Git et Mercurial: avant tout de bons outils de merge !
Git et Mercurial : derrière ces noms se cachent deux des trois DVCS les plus connus (le troisième étant Bazaar). Ces outils atteignent maintenant un bon niveau de maturité et je me suis donc demandé si ce bon vieux SVN n'avait pas trouvé ses successeurs... Mais avant de savoir ce que le pattern DVCS est capable de m'apporter, je me suis interrogé sur leurs capacités à être déjà, en soit, de bon outils de merge. Vous trouverez dans cet article le résultat de mon enquête...
C'est quoi un DVCS ?
Pour ceux qui souhaiteraient ce rafraichir la mémoire, vous pourrez trouver une définition dans cette article de David.
Comment ces outils fonctionnent techniquement, par rapport à SVN ?
SVN
SVN repose sur une représentation bi-dimensionnelle, permettant d'identifier chaque fichier par son chemin et son numéro de révision. Par exemple, le repo central SVN aura cette forme là au bout de 3 commits :
-revision 1 (commit initial) --com ---octo ----test -----fichier1 -revision 2 (ajout du fichier 2) --com ---octo ----test -----fichier1 -----fichier2 -revision 3 (modification du fichier 2) --com ---octo ----test -----fichier1
-----fichier2
A chaque fichier ou dossier peut être associé un fichier de propriété, lui aussi versionné, contenant des informations de configurations supplémentaires (ex : fichiers à ignorer, etc...). Chaque révision possède aussi un fichier de propriété, permettant de mieux la qualifier (commentaire, nom du commiter, timestamp...)
Ce mode de fonctionnement génère un certain nombre de contraintes, notamment sur la gestion du renommage et du déplacement du fichier ou d'un dossier. En effet, comment gérer efficacement l'historique entre deux versions d'un même fichier alors que celui-ci a été renommé et/ou déplacé ? Pire, comment gérer un merge entre deux versions du même fichier, dans l'une il a été déplacé, dans l'autre son contenu a juste été modifié. Ceux qui, comme moi, utilisent SVN depuis un certain temps, savent que c'est là que pèche SVN. Qui n'a pas pesté lors d'un merge douloureux après un gros refactoring de l'arborescence projet ?
Par exemple :
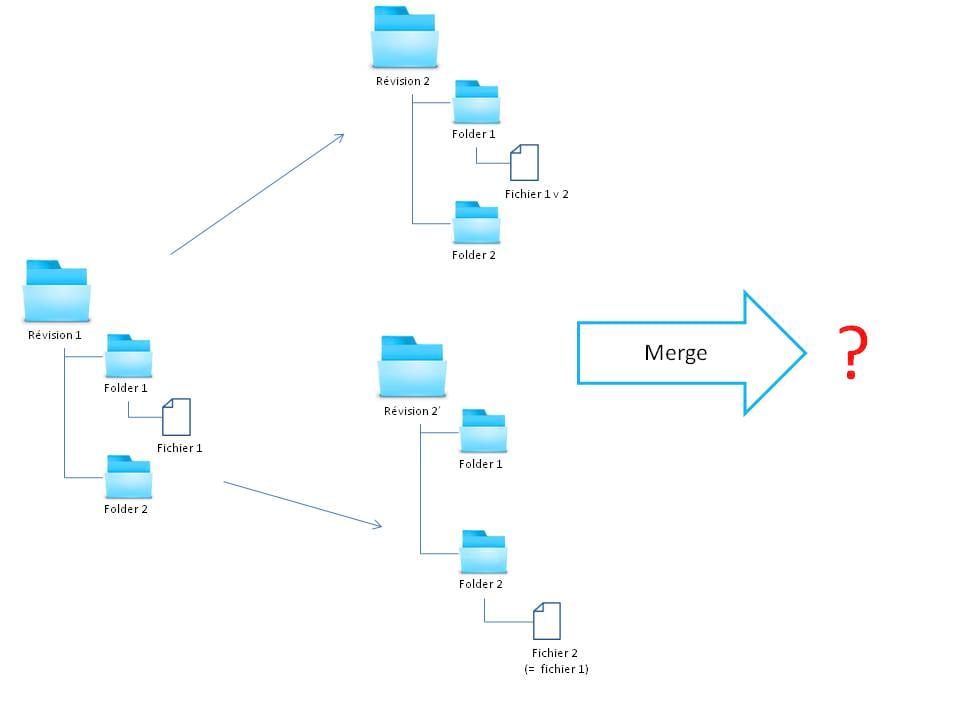
Un merge difficile en perspective...
Git
Le fonctionnement de Git repose sur l'association d'un UID à chacun de ses objets. Cet UID est généré à l'aide d'une clé de hashage de type SHA-1, appliquée sur le contenu de l'objet. Il n'est donc pas possible dans GIT d'avoir deux objets au contenu identique. Toutefois, un même objet peut être référencé à plusieurs endroits, comme il l'est décrit ci-après.
Ces objets sont aux nombres de 4:
- Un descripteur de révision, nommé "commit".
- Un descripteur de répertoire projet, nommé "tree".
- Un descripteur de contenu de fichier, nommé "blob".
- Un descripteur de tag, nommé "tag".
L'objet "commit", en plus de contenir un certain nombre d'info descriptive sur la révision (commiter, commit parent, timestamp, commiter initial (si le commit est un passe plat entre différent repo GIT)), pointe, via son UID, sur l'objet "tree" décrivant le répertoire racine du projet à la date du commit.
Un objet "tree" associe les UIDs d'autres objets "tree" ou d'objets "blob" a des noms. Si deux répertoires ont un contenu identique dans le système de fichier, alors, dans GIT, le tree parent associera juste des noms (de répertoire) différents au même UID.
Un objet "blob" est le contenu d'un fichier. Si deux fichiers ont un contenu identique, alors le tree parent associera juste ds noms (de fichiers) différents au même UID.
Un objet "tag" permet d'associer un nom particulier à un objet "commit".
Exemple (simplifié) :
Objet Commit :
id : 24ac7.. parent : 90a5fb... tree : 45c2a... commiter : Arnaud comment : user story 23
Objet tree :
id : 45c2a... blob : 0234ba... : readme blob : 721ba9... : pom.xml tree : ea123d... : src tree : 49d11a... : web-inf ...
Objet blob :
id : 721ba9... <project> <groupId>com.octo</groupId> <artifactId>test</artifactId> ...
Objet tag :
id : fa34c2 object : 24ac7.. type : commit tagger : Arnaud
tag : V1.5.0
Il est important de noter que deux versions d'un même fichier, par exemple, seront stockées de façon logique sous la forme de deux objets différents avec deux UID différents.
J'ajoute que Git possède un mécanisme de détection du renommage d'un fichier en comparant le contenu d'un blob renommé dans un commit à tous les blobs associés à des noms "disparus" dans un autre commit. Si la correspondance entre deux blobs se fait à plus de 50% (cette valeur est paramétrable), alors on considère que l'un et l'autre sont liés.
Pour reprendre le cas limitant de SVN concernant le merge entre deux versions d'un même fichier déplacé et renommé d'un côté , modifié de l'autre, ça ne pose aucun problème d'identification à Git. Il va utiliser à peu de choses près le workflow suivant :
- Identification du "blob" ancêtre du contenu du fichier
- Génération d'un "blob", fils de l'ancien" avec le nouveau contenu et génération d'un nouvel UID.
- Génération de nouveaux objets "tree", fils des anciens, dans lesquels les références vers l'UID de l'ancien objet ont été remplacées par celles vers le nouveau
- Génération d'un objet "commit" fils.
De façon plus schématique, on peut représenter ce cas ainsi :
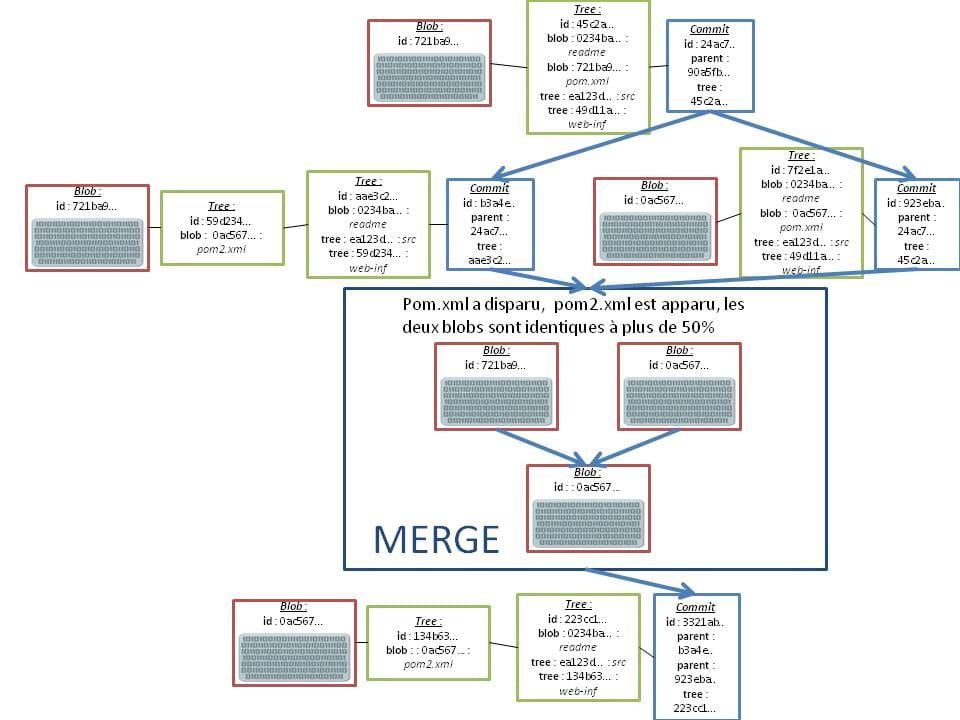
Merge sur un cas limite avec Git
Toutefois, il existe deux cas limites :
- Si dans un commit A, un fichier "test1" est à la fois modifié à plus de 50% de sa taille et renommé, GIT ne peut pas détecter le renommage. Par extension, il ne pourra pas faire le lien si dans un commit B, le fichier "test1" est juste modifié. Si A avait été découpé en deux commits, alors GIT aurait pu identifier les deux étapes et faire le lien.
- Imaginons que dans un commit A un fichier "test1" est renommé en "test2" et qu'un nouveau fichier "test1" est créé. Dans un second commit concurrent, B, le contenu du fichier "test1" initial a été modifié. Le merge des deux commit fera que le contenu modifié de "test1" dans B sera mergé avec le contenu du nouveau "test1" de A. Si le contenu du commit A avait été poussé vers le repo en deux fois, alors GIT aurait pu identifier que "test2" avait pour ancêtre "test1" et que, en fait, le "test1" de B hérite de "test2" de A.
Mercurial
Mercurial a un fonctionnement légèrement différent de celui de GIT. Il utilise lui aussi un système d'UID par la création d'un empreinte via une clé de hashage et un trio d'objets proche de celui formé par commit/tree/blob pour Git, nommés manifest/changeset/file. Toutefois, le contenu des objets "manifest" et "changeset" est complètement différent de leurs "équivalents" pour Git. L'objet "file" fonctionne de façon identique à l'objet "blob".
L'objet "manifest" est lui-même versionné mais unique : il n'y en a qu'un par projet. C'est la représentation du contenu de l'intégralité du projet. Chaque objet "file" y est représentée par son UID auquel est associé son chemin et son nom.
L'objet "changeset" est un ensemble de méta datas caractérisant les modifications apportés par une révision. Il contient l'information sur le committer, un timestamp, l'UID de la version de l'objet "manifest" associée ainsi que le chemin de chaque objet modifié dans le projet (et non l'UID).
Exemple (simplifié) :
Objet changeset :
changeset nodeid : 24ac7.. manifest nodeid : 45c2a... commiter : Arnaud file : pom.xml comment : user story 23
Objet manifest :
nodeid : 45c2a... 0234ba... : readme 721ba9... : pom.xml ea123d... : src 49d11a... : web-inf ...
Objet file :
id : 721ba9... <project> <groupId>com.octo</groupId> <artifactId>test</artifactId>
...
Chaque objet possède un index de ses différentes révisions, nommé "revlog", contrairement à Git. Pour chaque nouvelle version d'un objet, le revlog enregistre l'UID du ou de ces parents, le nouvel UID de l'objet ainsi que le delta entre la ou les précédentes version de l'objet. Les objets changesets sont un cas particulier. En effet, vu qu'il en existe un par version du projet, il n'existe donc par extension pas de "revlog". Toutefois, il existe un journal des changesets, nommé changelog dans lequel est contenu le lien entre les différents "changeset".
Les liens entre les différents "changeset" est fait via un changelog.
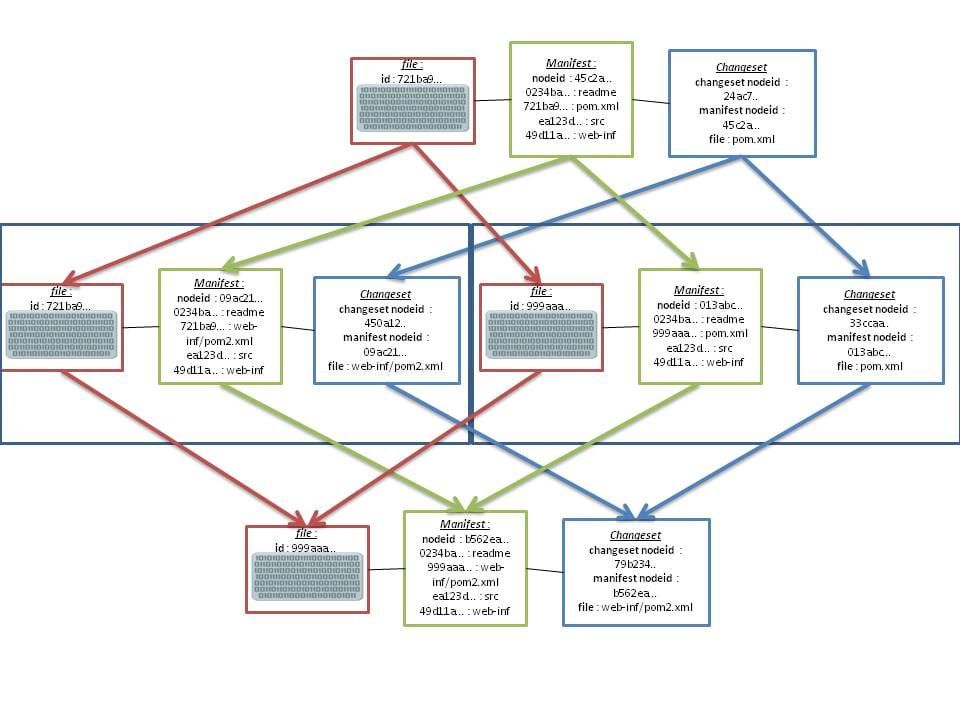
Enfin, pour reprendre toujours le cas de merge limite de SVN, avec Mercurial, on aura à peu près le workflow suivant :
- Identification du "file" ancêtre du contenu du fichier, via son revlog.
- Génération d'un nouveau "file" fils, avec le nouveau contenu et génération d'un nouvel UID.
- Mise à jour du "manifest" pour faire pointer les chemins vers le nouveau contenu
- Génération d'un nouvel objet "changeset".
- Ecriture des différents revlogs et du changelog
Schématiquement, les liens entre les différents versions du projets pourraient être représentés ainsi:
{kind=link}
Et Bazaar dans tout ça ?
Je n'ai pas réussi à trouver une documentation précise sur le fonctionnement interne de Bazaar. Toutefois, il se base aussi sur un mode où le nom et le chemin d'un fichier sont liés indirectement à leur contenu par l'utilisation d'un identifiant unique.
Au final, ça m'apporte quoi par rapport à SVN ?
Et bien, essentiellement une plus grande latitude sur les merges puisqu'on arrive enfin à gérer proprement le renommage et le déplacement de fichier et/ou de répertoire, même lors de modifications concurrentes. En terme de productivité des développements, c'est un atout indéniable. En effet, là où la peur d'un merge hasardeux pouvait faire hésiter avant tout refactoring de l'arborescence projet, il n'y a maintenant plus aucun doute à avoir !
Par extension, la fonctionnalité de merge étant un pré requis à celle de branchage, un frein supplémentaire s'enlève quant à l'adoption pleine et entière de cette possibilité et l'utilisation de nouveaux modes de travail basés sur l'utilisation des branches...
Pour conclure
Git, Mercurial et Bazaar, dans un mode VCS où les changements auraient pour but d'être poussés vers un repository central m'offrent effectivement plus de sécurités dans le cadre d'un travail collaboratif. J'ajouterai, en plus, qu'ils offrent tous les trois la possibilité de travailler en local sous leur propre format et de se synchroniser vers un repository central SVN. Je conclurai donc cette démonstration en vous conseillant de ne pas avoir peur de l'investissement préalable à la mise en place d'un des 3 outils précédemment cités, ne serait-ce que sur votre poste, à défaut de sur votre projet. En effet, la sécurisation de vos refactorings est, pour moi, à ce prix...
Toutefois, le merge n'est pas leur seul atout, et ne pas étudier les nouveaux workflows qu'ils peuvent vous permettre de mettre en place vous feraient passer à côté de bien des chose (comme le build incassable par exemple...)