La gestion de versions en Delivery de Machine Learning
Cet article fait partie de la suite “Accélérer le Delivery de projets de Machine Learning” traitant de l’application du framework Accelerate dans un contexte incluant du Machine Learning.

Lorsque l’on a des problèmes en production, sans machine à remonter dans le temps, notre seul espoir est d’avoir d’anciennes versions
Introduction
L’une des quatre métriques de performance que propose Accelerate est le temps moyen de correction d’un incident en production (Mean Time to Repair), il s’agit d’une métrique dont le suivi permet d’avoir une idée sur la stabilité du produit développé.
Lorsque l’on introduit un bug en production après une mise à jour, le moyen le plus efficace de réparer ce bug est de revenir à une version antérieure du produit qui ne contenait pas ce bug.
Pour ce faire, il faut avoir mis en place une solution de Gestion de Versions ou Contrôle de Version (Version Control), sujet de cet article, ainsi que l’outillage qui permet de retrouver rapidement un état passé du produit.
La gestion de versions a bien d’autres avantages comme la facilitation de l’audit du produit, ou encore la facilitation du travail à plusieurs en parallèle, et c’est pour toutes ces bonnes raisons que Version Control fait partie des 24 capacités initialement proposées dans le livre Accelerate.
Dans cet article, nous allons aborder la gestion de versions en génie logiciel, puis nous parlerons des raisons pour lesquelles il est primordial de mettre en place cette pratique en Machine Learning, tout en listant ce qui doit être versionné et quelques outils aidant à le faire.
Mais avant cela, commençons par détailler les bienfaits de la gestion de versions.
Pourquoi faire de la Gestion de Versions ?
Comme mentionné en introduction, la gestion de versions a bien des avantages. Elle permet de s’assurer qu’à tout moment, il est possible de :
- Retrouver un état précédent : Si la version de notre produit que l’on a déployée en production ne fonctionne pas, il est possible de revenir à une version précédente (rollback).
- Travailler en équipe et en asynchrone : La gestion de versions permet également de travailler à plusieurs en parallèle, puis de combiner les versions de chacun pour former une nouvelle version.
- Auditer le produit : Savoir quelle version est actuellement en production, et pouvoir naviguer dans l’historique des versions de différentes briques du produit mises en production permet d’analyser et de valider le comportement de ce produit au fil du temps.
- Tracer l’évolution du produit : Avoir plusieurs versions d’une même brique permet de les comparer les unes par rapport aux autres et ainsi visualiser l’évolution passée. Ceci permet entre autres de ne pas refaire les mêmes erreurs et de mieux prédire l’évolution future du produit.
Pour toutes ces bonnes raisons, il est rare de rencontrer un projet de Delivery logiciel qui ne mette pas en place de gestion de versions.
Version control en génie logiciel
Versionner son code est une bonne pratique très connue en génie logiciel. Les outils comme Concurrent Versions System, Apache Subversion ou plus récemment Git, ont fait partie de l’arsenal du développeur logiciel depuis plusieurs décennies.
Si ces outils ont été adoptés, et plus particulièrement Git, c’est parce qu’ils ont permis à plusieurs personnes de travailler sur la même base de code source, de manière asynchrone, puis de fusionner le fruit de ce travail sous la forme de petits incréments que Git appelle commit, en facilitant le retour à une version antérieure d’un fichier en cas de besoin.
Cette pratique de gestion de versions a ensuite été étendue pour aujourd’hui couvrir un grand nombre de briques d’un produit logiciel.
Code applicatif
La première chose à laquelle on pense quand on parle de gestion de versions. L’outil incontournable pour versionner le code applicatif est Git.
Code d’infrastructure
Que ce soit des scripts shell, des rôles Ansible ou des descriptions d’infrastructures Terraform, la gestion d’infrastructure se fait de plus en plus via du code. La gestion de versions de cette Infrastructure as Code peut donc se faire de la même manière que pour le code applicatif, et bénéficier des mêmes avantages.
Configurations
Il n’est pas rare pour un produit logiciel d’être paramétrique pour s’accommoder de différents environnements et s’adapter au plus grand nombre d’utilisateurs. Ces paramètres peuvent être fournis sous la forme de configuration, écrite dans un fichier.
Ces fichiers ayant un impact sur le comportement du produit logiciel, il est important de gérer leurs versions. Là encore, s’agissant de fichiers textuels, il est possible de les versionner de la même façon que le code applicatif.
Documentation
Au fur et à mesure qu’un produit évolue, sa documentation doit également évoluer. Par conséquent la doc doit aussi être versionnée.
Cette documentation prend souvent la forme de textes et d’illustrations, mis en forme dans des fichiers textuels structurés (Markdown, reStructuredText, dans une moindre mesure HTML…), qui se prêtent au version control avec Git.
Parmi les documentations où plusieurs versions sont nécessaires, on peut citer les documentations des bibliothèques logicielles et des langages de programmation.
La documentation du langage Python est un bon exemple. En entête de la page, un menu nous permet de facilement naviguer entre les différentes versions de la documentation, liées aux différentes versions du langage.
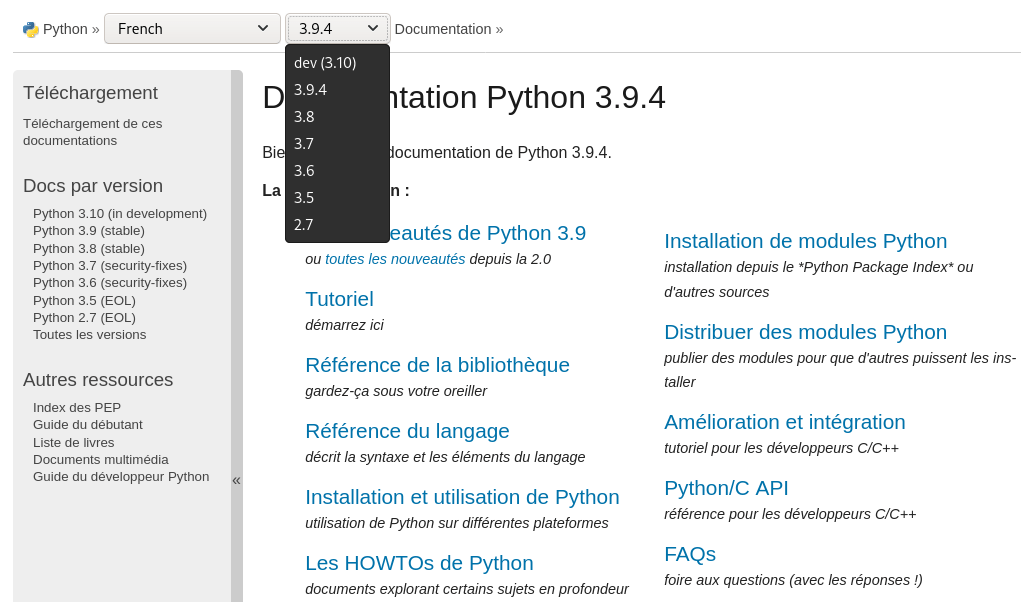
La documentation du langage de programmation Python et ses multiples versions
Schémas de base de données
Quand une application a besoin de stocker et accéder à des informations, elle est souvent accompagnée d’une base de données. Les bases de données relationnelles sont les plus courantes. Dans ces bases, les données sont rangées dans des structures tabulaires, les contenus, formes et contraintes imposées à ces structures forment ce que l’on appelle un schéma.
Le code d’une application est très fortement couplé aux schémas des bases de données avec lesquelles il interagit. De ce fait, lors d’une modification du schéma, le code doit évoluer en conséquence et vice versa.
Mais que se passe-t-il si le code est rollback a une version antérieure ? Le schéma de base de données doit lui aussi subir un retour en arrière.
Il existe des outils permettant d’effectuer ces opérations sans trop de douleurs, on peut par exemple citer Alambic, outil compagnon de l’ORM (Object-Relational Mapping) SQLAlchemy.
Artefacts construits
Avant d’être déployé, le code d’une application est souvent transformé en un objet qui encapsule tout ce dont le logiciel a besoin. Cet objet est appelé artefact, et est souvent un produit de pipeline de CI/CD.
Le type de cet artefact varie d’un projet à l’autre, il peut s’agir d’une archive (fichiers JAR en Java, wheel en Python…), de bibliothèques compilées (fichiers .so ou .dll en C), ou encore d’images Docker.
Ces artefacts faisant le lien entre le code et la production, il est primordial de gérer leurs versions. Là encore, il existe des outils faits pour cela (les dépôts d’artefacts comme Nexus ou Artifactory, les dépôts d’image Docker comme DockerHub…).
Données utilisées pour les tests
La gestion des données de test peut représenter un défi important. Une des 24 capacités du livre Accelerate traite d’ailleurs ce sujet, et un article de cette série lui sera consacré.
Si ces pratiques de gestion de versions s’appliquent au cas par cas selon le produit, les produits contenant des briques de Machine Learning ont des spécificités qui ajoutent de nouveaux objets que l’on doit obligatoirement versionner.
Version Control en Machine Learning
La nature stochastique des modèles de Machine Learning, et le pan d'expérimentation important de la discipline, demandent une attention particulière à la reproductibilité des résultats, tout en gardant un registre, accessible et lisible, de ce qui marche et ce qui marche moins.
Ces enjeux de reproductibilité sont aussi au cœur des questions d’audit de produits incluant une fonctionnalité basée sur du Machine Learning.
Il est également à prendre en compte que les modèles de ML ont aussi un cycle de vie. Des modèles ré-entraînés, ou même d’autres modèles, sont appelés à remplacer ceux en production, ce qui peut dans certains cas conduire au déploiement d’une version défectueuse, et donc requérir le redéploiement d’une version antérieure fonctionnelle.
Pour bien appréhender ce qui doit être versionné quand on fait du ML, il est possible de commencer par lister les dépendances de la finalité de toute brique Machine Learning : une prédiction en production.
Une prédiction réalisée à l’aide de ML peut dépendre de plusieurs facteurs :
- Le code d’inférence
- La configuration éventuelle de ce code d’inférence
- Les données sur lesquelles on veut prédire
- Le modèle entraîné
Le modèle entraîné dépend lui des éléments suivants :
- Le code d’entraînement
- Les hyper-paramètres du modèle à entraîner
- L’échantillon de données utilisé pour l’entraînement
Ceci peut être résumé grâce au diagramme de dépendance suivant :
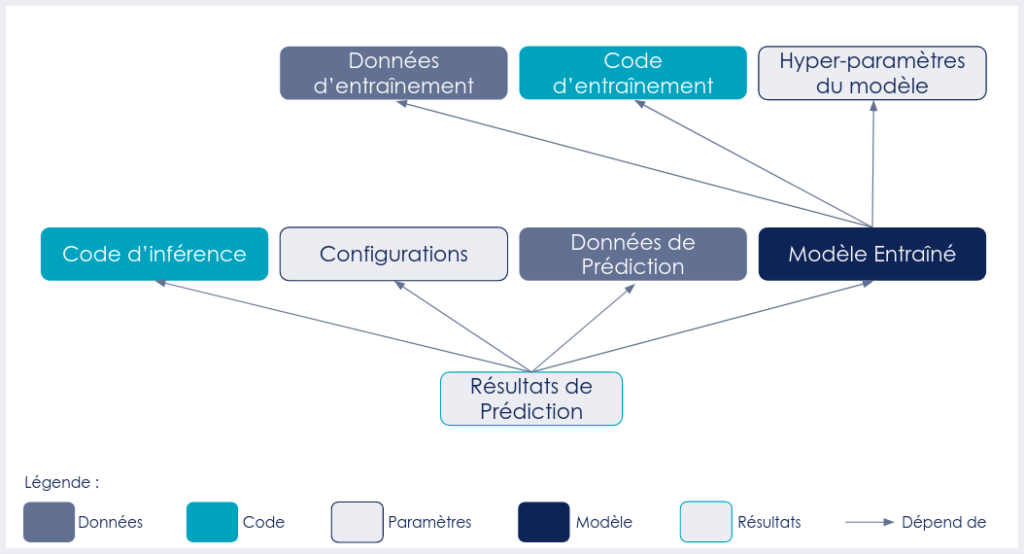
Diagramme de dépendance d’une prédiction
Pour répondre aux besoins de reproductibilité et gestion de cycle de vie des modèles, il est donc primordial de versionner.
Codes et configurations
Le Delivery (voir ici pour la définition) de produit contenant une brique de Machine Learning est du Delivery logiciel. Le code représente donc une grande partie de la logique du produit, et doit être versionné. L’outil de prédilection reste Git.
Cependant il est important de noter que beaucoup de code en Machine Learning (et pas que) est écrit sous forme de Notebooks, dont la saveur la plus utilisée est celle de Jupyter.
Capture d’écran d’un Jupyter Notebook
Ce format possède les avantages d’être interactif, pratique pour les présentations, et simple à prendre en main. Malgré cela, il est décrié pour un grand nombre de raisons, certaines citées par Joel Grus lors de son célèbre talk « I don’t like notebooks » à la JupyterCon de New York en 2018.
Parmi les raisons pour lesquelles les Jupyter Notebooks ne sont pas appréciés, celle qui nous intéresse dans cet article est le format de fichier ipynb.
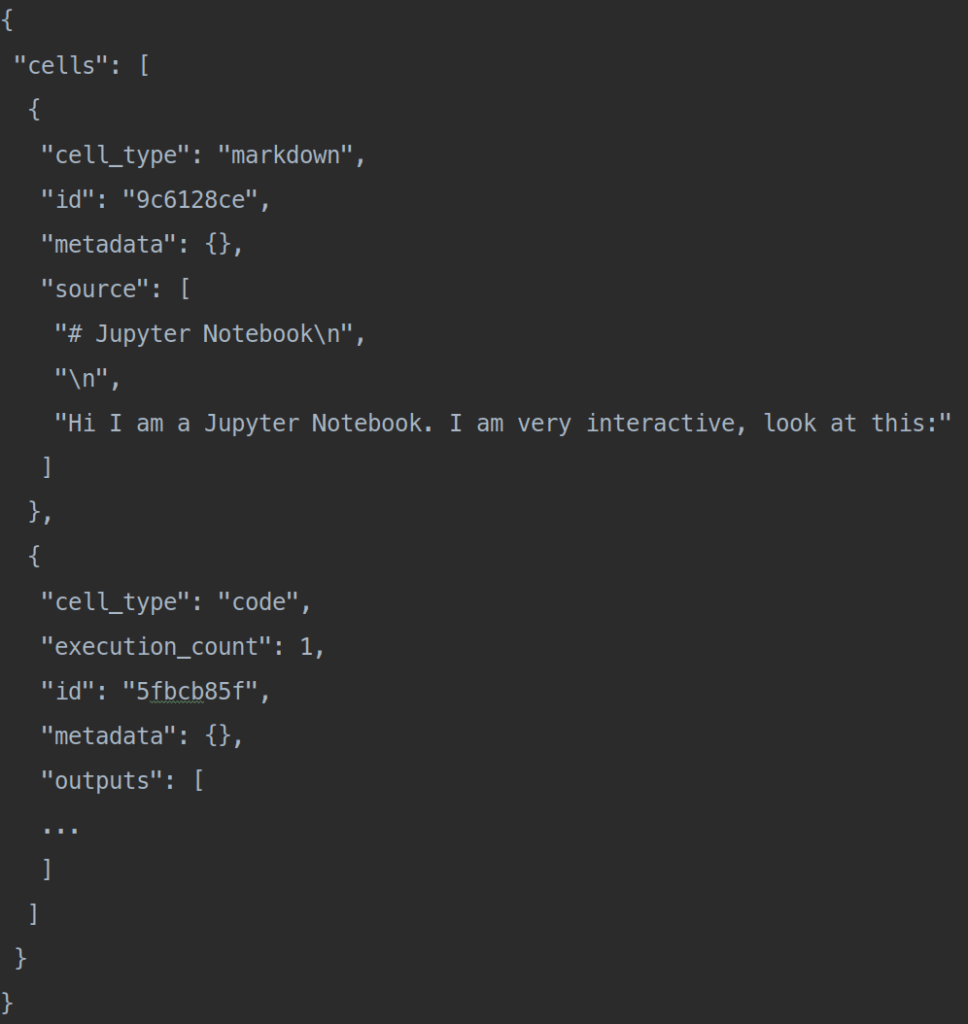
Un extrait du même Jupyter Notebook mais ouvert avec un éditeur de texte
Ce format peut certes être versionné à l’aide de Git, mais son contenu n’est pas fait pour être lisible par un être humain, ce qui rend les tâches de comparaison (diff) ou de jointure (merge) entre différentes versions très difficiles.
Il est préférable pour cette raison (et bien d’autres) d’éviter ce format de fichier, et privilégier des formats textuels purs pour la rédaction de code, y compris pour les expérimentations.
Des alternatives interactives existent, on peut citer le « Scientific mode » de l’édition Professional de PyCharm, ou encore les Notebooks Databricks. Ces alternatives sont payantes, mais font partie de solutions plus globales.
En dernier ressort, l’utilisation des Jupyter Notebooks doit être limitée au strict minimum, et leurs contenus doivent être extraits le plus rapidement possible pour aller peupler des packages et modules Python, mieux adaptés aux bonnes pratiques de développement, dont la gestion de versions.
Note : Bien que non abordés ci-dessus, les Zepplin Notebooks et bien d’autres sont malheureusement tout aussi mal adaptés au Delivery.
Échantillons de données (Datasets)
Note : En ML, il est possible de distinguer deux types d’échantillons de données à versionner :
- Les données utilisées pour les tests logiciels
- Les données utilisées pour entraîner et évaluer les modèles de Machine Learning
La suite se concentre sur le second type, mais les mêmes méthodes de gestion de versions peuvent s’appliquer sur le premier.
Comme mentionné précédemment, le résultat de l’entraînement d’un modèle dépend de ses hyper-paramètres, du code utilisé pour l’entraîner, ainsi que des données qui lui ont été fournies en entrée.
En ce qui concerne l’évaluation d’un modèle, les facteurs influant sur les valeurs des métriques sont essentiellement le code d’évaluation et les données utilisées pour son évaluation.
De là il est évident que les échantillons de données qui ont servi à entraîner ou évaluer un modèle doivent être versionnées.
Il est tentant d’une fois encore se reposer sur Git pour cette gestion de versions. Malheureusement il n’est pas pensé pour gérer les fichiers volumineux qui constituent les échantillons de données souvent utilisés en ML.
Cependant, Git étant un outil très largement connu, dont les opérations semblent correspondre à ce que l’on aimerait faire pour versionner les données (commit, retour en arrière, branches…), plusieurs outils proposent de se greffer à Git pour gérer des fichiers volumineux, tels que Git Large File Storage (Git LFS) ou Data Version Control (DVC), tandis que d’autres préfèrent imiter Git sans y être liés comme LakeFS.
Important : Quel que soit l’outil utilisé, si les données manipulées sont des données personnelles, il faut être capable de supprimer les informations liées à un individu, s’il le désire, et ce de toutes les versions des échantillons de données stockées.
Plus globalement, il est pertinent et responsable de mettre en place des délais de rétention des échantillons versionnés, tant d’un point de vue écologique ou d’un point de vue économique.
Pour les données personnelles, le règlement général sur la protection des données (RGPD), impose de définir une durée de conservation maximale, selon la finalité du traitement. Ce guide de la CNIL peut aider à définir cette durée de conservation.
Exemple d’utilisation de DVC
Pour illustrer la gestion de versions de données, prenons le cas du fichier CSV (Comma Separated Values) suivant
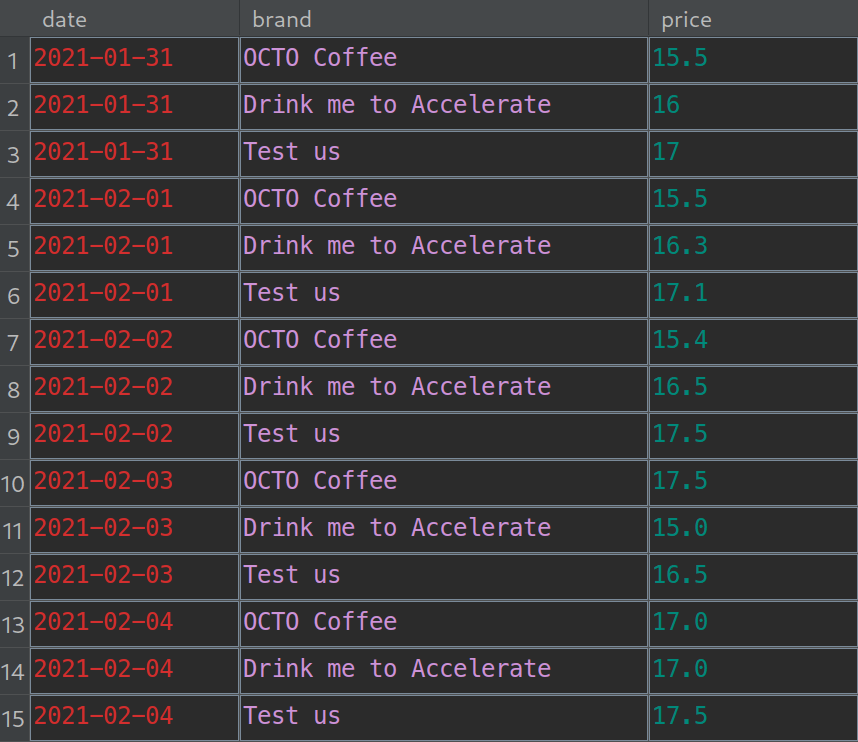
Fichier CSV des évolution du prix du café par marque au fil du temps
Supposons que le fichier ci-dessus, nommé coffee_prices.csv, se trouve dans le répertoire data/train_data de notre projet.
Installation et initialisation de DVC
La première chose à faire est de s’assurer que le projet est versionné avec Git, car DVC s’appuie dessus pour fonctionner.
Une fois cette vérification faite, il faut installer DVC. Ceci peut se faire dans notre environnement python favori, via la commande :
pip install dvc
L’installation terminée, il faut communiquer à DVC que le dépôt Git contient des données à versionner avec des commandes DVC. Pour ça, similairement à une initialisation d’un dépôt de code Git, la commande à exécuter est :
dvc init
Cette commande va ajouter au projet un répertoire caché .dvc et un fichier caché .dvcignore, qu’il ajoute à la liste des fichiers suivis et versionnés par Git.
Le répertoire .dvc contient les fichiers de configuration qu’utilise DVC en interne. Principalement le fichier config qui pour l’instant est vide.
Le fichier .dvcignore quant à lui est similaire au fichier .gitignore, il peut contenir des schémas de noms de fichiers ou de répertoires que DVC doit ignorer.
Il est d’usage de commiter les fichiers créés à cette étape
git commit -m "Initialize DVC"
Ajouter de la donnée à versionner avec DVC
Cette première étape effectuée, nous pouvons indiquer à DVC que le fichier coffee_prices.csv est à versionner avec la commande :
dvc add data/train_data/coffee_prices.csv
DVC va alors créer un fichier .gitignore dans le même répertoire que le fichier à versionner, et va y ajouter coffee_prices.csv, communiquant ainsi à Git qu’il n’est pas chargé de versionner ce fichier.
Il va aussi créer un fichier coffee_prices.csv.dvc, au format YAML. Dans ce fichier, DVC va stocker des informations sur le fichier de données versionné. Parmi ces informations on retrouve un hash MD5 du fichier, sa taille, ainsi que son chemin.
Une fois que la commande finit son exécution, elle affiche un message conseillant d’ajouter le nouveau .gitignore ainsi que le fichier coffee_prices.csv.dvc aux fichiers versionnés par Git, en lançant la commande :
git add data/train_data/coffee_prices.csv.dvc data/train_data/.gitignore
C’est de cette façon que DVC versionne les fichiers de données, il crée un fichier qui décrit la donnée à un moment T et demande à Git de versionner cette description. L’étape suivante est de commiter ces fichiers :
git commit -m "Add coffee_prices.csv data"
Mettre à jour et versionner la donnée
Pour illustrer le changement des données, ajoutons une ligne de données au fichier avec la commande :
echo "\n2021-02-05,OCTO Coffee,18.0" >> data/train_data/coffee_prices.csv
Si on lance la commande
dvc status
DVC nous indique que le fichier a changé. Pour versionner ces changements :
dvc add data/train_data/coffee_prices.csv
git commit -am "Add feb 5th data to the coffee_prices"
Le retour à une version précise des données se fait aussi grâce à un mélange de git et de DVC. Si on veut par exemple retourner à la version initiale des données au moment de l’insertion, il suffit de récupérer le hash du commit dont le message est « Add coffee_prices.csv data » et de lancer les commandes suivantes :
git checkout data/train_data/coffee_prices.csv.dvc
dvc checkout
Le fichier est de retour à son état initial.
Configurer un remote storage et y pousser les versions de la donnée
Comme mentionné plus tôt dans l’article, l’un des intérêts est de pouvoir travailler sur l’objet versionné à plusieurs.
Les données versionnées par DVC, à l’image du code versionné par Git, sont partagées via des serveurs distants appelés remotes.
DVC peut utiliser une large panoplie de services de stockage comme remote, allant du répertoire Google Drive, au système de fichiers distribué Hadoop (HDFS).
Dans l’exemple nous allons utiliser un répertoire local en tant que remote /tmp/coffee_data/.
Pour indiquer à DVC que ce répertoire sera notre remote, il suffit de lui trouver un nom, par exemple tmp-remote, puis de lancer la commande suivante :
dvc remote add -d tmp-remote /tmp/coffee_data/
Note : l’argument
-dest un raccourci de--defaultqui signifie que ce remote sera le remote par défaut.
Cette commande, une fois lancée, change le contenu de la configuration de DVC (le fichier .dvc/config) pour y mentionner tmp-remote et son chemin :
[core]
remote = tmp-remote
['remote "tmp-remote"']
url = /tmp/coffee_data
Finalement pour pousser les données vers le remote, il suffit d’exécuter la commande :
dvc push
Seule la version actuelle des données est alors envoyée vers le remote.
Si on veut téléverser toutes les versions de la donnée, la commande dispose d’un paramètre pour cela
dvc push –all-commits
Aller plus loin avec DVC
Pour continuer à mettre le pied dans l’étrier avec DVC, l’équipe de mainteneurs propose des vidéos d’introduction sur leur chaîne YouTube DVCorg. Pour aller plus loin, la documentation du projet est la meilleure source d’information, où chaque commande est détaillée avec des exemples d’utilisation.
Hyper-paramètres des modèles
En plus du code et des données, la dernière brique à versionner pour assurer la reproductibilité d’un entraînement de modèle est la liste des hyper-paramètres de ce dernier.
Il est possible de considérer les hyper-paramètres d’un modèle comme faisant partie du code, ou d’un fichier de configuration paramétrant le code, et donc d’utiliser Git pour en gérer les versions.
Même si ce n’est pas une mauvaise approche, versionner les hyper-paramètres d’un modèle de cette façon peut polluer l’historique de versions du code, avec un très grand nombre de combinaisons d’hyper-paramètres de modèles.
En outre, les combinaisons d’hyper-paramètres et de données ne font sens que si elles sont accompagnées de métriques les évaluant. Cela peut être fait en utilisant un tableur, mais cette solution n’est pas idéale car seuls les tableurs en ligne permettent la collaboration au sein d’une équipe, et le tenir à jour requiert soit des tâches manuelles accompagnées d’une discipline de fer, ou le développement/usage d’une brique permettant d’insérer automatiquement les hyper-paramètres et résultats à chaque changement.
C’est là qu’interviennent les outils de suivi d’expérimentations, qui proposent d’implémenter cette logique de tableur dans lequel viennent s’insérer, de façon quasi-automatique, les hyper-paramètres et les métriques obtenues, en ajoutant parfois des visualisations pour comparer les différents résultats.
Parmi ces outils, on retrouve DVC qui, depuis sa version 2, met l’accent sur le suivi des expérimentations. On trouve également d’autres outils qui le font depuis un peu plus longtemps tels que Aim, Comet.ML ou encore MLflow.
Exemple d’utilisation de MLflow Tracking pour suivre les expérimentations
MLflow est un projet Open Source de gestion de cycle de vie de produits ML. Il propose 4 composants :
- MLflow Projects : Une solution de packaging de projets Data Science
- MLflow Models : Un format standard pour le packaging, déploiement et mise à disposition de modèles de Machine Learning.
- Model Registry : Un composant particulièrement bien nommé servant de registre centralisé pour des modèles de Machine Learning (nous y reviendrons dans le chapitre suivant)
- MLflow Tracking : Un outil de suivi d’expérimentations que nous allons utiliser dans cet exemple
Nous avions déjà parlé de MLflow sur ce blog il y a bientôt 2 ans, nous allons reprendre les éléments clé de cet article, en ajoutant des détails sur le lien entre expérimentations, données et code.
Reprenons nos données de prix des différentes marques de café au fil du temps et essayons de prédire le prix du café à une date précise.
Dans cet exemple, par soucis de simplicité, nous allons utiliser un DummyRegressor de scikit-learn avec la stratégie quantile. Ceci nous donne un seul hyper-paramètre pour notre modèle à savoir le quantile des données d’entraînement, que le modèle retournera en prédiction.
Pour démarrer, partons de ce code Python :
def train_model():
coffee_prices = pd.read_csv('data/train_data/coffee_prices.csv')
coffee_prices['date'] = pd.to_datetime(coffee_prices['date']).astype(int)
label_encoder = LabelEncoder()
coffee_prices['encoded_brand'] = label_encoder.fit_transform(coffee_prices['brand'])
train_features, test_features, train_target, test_target = train_test_split(
coffee_prices[['date', 'encoded_brand']],
coffee_prices['price'],
test_size=0.25,
random_state=23
)
dummy_model = DummyRegressor(strategy="quantile", quantile=np.random.random())
dummy_model.fit(train_features, train_target)
score = dummy_model.score(test_features, test_target)
print(score)
Cette fonction permet de :
- Charger les données,
- Effectuer quelques transformations (date en entier, et marque en catégories),
- Découper en échantillon d’entraînement et d’évaluation (de façon répétable),
- Entraîner un modèle,
- Évaluer le modèle précédemment entraîné.
Voyons maintenant comment suivre les expérimentations à l’aide de MLflow.
Installation et lancement de la Tracking UI
Tout d’abord il faut installer et instancier la brique Tracking de MLflow.
Plusieurs façons de le faire, soit en local uniquement, soit avec un serveur qui centralise les expérimentations de plusieurs personnes.
L’utilisation étant similaire dans les deux cas, dans la suite nous allons instancier MLflow en local.
L’installation se fait via pip avec la commande :
pip install mlflow
L’étape suivante est de lancer la commande :
mlflow ui --backend-store-uri sqlite:///mlflow.db
L’exécution de cette commande la première fois entraînera la création d’une base de données SQLite qui contiendra toutes les données de suivi des expérimentations.
Note : La même commande, sans indiquer de paramètre de
backend-store, considère que les données de suivies sont des fichiers plats et se trouvent dans un répertoire nommémlruns, situé dans le répertoire de travail ou a été lancé la commande. L’utilisation d’une base de données sera justifiée un peu plus tard, lorsque nous parlerons de registre de modèles.
Une fois la base de données créée, le commande lance la Tracking UI. En visitant la page http://localhost:5000 sur un navigateur, la page de la l’interface de suivi des expérimentations s’affiche.
![]()
Tracking UI vierge
Suivi des expérimentations sur MLflow
La Tracking UI étant prête, il faut maintenant apporter quelques modifications au code Python de la pipeline d’entraînement
CODE_VERSION = version('version_control')
mlflow.set_tracking_uri('http://localhost:5000/')
def train_model():
data_path = 'data/train_data/coffee_prices.csv'
coffee_prices = pd.read_csv(data_path)
coffee_prices['date'] = pd.to_datetime(coffee_prices['date']).astype(int)
label_encoder = LabelEncoder()
coffee_prices['encoded_brand'] = label_encoder.fit_transform(coffee_prices['brand'])
features = ['date', 'encoded_brand']
target = 'price'
train_features, test_features, train_target, test_target = train_test_split(
coffee_prices[features],
coffee_prices[target],
test_size=0.25,
random_state=23
)
Sur cette première partie, il n’y a pas beaucoup de changements. Une constante contenant la version du projet a été ajoutée, et certaines valeurs passées à des fonctions directement ont été extraites dans des variables : data_path, features, et target.
with mlflow.start_run():
mlflow.log_param('code_version', CODE_VERSION)
data_url = dvc.api.get_url(data_path)
mlflow.log_param('data_url', data_url)
mlflow.log_param('features', features)
mlflow.log_param('target', target)
quantile_parameter = np.random.random()
mlflow.log_param('quantile', quantile_parameter)
dummy_model = DummyRegressor(strategy="quantile", quantile=quantile_parameter)
dummy_model.fit(train_features, train_target)
mlflow.sklearn.log_model(dummy_model, 'coffee_price_estimator')
score = dummy_model.score(test_features, test_target)
mlflow.log_metric('score', score)
La seconde partie du code voit l’introduction de l’utilisation de la bibliothèque mlflow.
Au tout début, pour marquer le début de ce que l’on considère être une expérimentation, on ouvre un context manager mlflow.start_run().
La ligne de code suivante nous permet de commencer à inscrire des informations sur le contexte dans lequel a été exécuté cette expérimentation. Il s’agit ici de sauvegarder quelle version du code a été utilisée pour effectuer l’expérimentation.
MLflow récupère déjà automatiquement le hash du commit Git pour le lier à l’expérimentation. Cependant il n’est pas rare de vouloir déployer le code d’entraînement sous la forme d’un package Wheel où le hash de commit est perdu.
Après cela, on utilise l’api Python dvc.api pour obtenir le chemin où se trouve notre fichier de données sur le remote. Ce chemin est ensuite sauvegardé comme paramètre de l’expérimentation.
Une bonne pratique est de toujours sauvegarder quelles caractéristiques ont été utilisées pour prédire une cible, qui doit elle aussi être sauvegardée.
Ceci permettant de distinguer les caractéristiques discriminantes des caractéristiques apportant moins de signal, ainsi que d’éviter des ambiguïtés lorsque l’on a plusieurs cibles possibles (par exemple : prédiction à 1 jour Vs prédiction à 5 jours).
Cette information est écrite dans le code, mais l’avoir dans MLflow est plus pratique car elle apparaitra sur la Tracking UI, ce qui permet de comparer les expérimentations sans avoir à regarder le code, en particulier si ce dernier n’évolue pas entre les expérimentations comparées.
Le dernier paramètre que l’on veut tracer dans MLflow est l’unique hyper-paramètre de notre modèle : le quantile.
Une fois le modèle entraîné, on le sauvegarde au sein de cette expérimentation, et ce grâce à l’API mlflow.sklearn car notre modèle est un issu de la bibliothèque scikit-learn.
MLflow gère la majorité des bibliothèques de ML telles que TensorFlow, PyTorch, ou encore XGBoost.
Finalement, après que le modèle soit évalué, le résultat est enregistré en tant que métrique associée à l’expérimentation. Dans notre cas, il n’y a qu’une seule métrique, mais rien ne nous empêche d’en utiliser plusieurs.
On peut maintenant exécuter cette fonction plusieurs fois, ce qui se rapporterait à faire un random search pour optimiser l’hyper-paramètre quantile.
Le résultat obtenu sur la Tracking UI est montré sur la capture d’écran suivante
![]()
Tracking UI après 3 runs
Il est possible de cliquer sur l’une des dates de début pour afficher la page détaillée de l’expérimentation (run), ou encore d’en sélectionner deux ou plus et d'utiliser l’option compare pour accéder à la vue de comparaison.
MLflow tracking propose un très grand nombre de fonctionnalités, et pour aller plus loin la documentation officielle est un bon point de départ.
Modèles entraînés
Une fois un modèle entraîné, s’il passe un certain nombre de tests de performances et d’intégration avec le reste du produit, il est destiné à être déployé en production, remplaçant l’un de ceux qui y sont déjà.
Si malheureusement ce modèle ne se comporte pas comme prévu en production, avoir la capacité de revenir rapidement à la version précédente du modèle est primordiale.
Pour cela, une solution serait de se baser sur les expérimentations faites pour recréer le modèle qui était en production et le redéployer, mais cette façon de faire a deux inconvénients majeurs.
Le premier est que dans les expérimentations, il faut avoir une trace de quel modèle était en production à quel moment, c’est faisable dans certains outils en ajoutant un tag à une expérimentation qui dit que le modèle résultant de celle-ci a été mis en production de tel moment à tel moment, et automatiser cette inclusion dans le pipeline de déploiement.
Le second inconvénient est que certains modèles peuvent mettre plusieurs semaines à s’entraîner. Sans parler de l’impact environnemental et financier, ce temps d’entraînement est autant de temps passé avec une production non-fonctionnelle.
Dès lors, il semble logique de vouloir disposer d’un registre de versions de modèles entraînés, qui ont vocation à être déployés en production.
Commodément, MLflow propose une brique permettant de faire exactement cela.
Exemple d’utilisation de MLflow Model Registry comme registre de modèles
On peut remarquer en entête de la Tracking UI l'existence de deux onglets, le premier nommé Experiments que nous avons exploré, et un second nommé Models, qui va nous servir à visualiser le registre de modèle.
Pour utiliser cette fonctionnalité, il est nécessaire d’avoir déclaré un backend-store de type base de données.
Pour promouvoir un modèle d’une expérimentation au registre de modèles, le moyen le plus simple est de passer par la vue détaillée d’une expérimentation, à laquelle on accède en cliquant sur la date et l’heure du début (Start Time) correspondant dans la vue Experiments.
Haut de page de la vue détaillée d’une expérimentation
En bas de la même page, se trouve la section Artifacts qui contient les informations sur le modèle entraîné, enregistré à la fin de l’expérimentation.
C’est dans cette section que se trouve la fonctionnalité qui nous intéresse. Le bouton Register Model nous permet de promouvoir ce modèle à un registre de modèle particulier.
Bas de page de vue détaillée d’une expérimentation avec le bouton Register Model
Cliquer sur ce bouton produit une boîte de dialogue modale demandant dans quel registre de modèle le résultat de cette expérimentation doit être enregistré.
À l’heure actuelle aucun registre n’existe, on peut choisir de créer un registre grâce à l’option Create New Model.
Boîte de dialogue modale d’enregistrement registre de modèle
Après avoir nommé notre nouveau registre de modèle et cliquer sur le bouton Register, nous avons notre première version du modèle ajoutée au registre.
Nous pouvons nous en assurer sur la vue Models
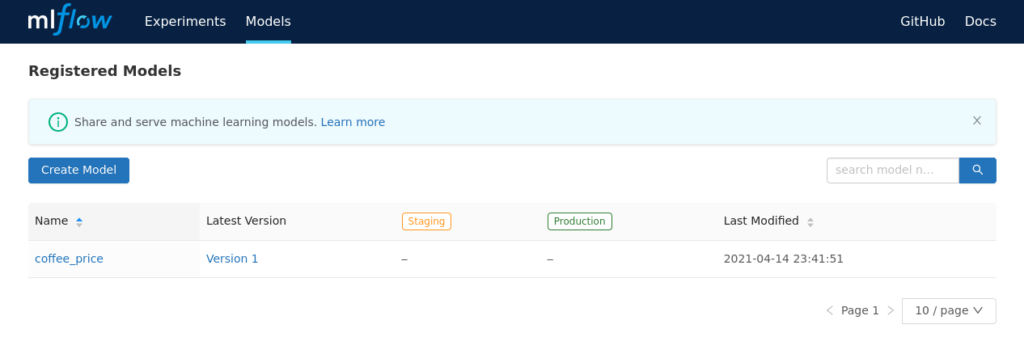
Vue Models avec un nouveau registre appelé coffee_price
La vue Models nous permet de gérer les différents registre de modèles que l’on peut avoir, de marquer quelle version est en test et quelle version est en production pour chacun d’entre eux. La vue détaillée d’une version précise de quel expérimentation est issue le modèle, et bien plus.
Pour explorer plus en profondeur les registre de modèles MLflow, là encore le meilleur point d’entrée est la documentation officielle.
TL;DR
Pour résumer en Machine Learning, il est recommandé de versionner :
- Codes et configurations
- Échantillon de données
- Modèles entraînés
Et de suivre les expérimentations, concluantes pour permettre de voir ce qui a marché et se baser dessus pour s’améliorer, et non concluantes pour ne pas répéter les erreurs du passé.
Conclusion
La gestion de versions est l’une des bonnes pratiques les plus utilisées en génie logiciel, en rédaction (Documents LaTeX à l’aide de Git, présentations à l’aide de Google Slides…) mais aussi en Machine Learning.
Il est d’usage de versionner en Delivery de produit contenant une brique ML : le code, les données, et les modèles. En se basant sur ces trois éléments il est conseillé de suivre les expérimentations effectuées en s'assurant de la reproductibilité de celles-ci.
Cette pratique tend à se normaliser, y compris dans le domaine de la recherche en Machine Learning, où le problème de la reproductibilité se pose de plus en plus, au point où des chercheurs mettent en place des outils pour signaler et lister les publications non reproductibles.
Beaucoup de bibliothèques et de frameworks se positionnent sur le sujet en proposant de couvrir partiellement ou entièrement ces besoins : DVC, MLflow, LakeFS, Aim, CometML… et bien d’autres.
Le choix du « bon » outil dépend de l’environnement, mais aussi des préférences de chacun. Il existe des comparaisons entre certains d’entre eux, mais la meilleure façon de se faire un avis reste de parcourir leurs documentations.