Harnessing des agents : 9 pratiques venant du logiciel
C’est dans les vieux pots que l’on fait les meilleures soupes, cet article est un plaidoyer pour ne pas oublier les bonnes pratiques du logiciel mais plutôt les utiliser et les adapter pour maximiser l’impact des agents de code.
L’Agentic Engineering, terme proposé par Andrej Karpaty, débarque comme une déferlante sur nos projets. Pour que l’utilisation d’agent de code ne se transforme pas en catastrophe industrielle, en particulier en brownfield, en production, il faut des pratiques. Le terme harnessing a été proposé par OpenAI, Anthropic et d’autres pour désigner l’ensemble des pratiques qui visent à tenir en “laisse” les agents de code.
Le marché est alors vite tenté d’inventer des nouvelles pratiques pour faire cela, nous avons la conviction qu’il est préférable d’utiliser et adapter notre savoir faire du logiciel sans agent.
Dans cet article, nous explorons et adaptons 9 pratiques du logiciel qui permettent de bien cadrer l’agent de code comme le développeur.
Introduction à la notion de harnais
Les harnais visent à tenir en laisse, à maîtriser l’agent de code pour avoir un résultat plus fiable.
Birgitta Böckeler sur le blog de Martin Fowler introduit plusieurs types de harnais :
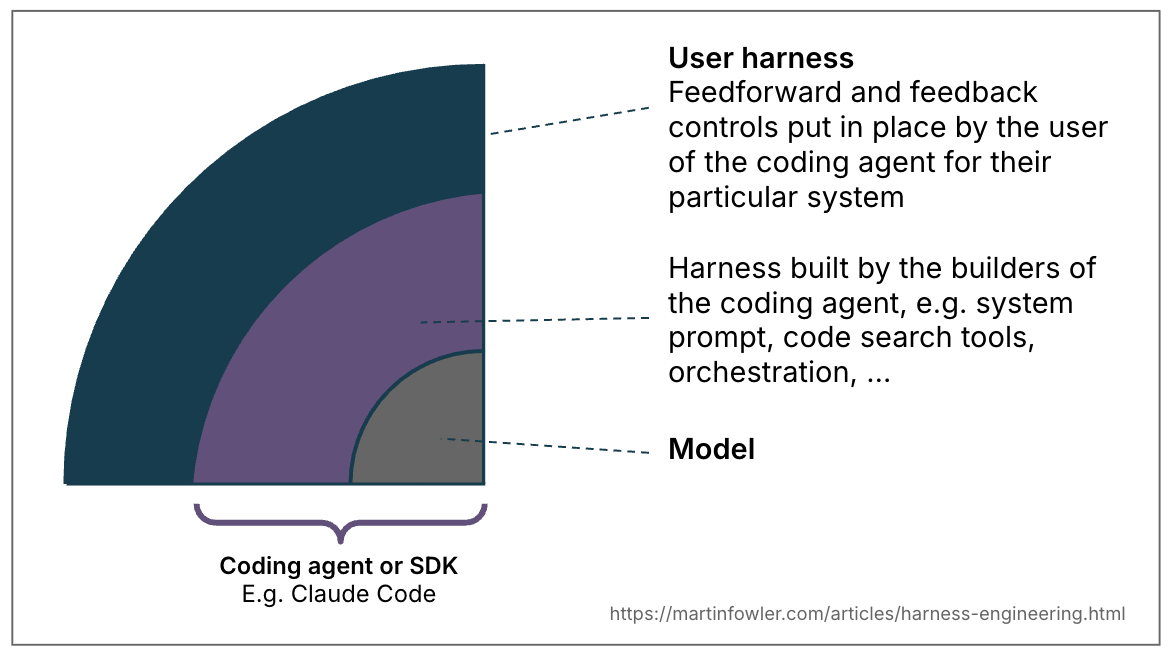
Cet article se concentre sur ceux définis par les utilisateurs (user harness), qui sont spécifiques à un projet / une équipe.
Ensuite, elle distingue les harnais feedforward qui visent à fournir un contexte plus pertinent, à guider l’agent avant l’action et feedback qui visent à observer (elle utilise le terme sensor) le résultat de l’agent et l’aider à s’autocorriger.
Ces harnais peuvent être déterministes, au sens de calculées, ou non-déterministes, au sens de inférées par le LLM.
Dans cet article, seront explorées et adaptées 9 pratiques venant du logiciel “sans agent” : huit seront feedforward et une feedback.
Pratique n°1 : Adopter une démarche de mono repository
🏷️ Type : feedforward, Nature : Non-déterministe
L’idée : Rassembler dans un seul repository de code l’ensemble du code produit par une ou plusieurs équipes. En opposition à découper un cas d’usage = un repo ou, pire, un cas d’usage = un repo de front, un de back, un d’ops.
Exemple :
📦 project-root
├── 📂 .github
├── 📂 config
├── 📂 documentation
├──├── 📂 experimentations
├── 📂 front
├── 📂 back
├── 📂 infrastructure
├── 📂 data-eng
├── 📄 .env
├── 📄 README.md
Comment cela impacte positivement l’agent de code :
- Maximise les chances d’harmonisation.
- Rend toutes les infos accessibles dans une seule fenêtre d’IDE, dans le cas contraire un humain devrait ouvrir un autre projet, et l’agent de code prendra des hypothèses.
- Facilite l’identification des changements qui auront un impact d’un service sur l’autre
- Mutualise les outils d’analyse de code et leurs configurations (voir Pratique n°3).
- Simplifie le déploiement en assurant d’avoir des versions de services compatibles
L’humain aussi en profite en réduisant le nombre de changements de fenêtres d’IDE.
Les contreparties :
- C’est l’intégration continue (CI) en charge de construire les artefacts et le déploiement continu (CD) qui compensent en sélectionnant ce qu’il faut pour construire les artefacts et les envoyer au bon endroit
- Pour les langages non compilés, et donc testés avant le build, il faut penser à valider après le build que l’artefact construit est complet pour éviter les mauvaises surprises. Par exemple, le fichier config/logger.py n’a pas été copié.
- La collaboration multi-équipe ou multi agent peut être complexifiée, investir dans un bon découpage (voir Pratique n°4) permettra de limiter cette contrepartie. Mono repo ne signifie pas fin du découpage !
- Il faut veiller à bien organiser et nommer sans ambiguïté pour s’y retrouver facilement (voir Pratique N°2)
NB : Il est envisageable d’ouvrir une fenêtre d’IDE dans un des sous dossier pour se focus
Pratique n°2 : Lever les ambiguïtés
🏷️ Type : feedforward, Nature : Non-déterministe
L’idée : Dans tout projet, il y a des objets mal nommés, ou des noms qui recouvrent deux objets. Un exemple classique peut être le “client” qui est à la fois le client de l’entreprise, le consommateur d’une api, … Lorsque le vocabulaire n'est pas clair et explicite, l’humain s'emmêle, l’agent aussi (voire plus). L’intention est d’investir de l’énergie pour nommer correctement les choses, pour préciser les acronymes.
Classiquement ce sont des choix inconscients, ou pire, nous choisissons de donner des noms rigolos, par exemple nommer ces tables d’après des personnages de starwars.
Avant de lancer la création d’une fonctionnalité, il convient d’identifier le vocabulaire à utiliser, le challenger, cela peut être en itérant avec l’agent soit via des ateliers tels que l’event storming, ou plus simplement des discussions avec ses pairs. Cette pratique nous vient du DDD et sa recherche de l’ubiquitous language.
“Ce qui se conçoit bien s’énonce clairement et les mots pour le dire viennent aisément.” - Nicolas Boileau
Lorsque l’agent doit nommer quelque chose, il est recommandé de lui demander de faire valider par l’humain (ou l’équipe) des propositions de nom, lui demander de signaler d’éventuelles ambiguïtés de vocabulaire. Enfin, noter ce vocabulaire dans un glossaire, par exemple un markdown AGENT.md (voir Pratique n°7).
Comment cela impacte positivement l’agent de code :
- Avec une base de code plus lisible, plus explicite, la probabilité que l’agent se mélange les pinceaux, ne fasse pas les modifications au bon endroit est réduite.
- La base de code sera également plus lisible pour l’humain, qui maîtrisera l’ensemble des concepts métiers utilisés.
Les contreparties :
- C’est chronophage, l’humain comme l’agent ne peut souvent pas décider seul, il faut s’aligner à plusieurs.
- En tant que développeur, le besoin d’un nom vient souvent au moment où l’on veut valider la faisabilité, et ce n’est généralement pas le moment où l’on souhaite être ralenti.
NB : Cette pratique est déterministe au sens où l’agent n’aura pas d'ambiguïté dans son contexte, mais non déterministe car elle ne garantit pas que l’agent utilise le bon terme 100% du temps.
Pratique n°3 : Avoir des boucles de feedback rapides et automatisées
🏷️ Type : feedback, Nature : déterministe
L’idée : Même lorsque les standards sont clairement établis et répétés (par exemple, l'explicitation de patterns obligatoires dans les skills ou les prompts), l’agent risque de les omettre partiellement ou totalement à mesure que la fenêtre de contexte augmente.
Plutôt que de faire du prompt engineering et d’écrire “Tu dois ABSOLUMENT respecter ces patterns”, la proposition est d’automatiser leur validation via des outils tels que linter et tests d’architecture logiciel (voir cet article introductif).
En pratique, il s’agit, pour chaque décision d’architecture, pour chaque nouveau standard choisi, de réfléchir à le valider de manière automatisée. Cela ressemble beaucoup à l’approche Test Driven Development (TDD).
Exemple de commandes make pour la validation dans un projet python :
static-validation:
ruff check --preview .
bandit .
.phony: test
test:
pytest tests
Comment cela impacte positivement l’agent de code :
- L’agent, comme le développeur ne pourra plus oublier !
- La validation pourra avoir lieu en local comme dans la CI avant la code review.
- En évitant les allers-retours avec le reviewer, l’agent consomme moins de tokens.
La contrepartie : Cela implique d’être vigilant dans le choix des standards et des patterns à appliquer pour ne pas paralyser le développement.
NB : Ces boucles de feedbacks seront automatisées en hook de pre-commit et dans la CI, elles peuvent aussi être mentionnées dans les instructions données à l’agent (voir Pratique N°9).
Pratique n°4 : Suivre et expliciter les patterns d’architecture
🏷️ Type : feedforward, Nature : Non-déterministe
L’idée : Pour qu’un logiciel puisse évoluer et garder sa vélocité au-delà de la phase de prototypage, et lorsque plusieurs contributeurs (agents comme humains) travaillent dessus, il doit être structuré.
Cette pratique consiste à formaliser et documenter explicitement les patterns d'architecture (tels que clean architecture, choix d’un framework). Ces choix doivent être conscients et documentés via des ADR (voir Pratique N°7). Ils peuvent être choisis en mode plan ou sparring partner avec l’agent.
Comment cela impacte positivement l’agent de code :
- Fournit un cadre strict pour la génération de code, empêchant le mélange de styles.
- Maximise les chances d'obtenir un résultat qui ressemble à ce que l’on avait imaginé.
- Permet d'implémenter facilement une boucle de validation automatisée (voir Pratique n°3).
La contrepartie : L’agent étant très rapide à la production de code, il faut poser les patterns au plus tôt. La pratique d’architecture émergente devient alors risquée.
Pratique n°5 : Avoir des abstractions, des outils facilement utilisables
🏷️ Type : feedforward, Nature : peut être déterministe
L’idée : Au sein d’un projet brownfield, des abstractions, des outils ont été développés pour éviter de dupliquer le code, pour implémenter les prochaines features plus simplement.
Avoir cela dans un projet, permet à l’agent de les utiliser et donc d’implémenter une nouvelle fonctionnalité plus vite, et de manière plus fiable.
Des exemples peuvent être :
- La couche d’accès au données : Au lieu de lui laisser écrire la façon de lire les données au risque qu’il le fasse de manière non optimale lui fournir un
Readerprenant comme argument les informations strictement nécessaires. - Le Design System / Composants UI : Au lieu de laisser l'agent générer un style inspiré d’un site existant, lui fournir le design system l’accélérera grandement.
Comment cela impacte positivement l’agent de code :
- Le résultat produit sera beaucoup plus fiable et plus proche de l’attendu.
- L’agent peut commettre moins d’erreurs, il nécessitera ainsi également moins d’itérations pour se corriger.
- En ré-utilisant, l’agent sera plus rapide, et réduira sa consommation de tokens en entrée comme en sortie.
Les contreparties :
- Faire émerger des abstractions requiert une attention particulière : temps ou tokens doivent y être consacrés. Il faut trouver le bon équilibre entre faire émerger des abstractions et développer de nouvelles fonctionnalités.
- Cependant, les agents ne sont pas encore très talentueux pour faire émerger les abstractions minimalistes. Si on leur demande de trouver des abstractions, ils rapidement du sur-ingeniering. Il faudrait, peut-être, imaginer des harnais à un niveau d’abstraction supérieur pour les faire converger.
NB : Cette pratique est déterministe si l’humain produit les abstractions et que l’agent se restreint à les utiliser, et non-déterministe si l'agent est chargé de les faire émerger.
Pratique n° 6 : développer itérativement, par petites features et livrer régulièrement
🏷️ Type : feedforward, Nature : peut être déterministe
L’idée : Le découpage en petites tâches vise à permettre la parallélisation du travail (entre agents, entre humains ou entre les 2), être capable de revenir à une version précédente stable sans perdre trop de travail, et à limiter la charge mentale pour l’humain, ou le contexte pour l’agent.
Concrètement il s’agit d’établir une liste de tâches, de demander à l’agent de faire une petite itération et versionner chaque résultat ou de demander à l’agent de découper lui-même son travail. Certains environnements de développement agentic rendent visible cette liste de tâches et ses mises à jour.
Illustration : Exemple de liste de tâches visuelles dans opencode.
Comment cela impacte positivement l’agent de code :
- Optimisation du contexte : En traitant des portions de code plus petites, l'agent optimise son contexte (évitant le context rot), améliorant ainsi sa pertinence et sa précision.
- Gestion des sous-tâches : Le découpage facilite l'envoi de sous-tâches à des sub agents, la parallélisation devient possible et le sub-agent aura besoin d’un contexte plus restreint.
- Sauvegarder les versions satisfaisantes en les versionnant
- Limiter la charge de relecture (pour l’humain comme pour l’agent reviewer)
Les contreparties :
- Les merges complexes dû à plusieurs contributions non-indépendantes peuvent être plus fréquentes qu’en logiciel sans agent.
- Il convient de trouver le bon niveau de découpage (voir Pratique N°4) pour faciliter la collaboration.
NB : Cette pratique est déterministe si l’humain est responsable du découpage, et non-déterministe si l'agent est sollicité pour décomposer la tâche lors de sa phase de planification.
Pratique n°7 : La documentation as code en markdown
🏷️ Type : feedforward, Nature : non-déterministe
Le markdown est plus populaire que jamais !
L’idée : Documenter l'ensemble des informations de contexte directement dans des fichiers Markdown, au sein du mono-repository, pour qu'elles soient traitées "as code". Les Architecture Decision Records (ADR), les post mortems et les run playbooks sont des exemples de pratiques qui fournissent un contexte supplémentaire à l'agent.
Cette pratique sera en particulier bénéfique pour les tâches de refactoring profond afin de comprendre l’état du code et pour les tâches de débug afin de retrouver des situations passées similaires.
Comment cela impacte positivement l’agent de code :
- Un contexte riche et facilement accessible, permettant une meilleure compréhension de l'historique, des standards et des procédures du projet.
- L'information étant versionnée et à jour, l'agent se base sur des connaissances fiables.
La contrepartie : Nécessite une rigueur pour maintenir la concision et l'actualité des documents, afin qu'ils ne deviennent pas du bruit pour l'agent (voir Pratique N°2).
Les conseils :
- Les garder les plus “humaines” possibles, c'est-à-dire concise avec les“trous” dans le raisonnement plutôt que de laisser le LLM introduire du texte verbeux pouvant contenir des approximations.
- Faire le ménage régulièrement, notamment dans les ADR qui sont dépréciés (voir pratique n°8).
Pour aller plus loin, explorer l’augmented coding pattern Knowledge document.
Pratique n°8 : Faire le ménage régulièrement
🏷️ Type : feedforward, Nature : non-déterministe
L’idée : Pour plein de bonnes raisons, par exemple les standards / façons de faire qui évoluent, ou de mauvaises raisons, par exemple du code vite fait mal fait, le code contient une hétérogénéité non souhaitable. Celle-ci représente du bruit pour l’humain comme pour l’agent.
Avant les agents, un code en inadéquation avec les standards actuels n’était relu que lorsqu’il présentait un bug ou nécessitait une évolution, l’agent lui risque d’aller l’explorer bien plus souvent. Par exemple, les agents font souvent appel à des grep pour s’inspirer de code existant. L’impact de ce code est alors augmenté, l’agent risque de propager ces défauts ailleurs. Le nettoyer devient alors plus important.
La proposition est de faire des audits exploratoires, se promener ensemble (entre humains, ou avec l’agent) dans la base de code pour trouver des choses qui ne sont pas cohérentes avec le reste ou qui ne respectent pas les ADR, les standards, contient des ambiguïtés de vocabulaire et de corriger cela.
Il est également possible de scripter l’application de nouveaux standards, voire de poser un test sur le nombre de cas qui ne respectent pas les standards et s’assurer que ce nombre ne grandit pas.
Comment cela impacte positivement l’agent de code :
- La réduction de l’entropie maximise les chances de s’inspirer de code aux standards plutôt qu’en décalage avec ceux-ci.
- Cela augmente les probabilités d’identifier une bonne abstraction (voir Pratique N°5).
- La réduction du “bruit” au sein du repository réduit également le nombre de token utilisés pour converger vers une solution souhaitable.
La contrepartie : Cette action est consommatrice en temps comme en tokens, nous retrouvons à nouveau une logique d’équilibre entre l’énergie passé à nettoyer et celle à développer.
Les conseils :
- Le ménage c’est comme dans sa maison, un peu au quotidien et parfois des “grands ménages de printemps”.
- Cela s’applique aussi à l’ensemble des markdowns écrits dans le repository
NB : Cette pratique est non déterministe car l’usage que l’agent fait ou ne fait pas de la saleté n’est pas maîtrisé.
Pratique n°9 : la check list pour faire une tâche
🏷️ Type : feedforward, Nature : peut être déterministe
L’idée : Pour réaliser une tâche, un certain nombre d’étapes sont à réaliser. L’agent, comme le développeur peut deviner ce qu’il faut faire, mais si la tâche est régulière, la liste des choses à faire est déjà connue, souvent dans la tête du PO ou du tech lead et parfois documentée dans le ticket Jira. L’idée ici est de documenter cela dans une SKILL.md.
Comment cela impacte positivement l’agent de code :
- Pas de temps, et de tokens, consacrés à identifier ce qu’il faut faire.
- Moins d’oublis d’étapes à réaliser.
La contrepartie : Il faut prendre le temps de documenter ces étapes de manière précise
Les conseils :
- Le faire dans un markdown, c’est donc as-code !
- Versionné au sein du projet ou dans un repository dédié.
NB : Cette pratique est non-déterministe car l’agent pourra ignorer certaines étapes.
Conclusion
Si l’Agentic Engineering bouscule les actions du développeur : moins de temps est consacré à coder, plus à prompter, designer, comprendre le besoin métier, les pratiques pour accélérer et fiabiliser le delivery changent peu. Il convient “juste” de les adapter aux spécificités des agents.
Les 9 pratiques de harnessing que nous avons explorées ne sont rien d’autre que des fondamentaux d’une ingénierie logicielle saine et robuste, adaptée à cette nouvelle réalité. Les harnais feedforward optimisent le contexte de l'agent et réduisent la consommation de tokens, tandis que le harnais feedback (les boucles de validation automatisées) devient notre dispositif de sécurité le plus fiable.
En appliquant cette rigueur, nous maximisons l’utilisation d’agents de code : ils passent d'un outil de prototypage rapide et potentiellement risqué à un contributeur fiable et industrialisé.
Au travers de cet article, 9 ont été présentés, de nombreuses autres s’appliquent également, plutôt que d’oublier les pratiques passées et recommencer sa carrière en tant qu’AI Engineer, notre recommandation est de capitaliser sur nos expériences passées en logiciel pour accélérer le développement des agents.
Pour aller plus loin, nous recommandons d’explorer :
- Les pratiques proposées sur le projet Augmented Coding Patterns.
- Pourquoi les LLMs oublient une partie de leur contexte : Lost in the Middle: How Language Models Use Long Contexts
Remerciements : Sébastien Roccaserra, Julien Tellier, Christophe Durand, Simon Lefort, Ali El Moussawi, Damien Hecquet pour leurs relectures exigeantes.