid channels!")
# Remove invalid rows
campaigns_enriched = campaigns_enriched.filter(
F.col("channel").isin(valid_channels)
)
# Write results
campaigns_enriched.write \
.format("delta") \
.mode("overwrite") \
.save(output_path)
spark.stop()
Let's call it "step 0" as I can't think of more primitive software code for this example. It is very straight to the point and simple in appearance. I think that it is good for proof of concepts when you need to start building fast to show value before jumping to any complex code architecture.
Some pros:
- Simplicity: everything in one file, easy to understand top-to-bottom
- Fast to write: no boilerplate, no abstractions
- Easy to debug: can run line-by-line, see intermediate results in integrated environments such as Databricks notebooks.
- Low learning curve: junior developers can understand immediately
- No overhead: no abstraction layers to navigate
Some cons:
- Not testable: can't test without running full Spark job
- Not reusable: logic is tied to this specific script
- Hardcoded values: paths and config mixed with business logic
- Difficult to change: modifying storage format requires code changes
- No separation of concerns: data access, business logic, validation all mixed
- Maintenance nightmare: as complexity grows, becomes spaghetti code
- Code duplication is king: if we have multiple tasks, we can't systemize the logic to publish data quality for instance. A change in the way to publish things, access given things must be done multiple times with a lot to test again and again because each task will use its own (free) logic.
It may be a good starting point but it becomes complex when working in a team. Every data engineer will do his script and mutualization will be harder and harder as time goes by. When there is a need to rationalize, there is a need for abstraction and I would not wait too long before jumping to a systematic code architecture because the refactoring effort would increase exponentially [8].
I find it both interesting and challenging that in practice from step 0 to a full DDD+hexagonal architecture (or any other sophisticated solutions) there is a wide spectrum of perfectly valid code architectures depending on your context. To cite myself a few lines above, I believe that the code architecture should/will be representative of your ways of working. If you are in a team where everything is fuzzy or changing without clear domain definitions, I would definitely not jump into a DDD-style code architecture just yet. If everything is purely experimental and chaotic, step 0 style is good. First focus on your ways of working, to define clear data product definitions and governance before changing the code too much. The challenge is that we still have to deliver value and we can't wait for the final organization structure and governance for data products. At some point I would make assumptions and refactor later, it is an endless game of cat and mouse. But why not go with your assumed definitions and try to do some context mapping later?
Conclusion
I am personally very happy to read the table definition of the business object in different layer (maturity) levels. By reading the table I can understand easily with a language that is almost natural what assertions and structure the target table will have. The transformation flow allows me to understand the lineage of transformation from a source to a target. I like the declarative approach. I imagine that it would be great to see a PR that includes changes on the data contract and to see the class definition on the same level. Code review would be easy. Everything can be perfectly tested in isolation and I would feel confident to change any part of the code to adapt to new business requirements or updated infrastructure.
References
- [1] Velappan, V. (2023, 20 octobre). Artificial Intelligence Adoption and Investment Trends in APAC. S&P Global Market Intelligence. S&P Global
- [2] Sanderson, C., Freeman, M., & Schmidt, B. E. (2025). Data Contracts : Developing Production-Grade Pipelines at Scale. O’Reilly Media.
- [3] Bardiakhosravi (s. d.). agent-context-kit : Context framework for AI coding agents. GitHub. https://github.com/bardiakhosravi/agent-context-kit
- [4] Data Contract (s. d.). DataContract.com. https://datacontract.com/
- [5] Contextive (s. d.). Contextive Documentation. https://docs.contextive.tech/community/guides/setting-up-glossaries/ Contextive
- [6] Octo. (s. d.). Hexagonal Architecture: trois principes et un exemple d’implémentation. OCTO Technology Blog. https://blog.octo.com/hexagonal-architecture-three-principles-and-an-implementation-example
- [7] Adam Wiggins (s. d.). The Twelve-Factor App. 12factor.net. https://12factor.net/config
- [8] Hunt, A., & Thomas, D. (1999). The Pragmatic Programmer. Addison-Wesley.