La Grosse Conf 2025 - IA et mésinformation – Eric Biernat
Éric Biernat, Partner et co-leader de l'entité Data & AI chez OCTO Technology, a récemment eu — selon ses propres mots — « la chance » de participer à un groupe de travail au sein de l'Académie des technologies, une institution placée sous la tutelle du ministère de la Recherche.

L’objectif de cette académie est d’éclairer la société sur l’usage responsable des technologies émergentes, notamment à travers Internet et l’intelligence artificielle (IA).
Pendant 18 mois, le groupe de travail « IA générative et mésinformation » s’est réuni chaque mois pour étudier les transformations profondes qu’apporte l’intelligence artificielle générative sur notre rapport à l’information. Autour de la table, une quinzaine de participants issus de disciplines variées : mathématiciens, sociologues, juristes, politiques… Tous ont contribué à une réflexion collective dont les conclusions sont aujourd’hui disponibles dans un rapport public.
Lors de la Grosse Conf’, Éric a partagé les grandes lignes de cette contribution, en se concentrant sur deux axes majeurs du rapport :
- Quelles sont les pathologies de l'information, quelle en est l'origine et quels en sont les mécanismes à l'œuvre, bien avant l'apparition de l'IA générative ?
- Que font précisément les outils d'IA générative ? Leur construction même les prédisposent-ils à devenir des vecteurs d'information fausse ou toxique ?
I. Pathologies de l’information : bien avant l’IA générative
Le rapport débute par un retour historique évocateur : le 30 octobre 1938, Orson Welles, alors âgé de 23 ans, lit à la radio des extraits de La Guerre des mondes de H.G. Wells, sous forme de faux bulletins d’information. Le lendemain, la presse dénonce une prétendue vague de panique à travers les États-Unis, où certains auraient cru à une invasion extraterrestre. Manipulation médiatique ou exagération journalistique ? Peu importe : les pathologies de l’information ne datent pas d’hier.
Mais à l’époque, l’homo digitalis n’existait pas encore. Il convient d’observer sa mutation depuis l’Homo sapiens qui n’a pas eu que des effets sociétaux bénéfiques.

Avec la généralisation d’Internet et des smartphones, la mutation sociétale s’accélère. Éric pointe trois maux contemporains liés à notre rapport à l’information :
- L’infobésité, cette surcharge informationnelle engendrée par les chaînes en continu, les réseaux sociaux et les sollicitations permanentes du numérique.
- La nomophobie, soit la peur irrationnelle d’être séparé de son téléphone. Comme le décrit Éric avec humour : « Quand vous oubliez votre enfant sur l’autoroute des vacances, vous hésitez à faire demi-tour. Quand vous oubliez votre téléphone, vous faites demi-tour immédiatement. »
- La mésinformation, c’est-à-dire la diffusion involontaire de contenus erronés, sans intention de nuire.
En ce sens, l’IA générative n’invente rien. Les dérives que l’on observe aujourd’hui existaient déjà avec Internet. La prise de conscience s’est faite tardivement, parfois trop, face à une promesse de transparence et de savoir partagé qui ne s’est que partiellement concrétisée.
Retour en 1996 : John Perry Barlow, cofondateur de l’Electronic Frontier Foundation, publie la Déclaration d’indépendance du cyberespace. Il y imagine un espace libéré des contraintes politiques et économiques, fondé sur le dialogue, la diversité et la sagesse collective. Ce principe, popularisé par James Surowiecki en 2004 sous le nom de « sagesse des foules », repose sur trois conditions : la diversité des points de vue, l’indépendance des opinions individuelles, la décentralisation des décisions.
De nombreuses expériences en attestent : la foule estimant collectivement le poids d’un bœuf lors d’une foire (Francis Galton), le public plus fiable que les experts dans Qui veut gagner des millions ?, ou encore les concours sur Kaggle, où les meilleures performances émergent souvent de l’agrégation d’approches variées.
Mais pourquoi cette sagesse collective fonctionne-t-elle si mal sur Internet ?
Le rapport identifie trois explications majeures :
Premièrement, l’économie de l’attention prime sur la vérité. Sur les plateformes, ce n’est pas le contenu véridique qui est mis en avant, mais celui qui capte l’attention. Comme le rappelle la théorie de Claude Shannon, plus un message est improbable, plus il a de "valeur informationnelle".
Exemple parlant :
- la phrase « Ce matin, un chien a mordu Donald Trump » suscite peu d’intérêt.
- la phrase « Ce matin, Donald Trump a mordu un chien » attire toute l’attention.
Deuxièmement, la vérité et le mensonge ne luttent pas à armes égales. En ligne, tout le monde peut publier. Et une fausse information peut être produite à moindre coût, alors que la réfuter demande temps et expertise. En 2013, un informaticien, Brandolini, image cela avec une théorie : "le bullshit assymetry principle" :
"La quantité d'énergie nécessaire pour réfuter des sottises est d'un ordre de grandeur supérieur à celle nécessaire pour les produire."
Heureusement, en science et en droit notamment, la charge de la preuve revient toujours à celui qui affirme.
Enfin, les algorithmes de recommandation nourrissent l’ère de l’opinion. Sur les réseaux, les utilisateurs sont enfermés dans des bulles cognitives, lisant surtout ce qu’ils souhaitent entendre. La vérité n’est plus une référence, mais devient optionnelle. On peut même se sentir à l’aise dans l’erreur.
C’est en grande partie cet internet-là qui a servi de base d’apprentissage à l’IA moderne.
II. Les LLM (Large Language Model) sont-ils structurellement porteurs de mésinformation ?
Dans une deuxième partie de son intervention, Éric Biernat s’attarde sur le fonctionnement même des modèles de langage, ou LLM (Large Language Models), et leur relation intrinsèque à la désinformation. L’IA générative n’est pas seulement un nouveau canal de diffusion d’erreurs ou de biais : elle est potentiellement un vecteur structurel de mésinformation, du fait même de sa conception.
Revenons à la base.
Éric revient sur Alan Turing, grand-père fondateur de l’IA et nous questionne : "la conversation humaine (fruit d'Internet) est-elle le bon étalon de la vérité ?"
En effet, le test de Turing fut pendant 70 ans la métrique des laboratoires pour déterminer si un ordinateur, à travers ses capacités conversationnelles, est capable d'imiter, ou non, la capacité de raisonnement d'un être humain.
Aujourd’hui, les LLM comme les GPT-x sont construits autour d’un objectif beaucoup plus modeste en apparence : prédire le mot suivant dans une séquence. À partir d’une quantité massive de textes — souvent issus d’Internet —, ces modèles sont entraînés à estimer la probabilité qu’un mot apparaisse dans un certain contexte. Autrement dit, plus une idée ou une tournure est fréquente dans les données d’entraînement, plus elle est apprise.
C’est là que réside une première source de mésinformation. Si une idée est largement répandue, mais fausse, elle aura de bonnes chances d’être reproduite par le modèle. Comme le souligne Éric :
« Un LLM formé au temps de Galilée aurait soutenu que le Soleil tourne autour de la Terre. »
Une autre limite réside dans la manière dont les LLM produisent leurs réponses, mot après mot. Chaque mot généré devient la base du mot suivant. Cela introduit un phénomène de dérive progressive : si un mot est mal estimé au début, l’erreur peut se propager, entraînant une incohérence logique ou factuelle sur l’ensemble de la réponse.
De plus, les LLM n’ont pas de mémoire structurée de ce qu’ils disent. À la différence d’un humain qui peut se corriger en cours de conversation, ils ne vérifient pas la cohérence globale du discours : ils improvisent, mot après mot. D'où l’apparition fréquente d’hallucinations — des affirmations factuellement erronées, mais formulées avec aplomb. Des avancées sont toutefois à noter récemment sur ce point.
Pour améliorer la qualité et la pertinence des réponses, les modèles sont ensuite soumis à des phases de fine-tuning et l’alignement. Ces étapes consistent à ajuster le comportement du modèle pour qu’il adopte des postures jugées « responsables », « utiles » ou « sûres » selon des critères humains. Cela inclut, par exemple, l’interdiction de contenus haineux, ou la correction de biais trop flagrants.
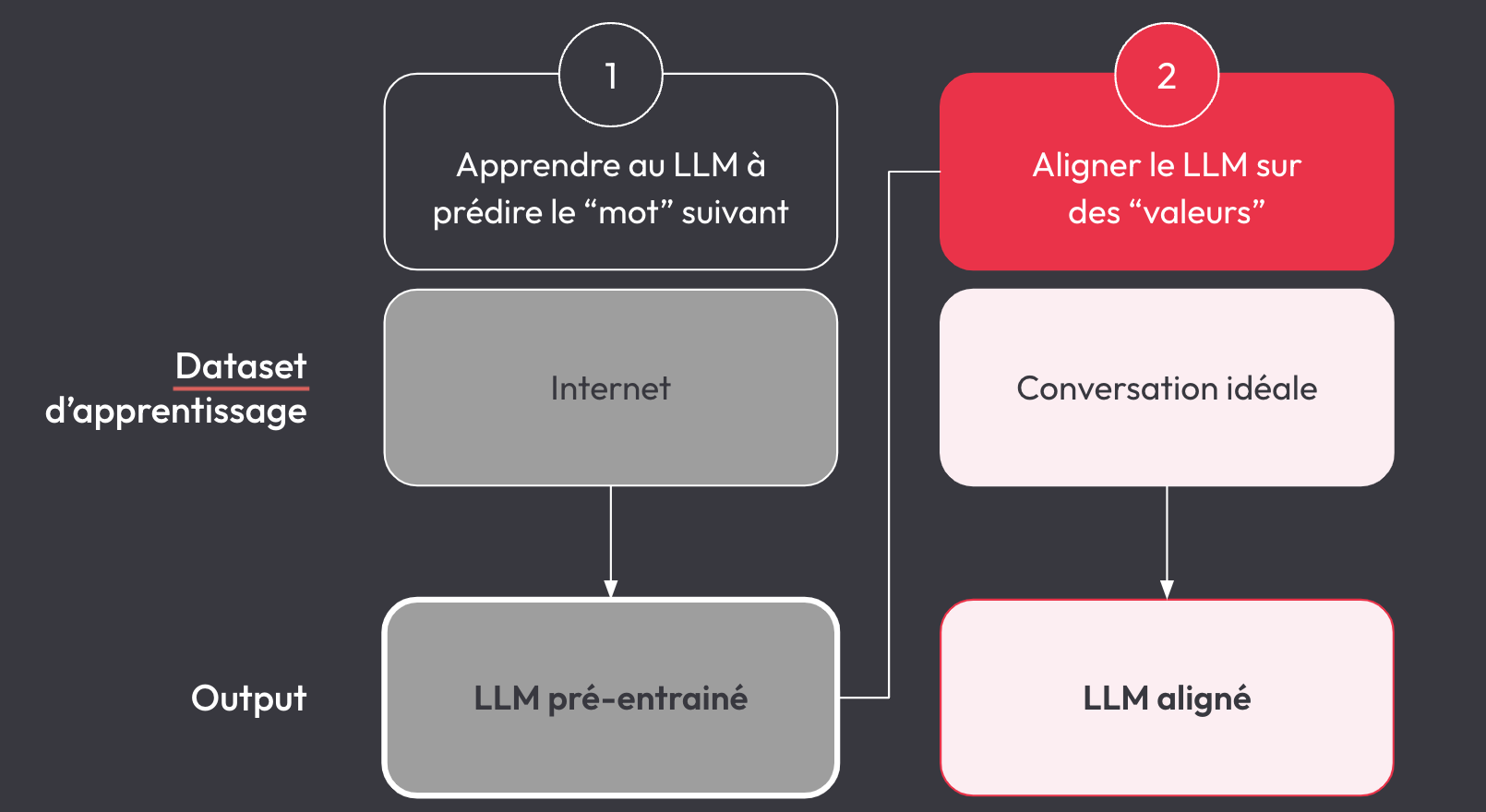
Mais ces ajustements reflètent les valeurs et les normes culturelles des équipes qui les conçoivent — souvent celles de la Silicon Valley. Cela pose une question essentielle : Qui décide de ce que le modèle doit penser ?
Aujourd’hui, on entend parfois : « C’est vrai, ChatGPT me l’a dit. »
De la même manière qu’on disait il y a 20 ans : « Je l’ai vu sur Internet. »
Le rapport de l'Académie des Technologies propose dans ses chapitres certaines recommandations quant à ces problématiques.
Un autre facteur de mésinformation potentiel existe : la compression induite par un LLM. En effet, les LLMs peuvent être vus comme des mécanismes de compression massive de l’Internet. Par exemple, pour le modèle Llama de Meta : 15 milliards de tokens entraînent 70 milliards de poids — soit un taux de compression de 99,5 %. Comme toute compression, cela implique des pertes de détails : des simplifications ou des représentations incorrectes du contenu original.
L’un des enjeux fondamentaux tient aux embeddings, ces représentations numériques des mots. Pour représenter le monde dans un espace mathématique, les IA doivent choisir des axes de représentation. Mais qui les choisit ? Et que laissent-ils de côté ?
Contrairement à l’humain, dont le cerveau adapte ses schémas en fonction de son vécu, les modèles IA imposent des axes universels, non choisis par l’utilisateur et peuvent homogénéiser nos façons de penser. Cette compression du monde et de ses subtilités force le modèle à se concentrer sur les aspects les plus courants et représentatifs du monde, laissant moins de poids aux détails et aux nuances, conférant pourtant toute sa beauté à l'intelligence humaine.
Il faut certes se rappeler que toute forme d’intelligence repose sur de la compression. Le cerveau est capable de “processer” et de compresser une énorme quantité d’information à l’aide d’heuristiques mentales et patterns pour en extraire des structures sous-jacentes. Le cerveau, by design compresse. La différence fondamentale est que la compression faite par notre cerveau nous est propre. Il y a autant de manières de compresser l’information que d’humain dans le monde. C’est une force de résilience cognitive de l’espèce humaine qu’on ne retrouve pas dans un LLM qui choisit une bonne fois pour toutes l’espace de représentation des mots, des concepts, des connaissances.
Eric évoque enfin la complexité des LLM et le manque d’explicativité des modèles d’IA en rappelant qu’à une époque, tout le monde avait une connaissance basique des technologies, en tout cas suffisante pour réparer ce qui devait l’être. Aujourd’hui, quel pourcentage de la population est capable de comprendre un système technologique avec lequel on interagit tous les jours (voiture, aspirateurs, téléphone, application informatique) au point de pouvoir le réparer ? Ce glissement inexorable vers la perte de compréhension des technologies peut être compensé par la confiance dans le tiers qui nous fournit produit et service (l’écosystème Apple par exemple).
Pour conclure avec une analogie éclairante, Éric compare l’IA générative à l’électricité : Personne n’a peur de l’électricité aujourd’hui, bien qu’elle cause chaque année des accidents.
Pourquoi ? Parce qu’on l’enseigne tôt, qu’on la régule, qu’on l’encadre. Il faudra faire la même chose avec l’IA.
Ses derniers mots présentent la conclusion du rapport :
« Les générations à venir devront savoir donner un sens à l'innovation, pas seulement une direction. Elles devront conjuguer le principe d'audace, moteur indispensable de l'innovation, et le principe de précaution, garant de la pérennité. La belle devise de l'académie leur balise le sentier, pour un progrès raisonné, choisi et partagé. »
Le rapport peut être apprécié dans son intégralité via ce lien de téléchargement.