Git dans la pratique (1/2)
Nous avons déjà parlé de Git sur ce blog, sur la notion de DVCS, sur son utilisation pour réaliser un build incassable, et sur ces formidables outils de merge que sont les DVCS. Mais qu'en est-il des "Git va vous sauver la vie", "Git c'est trop cool, comment je faisais avant ?" ou des "Git c'est trop compliqué, j'comprends rien, pourquoi on n'utilise pas Subversion ?". Qu'en est-il de l'utilisation de Git dans un projet ou Subversion aurait pu "faire l'affaire" (ie. un dépôt centralisé, une seule équipe de développeurs dans un même bureau) ?
Après quelques mois d'utilisation de Git dans un projet avec une dizaine de développeurs, la plupart ne connaissant Git que de nom et ayant tous une bonne connaissance de Subversion, chacune des citations précédentes deviennent plus claires :
- Oui, Git c'est compliqué si l'on veut profiter de tout son potentiel et même parfois pour faire ce que l'on faisait avec d'autres outils de gestion de version,
- Et oui, Git offre des fonctionnalités et une flexibilité qui peuvent améliorer votre quotidien de développeur.
Oui, Git c'est compliqué
Lorsque l'on n'a pas pris/eu le temps d'apprendre à se servir de Git et de comprendre son fonctionnement, il faut avouer que soit on n'en demande pas trop et on ne trouve pas Git plus compliqué qu'un Subversion (ie. git commit/push/pull c'est comme svn commit/update et ça me suffit), soit on avait une utilisation avancée de Subversion et on veut vraiment savoir ce qu'il est possible de faire avec Git et à ce moment là, ça se corse.
Si vous voulez vraiment utiliser Git au-delà du simple commit/push/pull, comprenez d'abord ce qu'est l'index et la différence entre une branche distante et locale. Dans la suite de l'article, lorsqu'on évoquera le dépôt Git, il s'agira de votre dépôt local sauf si spécifié autrement.
L'index
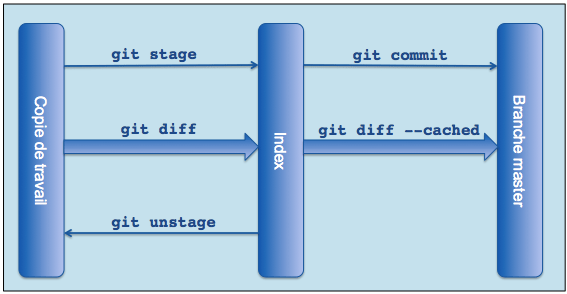
L'index est une zone qui permet de préparer un commit. En effet, un commit n'est créé qu'à partir des modifications ajoutées à l'index. C'est pour cela qu'il faut faire un git add (je préfère git stage qui est un alias à git add que je trouve plus parlant) des fichiers avant d'effectuer un commit. Un fichier a potentiellement 4 états différents (sans même parler de branches et autres fonctionnalités telles que git stash que l'on abordera dans la seconde partie de l'article) dans un même dépôt Git :
- son contenu sur votre copie de travail (on parle de la même copie de travail que celle de Subversion),
- son contenu sur l'index,
- son contenu sur la branche actuelle sur le dépôt local,
- son contenu sur la branche actuelle sur le dépôt d'origine.
Un git stage monfichier met à jour l'état de monfichier sur l'index à partir de l'état de ce fichier dans la copie de travail. Attention toutefois à bien comprendre que git stage ajoute les modifications à l'index au moment où la commande est exécutée. Cela veut dire que si monfichier est modifié après un git stage, ces modifications ne seront pas présentes sur l'index et ne seront donc pas commitées lors du prochain git commit. Ceci nous permet de contrôler finement les modifications que l'on souhaite inclure dans le prochain commit (pour aller plus loin, je vous conseille de tester git stage --interactive : Interactive adding).
Pour retirer les modifications de l'index git unstage monfichier fera l'affaire (unstage n'est pas une vraie commande Git, mais seulement un alias. La liste complète d'alias utilisés est disponible à la fin de l'article).
Un point sur git reset
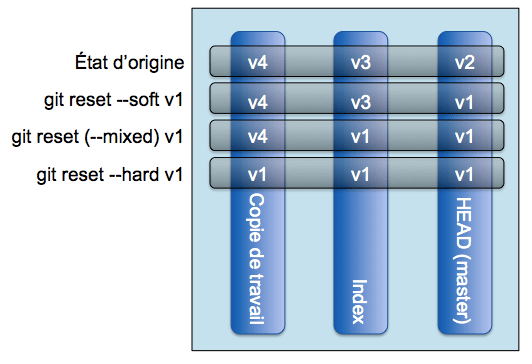
La commande reset permet, entre autre, de "remettre en état" l'index et/ou la copie de travail. Nous l'utilisons principalement pour 3 choses :
un
git reset HEADsupprimera toutes les modifications ajoutées à l'index sans toucher à la copie de travail. C'est l'opération inverse d'ungit stage. HEAD étant la référence sur le commit sur lequel on se trouve actuellement (et que l'on change avecgit checkout).Avec l'option
--harden plus, toutes les modifications de la copie de travail seront elles aussi supprimées : la copie de travail, l'index et la branche en cours seront dans le même état (ie. ce qui est l'équivalent dusvn revertde Subversion).En utilisant une autre valeur que HEAD, cela permet justement de déplacer la HEAD de la branche en cours. Par exemple, pour revenir 3 commits en arrière et donc "oublier" les 3 derniers :
git reset --hard HEAD~3
Pour résumer la commande reset :
- l'option
--softne modifie que la HEAD, - l'option
--mixed(qui est l'option par défaut) modifie la HEAD et l'index, - et enfin, l'option
--hardmodifie la HEAD, l'index et la copie de travail (c'est l'équivalent d'unsvn revertdans Subversion).
Enfin, pour bien suivre les modifications qui sont sur l'index et celles qui n'y sont pas :
git diffcrée un diff entre la copie de travail et l'index,- et
git diff --cachedcrée un diff entre l'index et le dernier commit de la branche actuelle
Les branches locales et distantes
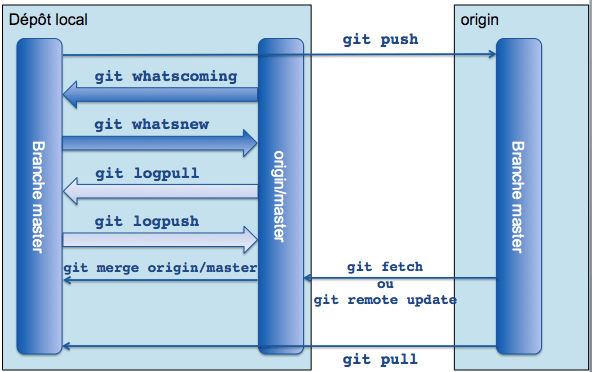
Une autre notion pas toujours bien comprise au départ est qu'une branche d'un dépôt distant (le dépôt origin par exemple qui est le nom du dépôt à partir duquel nous faisons un git clone) n'existe pas forcément dans son dépôt local. Pour être plus précis, un git pull ne créera pas de branches sur lesquelles nous pourrons travailler mais seulement des images de ces branches qui ne seront pas accessibles pour commiter dessus. git branch -r liste les branches distantes alors que git branch ne liste que les branches locales au dépôt :
$ git branch
* master
$ git branch -r
origin/master
origin/integration
Pour pouvoir commiter sur une branche d'un dépôt distant, il faut créer une branche locale qui suit la branche distante :
$ git branch --track integration origin/integration
Dans cet exemple on crée une branche locale integration qui suit la branche integration du dépôt distant origin. Les branches distantes sont nommées ${nom_du_dépôt}/${nom_de_la_branche}. Ainsi, lorsque nous exécuterons un git pull depuis cette branche locale integration, celle-ci sera mise à jour avec les modifications provenant de la branche suivie origin/integration. De même, un git push enverra les modifications locales vers la branche suivie.
Après avoir mis à jour les références des branches distantes avec un git remote update, les alias suivants (cf. l'encadré sur les alias) vous seront utiles :
git logpushlistera les commits qui seront poussés lors du prochaingit push origin $(git currentbranch),git logpulllistera les commits que l'on s'apprête à merger lors du prochaingit pull,git whatsnewdétaillera sous forme d'un diff ce qui va être poussé au prochaingit push origin $(git currentbranch),git whatscomingdétaillera sous forme d'un diff ce qui va être mergé au prochaingit pull.
Oui, Git est efficace et flexible
Avec les notions abordées dans cette première partie, nous verrons dans un deuxième article quelques fonctionnalités qu'offre Git pour gérer le versionnement des sources de son projet et qui en font un outil particulièrement efficace et flexible.
Annexes
Quelques alias utilisés dans l'article
Il suffit d'ajouter dans la section alias du fichier ~/.gitconfig :
...
[alias]
st = status
stp = status --porcelain
ci = commit
br = branch
co = checkout
rz = reset --hard HEAD
pullr = pull --rebase
unstage = reset HEAD
lol = log --graph --decorate --pretty=oneline --abbrev-commit
lola = log --graph --decorate --pretty=oneline --abbrev-commit --all
lpush = "!git --no-pager log origin/$(git currentbranch)..HEAD --oneline"
lpull = "!git --no-pager log HEAD..origin/$(git currentbranch) --oneline"
whatsnew = "!git diff origin/$(git currentbranch)...HEAD"
whatscoming = "!git diff HEAD...origin/$(git currentbranch)"
currentbranch = "!git branch | grep \"^\\*\" | cut -d \" \" -f 2"
...
[color]
branch = auto
diff = auto
status = auto
interactive = auto