GraphQL: Et pour quoi faire ?
D’après l’étude de l'écosystème Github, GraphQL est l’une des tendances à suivre de 2018. Tendance confirmée par la parution, en juin 2018, de la dernière version de la spécification de GraphQL. Lee Byron (co-créateur de GraphQL) définit cette nouvelle version comme “the first edition to no longer be considered a "Draft RFC" to reflect its extensive use in production”. Vous n’avez pas eu le temps de vous y intéresser ? Alors je vous propose un résumé des avantages et inconvénients de cette technologie.
Le but de l’article n’étant pas de réexpliquer tous les principes de GraphQL et comment l’implémenter, je vous conseille l’introduction de Sacha Greif, So what’s this GraphQL thing I keep hearing about? ou en français l’article plus encyclopédique d’Aurélien Castel. Néanmoins j’aimerais revenir sur quelques idées reçues.
Qu’est ce que GraphQL ?
Selon la définition officielle, GraphQL est un langage de requêtes pour API ainsi qu’un environnement pour exécuter ces requêtes. Il est défini par une spécification indépendante des langages de programmation et des protocoles de transport, dans le but de s’inscrire comme un nouveau standard dans le développement d’API. Cela vous paraît un peu abstrait ? Schématisons tout cela !
Uniquement la couche de routage de l’API
La place de GraphQL dans l’architecture de notre application est une des premières sources d’incompréhension. Souvent lorsque l’on aborde le sujet on a du mal à imaginer où cela se situe.
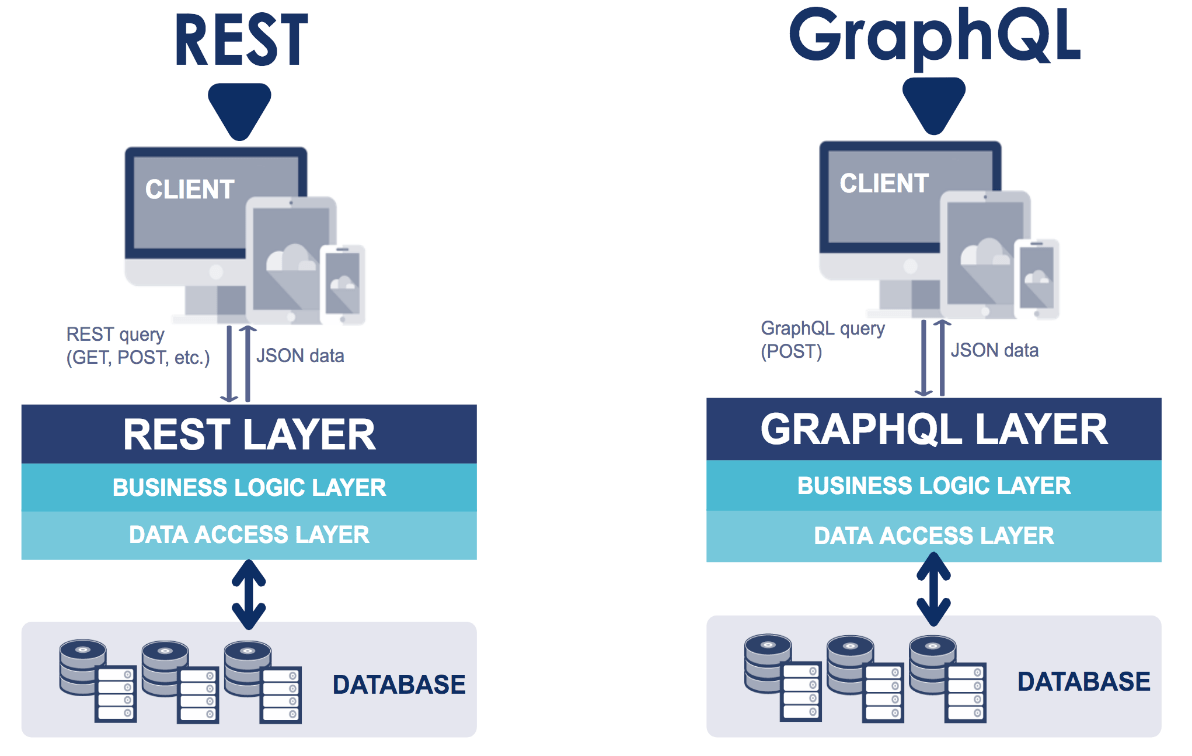
Comparaison architecturale d’une API REST et d’une API GraphQL
Dans les schémas ci-dessus, on voit que les architectures des deux APIs sont identiques excepté la couche de routage. Pour rappel le rôle de cette couche dans une API REST (par exemple) est d’appeler les fonctions du métier en fonction du verbe HTTP, de l’url et possiblement des paramètres envoyés. GraphQL agit de même en appelant le métier en fonction de la requête (GraphQL query) envoyée.
L’environnement d’exécution de GraphQL n’est donc qu’une couche de routage de l’API, qui interprète des requêtes GraphQL, reçues via le payload d’un POST.
Langage de requêtes
GraphQL est en premier lieu un langage de requête. Celles-ci ressemblent comme on peut le voir dans l’exemple ci-dessous à la réponse que l’on souhaite obtenir sans les valeurs. Le client choisit alors quels champs de chaque Objet (ex: orders) il souhaite et dans quel ordre. La réponse du serveur GraphQL sera alors identique à l’ordre dans lequel a été formulé la requête.
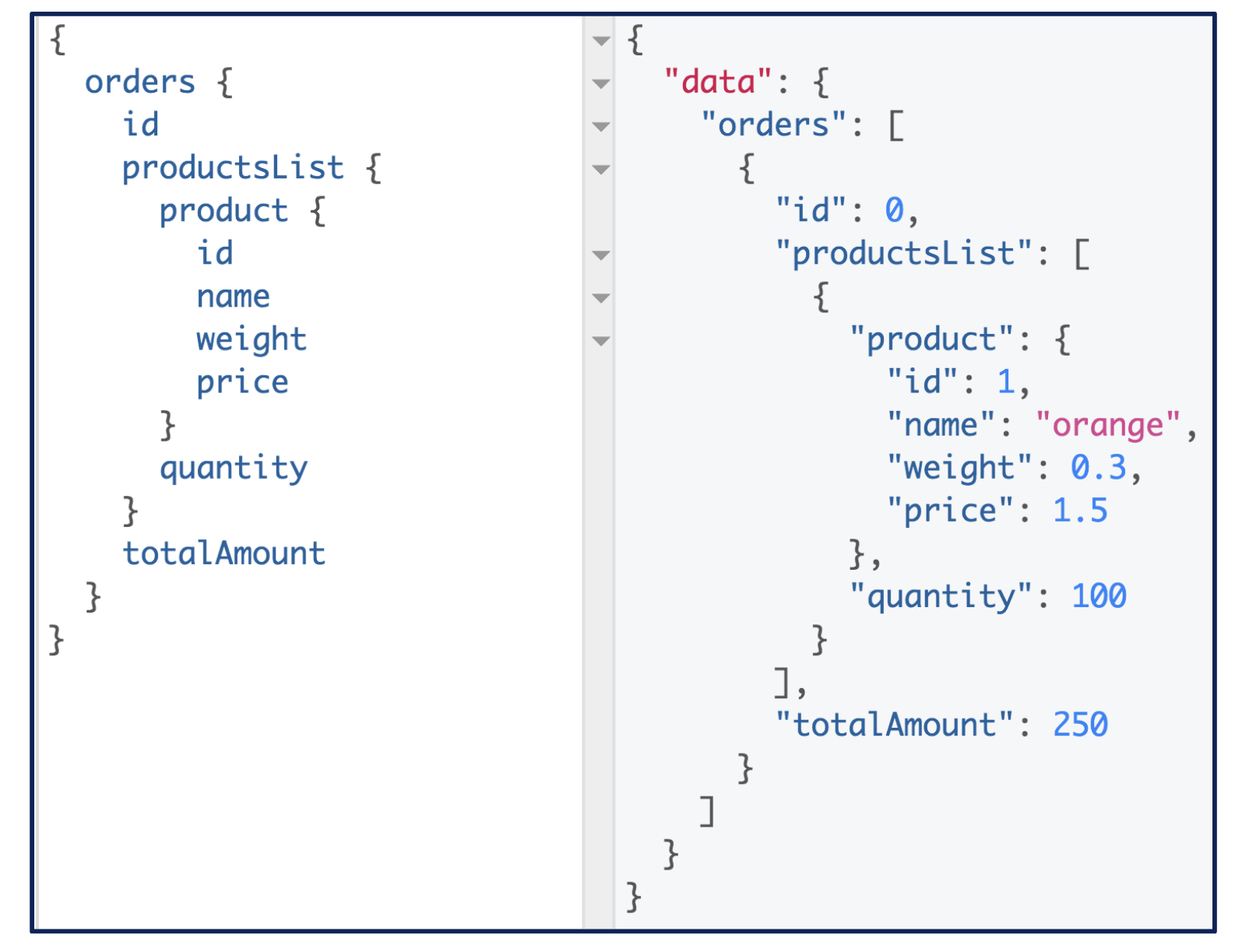
Exemple de requête GraphQL (à gauche) et sa réponse (à droite)
Le schéma : Squelette de l’API
Dans un second temps, GraphQL est un environnement d’exécution qui interpréte et structure ces requêtes à partir du schéma. En effet, après avoir vérifié que la requête correspond bien à la syntaxe du langage, le serveur GraphQL vérifie que la requête est bien disponible dans Query (défini ci-dessous) et que les champs demandés correspondent bien au retour de la requête en question.
Le schéma est donc un élément central dans la conception d’une API GraphQL. On y définit tous les objets GraphQL, leurs types (string, int, objet précédemment défini… ou encore un tableau des éléments précédents). On y définit aussi toutes les requêtes disponibles dans l’objet global Query, toutes les actions disponibles dans l’objet global Mutation et leurs éventuelles entrées. Enfin il est directement possible de spécifier des règles métier comme par exemple l’ajout d’un point d’exclamation si un champ est obligatoire.
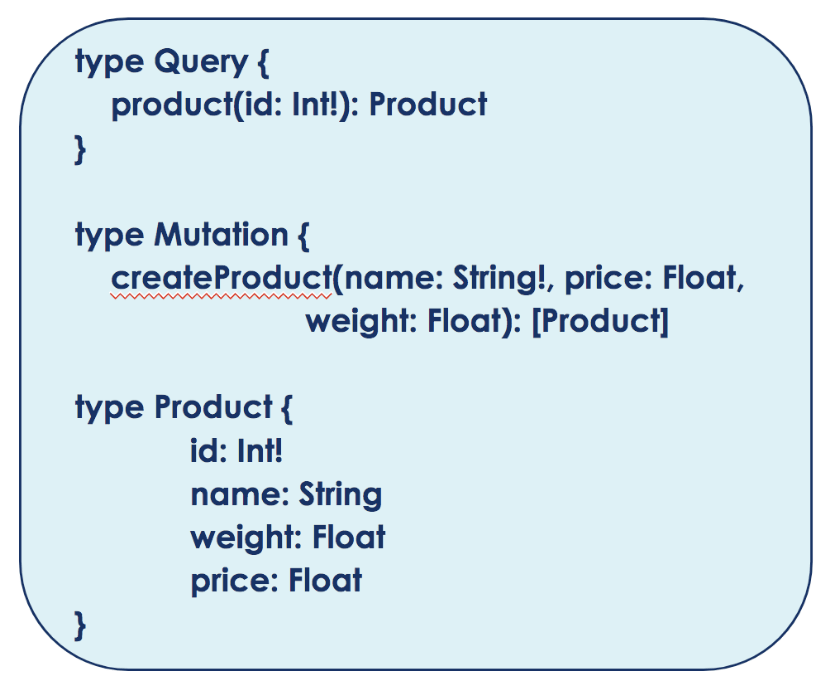
Exemple de schéma GraphQL
Illustrons ces notions avec l’exemple ci-dessus. Ici seule la requête product est proposée aux utilisateurs sous réserve qu’il précise l’id du produit dont il souhaite obtenir les informations. Le retour de la requête n’est constitué que d’un seul Product mais si on avait voulu une réponse avec tous les produits il aurait fallu ajouter des crochets autour de l’objet (ex [Product], tableau de produits_)._
Les resolvers : Liaison avec le métier
Une fois la requête vérifiée de part sa syntaxe et le schéma du serveur, GraphQL fait appel aux resolvers. Un resolver associe une fonction de l’API (calculs, récupération de données de la base de données, appels à une autre API, etc...) à une requête ou une action définie dans les objets globaux du schéma, Query et Mutation. C’est donc à ce niveau que l’on fait le lien entre les entrées des requêtes et les arguments des fonctions (id dans l’exemple ci-dessous) mais aussi que l’on regroupe les règles de fonctionnement de notre API telle que l’authentification ou la gestion des droits.
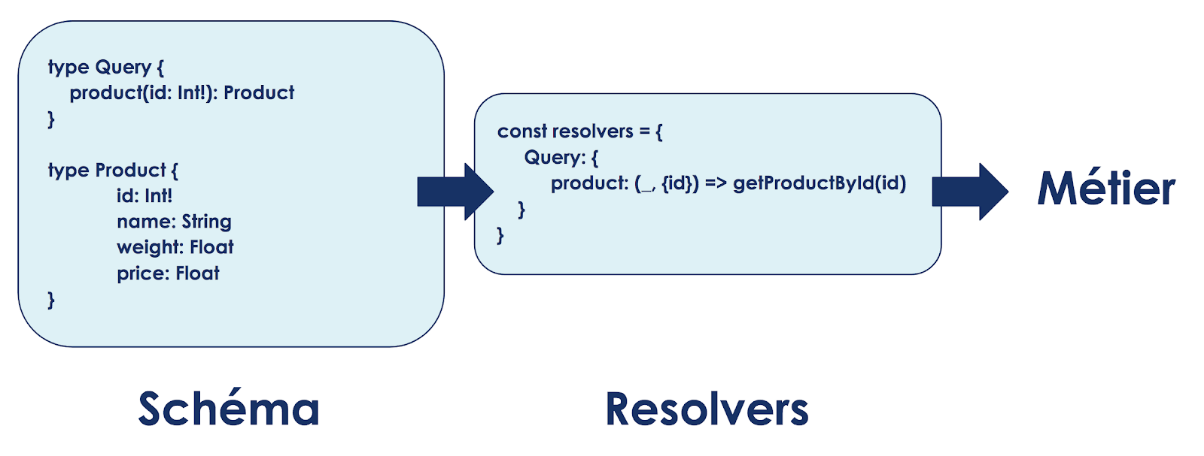
Rôle des resolvers dans une API GraphQL
Considérons l’exemple ci dessus. Dans notre schéma nous avons défini sous Query la requête product sous réserve que l’utilisateur nous précise l’id du produit qu’il souhaite. GraphQL, après avoir validé la requête, recherche dans resolvers la fonction associée, lui transmet l’argument id, récupère les données et enfin réorganise celles-ci (uniquement les champs demandés dans l’ordre demandé) pour que la réponse corresponde à la requête.
Pourquoi “Graph” dans GraphQL ?
Alors que “QL” signifie assez intuitivement Query Language (langage de requête), le “Graph” de GraphQL est souvent source de confusion. Contrairement à ce que beaucoup pense au premier abord, cela n’a rien à voir avec les bases de données orientées graphe telles que Neo4j. Il correspond plutôt à la vision côté consommateur de l’API. On peut en effet voir dans une réponse GraphQL, et dans une réponse profonde d’API en général, un arbre.
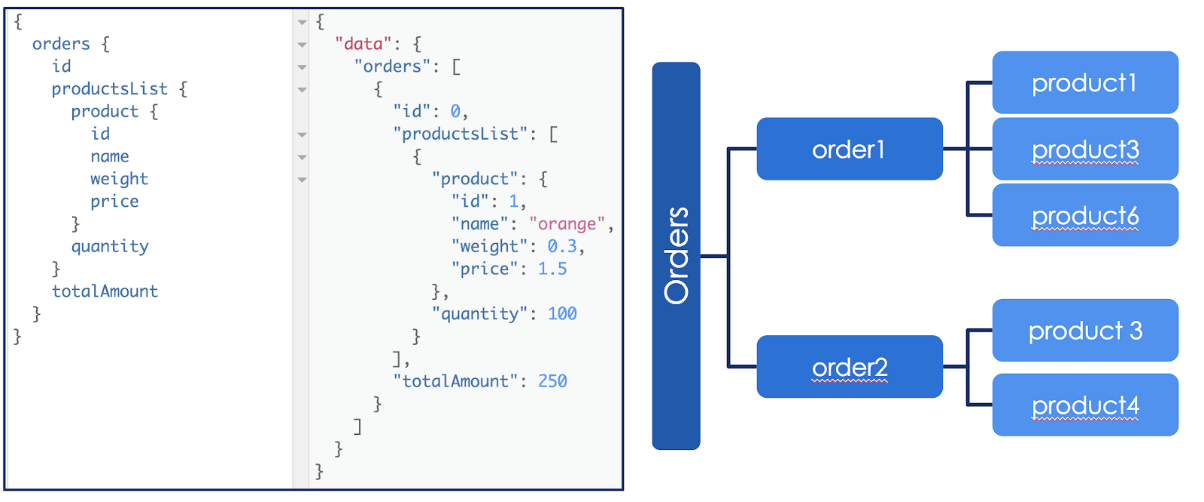
Exemple de requête et de réponse GraphQL
Par exemple, dans la requête basique ci-dessus on peut imaginer un premier niveau de notre arbre avec toutes les commandes (orders). Puis à chaque branche order, dans le champ inventaire (productsList), de nouvelles branches pour chaque produit de la commande. Dans cet exemple de requête nous n’avons qu’une seule commande avec un seul produit mais évidemment l’utilisation de GraphQL devient pertinente lorsque l’arbre est plus profond et plus fourni comme l’exemple de droite.
Ceci est un exemple très basique mais on peut bien sûr imaginer des relations bien plus complexes avec des objets interdépendants.
GraphQL : Pourquoi faire ?
Maintenant que le contexte est en place, attelons nous aux avantages et inconvénients. Le but est de déterminer les cas d’usage et les besoins de développement d’API où GraphQL sera le plus pertinent.
Optimisation des données réseau
A l’origine, le premier prototype de GraphQL en 2012 avait pour objectif de répondre aux besoins de l’application iOS de Facebook. Lorsque l’on développe une application mobile, la consommation des données est un enjeu important à considérer. En effet, notre utilisateur peut se retrouver à tout moment avec une bande passante faible (utilisateurs isolés, transport en commun...) et l’application doit tout de même s’afficher avec le minimum d’appels API, quitte à se compléter par la suite.
Le besoin du premier prototype était donc de réunir toutes les informations importantes au bon fonctionnement de l’application dans un seul appel en déléguant la complexité du client au serveur épargnant ainsi de multiples appels.
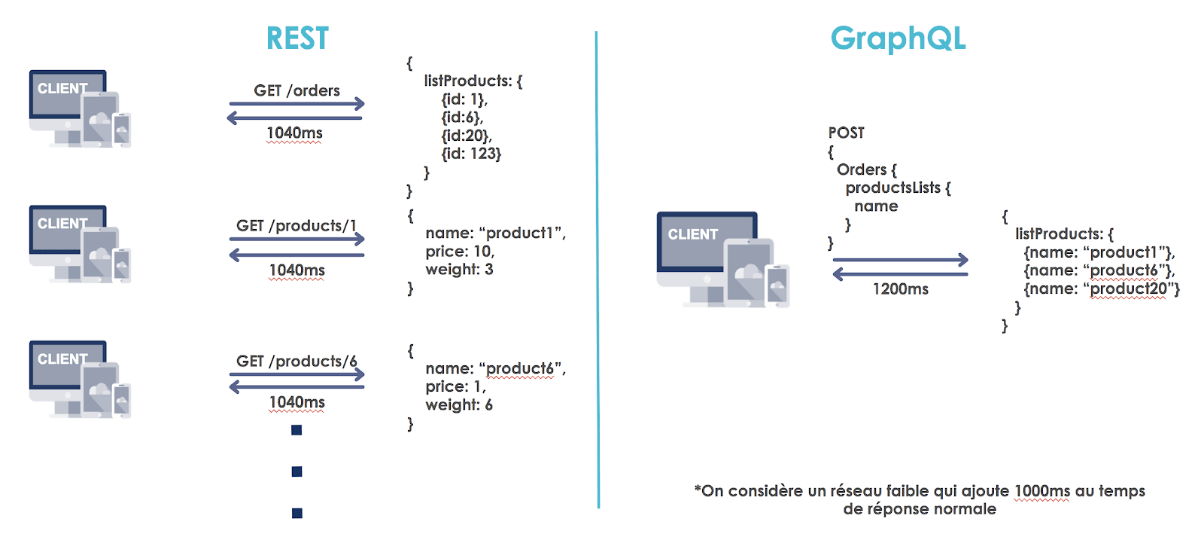
Exemple de performance réseau entre une API REST et une API GraphQL
Considérons l’exemple ci-dessus. On suppose qu’en général une requête GraphQL est plus longue à arriver à cause de problématique de cache (sur lesquels nous reviendrons) ou du fait d’un temps d’exécution serveur plus important (~+50ms). Donc en temps normal la requête GraphQL sera en général plus lente à arriver (ici par exemple 200ms au lieu de 40ms en temps normal). Mais, si le nombre d’appels augmente, ici au dessus de 5, alors le temps de réponse du serveur GraphQL est amorti. En revanche dans le cas où le transport des données est 10 fois plus important (+1000ms, 1200ms au lieu de 1040ms) cela devient alors négligeable et un seul appel s’impose.
L’optimisation des données réseau est donc un des enjeux majeurs de GraphQL.
Le cache avec GraphQL
Un des inconvénients lorsque l’on offre le pouvoir au client c’est que, contrairement à une API REST où les ressources seront toujours les mêmes, la réponse d’une API GraphQL est personnalisable que ce soit dans le choix des champs, dans l’ordre de ceux-ci et dans la combinaison des différents objets.
Le cache serveur est alors difficilement envisageable puisque les requêtes et les réponses diffèrent d’un client à l’autre. Pour remédier à cela on peut mettre en place des solutions de cache par Etag associée à chaque requête afin de ne récupérer la réponse que si l’information a été modifié. Néanmoins cette solution a ses limites puisqu’elle implique que les consommateurs exécutent toujours la même requête.
On retrouve donc généralement les stratégies de cache en GraphQL directement au niveau applicatif. Pour cela tous les outils “classiques” tels que redis ou memcache sont les bienvenus afin de ne pas refaire une même requête deux fois inutilement. Facebook fournit aussi un outil de batching et de caching, Dataloader, qui permet d’agréger les données récurrente d’une requête afin de demander une seule fois chaque donnée au serveur. Cet outil fait donc économiser un temps précieux sur des grosses requêtes récurrentes (si le sujet vous intéresse je vous recommande cette vidéo d’implémentation de DataLoader dont on voit l’efficacité à 20’45”).
Optimisation des requêtes : Personnalisation du client
Deux problématiques récurrentes avec les API en général sont l’****over fetching et l’under fetching. L’over fetching est le surplus d’informations délivrées par la requête par rapport à la donnée désirée par le client. L’under fetching est le fait de devoir faire plusieurs appels à l’API pour compléter la réponse de notre premier appel qui ne contient pas assez d’informations. Concilier ces deux problématiques peut rapidement devenir un dilemme important dans la conception d’une API avec beaucoup d’informations.
L’un des acteurs emblématiques de l’adoption de GraphQL, Github, détaille bien ce choix technologique pour la dernière version de leur API. Dans leur article, les développeurs responsable de l’API v3 (API REST hypermedia) expliquent que pour la conception de la v4 ils ont effectués plusieurs sondage auprès de leurs consommateurs. Ils en sont venus à la conclusion que les ressources de l’API contenaient trop d’informations (over fetching) et en même temps pas forcément les informations pertinentes pour chaque consommateur (under fetching).
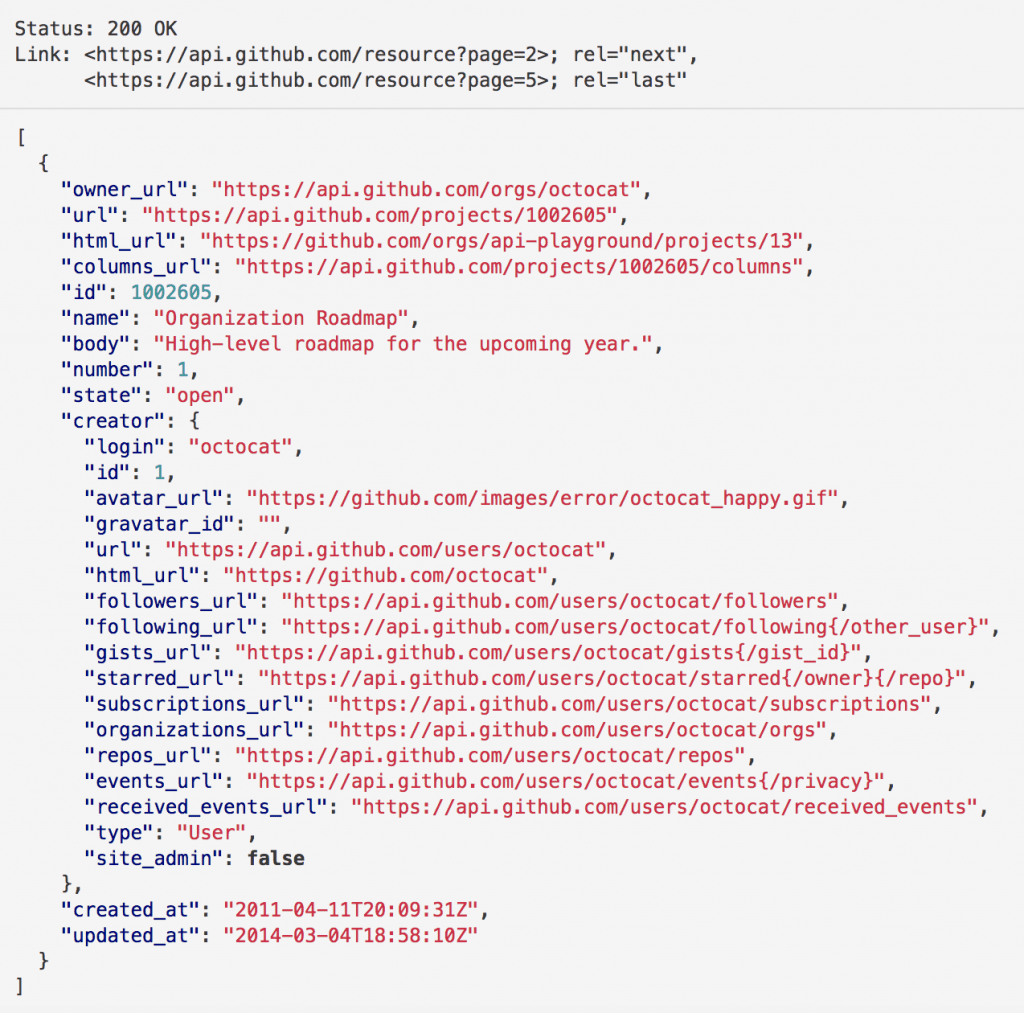
Exemple d’une requête “simple” - API v3 de Github
Pour concilier tous les besoins, les développeurs de l’API GitHub ont donc décidé plutôt que de développer une nouvelle version, d’ajouter un endpoint GraphQL afin de laisser le choix aux consommateurs des champs qu’ils souhaitaient et des combinaisons entre ressources nécessaires.
L’optimisation des requêtes ainsi que l’optimisation des données réseaux sont à mon sens les deux avantages majeurs de GraphQL à l’état de l’art. C’est-à-dire lorsque l’on considère le développement d’une API et que l’on maîtrise aussi bien REST que GraphQL en production. Néanmoins on se retrouve plus souvent dans des environnements où l’on est loin de l’état de l’art et l’on peut alors considérer d’autres enjeux de GraphQL.
Expérience développeur
Apprentissage
Dans le milieu de l’API, l’apprentissage des bonnes pratiques et la construction d’une expertise n’est souvent pas un long fleuve tranquille. Sur ce point Facebook a mis en place dès la sortie open source de GraphQL un site vitrine ainsi qu’un tutoriel. La communauté s’est aussi attelée à faire des guides comme HowtoGraphQL de GraphCool.
Mais au delà des tutoriels, cette technologie repose sur une spécification qui impose des règles précises.
Comme le souligne bien cet article de Zdenek "Z" Nemec, une des grandes difficultés avec REST est le manque de ressources et de tutoriels officiels pour apprendre les bonnes pratiques. REST n’étant pas une spécification mais un style d’architecture, il est sujet à interprétation et n’impose pas vraiment de règle à suivre.
Ainsi le recul nécessaire pour se faire un avis sur comment designer une API REST peut constituer une condition bloquante d’accès au développement d’API. Cela engendre aussi des API difformes soi-disant REST mais qui ne respecte pas les principes du style d'architecture. C’est pourquoi dès 2010, de nombreux “standards” REST ont émergés sans rencontrer néanmoins de succès franc.

How standards proliferate - Situation des standards REST à la sortie de GraphQL
À l’inverse, GraphQL est une spécification qui définit la forme des requêtes mais aussi comment les exécuter tout en restant indépendant des langages de programmation et des protocoles. C’est donc un standard clair, facile à suivre et à appliquer.
Nouvelles pratiques - Le Schéma
Mode d’emploi de l’API
Au coeur d’une API GraphQL, le schéma est le squelette de l’API. Il permet d’introduire des fonctionnalités intéressantes tels que le typage fort et donc la validation des requêtes reçues ce qui améliore l’expérience développeur dans des langages de programmation non typés notamment.

Exemple de directives dans un schéma GraphQL
Le schéma permet aussi d’avoir une vision concise et intuitive du fonctionnement de notre API. On peut en effet ajouter des directives à notre schéma pour préciser des informations telles que la dépréciation de champs mais aussi des règles métier comme @upper (cf exemple ci dessus).
Introspection et documentation automatique
Enfin les API GraphQL proposent de manière générale une fonction d’introspection du schéma. C’est-à-dire que l’on peut demander au serveur de nous envoyer son schéma. On obtient alors le descriptif de toutes les requêtes et actions possibles, les différents objets, leurs champs et les arguments à fournir pour obtenir telle ou telle réponse. En somme, on obtient une documentation automatique. On en voit l’application notamment dans les IDEs de serveur GraphQL tels que GraphiQL.
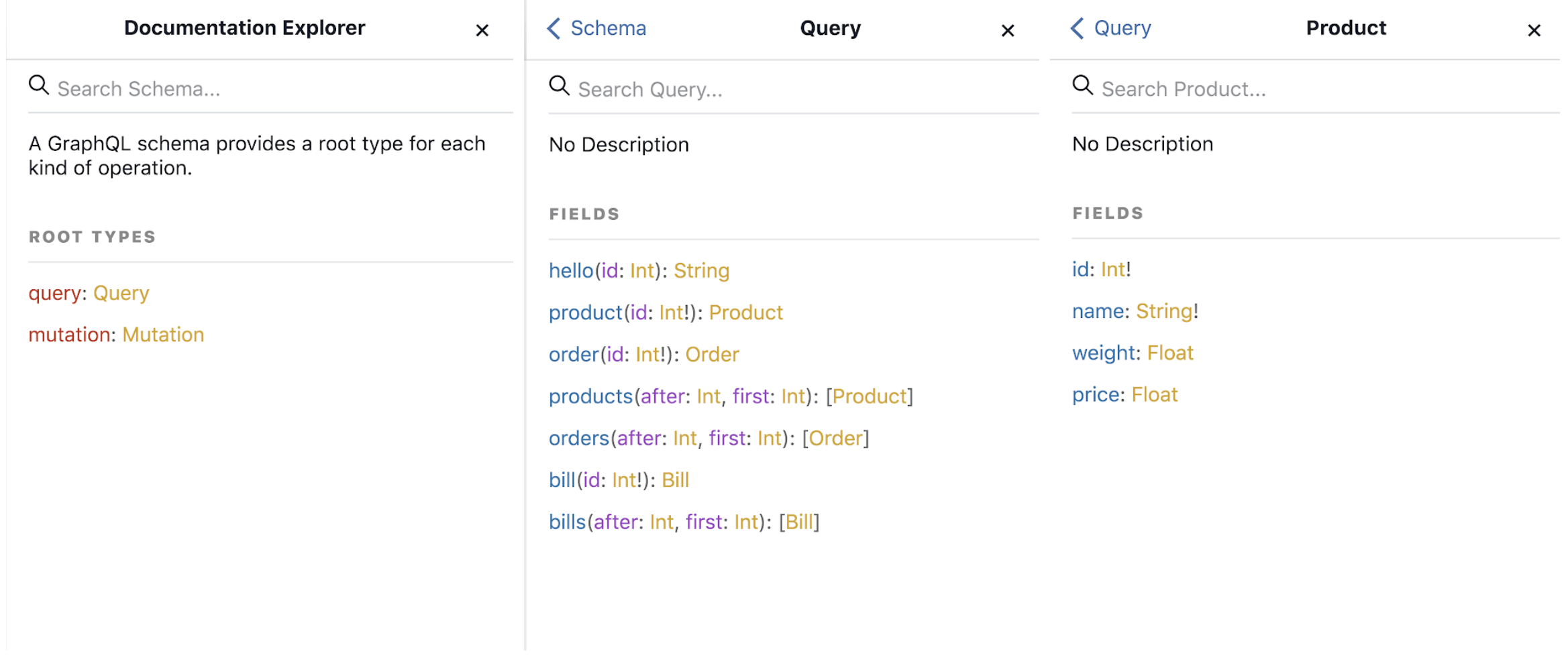
Exemple de cheminement (de la gauche vers la droite) dans la documentation GraphiQL
De plus à partir de cette introspection, le client peut, avant d’envoyer la requête au serveur, valider celle-ci grâce au schéma récupéré. On évite alors les échanges superflu avec le serveur lors du développement d’un client.
Dans un monde idéal, les API se doivent d’être autoportantes c’est-à-dire que, sans documentation extérieure, l’intuitivité de l’interface permette à l’utilisateur de consommer l’API et d’en découvrir toute les fonctionnalités. Aujourd’hui on est loin de ce modèle et de nombreuses API souffrent du manque de documentation ou de leur design peu instinctif.
L’introspection est donc un avantage clé de GraphQL et solutionne de nombreuses problématiques d'abordabilité et de découverte de l’API.
GraphQL pour améliorer la communication Client / Serveur
Backend for frontend pattern
Les nouvelles API se veulent être le plus générale possible afin de répondre aux besoins de toutes sortes de consommateurs.
Pour faciliter la communication très générale d’une API vers un client spécialisé, il existe beaucoup d’implémentations de BFF (Backend For Frontend) avec GraphQL et c’est d’ailleurs les premiers cas d’usage en production.
Pour rappel, le pattern Backend For Frontend est souvent utilisé pour bâtir une API dédiée à un front spécifique afin de répondre à des problématiques organisationnelles (exemple : mocker des endpoints API qui n’existent pas encore), de performance (API « dédiée » aux écrans de l’application mobile) ou sécuritaires (exemple : mise en place du flow Authorization Code Grant).
On retrouve donc l’aspect performance en lien avec les problématiques d'optimisation des données réseaux. Par exemple lors du développement d’une application mobile qui consomme une API non optimisée pour les réseaux à faible débit. Un BFF en GraphQL permet de récupérer les données de l’API en un seul appel. Les multiples appels sont alors effectués directement au niveau du serveur et sont indépendants des fluctuations de réseau de l’utilisateur.
On retrouve aussi l’aspect personnalisation du client et l’expérience développeur. Par exemple lors du développement d’un client personnalisé à partir des données d’une API très générale. Un BFF en GraphQL est alors pertinent:
- pour offrir au front consommateur la personnalisation de ses requêtes en fonction de ses besoins
- pour améliorer l'expérience développeur du développement du BFF puisque le niveau de personnalisation nécessaire n’impacte que très peu la complexité du développement
- pour la réutilisation du même BFF entre plusieurs front puisque la personnalisation dépend du client et non plus du serveur
Conclusion
Besoins à l’état de l’art
- Optimisation des données réseaux
- récupération des informations en un seul appel
- idéal pour des consommateurs avec un réseau faible
- Optimisation des requêtes
- le pouvoir est donné au client
- résolution des problématiques d’over fetching / under fetching
Autres apports de GraphQL
- Apprentissage et construction d’une expertise plus simple
- spécification
- tutoriels officiels et aide de la communauté
- Communication API / consommateur
- introspection du schéma / auto-documentation
- facilité d’envelopper l’existant
Aspects à considérer
- Cache
- plus complexe
- plutôt applicatif
- Nouvelles pratiques de développement
- Fonctionnement des mutations en RPC
- une mutation par action
- pas de standard de nommage (compensé par l’introspection du schéma)
GraphQL s’avère plus que pertinent pour le développement d’API avec certes des contraintes mais surtout des avantages indéniables par rapport à d’autres solutions. Son utilisation par des grands acteurs de la tech prouve qu’à l’état de l’art il y a des enjeux forts autour de cette technologie. Pour moi, GraphQL apporte aussi des réponses à des problématiques existantes telles que le manque de standards dans REST, les difficultés autour de la documentation et la communication etc... et de là vient toute l’agitation qui a entouré sa publication en open source.
MAIS GraphQL n’est pas non plus la réponse à tout et encore moins un remplaçant à REST. C’est au contraire un autre outil complémentaire dans notre boîte à outils de développement d’API.
Et vous, avez-vous testé GraphQL ? N'hésitez pas à ajouter vos retours dans les commentaires.