Graph databases: an overview
In a previous article, we introduced a few concepts related to graphs, and illustrated them with two examples using the Neo4j graph database.
For the previous years, many companies have been developing graph databases -- as software vendors like Neo Technology (Neo4j), Objectivity (InfiniteGraph), Sparsity (dex*), or by building their own custom solution to integrate it into their applications, like LinkedIn or Twitter. Thus it can be hard to grasp a global picture of this rich landscape in continuous evolution. In this new article focused on graph databases, we will give you the elements that are necessary to understand how they fit into the ecosystem, compared to the other kinds of databases and to the other types of graph processing tools. Specifically, we will try to answer an important question -- when to use a graph database and when not use one. The answer is not that obvious.
What is a graph database?
A graph database is a databases whose specific purpose is the storage of graph-oriented data structures. Thus it's all about storing data as vertices and edges. By definition, a graph database is any storage solution where connected elements are linked together without using an index. The neighbours of an entity are accessible by dereferencing a physical pointer. There are several types of graphs that can be stored: from a "single-type" undirected graph to an hypergraph, including of course property graphs.
Hence a graph database meets the following criteria:
- Storage is optimized for data represented as a graph, with a provision for storing vertices and edges
- Storage is optimized for the traversal of the graph, without using an index when following edges. A graph database is optimized for queries leveraging the proximity of data, starting from one or several root nodes, rather than global queries
- Flexible data model for some solutions: no need to declare data types for vertices or edges, as opposed to the more constrained table-oriented model of a relational database
- Integrated API with entry points for the more classical algorithms of the graph theory (shortest path, Dijsktra, A*, betweenness, ...)
Positioning
The NoSQL movement has been gaining popularity for the past few years, in particular because it can address several issues for which relational databases don't give a satisfactory answer:
- availability, for the processing of large datasets, and partitioning (relational databases give too much priority to consistency, the 'C' in the CAP theorem)
- flexibility of the schema
- difficulty in modelling and processing complex structures like trees, graphs, or too many relationships
In the database ecosystem, graph databases mostly address the last two items:
- process highly connected data
- easily manage complex and flexible data models
- offer exceptional performances for local reads, by traversing the graph
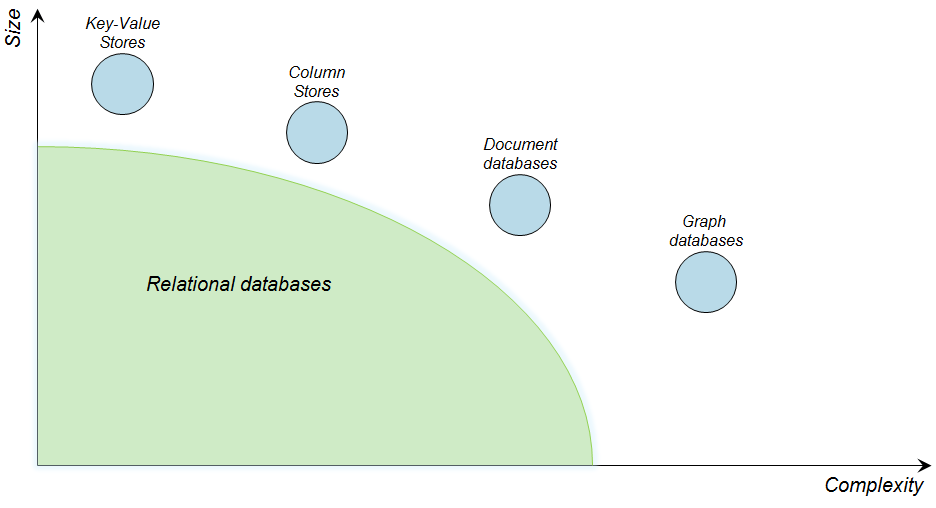
Positions of NoSQL databases (source: Neo4j)
Graph vs relational databases
A graph database is a good fit for exploring data that are structured like a graph (or derived such as a tree), in particular when the relationships between items are significant. The ideal use case for a query, is starting from one or several nodes and traversing the graph. It's always possible to issue more global queries such as myEntity.findAll ("find all entities of a kind"), but in this case an indexation mechanism must be used. Such a mechanism can be crafted into the graph (supernodes added for indexing purposes), or use another solution on top of the database (with Apache Lucene for example).
By contrast, relational databases are well fitted to findAll-like queries, thanks to the internal structure of the tables. It's all the more adequate when aggregations over a complete dataset must be performed.
Despite their names though, relational databases are less suited for exploring relationships. Such use cases need indices, in particular foreign keys. As stated before, with graph databases traversals are performed by following physical pointers, whereas foreign keys are logical pointers.
To make it clearer, let's take a naïve example where we try to store companies, people who work for them, and for how long they have been working there. For instance, we are trying to find all people working at Google.
With a relational model, we could execute the following query, which would probably need 3 index lookups corresponding to the foreign keys in the model.
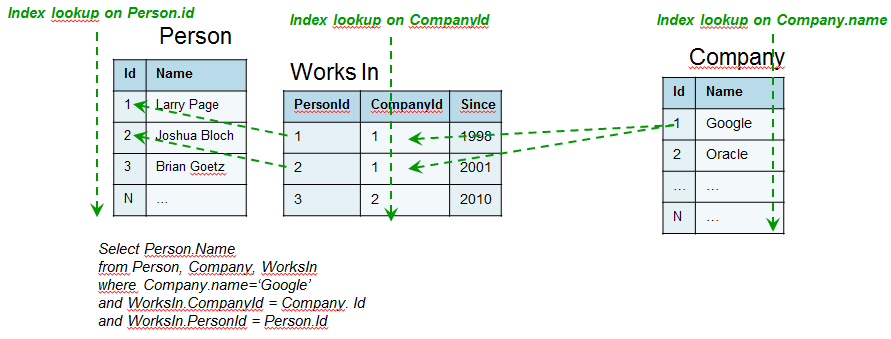
In the case of a graph, the query will need 1 index lookup, then will traverse relationships by dereferencing physical pointers directly.
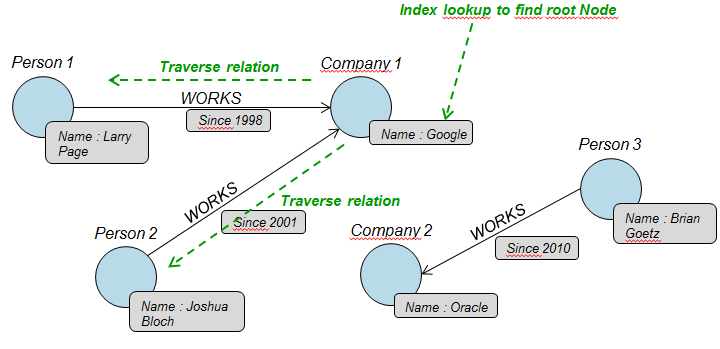
This is a very simple example, however it shows a situation where the performance of a graph database will be superior than that of a relational database.
The difference in performance will be all the more important as the volume of data increases, because except the first index lookup to find the starting node(s) for traversal, the query will more or less run in constant time. With a relational database, in contrast, each index scan dereferencing a foreign key will cost O(log2 N) if using is a B-Tree index (N being the number of records in the table).
Comparing performances between graph databases and other types of databases is a challenge, because of their difference in nature and in purpose. For a query, a graph database will necessarily encompass a relational database if the access pattern is what it was designed for: a traversal. The difference will be even greater when the depth of the traversal is important, or when it is not known in advance (the execution plan for an equivalent SQL query could not even be optimized). Some public benchmarks illustrate it well.
Graph storage and graph processing
Another comparison that can be made concerns graph databases vs large-scale graph processing frameworks, such as Google's Pregel or BSP, that were recently presented. The first difference is that they are tools with quite different purposes, although they represent data in the same way. Jim Webber from Neo Technology gives an interesting (though not independant) point of view:
- graph processing tools, as their names say, only address analytical use cases (OLAP), whereas graph databases mainly address storage and transactional processing use cases (OLTP)
- graph processing tools, akin to other tools like Hadoop, incur significant latency costs (several seconds) when performing calculations. In contrast, Neo4j aims at low latency reads (around a millisecond)
- the two families don't aim at the same volume of calculations, and don't have the same requirements in infrastructure: with a graph database such as Neo4j, high volumes are typically handled with vertical scaling on a single server. Tools like Pregel handle them with a scale-out approach, by distributing the processing across several commodity servers
- graph processing tools are fully distributed in nature, a characteristic that most graph databases don't have
Thus we deal with two different families that address different types and scales of problems. Speaking about use cases, a graph database will be well fitted for navigation inside a graph, or solving a shortest path problem, whereas a graph processing framework will address clustering problems, betweenness computations or a global search over all paths.
Graph databases have a structural limitation regarding their size: partitioning a graph is a difficult problem, in particular when it has to consider parameters such as the network latency, the access patterns in the graph (which relationships are followed the most), and the real-time evolution of the graph. Some graph databases like OrientDB and InfiniteGraph advert themselves as easily partitionable, while the Neo4j guys are working on it.
But one has to keep in mind that a graph databases is adequate for the volume that most organizations have to deal with, and that it can store several billions of nodes on a single server. One should not consider Pregel at the expense of Neo4j every time -- just like relational databases should not be dismissed altogether because they can't handle high volumes as well as BI tools or a SMAQ stack (Storage, MapReduce And Query) like Hadoop.
The presentation of the new challenger Titan by Marko Rodriguez gives more insight on the rich graph ecosystem.
The following chart, taken from the presentation, sums up very well the position of several tools, depending on the volume of data to handle and the expected speed of the graph traversal. The bigger the graph (and the portion of the graph being traversed), the higher the latency.
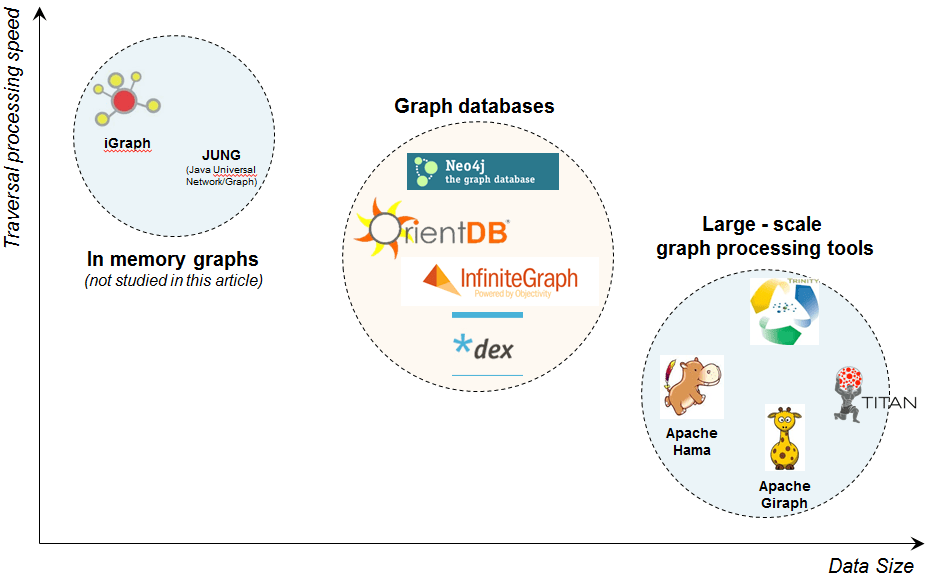
Classification of graph processing tools (source: Marko Rodriguez)
Data model
A last point where graph databases shine, is the ease of data modelling. Oftentimes, when one has to represent a business problem and the associated entities, it looks like this:
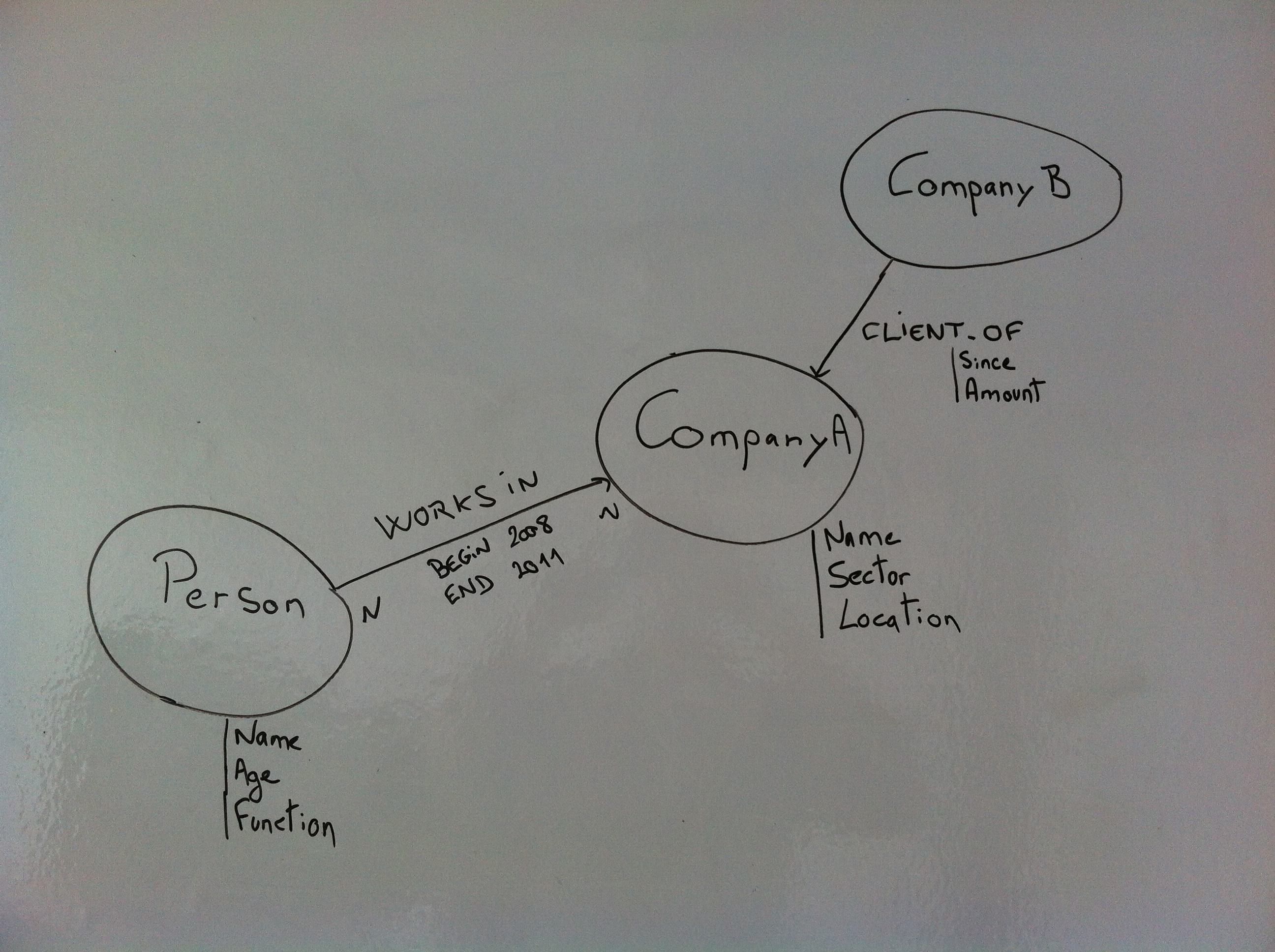
Business model
Then, when one has chosen the storage system, the data model must be fitted into it. If a relational database is chosen, one generally starts by normalizing the model so that it complies with the 3rd normal form, and it could look like this:
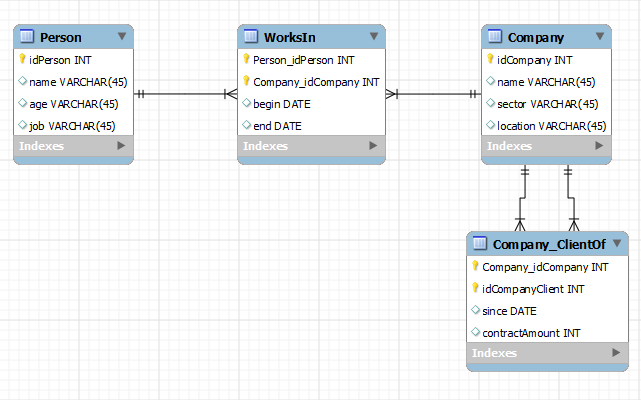
Relational model
But if one chooses to model the data with a graph database, it will probably look like this:
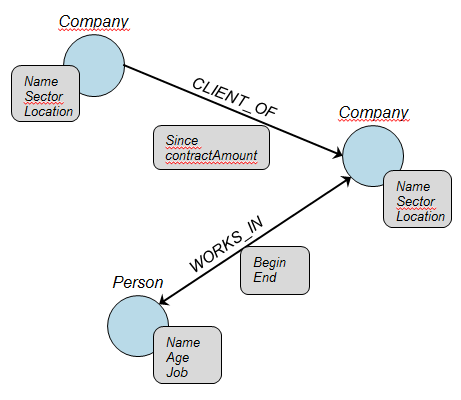
Graph model
Modelling data as a graph is natural, and has the nice benefit of staying legible even by non-technical people. The previous example is simplistic, and just as a relational model is sometimes denormalized for performance reasons, some less legible optimizations of the graph may be brought into the graph.
So, what to choose?
There is no single answer to this question, and the take-away of this article is that everything depends on how the data will be used.
If your system requires you to query data like a graph, a tree, a hierarchical structure -- in short with a complex and highly connected model --, then a graph management systems is probably the best choice.
The next step depends on the way the data is to be processed: if you have real-time access needs and the volume is not too high, a graph database or a custom graph representation in memory should be fine.
If there is in addition a need to store data as a graph, a graph database will do it. Such a choice will allow you to easily traverse the relationships, with some trade-offs like complementary indices for reporting or CRUD display. And vice-versa if you opt for a relational database.
Lastly, if the volume of data to process is huge, a graph processing solution must be considered, at the cost of higher processing delays and a batch approach.
The election of the database is a crucial architectural decision that is often made at the beginning of a project, but it may not be carved in stone. By keeping one's code and architecture clean, complying to the principle of separation of responsibilities, and with a clean view of the data model, new choices can be made and the architecture can evolve. If necessary, two separate persistence solution can coexist for each use case: this is the world of polyglot persistence.
In the next article, we will dive deeper into the characteristics of graph databases and development tools that are proeminent today.