Gestion de version distribuée et build incassable
Dans un précédent article, nous avons introduit les concepts qui accompagnent la gestion de versions distribuée afin de comprendre son fonctionnement de base. À l'aide de ces quelques concepts, nous allons voir comment il est possible de mettre en place un build d'Intégration Continue "incassable" sans effort (ie. sans développement d'une infrastructure dédiée : avec un gestionnaire de versions non distribué celà reste possible avec un peu de développement ou avec encore avec la solution TeamCity de JetBrains) grâce à la flexibilité de ce type d'outils. Git continuera à nous servir d'exemple mais cette fois-ci, les détails d'implémentation (en comparaison avec Mercurial ou Bazaar) auront leur importance dans la mise en place de la solution. Mais avant de présenter la solution, revenons sur le principe du build incassable. Le build incassable fait référence au build automatique qui s'exécute sur un serveur d'Intégration Continue. Ce build consiste à compiler, déployer et tester une application en cours de développement et est exécuté régulièrement en surveillant les modifications dans le gestionnaire de versions.
Aujourd'hui lorsqu'on utilise un gestionnaire de versions centralisé, le développeur partage ses modifications de l'application (commit avec Subversion) en les envoyant sur le dépôt central utilisé par tous les développeurs et le système d'Intégration Continue. Si le build échoue, l'Intégration Continue notifie l'ensemble des développeurs qui ont partagé leurs modifications que l'état des sources dans le gestionnaire de versions n'est pas stable. Ceci permet de savoir rapidement qu'il y a quelque chose à corriger dans l'application avant de démarrer une autre fonctionnalité. Plus le problème est découvert tôt, moins il prendra de temps à corriger (Principe exposé par Martin Fowler dans son article l'intégration continue). Cette utilisation de l'Intégration Continue apporte beaucoup à l'amélioration de la qualité des applications mais il reste encore quelques faiblesses à cette procédure.
En effet, entre le moment où un développeur partage ses modifications et le moment où le build échoue, il peux se passer un certain temps (temps de détection des modifications + temps du build qui peut être plus ou moins long) pendant lequel les autres développeurs peuvent mettre à jour leur copie de travail et ainsi la rendre instable (problème de compilation, tests en échec, ...). La deuxième faiblesse est qu'une fois que l'Intégration Continue a notifié les développeurs que la version de l'application dans le gestionnaire de sources est invalide, ils ne peuvent plus envoyer leurs modifications (il est en général recommandé de mettre à jour sa copie de travail en résolvant les conflits de merge avant d'envoyer ses modifications) sous peine de récupérer la version instable et ceci tant que le build n'est pas corrigé. Cela les conduit soit à créer une version plus volumineuse qui contiendra plusieurs fonctionnalités, soit à mettre à jour leur copie de travail malgré les erreurs de build.
Malgré les apports indéniables de l'Intégration Continue, celle-ci reste bridée par le fait que les versions non testés des développeurs et la version testé et considérée stable par l'Intégration Continue sont mélangées dans une seule et même branche du gestionnaire de versions. Le build incassable n'est donc pas un build qui n'échoue jamais mais un build qui assure que toutes les versions de l'application disponibles dans le gestionnaire de sources sont saines.
Principe de la solution
Le coeur de la solution de build incassable que nous allons voir permet de séparer les versions partagées par les développeurs de la version stable depuis laquelle se font les mises à jour des copies de travail des développeurs.
Comme expliqué dans le premier article, avec un gestionnaire de versions décentralisé, il est possible d'imaginer toute sorte de topologie des dépôts. Nous utiliserons donc un dépôt centralisé en plus du dépôt par développeur. Ce dépôt centralisé aura de particulier de posséder une branche par développeur. Ces derniers enverront leurs modifications (push avec Git) sur leur branche personnelle sur le dépôt central (cf étape 1 du schéma). Si un développeur casse le build avec ses modifications, il ne cassera que sa branche dans le dépôt central.
Il reste encore à positionner l'Intégration Continue dans ce système, et puis c'est bien beau d'avoir sa branche personnelle, mais où sont consolidées les modifications des développeurs ? ie. où est la version de l'application qui contient l'ensemble des modifications des développeurs ? À notre dépôt central, nous ajouterons donc une branche supplémentaire qui contiendra la consolidation de toutes les branches des développeurs. C'est l'Intégration Continue qui se chargera de merger les branches de chaque développeur vers cette branche de référence. 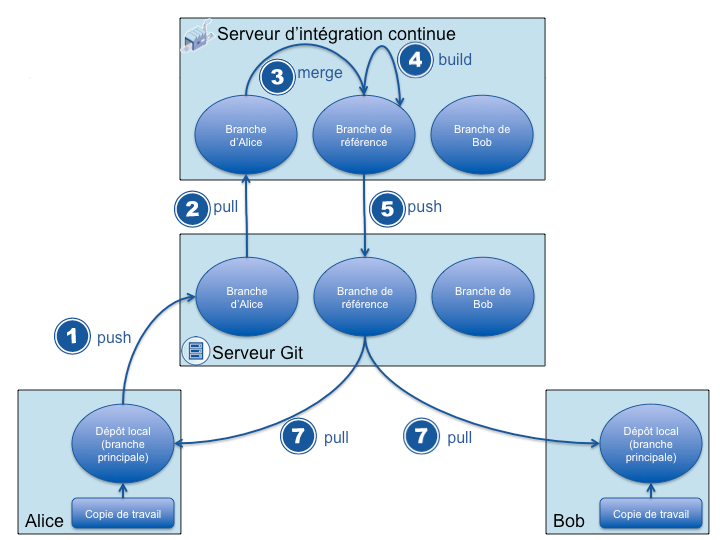
Voyons comment se comporte ce système dans les deux situations décrites comme des limites précédemment :
- Un développeur partage des modifications qui vont faire échouer le build. Comme il les partage sur sa branche personnelle sur le dépôt central, aucun des autres développeurs n'est impacté. Ils vont en effet mettre à jour leur dépôt (et copie de travail) depuis la branche de référence qui n'est pas modifiée tant que le build du développeur n'est pas stable.
- Les autres développeurs peuvent partager leurs modifications car un build qui échoue sur une branche d'un développeur n'empêche pas d'effectuer un build des autres branches et de continuer à faire évoluer la branche de référence.
Une source supplémentaire d'échec du build apparait cependant. En effet, si un développeur partage ses modifications avant d'avoir mis à jour sa copie de travail (ou si un autre build est en cours), le build de sa branche peut échouer à cause de conflits qui apparaissent lors du merge dans la branche de référence (étape 3). Dans ce cas, il faudra au développeur mettre à jour sa copie de travail depuis la branche de référence, résoudre les conflits et renvoyer ses modifications. Le reste de l'équipe n'est pas impacté par les erreurs de merge, de la même manière qu'il n'est pas impacté par les erreurs de build.
Un dernier avantage, qui n'est pas si négligeable qu'il n'y parait, est que lorsqu'un build échoue, l'Intégration Continue "connait" de façon certaine le développeur incriminé : celui à qui appartient la branche à partir de laquelle le build a été initié. Elle peut alors notifier uniquement ce développeur et non pas tous les développeurs ayant potentiellement cassé le build comme c'est le cas aujourd'hui (ie. tous les développeurs qui ont partagé des modifications depuis le dernier build en succès). C'est un avantage non négligeable car une des raisons pour lesquelles l'Intégration Continue n'est pas très suivie est qu'elle peut générer une quantité importante de notifications pas toujours bien ciblées qui finissent par être ignorées.
Mise en oeuvre
Pour mettre en place cette solution nous allons utiliser le serveur d'Intégration Continue Hudson et son plugin Git.
Commençons par initialiser un projet Git, qui nous servira de dépôt central :
$ mkdir unbreakable_project
$ cd unbreakable_project
$ git init
$ cat build.sh
#!/bin/sh
echo "Build successful"
$ chmod +x build.sh
$ git add build.sh
$ git commit -a -m "ajout du script de build du projet"
Nous utiliserons un simple script shell que nous feront échouer pour simuler un build cassé.
Nous allons maintenant créer un nouveau job Hudson pour qu'il construise automatiquement notre merveilleux projet. Un job "free-style" suffira à faire exécuter notre script shell de build.
Si le plugin Git a bien été installé, celui-ci devrait être sélectionnable dans la section "Gestion de code source".
- Remplir le champs de l'URL du dépôt avec le chemin qui convient (http://..., ssh://..., file:///...),
- Laisser le champs
Branchvide, de cette façon le plugin Git pour Hudson surveillera toutes les branches (ie. chacune des branches de nos développeurs), - Dans "Avancé", sélectionner l'option
merge before buildet indiquermaster(branche par défaut de Git et notre branche de référence) dans le champsBranch to merge to, - Et enfin, dans la section
Post-build Actions, sélectionner l'optionPush Git tags back to origin repository.
Et voilà, Hudson et le plugin Git fonctionneront comme décrit précédemment.
La dernière étape consiste à configurer l'environnement des développeurs. En effet, il faut configurer Git pour lui indiquer sur quelle branche aller chercher les mises à jour et sur quelle autre les envoyer.
Mettons-nous dans la peau de Bob :
$ export EMAIL="Bob "
$ git clone ssh://bob@git.octo.com/projects/unbreakable_project
$ cd unbreakable_project
Ici nous configurons le dépôt de Bob pour que Git pousse les modifications de la branche master du dépôt local vers la branche bob sur le dépôt distant :
$ git config remote.origin.push master:refs/heads/bob
Bob peut maintenant exécuter git pull qui ira chercher les mises à jour dans la branche master du dépôt central (comportement par défaut lors de l'utilisation de git clone et git push qui enverra ses modifications sur la branche bob du même dépôt.
Si Alice fait échouer le build (ou le merge en provoquant un conflit), Hudson marquera le build en échec mais la branche master du dépôt central restera saine.
$ export EMAIL="Alice "
$ git clone ssh://alice@git.octo.com/projects/unbreakable_project
$ cd unbreakable_project
$ git config remote.origin.push master:refs/heads/alice
... Alice modifie le script de build
$ cat build.sh
#!/bin/sh
echo "Build successful"
false
$ git commit -a -m "casse le build"
$ git push
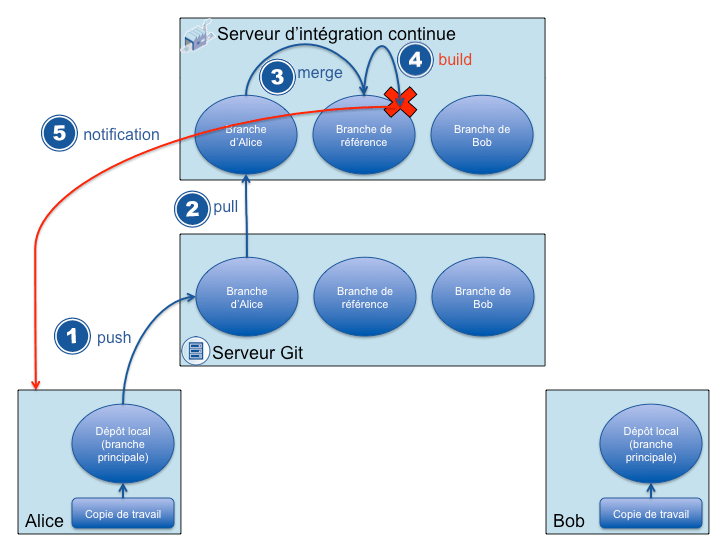
alice sur master vers le dépôt central.
Bob n'est alors pas perturbé par cette modification lorsqu'il essaye de mettre son dépôt à jour :
$ git pull
...
Already up-to-date.
Alice ne pourra pas intégrer ses modifications à la version de référence tant qu'elle n'aura pas corrigé sa version. Elle pourra cependant continuer de la mettre à jour depuis le dépôt central ou même aller chercher des modifications directement dans le dépôt de Bob (s'il a un quelconque moyen d'y accéder).
Nous avons donc vu qu'un gestionnaire de versions distribué tel que Git nous permet de pousser encore plus loin le principe d'Intégration Continue sans faire le moindre développement. Vivement que les plugins des gestionnaires de versions distribués pour nos IDE favoris arrivent à maturité pour pouvoir démocratiser ce genre de solution !