Hadoop Distributed File System : Overview & Configuration
Hadoop Distributed File System can be considered as a standard file system butt it is distributed. So from the client point of view, he sees a standard file system (the one he can have on your laptop) but behind this, the file system actually runs on several machines. Thus, HDFS implements fail-over using data replication and has been designed to manipulate, store large data sets (in large file) in a write-one-read-many access model for files.
Overview
HDFS is made of several Java process running on separate (even if this is not necessary) physical machines and follow a Master/Slave model : 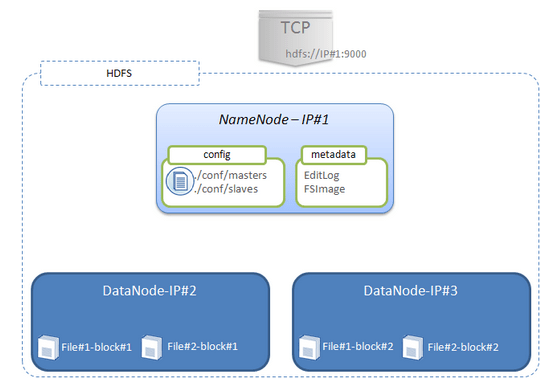
- NameNode. The NameNode is responsible for storing the files’ metadatas (the locations of the files...) and for tracing all the operations realised on the file system. All these datas are stored on the local file system of the NameNode in two files called “Edit Log” and “FSImage” : - Edit Log. Stores all changes that occur into the file system metadatas. For instance, adding a new file in HDFS is traced in this file. - FSImage. Stores all the file system namespace : the location of files (or blocks) in the cluster - DataNodes. The DataNodes simply store the datas, ie. the files’ blocks without any knowledge of HDFS. The files’ blocks are stored on the local file system of the DataNodes and are replicated among the other datanodes based on the configured replication factor.
Commands on the file system
HDFS thus provides a lot of commands to import, copy, delete or whatever you wanna do with your files...The exhaustive list of commands is available here and you can interact using either a shell or the Java API
For instance, if you want to delete the folder /chukwa/logs and all its subfolders, you can type (on the client machine which must have Hadoop shells installed) :
$HADOOP_HOME/bin/hadoop fs -rm /chukwa/logs/*.*
To create a folder, you can use mkdir (almost as usual) :
$HADOOP_HOME/bin/hadoop fs -mkdir /tmp/myfolder
To copy a file from your local directory to the /data directory :
./bin/hadoop fs -put /home/user/cash-flow/cashflow-clean.txt /data
HDFS also provides a console (http://localhost:50070/dfshealth.jsp) which in turn provides a HDFS couple of metrics
Handling failures
In HDFS, the files are truncated into several blocks (the block size can be configured) and these blocks are replicated (based on the configuration) around several replicas, on different DataNodes.
Moreover, each DataNodes broadcast its health to the NameNode using a heartbeat mechanism. If the NameNode does not detect the heartbeat, the node is therefore considered dead. The datas are automatically replicated to other available DataNodes to respect the configured replication factor. Moreover it seems that you can dynamically add a new DataNode to the cluster without restarting it. New files will be stored on the added DataNode but you may have to manually rebalance the HDFS blocks into the cluster.
This is the simplest part of the deal as I am more than doubtful concerning NameNode failures. If metadatas are corrupted, HDFS could be non-functional...It seems there are two ways of managing this (I may have to digg further with these “fail-over” mechanisms in the future). In the first one, the NameNode can be configured (via the property dfs.name.dir in hdfs-file.xml configuration file) to maintain multiple copies of the FSImage and EditLog (on different devices). The replicas are synchronously done and so decreasing the throughput. In the second one, a SecondaryNameNode can be defined (in the masters configuration file) and in that case : The SecondaryNameNode periodically compacts the EditLog into a “checkpoint;” the EditLog is then cleared. A restart of the NameNode then involves loading the most recent checkpoint and a shorter EditLog containing only events since the checkpoint. Without this compaction process, restarting the NameNode can take a very long time...The duties of the SecondaryNameNode end there; it cannot take over the job of serving interactive requests from the NameNode. Although, in the event of the loss of the primary NameNode, an instance of the NameNode daemon could be manually started on a copy of the NameNode metadata retrieved from the SecondaryNameNode.
Installing & Configuring a HDFS cluster
The official documentation is quite complete for version 0.20.2 and 0.21.0. Once HDFS (and in fact Hadoop) has been installed you need to specify the constant HADOOP_HOME (at least for the version 0.21.0) and the cluster configuration. In our case, we will use 3 machines : 1 master (aka. the NameNode) and 2 slaves (aka the DataNodes).
Master Configuration
You will have to define which machine is the master, which ones are the slaves and the ssh connexions between them (aka. NameNode and the slaves aka. DataNodes) - copy the phraseless key (for instance id_ras.pub) on the remote slaves ssh-copy-id -i /home/user/.ssh/id_dsa user@master-ip - In $HADOOP_HOME/conf/masters file, write the master IP - In $HADOOP_HOME/conf/slaves, add the two slaves IP These two configuration files are used by the start-dfs.sh shell to remotely start the DataNodes.
Slaves Configuration
There are no particular configuration needed except the slaves must have the Hadoop distribution installed and must follow the same folders arborescence.
GlobalConfiguration
On all machines, you will have to modify the ./conf/*-sites.xml files to specify : - core-site.xml. Specifiy the hdfs url (by replacing ip-master with the real master IP)
<property>
<name>fs.default.name</name>
<value>hdfs://ip-master:9000</value>
</property>
If you do not specify this, you will get the following error :
20:13:18,026 INFO org.apache.hadoop.security.Groups: Group mapping
impl=org.apache.hadoop.security.ShellBasedUnixGroupsMapping; cacheTimeout=300000
2010-09-12 20:13:18,058 ERROR org.apache.hadoop.hdfs.server.namenode.NameNode:
java.lang.IllegalArgumentException: Invalid URI for NameNode addrgeess (check fs.defaultFS): file:/// has no
authority.
- hdfs-site.xml. Specify the replication factor.
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
you specify the number of replicas (cannot be greater than the DataNodes number)
HDFS launching...
Launching HDFS is quite simple. Type the following command from the master :
$HADOOP_HOME/bin/start-dfs.sh
The DataNodes will be remotely (using ssh) started from the NameNode. If this is the first usage of HDFS, you will need to format the file system using the command line :
$HADOOP_HOME/bin/hadoop namenode -format
To conclude
Here is an overview and a short introduction of how to setup a HDFS mini cluster.Yet, I still have a couple of questions to look into. The first one is about the NameNode fail-over mechanisms in terms of service interruption as well as data corruption. The second one concerns the HDFS (and Hadoop) infrastructure upgrade with (or without) service interruption. Last but not least, there are also concerns about how to process this data. Storing vast amount of data is a first step, the next one will be to see how to “crunch” all these datas using Hadoop.