Hexagonal Architecture: three principles and an implementation example
Documented in 2005 by Alistair Cockburn, Hexagonal Architecture is a software architecture that has many advantages and has seen renewed interest since 2015.
The original intent of Hexagonal Architecture is:
Allow an application to equally be driven by users, programs, automated test or batch scripts, and to be developed and tested in isolation from its eventual run-time devices and databases.
To explore the benefits of piloting an application by automated tests, or developing and testing in isolation from the database, we recommend that you read this series of blog post on the test pyramid we published recently: the test pyramid by practice.
The promise is quite attractive, and it has another beneficial effect: it allows to isolate the core business of an application and automatically test its behaviour independently of everything else. This could be the reason why this architecture has caught the eye of Domain-Driven Design (DDD) practitioners. But be careful, DDD and hexagonal architecture are two quite distinct notions which can reinforce each other but which are not necessarily used together. But this is a topic for another time!
Finally, this architecture is not very complicated to set up. It is based on a few simple rules and principles. Let’s explore these principles to see what they mean in practice.
Principles of Hexagonal Architecture
Detail: How is the code organized inside and outside?
Detail: At the Runtime
Detail: Dependencies inversion on the right
Detail: Why an Interface on the left?
Testing in Hexagonal Architecture
To go further ahead
References
Principles of Hexagonal Architecture
The hexagonal architecture is based on three principles and techniques:
- Explicitly separate User-Side, Business Logic, and Server-Side
- Dependencies are going from User-Side and Server-Side to the Business Logic
- We isolate the boundaries by using Ports and Adapters
Vocabulary note: Throughout the rest of the article, the words User-Side, Business Logic and Server-Side will be used. These words come from the original article, and they are defined in the section below.
Principle: Separate User-Side, Business Logic and Server-Side
The first principle is to explicitly separate the code into three large formalized areas.
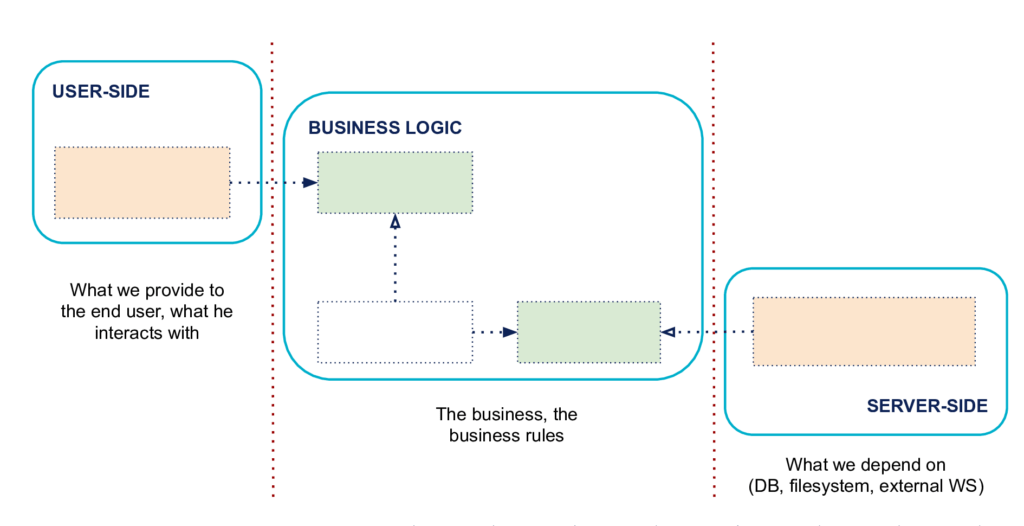
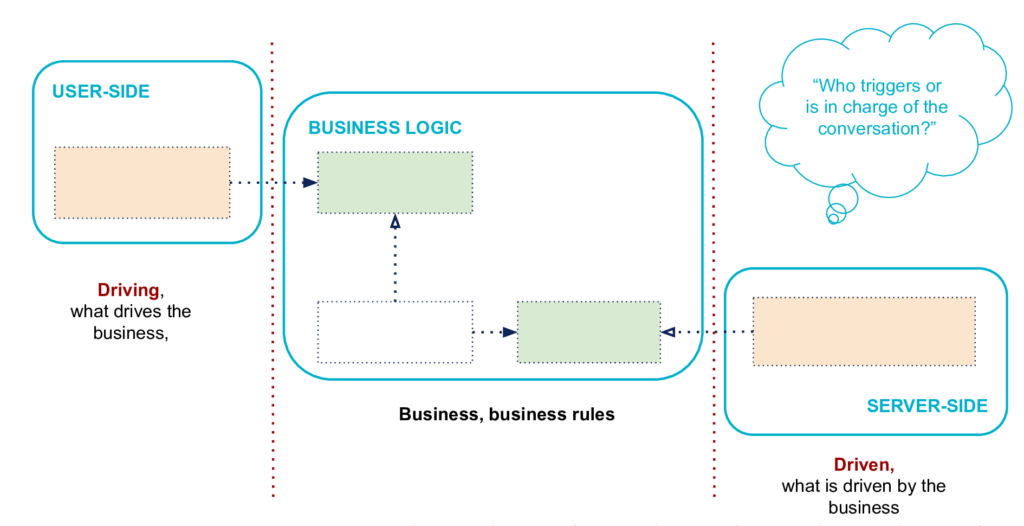
On the left, the User-Side
This is the side through which the user or external programs will interact with the application. It contains the code that allows these interactions. Typically, your user interface code, your HTTP routes for an API, your JSON serializations to programs that consume your application are here.
This is the side where we find the actors who drive the Business Logic.
Note: Alistair Cockburn also calls it the Left Side.
The Business Logic, in the center
This is the part that we want to isolate from both left and right sides. It contains all the code that concerns and implements business logic. The business vocabulary and the pure business logic, which relates to the concrete problem that solves your application, everything that makes it rich and specific is at the center. Ideally, a domain expert who does not know how to code could read a piece of code in this part and point you to an inconsistency (true story, these are things that could happen to you!).
Note: Alistair Cockburn also calls it the Center.
On the right, the Server-Side
This is where we'll find what your application needs, what it drives to work. It contains essential infrastructure details such as the code that interacts with your database, makes calls to the file system, or code that handles HTTP calls to other applications on which you depend for example.
This is the side where we find the actors who are managed by the Business Logic.
Note: Alistair Cockburn also calls it the Right Side.
The following principles will allow to put into practice this logical separation between User-Side, Business Logic and Server-Side.
Why is that important?
A first important feature of this separation is that it separates problems. At any time, you can choose to focus on a single logic, almost independently of the other two: user-side logic, business logic, or server-side logic. They are easier to understand without mixing them, and the constraints of each logic have less impact on the others.
Another characteristic is that we put business logic at the forefront of our code. It can be isolated in a directory or module to make it explicit to all developers. It can be defined, refined and tested without taking on the cognitive load of the rest of the program. This is important because, in the end, it is the developers' understanding of the business that goes into production.
And finally, in terms of automated tests (as we will see below), we will succeed in testing with a reasonable effort:
- The whole Business Logic individually,
- Integration between User-Side and Business Logic independently from the Server-Side
- Integration between Business Logic and Server-Side independently on the User-Side
Illustration: a small example of an application
To illustrate these principles more concretely, we will use the small example used during the "Alistair in the Hexagon" event, proposed in 2017 by Thomas Pierrain (@tpierrain) and Alistair Cockburn (@TotherAlistair) himself. Note: you will find the videos and the event code at the end of the article.
The purpose of this small application is to provide a command line program that writes poems into the standard output of the console.
Example of the expected output of this application:
$ ./printPoem Here is some poem: I want to sleep Swat the files Softly, please. -- Masaoka Shiki (1867 - 1902) Type enter to exit...
To correctly illustrate the three zones (User-Side, Business Logic, Server-Side), this application will search poems in an external system: a file. We could also connect this application to a database, the principles would be identical.
In this context, how can we apply this first principle, namely the separation into three zones? How to distribute on the left (what drives), in the center (the core business), and on the right (what is driven)?
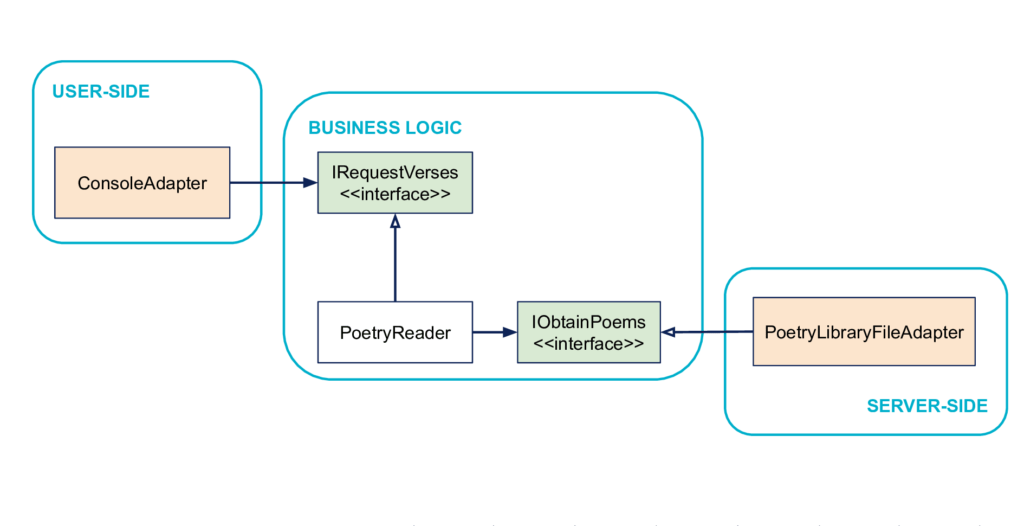
The User-Side
From the user's point of view, the program is presented as a console application. So the concept of console will be on the left, on the User-Side. It is through the console that the user will drive the domain.
The Server-Side
Technically, in our case, the poems are stored in a file. This notion of file will be found on the right, on the Server-Side. The business will make the request of its poems by piloting this right side, concretely implemented by a PoetryLibraryFileAdapter.
Here, as mentioned above, we can easily exchange our source of poems (a file, a database, a web service...). The actual implementation of the source as a file is therefore a technical detail (also called a technical implementation detail).
The Business Logic
Our core business in this case, what has value for the user, is the notion of reading poems. We can materialize this notion in the code with a PoetryReader class for example
User-Side → Business Logic interactions
From a business point of view, it doesn't matter whether the request comes from a console application or another, it's a technical detail that we want to be able to abstract. This is precisely one of the initial intentions: "to be driven as well by a user as by tests". There is therefore no concept of console in the Business Logic. What our application does allow, however, from the user's point of view (= the service it provides) is to ask for poems. It is this notion that we will find in the Business Logic (materialized by IRequestVerses) and that will allow the User-Side to interact with the Business Logic.
Business Logic → Server-Side interactions
Similarly, from the Business Logic point of view, it doesn't matter whether the poems come from a file or a database, we want to be able to test our application independently of external systems. No notion of file in the Business Logic. To operate, the domain still needs to get the poems. We find this notion of obtaining poems in the Buisiness Logic in the form of the IObtainPoems interface. It is this notion of obtaining poems that will allow the domain to interact with the Server-Side.
Note: From here, when you read the diagrams, you can start to observe the arrows that show the relationships between the classes. A solid arrow represents a call or composition interaction. And an arrow without filling represents an inheritance relationship (as in UML). But no need to analyze everything right away, we'll explore it in detail later.
Note: the names IRequestVerses and IObtainPoems represent many interfaces, we will talk about them in a principle to follow. For the anecdote, the convention of starting an interface name with an "i" is no longer in fashion but Thomas Pierrain reads interface names as sentences in the first person singular. IRequestVerses reads: I request verses for example. I like this idea.
Principle: dependencies go inside
This is an essential principle for achieving the objective. We have already begun to see this in the previous principle.
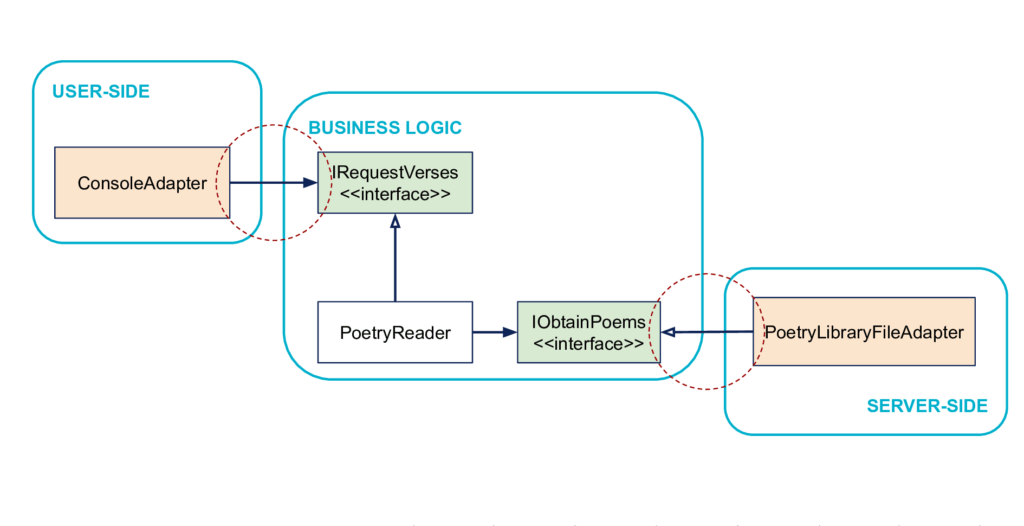
Principle: Dependencies go to the Business Logic
The program can be controlled both by the console and by tests, there is no concept of a console in the Business Logic. The Business Logic does not depend on the User-Side side, it is the User-Side side that depends on the Business Logic. The User-Side (ConsoleAdapter) depends on the notion of poem request, IRequestVerses (which defines a generic "poem request" mechanism on the part of the user).
Similarly, the program can be tested independently of its external systems, the Business Logic does not depend on the Server-Side, it is the opposite. The Server-Side depends on the Business Logic, through the notion of obtaining poems, IObtainPoems. Technically a class on the Server-Side side will inherit the interface defined in the Business Logic and implement it, we will see it in detail below to talk about dependency inversion.
Inside and outside
If we see dependency relationships (<<depends on...>>) as arrows, then this principle defines the central Business Logic as inside, and everything else as outside (see figure). We regularly find these notions of inside and outside when we discuss hexagonal architecture. It can even be the fundamental point to remember and transmit: dependencies go inside.
In other words, everything depends on the Business Logic, the Business Logic does not depend on anything. Alistair Cockburn insists on this demarcation between inside and outside, which is more structuring than the difference between User-Side and Server-Side to solve the initial problem.
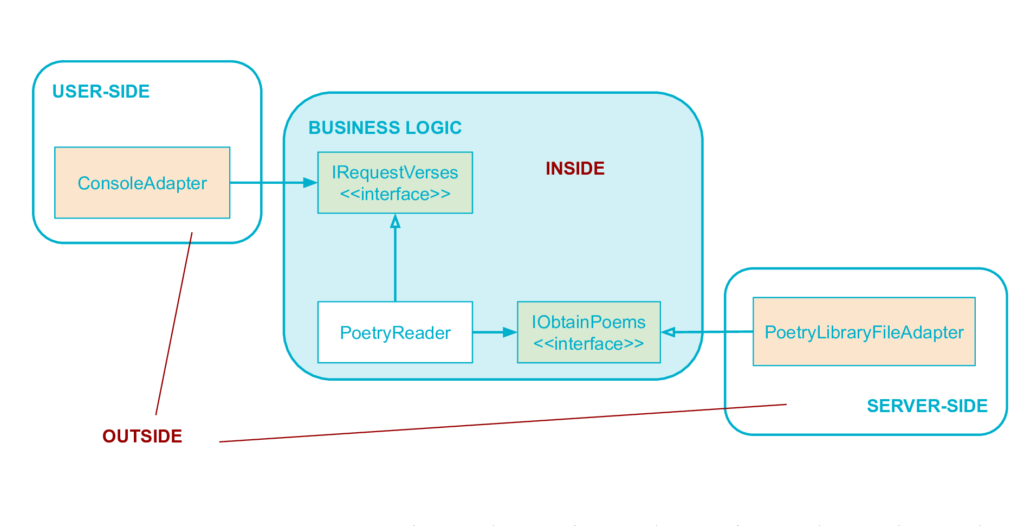
Principle: boundaries are isolated with interfaces
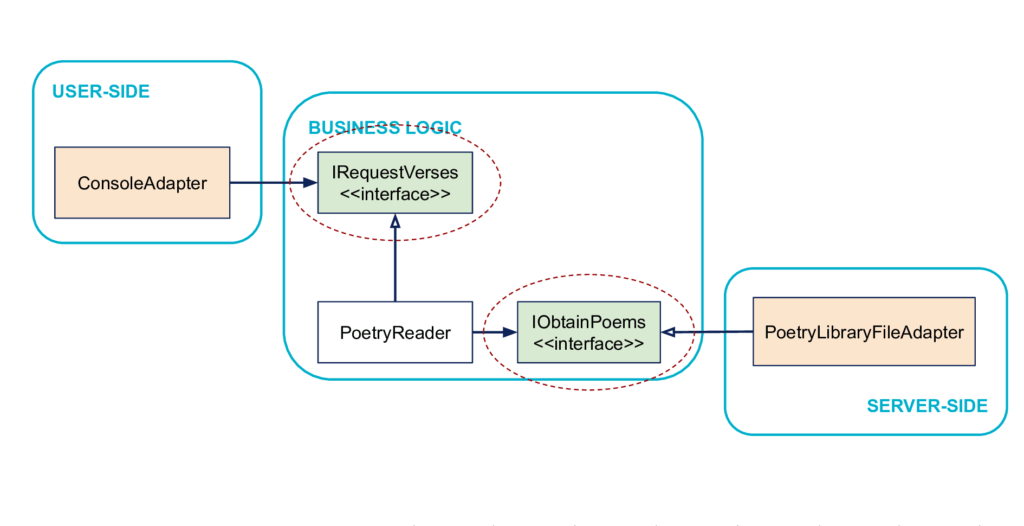
To summarize, the user-side code drives the business code through an interface (here IRequestVerses) defined in the business code. And the business code drives the server-side through an interface also defined in the business code (IObtainPoems). These interfaces act as explicit insulators between inside and outside.
A Metaphor: Ports & Adapters
The hexagonal architecture uses the metaphor of ports and adapters to represent the interactions between inside and outside. The image is that the Business Logic defines ports, on which all kinds of adapters can be interchangeably connected if they follow the specification defined by the port.
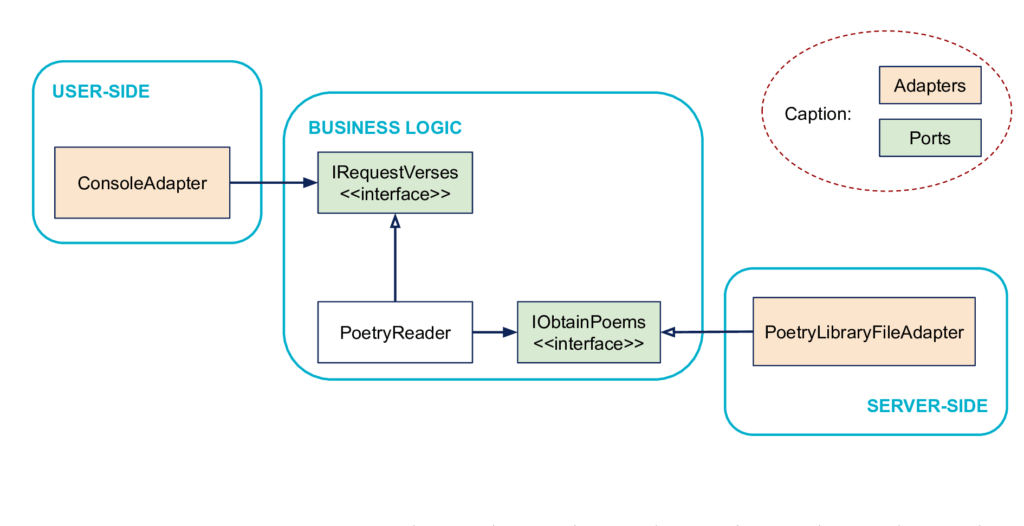
For example, we can imagine a port of the Business Logic on which we will connect either a hard-coded data source during a unit test, or a real database in an integration test. Just code the corresponding implementations and adapters on the Server-Side, the Business Logic is not impacted by this change.
These interfaces defined by the business code, which isolate and allow interactions with the outside world are the ports of the Ports & Adapters metaphor. Note: as mentioned previously, ports are defined by the business, so they are inside.
On the other hand, Adapters represent the external code make the glue between the port and the rest of the user-side code or server-side code. Here, the adapters are ConsoleAdapter and PoetryLibraryFileAdapter respectively. These adapters are outside.
Another Metaphor: the Hexagone
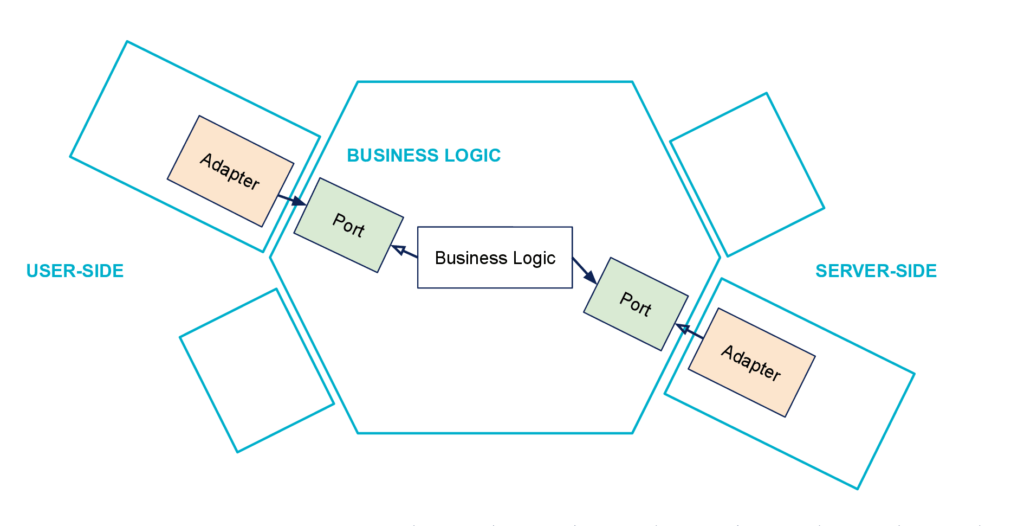
Another metaphor that gave its name to this architecture is the hexagon, as we see on the previous figure. Why a hexagon? The main reason is that it is an easy-to-draw shape that leaves room to represent multiple ports and adapters on the diagram. And it turns out that even if the hexagon is quite anecdotal in the end, the expression Hexagonal Architecture is more popular than Ports & Adapters Pattern. Probably because it sounds better?
The theoretical part is over, there are no other principles: for everything else we are totally free.
Detail: How is the code organized inside and outside?
Apart from the principles seen above, we are totally free to organize the code within each zone exactly as we want.
Concerning the business code, the inside, a good idea is to choose to organize its modules (or directories) according to the business logic.
One organization to avoid is to group classes by types. For example the "ports" directory, or the "repositories" directory (if you use this pattern), or the "services" directory. Think 100% business in your business code, including for the organization of your modules or directories! The ideal case is to be able to open a directory or a business logic module and immediately understand the business problems that your program solves; rather than seeing only "repositories", "services", or other "managers" directories.
See also on this topic:
- https://medium.com/@msandin/strategies-for-organizing-code-2c9d690b6f33
- https://martinfowler.com/bliki/PresentationDomainDataLayering.html
Detail: At the Runtime
How exactly do you instantiate all this to satisfy runtime dependencies? If you are using a dependency injection framework, you may not need to ask yourself this question. But I think that to understand the hexagonal architecture, it's interesting to see what happens when the application starts. And to do this, do not use dependency injection framework at least for the time of this article.
For example, here is how we will write the entry point of the application if we instantiate everything by hand:
class Program { static void Main(string[] args) { // 1. Instantiate right-side adapter ("go outside the hexagon") IObtainPoems fileAdapter = new PoetryLibraryFileAdapter(@".\Peoms.txt");
// 2. Instantiate the hexagon
IRequestVerses poetryReader = new PoetryReader(fileAdapter);
// 3. Instantiate the left-side adapter ("I want ask/to go inside")
var consoleAdapter = new ConsoleAdapter(poetryReader);
System.Console.WriteLine("Here is some...");
consoleAdapter.Ask();
System.Console.WriteLine("Type enter to exit...");
System.Console.ReadLine();
}
}
The instantiation order is typically from right to left:
- First we instantiate the Server-Side, here the fileAdapter which will read the file.
- We instantiate the Business Logic class that will be driven by the application, the poetryReader in which we inject the fileAdapter by injection into the constructor.
- Install the User-Side, the consoleAdapter that will drive the poetryReader and write to the console. Here the poetryReader is injected into the consoleAdapter by injection into the constructor.
We said the inside shouldn't depend on the outside. So why do we inject the fileAdapter, which is code from the Server-Side, into the poetryReader which is code from the Business Logic?
We can do this because, by looking at the schemas and code, in addition to being a PoetryLibraryFileAdapter (Server-Side), the fileAdapter is also an instance of IObtainPoems by inheritance.
In practice, the PoetryReader does not depend on PoetryLibraryFileAdapter but on IObtainPoems, which is well defined in the Business Logic code. You can check it by looking at the signature of its constructor.
public PoetryReader(IObtainPoems poetryLibrary) { this.poetryLibrary = poetryLibrary; }
PoetryLibraryFileAdapter and PoetryReader are weakly coupled.
Detail: Dependencies inversion on the right
The fact that the fileAdapter depends on the business for its definition (dependency by inheritance here), but that at the runtime the poetryReader can control in practice an instance of fileAdapter is a classic case of dependency inversion.
Indeed, without the IObtainPoems interface, the business code would depend on the server-side code for its definition, which we want to avoid:
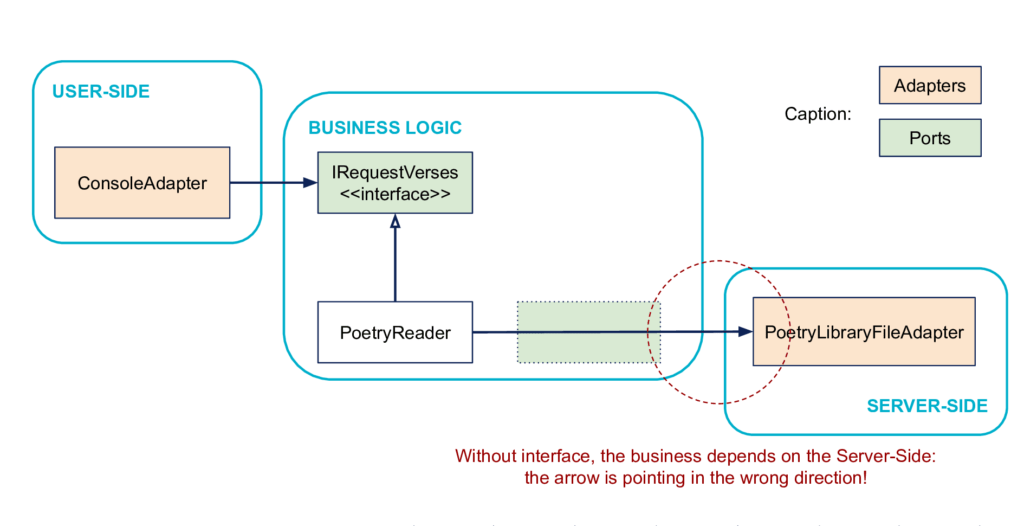
The interface allows to reverse the direction of this dependency:
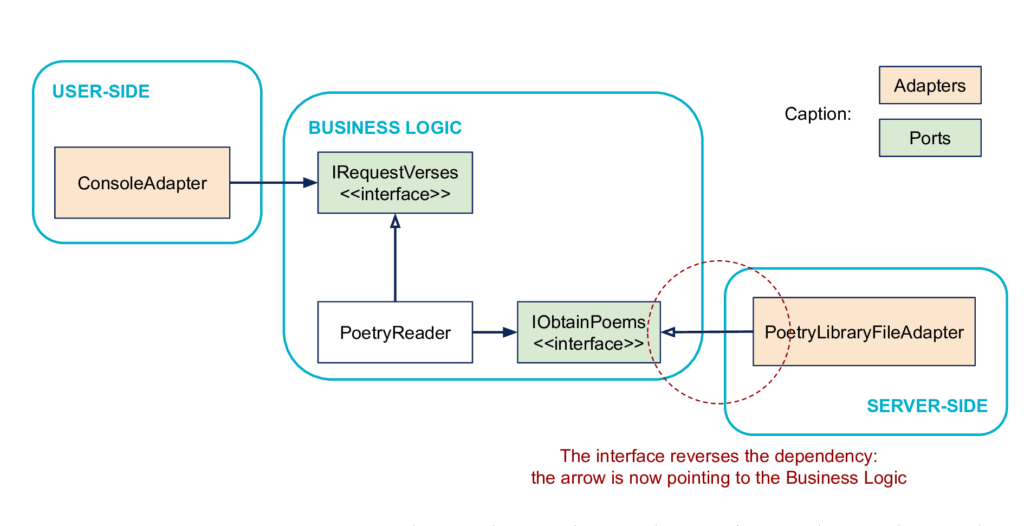
In addition to making the business independent of external systems, this interface on the right allows to satisfy the famous D of SOLID, or Dependency Inversion Principle. This principle says:
- High level modules should not depend on low level modules. Both must depend on abstractions.
- Abstractions should not depend on details. The details must depend on the abstractions.
If we did not have the interface, we would have a high-level module (the Business Logic) that would depend on a low-level module (the Server-Side).
Note: for interactions between the left side and business code, dependency is naturally in the right direction.
This difference in the implementation of interactions is related to the difference between User-Side / Business Logic and Business Logic / Server-Side relationships. Reminder: the User-Side drives the Business Logic, and the Server-Side is driven by the Business Logic.
Detail: Why an Interface on the left?
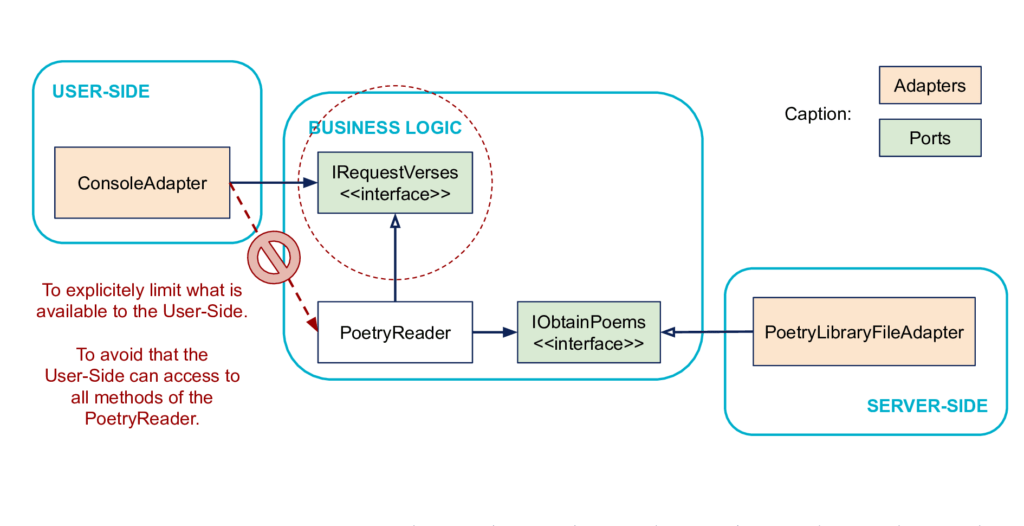
Since the dependencies between User-Side and Business Logic are already in the right direction, the role of the IRequestVerses interface is not to reverse dependencies.
However, it still has an interest: that of explicitly limiting the coupling surface between the User-Side code and the Business Logic code.
In practice, the PoetryReader class can have other methods than those of the IRequestVerses interface. It is important that the ConsoleAdapter is not aware of this.
And it is aligned with another SOLID principle, Interface Segregation Principle.
Clients should not be forced to depend on methods they do not use.
But once you have understood the intent, if a port to the left side has only one method, and its implementation has only one method as in our example, is the interface really necessary? In a dynamic language that will work by duck typing in the end?
We can answer with a question: what does your team think about this? Is the isolation objective clear to everyone, no need for an interface to even trigger a conversation? It's up to you to decide altogether.
Testing in Hexagonal Architecture
An important benefit of this software architecture is that it facilitates test automation, which is part of its original intent.
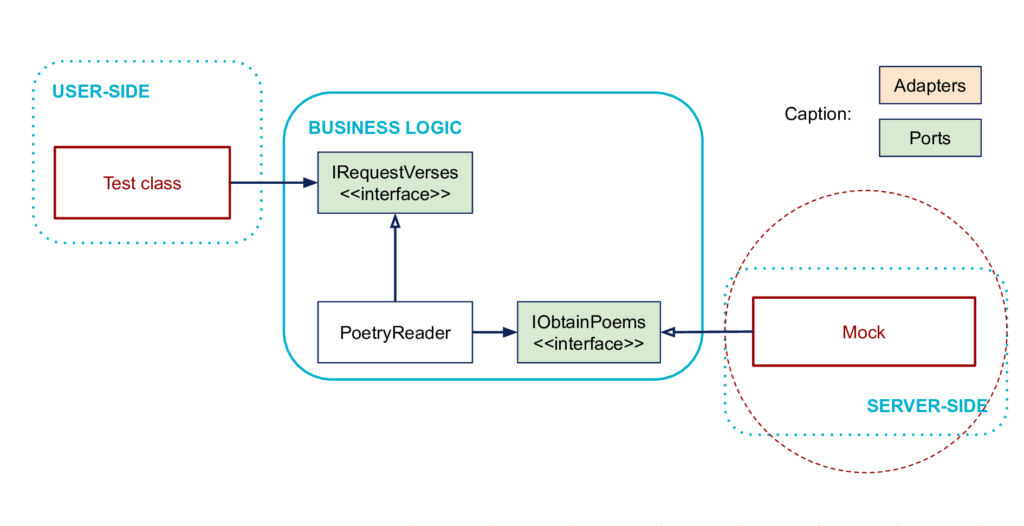
How to replace some code from the User-Side?
In the general case, the role of the left code can be directly played by the test framework. Indeed, the test code can directly drive the business logic code.
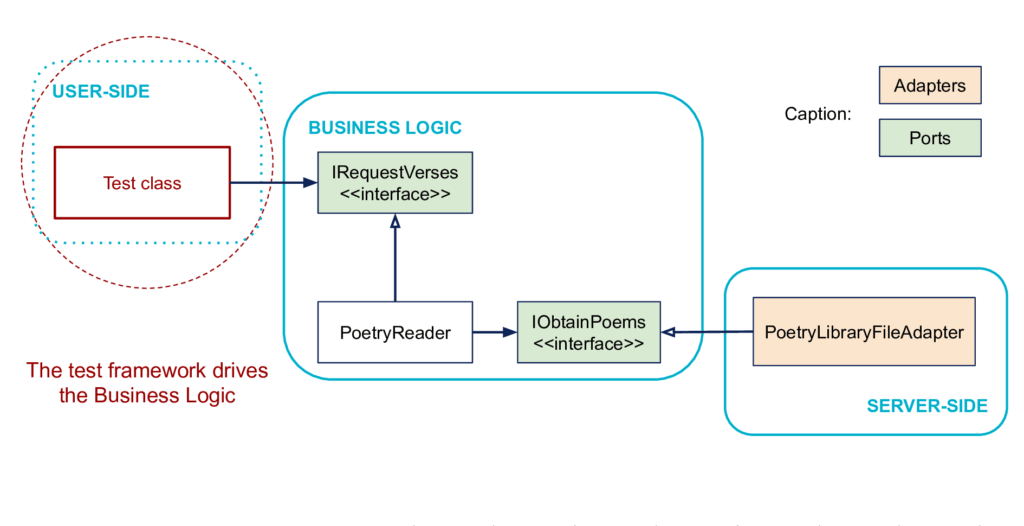
Note: The figure illustrates an integration test because the right part is not replaced. It can also be replaced, see below.
How to replace some code of the Server-Side?
The code on the right must be driven by the business. In general, if you want to write a unit test, you replace it with a mock or any other form of test double depending on what you want to test.
Target reached!
Allow an application to be driven by users, programs, automated tests or batch scripts, and to be developed and tested in isolation from its possible execution systems and databases.
Be careful! This does not prevent you from testing your User-Side and Server-Side code, any code deserves to be tested. On this subject, I refer you again to the series The pyramid of tests by practice.
And indeed, by combining what we replace or not, we see that with this architecture we can test what we wanted:
- The whole Business Logic individually,
- Integration between User-Side and Business Logic, independently from the Server-Side
- Integration between Business Logic and Server-Side, independently on the User-Side
To go further ahead
Talk about it as a team, who already knows how to do it at home?
Go ahead, experiment in real life, on your code. A small personal project for example, or a small project with your team. What is easy for you, what is difficult?
Here are some additional questions you may have during implementation:
- A port can have only one method, or group several methods. What makes sense in your case?
- Even when it follows the dependency principles well, the code is not necessarily separated into three explicit modules or directories or packages or namespaces. As in Thomas Pierrain's code, I have seen several times the Business Logic code in a "Domain" directory, and both the User-Side and Server-Side code in an "Infrastructure" directory. In his example, the inside code is located in the HexagonalThis.Domain namespace, and the outside code in the HexagonalThis.Infra namespace.
Quick reminder: there is no silver bullet. The hexagonal architecture is a good compromise between complexity and power, and it is also a very good way to discover the subjects we have addressed. But it is only one solution among others. For simple cases, it may be too complicated, and for complicated cases, it may be too simple. And there are other software architectures worth exploring. For example, Clean Architecture goes further in formalisation and insulation (with a zest of extra SOLID). Or in a different but compatible axis, CQRS makes it possible to better separate readings and writings.
References
The videos of the event "Alistair in the Hexagone" are here. The code from this event is on Thomas Pierrain's github.
You can also read these good articles on this topic:
- http://alistair.cockburn.us/hexagonal-architecture
- http://wiki.c2.com/?HexagonalArchitecture/
- https://martinfowler.com/bliki/PresentationDomainDataLayering.html
- https://fr.slideshare.net/ThomasPierrain/coder-sans-peur-du-changement-avec-la-meme-pas-mal-hexagonal-architecture
- http://tpierrain.blogspot.fr/2016/04/hexagonal-layers.html
- http://alistair.cockburn.us/Configurable+Dependency
- http://blog.cleancoder.com/uncle-bob/2016/01/04/ALittleArchitecture.html
Finally, thanks to Thomas Pierrain for allowing me to reuse his sample code, and thanks for the suggestions and proofreadings by: Etienne Girot, Jérôme Van Der Linden, Jennifer Pelisson, Abel André, Nelson Da Costa, Simon Renoult, Florian Cherel Enoh, Mathieu Laurent, Mickael Wegerich, Bertrand Le Foulgoc, Marc Bojoly, Jasmine Lebert, Benoît Beraud, Jonathan Duberville and Eric Favre.
Update note: in a first version of this article, we used the words Application, Domain and Infrastructure in place of User-Side, Business Logic and Server-Side. We went back to the original words because this substitution was sometimes ambiguous and not helpful.