Hadoop Summit 2013 à Amsterdam - La suite
Cet article est une suite à celui de Rémy, relatant nos pérégrinations au Hadoop Summit d’Amsterdam. Dans celui-ci, nous nous intéresserons d’abord à des retours d’expérience de l’écosystème Hadoop en entreprise : mise en place, adoption, et applications pratiques. La suite de l’article fera le compte-rendu des sessions plus techniques auxquelles j’ai pu assister.

Les retours d’expérience
Dans la plupart de ces expériences, on retrouve un motif récurrent. Les premières applications sont des quick-wins et consistent à déporter du stockage ou du batch simple sur Hadoop. Cette étape apporte de l’air principalement à l’IT et fait économiser des coûts de traitement devenus prohibitifs (exemple : mainframe).
Ensuite, à moyen terme, le datawarehouse est porté, afin de dépasser les limites de scalabilité des RDBMS classiques, tout en évitant l’extrême inverse des appliances coûteuses. Ce use case se répand, mais doit encore faire ses preuves avec la venue récente des frameworks de requêtage interactifs sur Hadoop. Cette étape apporte de la valeur à l’IT, et aux départements métiers qui utilisent le datawarehouse.
La troisième “ère”, à peine émergente, s’adresse elle à la stratégie de l’entreprise. C’est celle de la découverte de nouvelles applications ou de nouveaux services, grâce au puits de données et à ses capacités d’analyse étendue. En termes de moyens, on y retrouve le machine learning, le streaming et l’analyse temps réel.
Le cas de la HSBC
L’activité et l’organisation de la HSBC sont évidemment très éloignés de ceux d’un Facebook ou d’un Ebay : les processus y sont fortement cadrés, externalisés, et les expérimentations doivent être justifiées. L’adoption d’un tel outil est donc un défi - et une belle preuve que c’est possible.
En voulant dépasser les limites de scalabilité de la BI classique, la HSBC avait connu une expérience Big Data malheureuse (nous n’en saurons pas plus sur l’implémentation). La pression du time to market avait conduit à la prolifération des silos, sans retour satisfaisant pour les utilisateurs... La plateforme Hadoop a donc été montée avec en vision, une vue 360° des clients, produits et opérations, concentrée en un lieu unique.
L’adoption s’est faite petit à petit, en commençant par un POC en Chine : un cluster opérationnel en une semaine, un grand déversement de 18 systèmes (datawares et datamarts compris) dans le cluster, sans ETL, par copie de fichiers, puis un portage d’un batch Java avec un temps d’exécution ramené de 3h à 10 minutes.
Ce succès a motivé un hackaton de 24h, ouvert aux équipes sous-traitantes, pour mettre la main à la pâte et imaginer de nouvelles applications. A titre d’exemple, l’équipe gagnante (3 personnes) a mis en place une application d’optimisation de portefeuille, à base de Hadoop et de R.
Il reste quelques challenges à surmonter :
- les opérations, à faire rentrer dans le cadre de la HSBC : virtualisation, DRP, sécurité des données et accès à celles ne pouvant être copiées vers le cluster (fédération)
- l’organisation : devops n’est pas à l’ordre du jour, cependant le maintien de la plateforme nécessite des compétences multiples
- l’effet de mode : il y a un risque de pousser une solution qui n’apporte pas la valeur souhaitée dans le contexte. Pour éviter cet effet, la HSBC a établi un arbre de décision technologique (et le maintient à jour), et utilise la popularité de Hadoop comme catalyseur (exemple du hackaton)
Chez Deutsche Telekom (DT)
La session était très dense, et les slides étaient bien remplis ! Mais le discours était très clair et le retour d’expérience pertinent. Voici un compte-rendu à la serpe, qui ne fait pas honneur à la présentation dans son ensemble... Une lecture des slides sera plus instructive pour un discours général sur Hadoop et sur Big Data, au-delà du retour d’expérience simple.
Les chiffres de DT : 50 use cases Hadoop implémentés, 600 utilisateurs sensibilisés à la BI (i.e. qui connaissent SQL). DT a mis en place son cluster Hadoop comme “data fabric” centralisée. Là encore, on retrouvait les 3 vagues d’adoption et de valeur résumées en introduction de cet article.
Voici la liste des questions que DT s’est posée lors de la mise en place de la plateforme :
- le type d’infrastructure de stockage (SAN, NAS, Hadoop, DAS, Cloud, par ordre décroissant de coût)
- a-t-on vraiment besoin d’Hadoop ? En-deçà de 10 TB de données structurées, ou sur des volumes intermédiaires mais avec des données très proches des sources relationnelles, la valeur est discutable. Sur les gros volumes non structurés la valeur est là, mais certains use cases (le temps réel notamment) ne sont pas encore couverts
- la virtualisation - ou pas - des noeuds, en fonction des contraintes d’isolation (de ressources, de données, de versions) et des environnements
- la distribution Hadoop le cas échéant. Evidemment les acteurs bougent, notamment dans le domaine du requêtage interactif (deuxième palier) ! Et attention au “big data washing”...
- les sources de données, en fonction de leur origine, leur typologie, leur volume, et leurs API d’accès
- le type de traitement à effectuer, y compris l’interaction avec d’autres systèmes complémentaires comme Cassandra ou les bases relationnelles du SI. Un message à retenir : “Store first, ask questions later”
- l’exploitation : backup, PRA, TCO, impact de l’hétérogénéité du cluster sur le long terme, migrations de versions, compétences, ...
Pour une entreprise “abonnée” à Microsoft
Une session qui laissait sur sa faim... Il était très peu question de l’intégration d’Hadoop avec les outils Microsoft, sauf un peu à la fin, et encore moins des éditions d’Hadoop optimisées pour les environnements Windows.
Un SI “tout Microsoft” est simple en apparence, mais pour un outil “de l’extérieur” le nombre de composants techniques en face rend la tâche d’intégration compliquée : NTFS, SSIS (ETL), OLAP, Active Directory, System Center, …
Pourquoi tous ces composants ? La donnée est en général décentralisée : des fichiers dans des répertoires réseaux (propriétés des départements de l’entreprise), des bases de données SQL Server, des annuaires, des portails, des logs IIS, … HDFS est un bon candidat pour recentraliser la donnée et reconstituer une vue client complète (par exemple). Le pattern “schema on read” adapté à la diversité de ces données. Le requêtage avec les outils Microsoft est possible avec les drivers ODBC de Hive, par exemple.
Quelques astuces pour récupérer cette donnée :
- commencer simple, avec les logs, qui sont en plus susceptibles de tourner assez vite (les stocker sur HDFS permet de les archiver facilement). A ce stade, les métiers et l’IT peuvent déjà faire du log mining
- se brancher sur les jobs ETL qui irriguent le SI, en mettant des “robinets de données” aux points intéressants (notamment aux frontières entre les départements). Dans un temps suivant, on peut envisager un enrichissement
Pour ce qui est de données stockées dans Sharepoint ou Exchange, il n’y a pas de procédure standard, il faut faire des exports et les cruncher avec Pig par exemple. La tâche n’est pas simple pour Sharepoint à cause du format propriétaire.
A l’autre bout de la chaîne, une restitution PowerView des données du cluster est possible avec le connecteur ODBC. Les performances seraient plutôt acceptables (sans plus de précision), y compris pour des données volumineuses en utilisation interactive.
Pour ce qui est de la plateforme, HDInsight, l’édition Hadoop d’Azure, est en beta publique, à $70 / TB / mois aux Etats-Unis (sur site ou sur le cloud). Le cluster est administrable depuis System Center.
Au sein des Bilbliothèques Nationales des Pays-Bas et d’Autriche
Les contextes des bibliothèques nationales sont très particuliers. Il s’agit de numériser ou d’archiver un patrimoine culturel multiforme (livres, textes, sites web, images, vidéos, …), qui croît bien plus vite que le processus de numérisation, avec indexation, restitution aux citoyens, et en garantissant la pérénnité des formats de stockage, qui sont multiples et spécifiques au domaine. A titre d’exemple, le projet européen Enumerate constatait qu’en 2012 seuls 4% de l’héritage culturel était numérisé.
Voici les scénarios possibles présentés dans cette session. Comme ils opèrent sur des documents ou des parties de documents (images par exemple), ils se prêtent bien à de la distribution avec un framework comme Hadoop.
Numérisation d’une image en XML (par exemple, un journal scanné). On peut chercher à encoder la structure du document, le transformer en ebook, l’indexer, …
La conversion bidirectionnelle JPEG 2000 ←→ TIFF : ce besoin émerge de la contradiction entre deux contraintes. JPEG 2000 est plus compact que TIFF, mais sous licence et peut-être moins pérenne (en tant que standard). On veut donc pouvoir passer librement de l’un à l’autre. Ce type de scénario se représente sous forme de workflows, qui font intervenir des outils de traitement d’image multiples (écrits en Java, en Python, …), et des étapes de validation (contrôle de la qualité après compression, par exemple).
L’archivage web : par exemple, la Bibliothèque Autrichienne crawle tous les domaines en .au, à des fins de statistiques sur les sites présents, la répartition des formats de fichier, … Ces statistiques, intéressantes en elles-mêmes, peuvent servir à construire des stratégies de préservation du contenu car ces formats de fichiers peuvent dans le futur devenir obsolètes. Concrètement, avec Hadoop, ce scénario conduit à développer des RecordReader/Writer adaptés au standard d’archivage (WARC).
La détection d’erreurs de cadrage : lors de la numérisation d’un ouvrage, les marges sont détectées pour cadrer l’image résultante. Il arrive que ce processus fasse des erreurs et coupe le texte ; une comparaison entre la taille de l’image et celle déduite de la structure du document en paragraphes, permet de repérer de telles erreurs.
Les sciences humaines : ce scénario est plus ambitieux (et à ma connaissance non implémenté). Il vise, avec des outils de traitement du langage naturel, à analyser les textes publiés, sous l’angle de l’analyse de sentiments, de la sémantique, etc. On peut ainsi mesurer l’évolution d’opinion d’un journal au cours du temps, par exemple.
Les implémentations sont en MapReduce et en Hive. Des expérimentations ont lieu autour de Pig, de MongoDB, et Mahout est également à l’étude...
Quelques liens :
- le projet européen de numérisation Enumerate
- le projet Scape, une plateforme open-source scalable dédiée à la préservation du patrimoine culturel. Pour les courageux, un hackaton sera prévu à Vienne en décembre
- Scape est porté par la fondation Open Planets dont le github est accessible en ligne
Les applications analytiques chez Ebay
Une session décevante... car très peu détaillée au final, et qui n’apprenait pas tant de choses que ça. De la part d’un acteur comme Ebay, pionnier dans l’utilisation de Hadoop, c’est dommage !
Aujourd’hui, les clusters Hadoop d’Ebay font de l’ordre de 4.000 noeuds, pour 40.000 cores, en progression exponentielle depuis 2007.
Quelques chiffres sur les données :
- 102 millions d’utilisateurs (vendeurs et acheteurs)
- 350 millions d’articles
- 3 milliards de pages vues par jour
- 300 millions de requêtes par jour (le rapport entre les deux derniers chiffres est étonnant d’ailleurs !)
Le tout est amené à augmenter, avec une perspective de convergence des commerces traditionnel et électronique. Ce marché unique “cible” avait été estimé il y a quelques années ; le chiffre prédit pour 2013 était de 10 T$.
Au total, toutes les données d’Ebay sont capturées : comportementales (clics, historiques, …), transactionnelles, d’inventaire. Elles sont référencées dans un métastore et mises à disposition sous plusieurs formats, pour être requêtées par Java, Scala, Pig, Mobius, Hive, Cascading, R, dans des scénarios divers : rétention de clients, calcul de revenu, web analytics, etc. Les résultats agrégés peuvent être envoyés vers des bases MySQL. L’offre sera bientôt complétée par des outils de requêtage interactifs et l’ingestion de données temps réel (streaming).
En ce qui concerne la construction des applications elles-mêmes, outre qu’elles tapent dans Hadoop, on apprend qu’elles sont construites de manière itérative, en exploitant les données de recommandation (“personalization”) calculées par des outils statistiques.
Les sessions méthodologiques et techniques
Big Data sampling
Une session intéressante sur les limites et les pièges de l’échantillonnage dans un contexte Big Data. Il ne faudra pas manquer les supports de la présentation, quand ils seront disponibles, car ils illustrent bien les problématiques et sont très concrets.
L’échantillonnage a des avantages économiques (en puissance de traitement nécessaire) et en gain de temps, et il est parfois nécessaire car les outils “legacy” ne savent pas appréhender les gros datasets modernes. La technique est pourtant peu employée : par commodité (c’est un travail de plus), et par crainte de perdre de la précision. Ce dernier argument est parfois illusoire : les méthodes de prédiction classiques, peut-on observer, sont faites avec des erreurs qui sont, après confrontation, largement au-delà de la perte de précision due au sampling. Les chiffres donnés à titre d’illustration : prédictions de profits en écart de ± 30%, rentabilité d’actions ± 40%, sales forecast ± 15-20%. Avec ces ordres de grandeur, inutile de faire la fine bouche...
Une équation économique plus précise peut être établie en calculant la perte de profit découlant de la perte de précision, et le coût d’infrastructure de la puissance de calcul nécessaire. Les deux courbes se croisent en un point qui donne la taille de l’échantillon optimale : 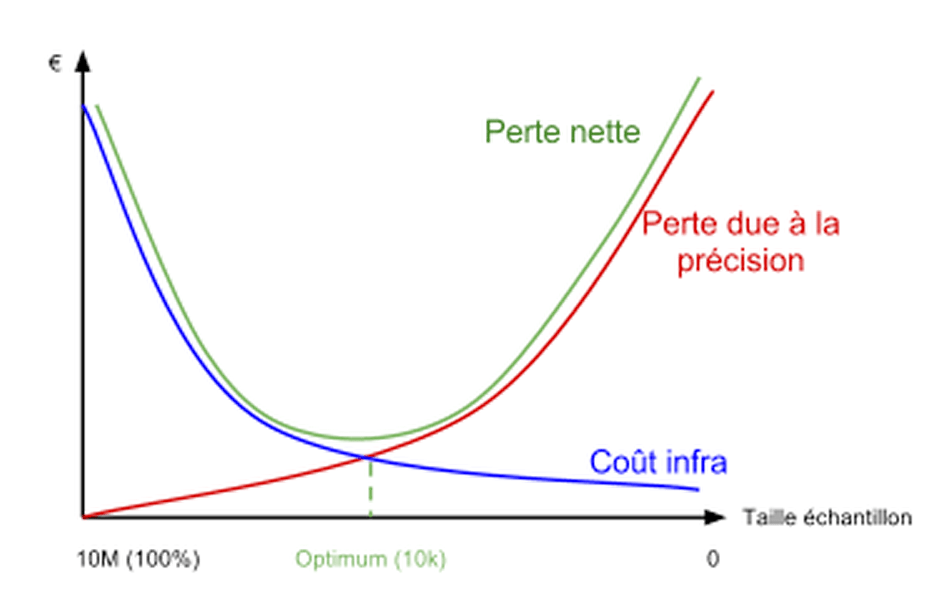
Empiriquement, le présentateur constate que le chiffre de 10.000, comme taille d’échantillon, revient souvent (Big Data ? voire !)
Un peu de bon sens dicte les situations où l’échantillonnage n’est pas adapté : en collecte (il vaut mieux tout collecter et échantillonner ensuite), pour le reporting qui doit être exact, et pour les petits jeux de données.
Comment échantillonner ? Un bon algorithme doit être uniforme, non biaisé, cohérent, et proposer l’option d’être répétable (i.e. de donner 2 fois les mêmes échantillons). Quelques exemples de méthodes : modulo ou hashing sur des ID uniques, choix d’un tous les N enregistrements, données d’un sur N serveurs. Attention quand même aux biais cachés d’implémentation (génération d’ID) ou de saisonnalité (pour la répétabilité).
En fonction du domaine, on peut aussi être amené à affecter des poids à certaines catégories d’enregistrements, voire mettre en place des règles spécifiques. Par exemple, inclure obligatoirement les clients VIP, avec un poids supérieur. Il faut juste faire attention à ne pas faire remonter des enregistrements par plusieurs “canaux” par erreur, et rectifier les statistiques finales en tenant compte des poids introduits au début...
Les outils de l’écosystème Hadoop ont aussi été abordés. Avec Hive, l’utilisation des buckets peut s’avérer judicieuse si on est conscient des pièges : les types INT et BIGINT ne sont pas hashés de la même manière, et les chaînes de caractère utilisent un algorithme de hashage opaque et qui peut changer avec les versions de Hive. L’auteur recommande de rester prudent et de se cantonner aux INTs.
L’identification des catégories et le “routage” des enregistrements en fonction de celles-ci peuvent être faits en MapReduce ou en Pig, avec l’opérateur SPLIT. Hive, en revanche, n’est pas très efficace dans ce contexte, car il à chaque noeud de son DAG il relit tout le jeu de données, sans tenir compte de l’éclatement.
Finissons par la morale de la présentation : “Collect more, analyze less”. De fait, les ordres de grandeur de volumétrie obtenus après échantillonnage ne sont pas rédhibitoires : ~ 10.000 points. Hadoop et les outils d’analyse plus traditionnels (R, SAS), sont donc bien complémentaires.
Des transactions sur HBase avec Omid
Omid est un framework développé (et présenté) par Yahoo!, dotant HBase de fonctions de gestion de transactions. Le but est à terme d’en faire un framework plus large d’”incremental processing” (par opposition au traitement de masse style MapReduce), sur le modèle de Google Percolator ; la gestion des transactions est la première étape car c’en est une brique de base.
Omid (“espoir” en farsi) fonctionne sur le principe du verrouillage optimiste -- contrairement d’ailleurs à Percolator. Il stocke sur un serveur (le Status Oracle) des métadonnées de transaction : timestamps de début et de fin de transaction, ID de snapshot par ligne, dernier timestamp (pour la purge des vieilles transactions). Par “snapshots”, il faut entendre des ensembles de lignes en isolation pendant l’exécution d’une transaction, le I de ACID. Le Status Oracle est extérieur au cluster HBase ; dans ce dernier, les lignes sont versionnés avec les mêmes IDs de snapshot, ce qui permet à chaque transaction de ne voir que son snapshot de données, indépendamment des autres transactions en concurrence.
En termes d’architecture, des clients Omid “cachent” une partie des métadonnées du Status Oracle. La seule partie vraiment volumineuse des métadonnées, les ID de snapshot par ligne, n’est pas concernée car elle ne sert qu’en cas de résolution de conflits : rarement. Le volume de réplication est faible, ce qui permet au nombre de clients Omid de scaler sans trop de contraintes (testé jusqu’à 1.000).
L’API, elle, se résume à quelques points d’entrée : begin(), commit() et rollback() pour les transactions, et des surcharges des opérations de TTable prenant un objet transaction en paramètre. Puisque Omid fonctionne en concurrence optimiste, les conflits sont détectés au commit, en vérifiant si des intervalles temporels de transactions se recouvrent sur des lignes communes. Auquel cas, le client annule la transaction et fait le ménage dans les métadonnées. C’est le seul vrai overhead par rapport à l’utilisation nominale d’HBase, ce qui fait d’Omid un système peu impactant pour les performances (tant que les conflits restent rares !).
En termes de haute disponibilité, le Status Oracle peut être configuré en maître/esclave, avec Apache Bookkeeper entre les deux pour la réplication de logs. Le temps de récupération (dernières transactions) reste en pratique inférieur à 1 min.
La présentation donnait des exemples de use cases, qui permettent de comprendre l’intérêt de l’isolation dans ce contexte. D’abord, sur un système de recommandation basé sur du clustering -- des requêtes peuvent être faites pendant que les opérations de calcul modifient les clusters, sans pour autant que la requête ne trouve des clusters “orphelins” car interrogés au mauvais moment. Un autre use case, celui de Google, est l’indexation en tâche de fond. Enfin, le système pourrait être utilisé pour faire du traitement de graphes avec modifications concurrentes de la topologie.
La roadmap est également bien chargée :
- distribution de charge transparente entre les clients et le Status Oracle (mais en pratique, aucun goulet n’a été identifié à ce jour)
- retry en cas de conflit (plus probables sur les grosses transactions)
- API de plus haut niveau et notamment pour l’incremental processing (à base de triggers)
- debugging, métriques
- hot failover
- et si pertinent, affinage de la granularité des transactions (aujourd’hui au niveau ligne)
Le code du projet est accessible sur github.
Willy, une appliance Hadoop
Cette session était la première annonce officielle d’une nouvelle appliance basée sur Hadoop : Willy.
Le constructeur, Merou Inc., est parti du constat que sur les workloads critiques, le réseau était un goulet d’étranglement des distributions Hadoop classiques. La réponse est une nouvelle architecture, où tous les noeuds de calcul sont rassemblés sur un même serveur, évitant de fait le goulet. Le système d’exploitation de la machine, baptisé H/OS, se charge alors d’exécuter le traitement en le distribuant sur les coeurs de calcul internes.
En termes de développement, l’éditeur supporte un langage de haut niveau destiné aux métiers et au marketing, le CODBOL (COmmon Distributed Business Oriented Language). Le langage propose une connection native avec HDFS et avec HB2, version modifiée de HBase embarquée. Les traitements MapReduce classiques sont aussi supportés, via le moniteur d’exécution PISC, une version mono-serveur de YARN.
L’appliance Willy, de la taille d’un réfrigérateur (américain), sera disponible courant 2013, avec une politique de facturation basée sur le nombre de tâches Map exécutées (Maps Instantiations Per Slot).
Avec Willy, attendons-nous donc à de grands changements dans le monde de l’IT !
Conclusion
Personnellement, je retiens une double impression de ces deux jours de séminaire. Tout d’abord, les organisations qui adoptent Hadoop aujourd’hui suivent peu ou prou la même stratégie en 3 temps présentée en introduction. C’est une stratégie prudente, qui permet aux équipes de s’approprier la “bête”, avant de lui faire une place à part entière puis enfin d’en faire le support de nouveaux produits par l’innovation. C’est aussi ce que nous observons chez nos propres clients.
Deuxième constat, Darwin n’est pas encore passé sur les distributions et n’est pas prêt de venir :-) Raison pour laquelle on assiste à une course à l’armement, pour proposer du requêtage à faible latence (Impala, Stinger, Hawq), et bientôt sans doute de l’ingestion temps réel (par exemple avec l’intégration prochaine entre Mahout et Storm).