GraphQL: A new actor in the API world
In 2012, Facebook teams were in the process of rebuilding their native mobile applications and they had to adapt their server queries to get the data they needed. When they started to refactor some parts of their code, some got frustrated and stepped back to think of a better way. GraphQL was born.
They changed their point of view in terms of resources, and they preferred the idea of a graph of objects instead. The whole idea is to call a single endpoint, passing a query as the content of the request.
Throughout this post, I will give an overview about what GraphQL is, including advantages and drawbacks. Then will come the best part with being how to create a GraphQL API.
Some major IT actors are already using it and that gives us hints about its current stability. Here is a growing list of current users (Github, Coursera, etc…).
Let me highlight some reasons to think about GraphQL:
- Your API has more than one consumer app and these apps are out of your scope.
- You need to maintain specific endpoints for some of your consumers.
- Your consumers usually need more than one request to build a complete view.
- Some of your consumers are mobile apps (potentially slow connections).
That being said, if your application is fairly simple, it wouldn’t make sense to start using GraphQL. Or if your app requires a lot of caching and that you don't want to use a complex client app, Rest will continue to be your best choice.
And if it’s too early for you to switch everything to GraphQL, you can still work internally with it while still exposing public APIs through Rest.
Where does it come from?
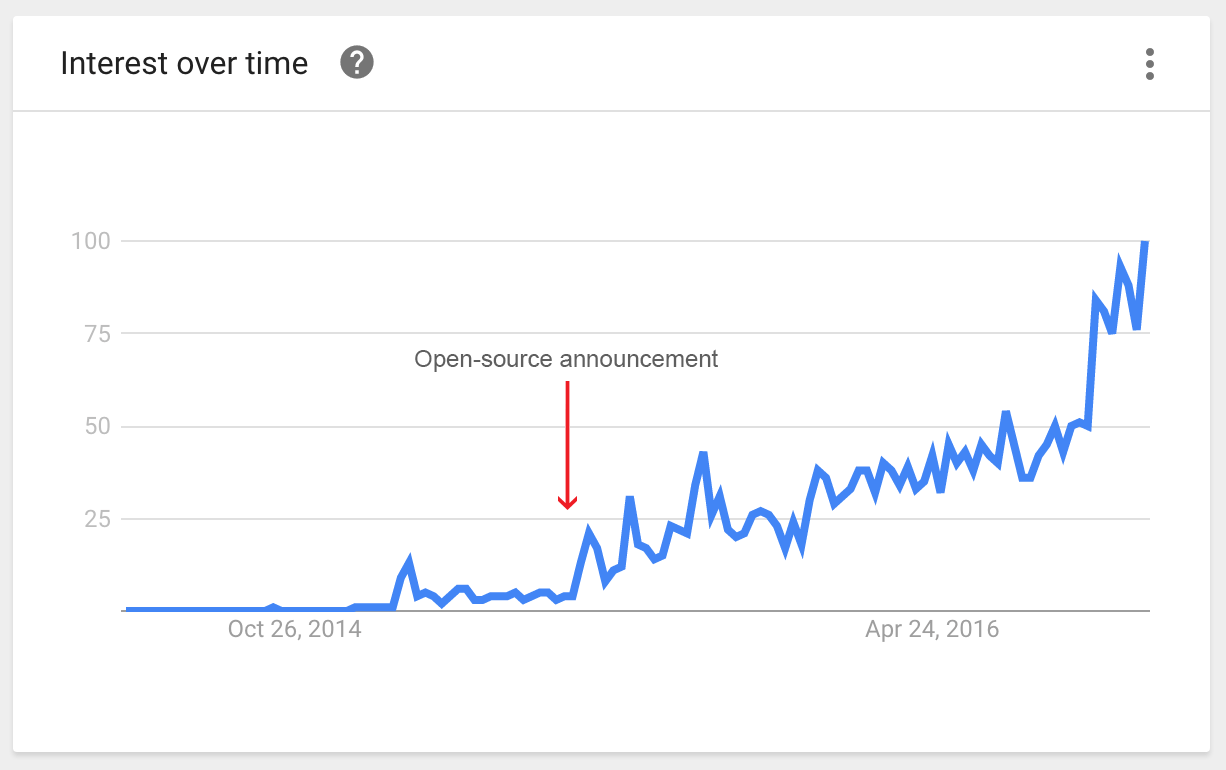
GraphQL comes from Facebook where it has been internally used for over 4 years, serving billions of API calls everyday. It became interesting when they decided to open-source it mid-2015. The detailed story can be found in their blog post.
As we can see from Google Trends, GraphQL has risen more and more interest over the past months and reached its highest peak of popularity last week.
What is it?
The name of “GraphQL” is almost self-explained: Graph Query Language. It’s a specification for a language to query data represented as a graph of objects.
The query is a string with a specific GraphQL syntax that is sent to a server to be interpreted and fulfilled, which then returns a JSON document back to the client.
Example here from Facebook, get some information about a user:

We can see that the shape of the query mirrors the response itself.
Let’s have a look at the full workflow:
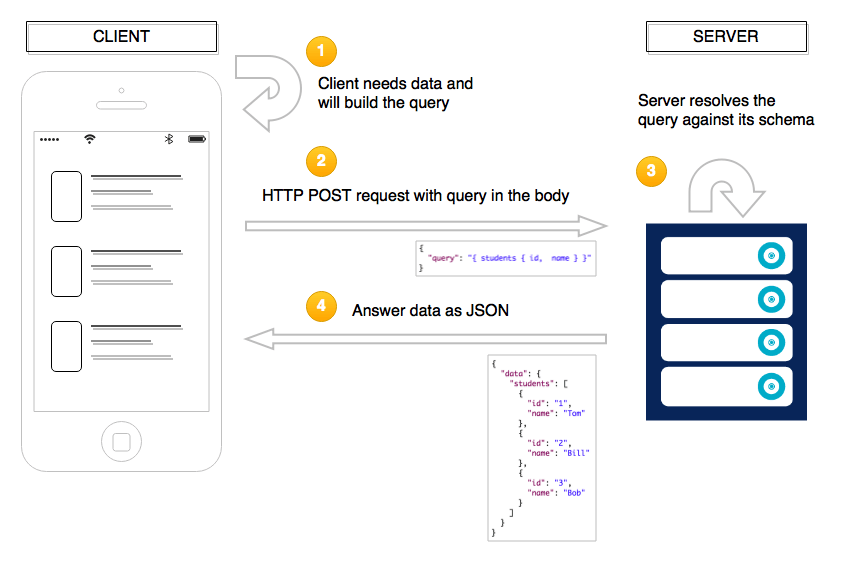
GraphQL doesn’t require to use HTTP to send your query, but that’s how it has been used by everyone so far.
You can either use a GET request and give your query as a URL parameter:
http://localhost:4000/graphql?query=query{students{id,name}}
Or use a POST request with a specific “Content-Type” header:
- “application/json”, and the body would contain a unique attribute called “query” with its value to be the GraphQL query as a pure string
- “application/graphql”, and the body would contain the raw GraphQL query in the body.
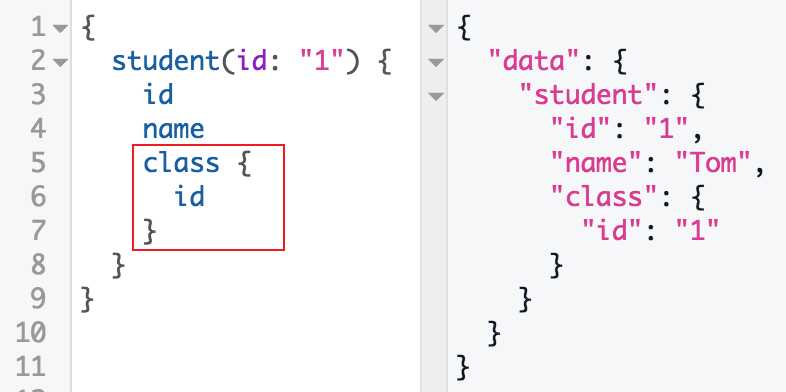
GraphQL also allows us to write complex queries using nested queries and fragments.
Nested queries are simply parts of the query that could be independent. We can then ask for children of our main object, which we call connections.
Fragments are a way to extract parts of a query and are useful to avoid any duplicate portions:
So far, we have only covered read access to our data. What about writing data?
Apart from queries, there is another operation called mutation. You can decide of these mutations, depending on what you choose to declare in your schema, but most likely they will represent C(R)UD operations. For instance, we can create a student object by defining it in the “variables” window:
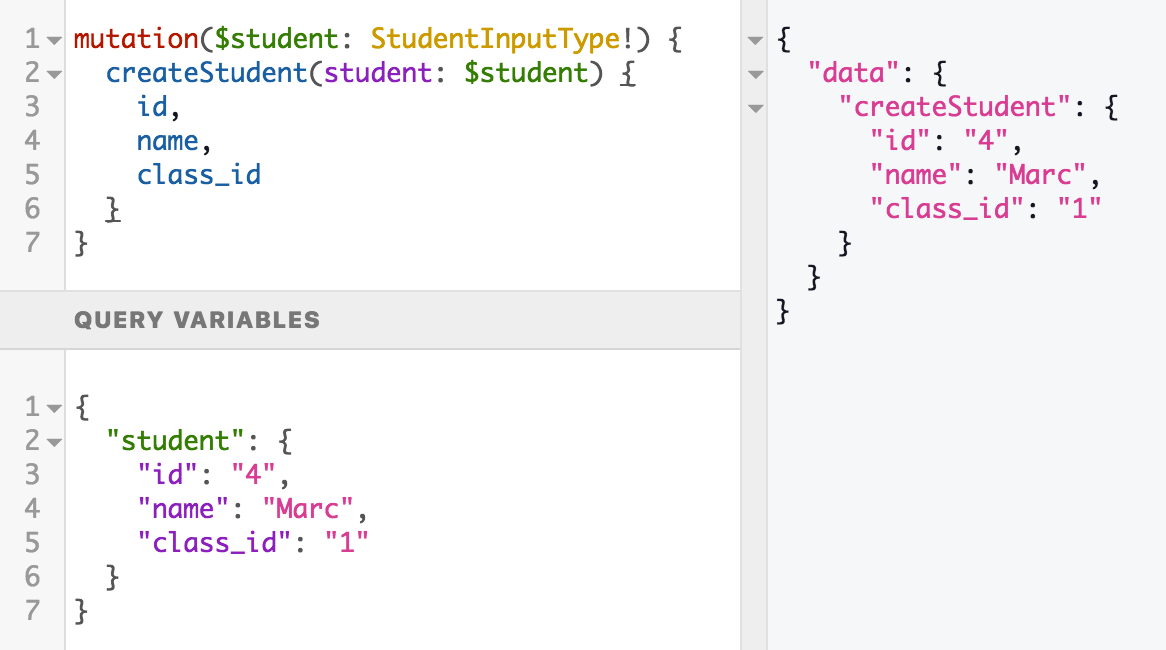
A mutation is nothing more than a query, but by convention we know that they will modify data.
As an example, Github currently proposes 15 mutations in its GraphQL API, all related to the Project feature inside repositories.



Advantages
Less backend requests
If we think in terms of resources, a client usually requires to communicate more than once with a server, as one resource is hardly enough to build a complete view.
As a simple example, if I want to display a list of 10 students from a class, I would need one request for the list + potentially ten other requests, one for each student’s details.
I could easily create a dedicated resource for this use-case, which would get me everything in one call, but it means that I need to adapt my server to handle this specific client.
HATEOAS (Hypermedia As The Engine Of Application State) aims to facilitate navigation through an API, but it doesn't change the problem. Indeed, it doesn’t decrease the number of requests you might need to render your view and doesn’t give any flexibility to the client regarding what data it needs.
Smaller payload
Let’s pretend my students API gets consumed by two different clients. They both want to display a list of students, but one wants to display student's date of birth, whereas the other client doesn’t need it.
A simple solution is to create one resource including everything. But then the second client will get student’s date of birth in all its server responses, without needing it.
With GraphQL, you can specify in your query which attributes from which entities you want. This could greatly improve mobile apps performance.
Servers become easy to generalize
Since clients are now in charge of explaining data they want through GraphQL queries, the server can then only focus on its graph of objects, instead of being adapted to each of its clients. Only one endpoint will serve everyone.
Easier to test
In a GraphQL query, we ask for entities, also called “Types”. Since each type gets a dedicated handler, it will be fairly easy to unit test them.
Hierarchy
By its nature, GraphQL is hierarchical and follows relationships between objects, as opposed to Rest where you might need additional requests to fetch linked data. Once again, when writing your query, you control the structure of the answer you want.
Strongly typed
Unlike Rest APIs, GraphQL strongly relies on types within its schema, and gives you the ability to create your own types on top of its internal types. This Type System allows GraphQL to provide descriptive error messages before executing a query.
Example of a bad parameter type:

This Type System highly contributes to all the tooling available around GraphQL, such as mock-server from graphql-tools for instance.
Documentation
Every GraphQL server comes with a tool called GraphiQL, which is a UI to execute queries, explore the schema and access documentation.
Since the whole schema is easily available on the client through GraphiQL, we can enjoy efficient auto-completion and light but complete documentation, depending on how well description is put on each field:
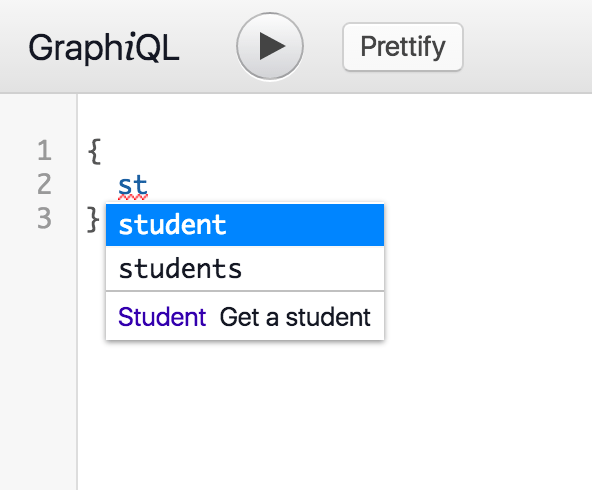
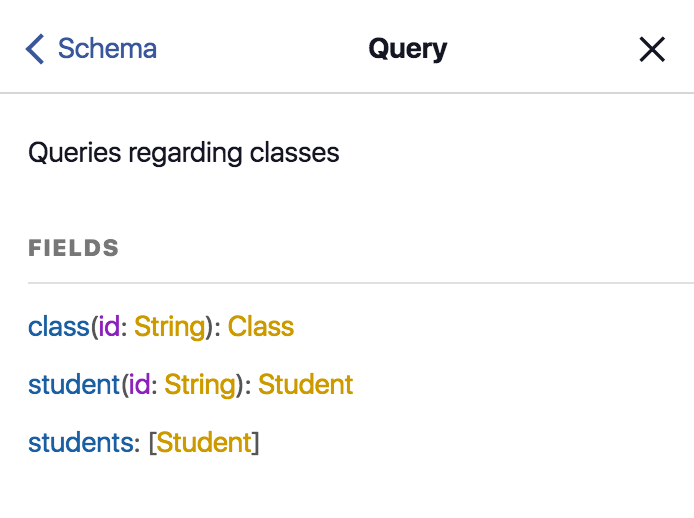
We can also query the schema itself and ask for its structure. This is called “introspection”.
With Swagger UI (a well-adopted standard to document APIs, example here), all you need as a consumer is a list of endpoints with a description of all parameters. Here with GraphQL, all you need is the schema. Apart from the schema, the problematic is the same and will depend on how much effort the dev team has put in the doc, by adding helpful comments to every field for example.
Drawbacks
As you might have guessed, GraphQL also comes with some disadvantages. Let’s have a look at the main ones.
Server code is more complex but at the end, same code will be used to answer multiple use-cases.
Defining the schema is a bit verbose but once it’s done, our server will be able to answer multiple use-cases.
To consume a GraphQL API, several clients already exist, depending on your programming language. But they lack maturity compared to any client consuming Rest services.
The need to rethink caching since getting data through POST requests disables any caching by any proxy between the client and the server. Even if the query is in the URL using GET, caching will still be compromised, as the same entity / “resource” could be part of many different queries. If you want to learn more about this, official doc will help as well as this Relay doc page explaining how to cache a graph.
And last but not least, parallelism and concurrency of processing will now have to be handled on the server-side, as we’ll have only one request potentially asking for many relations.
How to expose a GraphQL API?
We will look at an implementation in Node.js / express.
This working example is available at https://github.com/cedric25/graphql-example.
A quick demo has also been recorded: https://youtu.be/mZrSV8eRyhc. It shows some examples on how to use our schema through GraphiQL.
The server part is quite straightforward and expose one endpoint: “/graphql”:
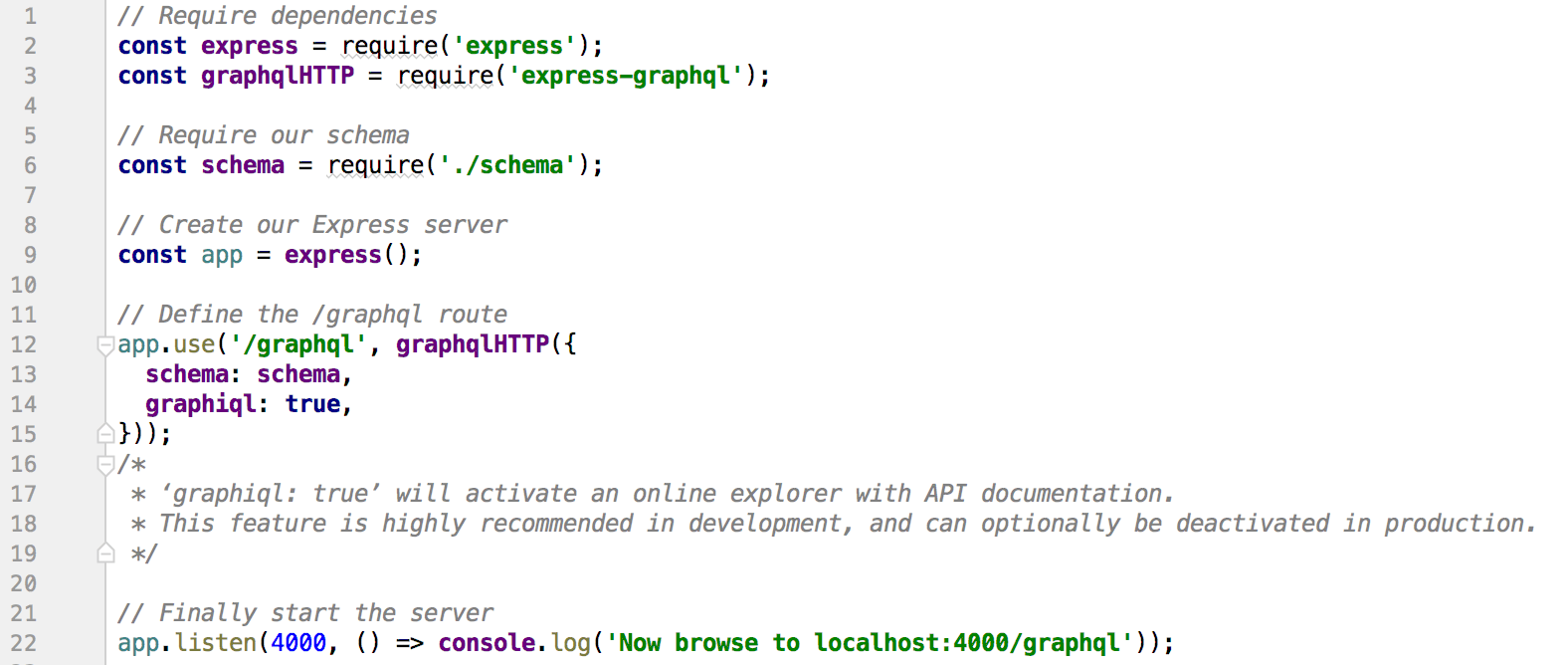
The most time-consuming part of our GraphQL server will probably be the definition of the schema.
Communication between the schema and previous data services are done through the resolve() functions.
The schema includes two parts, queries and mutations:
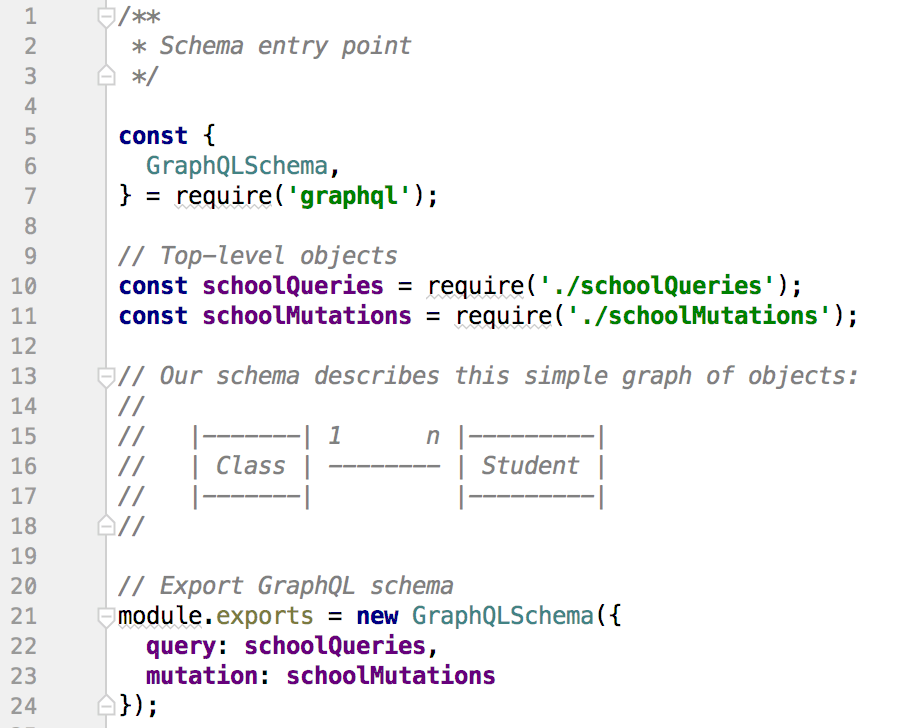
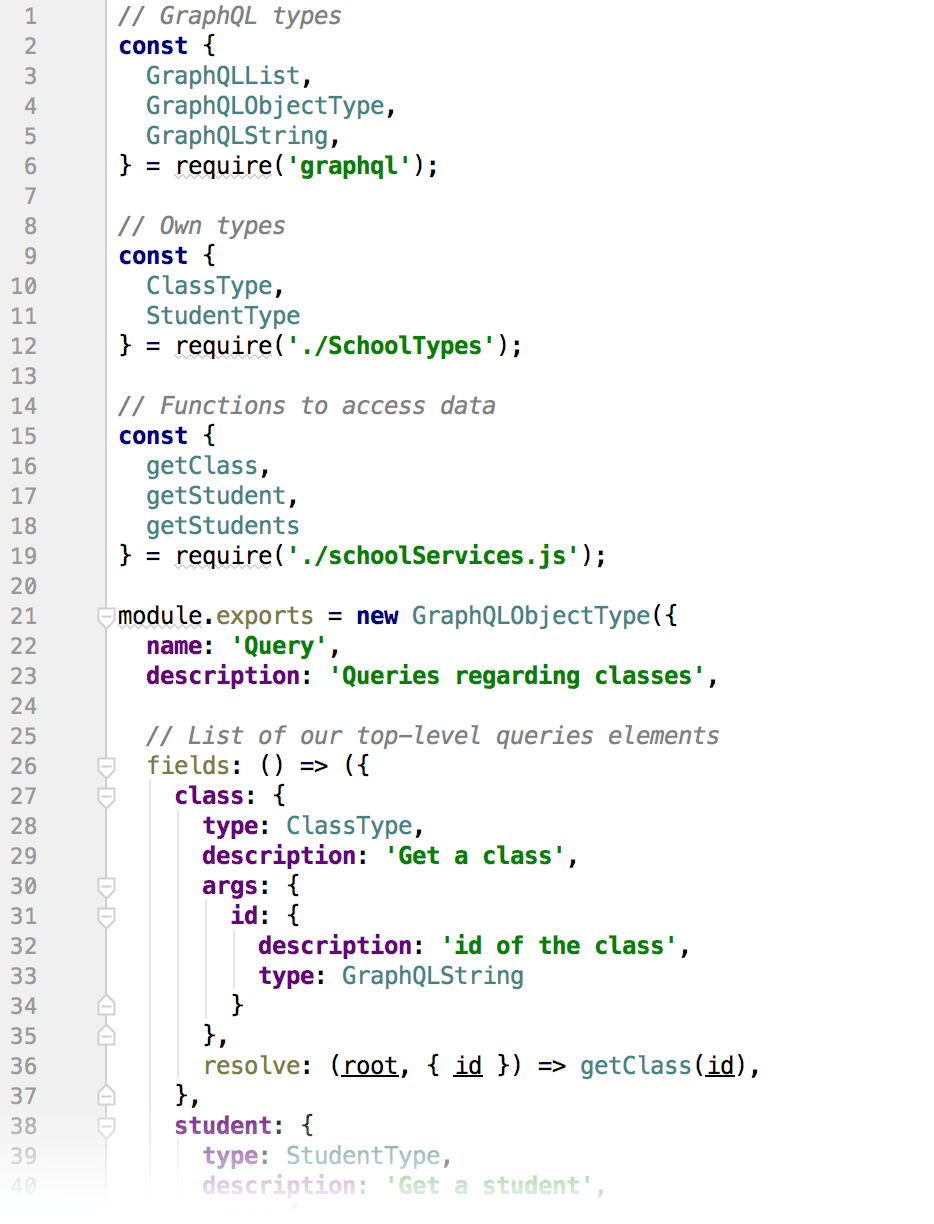
Now let’s have a look at the first query, getClass(), which takes an “id” as argument:
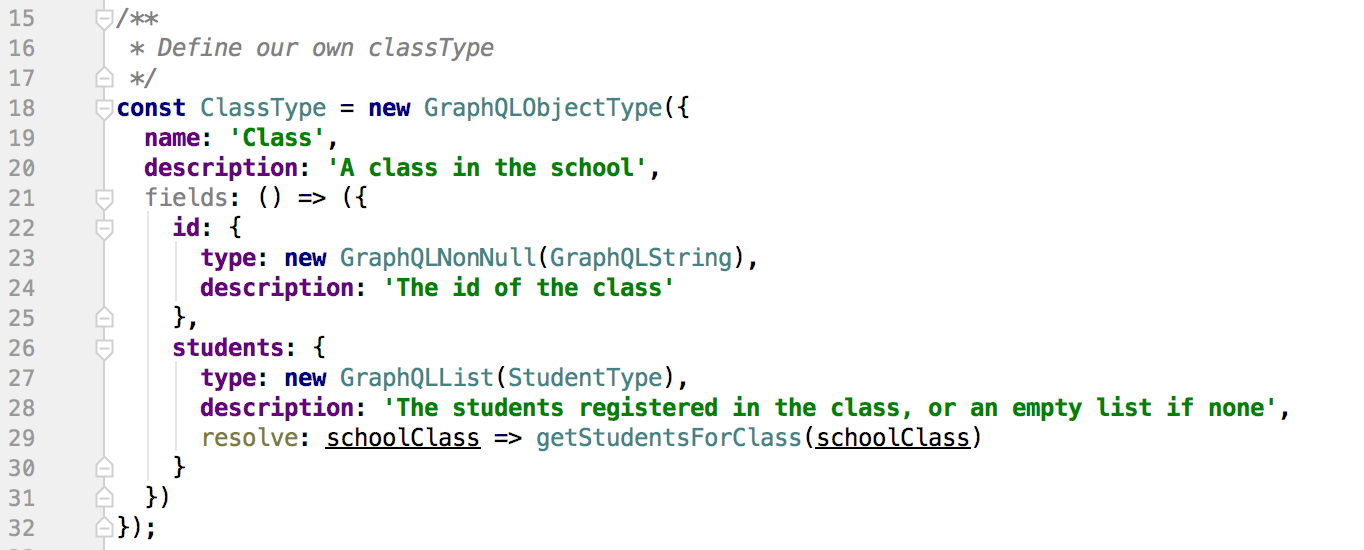
As we can see from the top of the file, we need to define some custom types. Here is the “class” type, where we simply list fields it contains, their type, if they can be null, etc…:
We can now go to our /graphql route and start playing with our data through our schema, thanks to GraphiQL, since we've activated it in the server part.
If Javascript is not your best friend, you’re not alone, a lot of other implementations exist. A good way to find them is here, or in the “Questions” part at the end of this post.
We haven’t seen it in this simple implementation, but one of the main challenges using GraphQL will be to replicate its flexibility to our data access services, meaning for example to get only necessary fields when querying our SQL / NoSQL database.
Going further
We have seen that consuming a GraphQL API is pretty straightforward by passing our query in a POST request for example. But for a real business application, we might need to use a dedicated client such as Relay for React or Apollo Client.
GraphQL will continue to evolve and will include following features in the near future:
- Subscriptions. Ability to subscribe to a feed, in case of the result of a query changes. (Just the specification part, implementations will be free to use web sockets, server-side events, etc…)
- Deferred queries. Ability to identify part of a query as not necessary before displaying a page.
More details from the React Europe conference last June.
Questions
> Will GraphQL replace Rest?
It seems too early to answer, probably not in the near future as the vast majority of existing web services are developed with a Rest architecture. Some say that both solutions can peacefully coexist, as they answer different use-cases.
> How active is the GraphQL community?
The best way to answer this question is probably to look at the public repos of different implementations:
JS, Ruby, Python, Java, Scala, .NET, PHP, C++, Go, Elixir, Haskell, Lua, Elm, Clojure
To put it in a nutshell, yes, GraphQL benefits from a fairly big and growing community, increased by big actors starting to use it.
> Does it mean that anybody can query your entire database?
No, as long as you don’t directly map your database schema to your GraphQL schema. GraphQL could be seen as a layer where you only expose the data you want.
> Would it be possible to query the entire schema to crash the server?
Theoretically, yes. But you can define timeouts and set a maximum query depth allowance, or assign complexity points to your entities and define a maximum complexity.
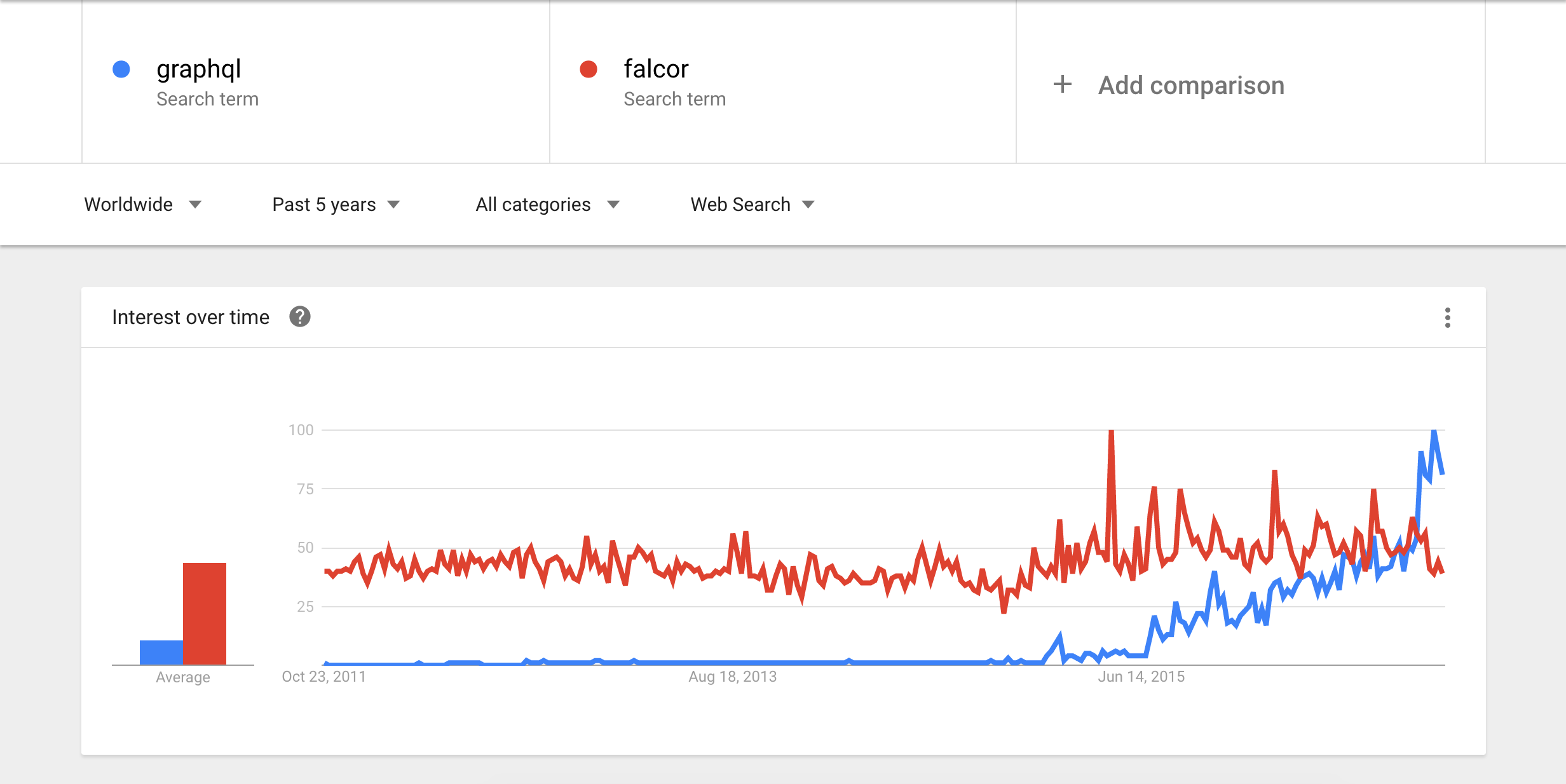
> How is it different from Falcor?
GraphQL and Falcor aim to solve the same problems. But Falcor doesn't have the type power provided by GraphQL.
I was curious and took a look at what Google Trends say:
Sources and links
- Facebook first presentation
https://code.facebook.com/posts/1691455094417024
- Complete spec from Facebook
https://facebook.github.io/graphql/
- Github explaining why they wanted to expose their API through GraphQL
http://githubengineering.com/the-github-graphql-api/
- A huge list full of interesting resources related to GraphQL:
https://github.com/chentsulin/awesome-graphql
- A GraphQL example with schema definition and data
https://github.com/graphql/graphql-js/blob/master/src/__tests__/
- 30min talk of a Shopify developer explaining GraphQL
https://www.youtube.com/watch?v=eD7kLFGOgVw
- Utility functions of graphql-js (introspection query, print schema, validate a query, etc…)
https://dev-blog.apollodata.com/graphql-js-the-hidden-features-effaca7a81b3