Geolocalização de publicações médico científicas

Na medicina, existem descobertas especiais que não apenas revolucionaram o conhecimento do corpo humano, das doenças e seus tratamentos, mas também salvaram milhões de pessoas. Essas descobertas aumentaram a qualidade e a expectativa de vida em todo o mundo, além de abrir horizontes para novos estudos.
Mas atualmente, de onde as publicações médicas científicas estão vindo? Quais são os países que mais colaboram?
Para investigar essas questões, nós nos concentramos na base de dados da biblioteca nacional de medicina dos Estados Unidos, a MEDLINE, com mais de 18 milhões de artigos e citações medicas.
Dados abertos estão fluindo ao redor do mundo, esperando por novos ângulos de análise e para enfrentar esses grandes problemas, um rico ecossistema de ferramentas tem evoluído, juntamente com novos paradigmas de arquitetura. O desafio Medline demonstra o que pode ser alcançado com o poder de ferramentas BigData.
Para fornecer alguns insights sobre como a nossa aplicação web interativa foi construída para explorar esses dados, vamos analisar o método de localização geográfica com base na filiação de texto livre. O Hadoop orientado para tratamento de dados com Scala e Spark e análise interativa com o Zeppelin notebook e renderização com React (um moderno framework JavaScript). O código foi aberto e publicado no github [1, 2] e o aplicativo está disponível funcional na Amazon AWS.
Abordagem
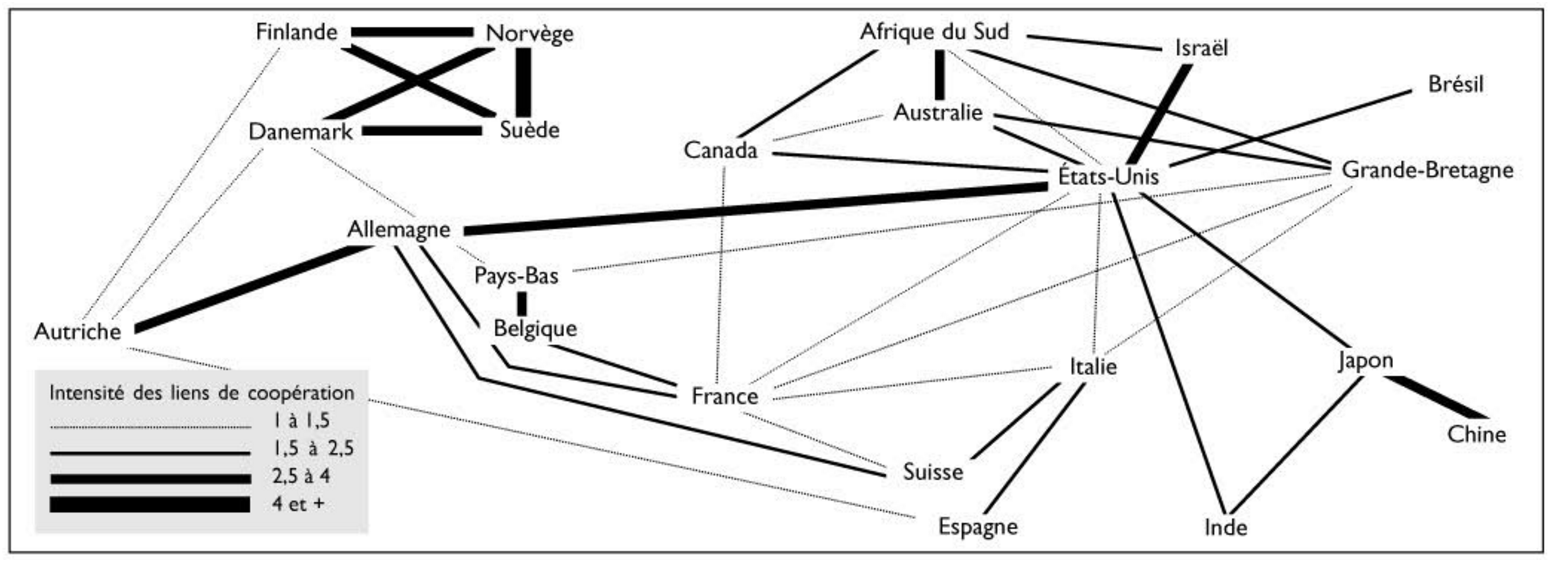
A análise de origem geográfica de publicações científicas já foi abordada em trabalhos anteriores, como [3, 4, 5]. Embora estes documentos apresentem uma visão sociológica, política e histórica interessante sobre o assunto, os dados subjacentes foram agregados à mão (ver figura 1) e, portanto, oferecem poucas possibilidades de uma maior “escavação”.
Cada vez mais conjunto de dados abrangentes são disponibilizados, (tais como arxiv.org [6], toda via, nós decidimos concentrar os esforços no repositório de citações de biologia e biomedicina Medline; Com a fonte subjacente dos dados PUBMED [7], sendo o principal ponto de entrada para qualquer pesquisa bibliográfica na área, ele oferece um grande volume de citações e um formato analisável.
Incontáveis perguntas podem ser “escavadas” de tais materiais. Nós estávamos imaginando quais países seriam os mais prolíficos ao longo dos anos. Além disso, se existem padrões em colaborações entre esses países? Embora a informação de localização não esteja diretamente disponível, ela pode ser deduzida a partir de associações dos autores na maioria dos casos (quando disponíveis). Finalmente, gostaríamos de fornecer tanto uma ferramenta interativa para navegar através desses dados e um quadro para analisá-los de forma programática.
O presente artigo não tem outras reivindicações do que oferecer uma ferramenta de visualização e um acesso a esses dados para análises posteriores.
Materiais
Como mencionado, os dados de citações foram baixados do Medline, e eles podem ser obtidos através de um acordo NLM [8]. Refletindo outubro de 2015, para este estudo. Eles consistem em 789 arquivos (15GB) contendo 23 milhões de citações no formato XML. Cada citação é abrangente, não inclui o conteúdo do artigo, mas as informações meta, tais como data de publicação, título, autores, filiação parcial, referências, etc. Um exemplo desse tipo de saída pode ser encontrado aqui [9].
A localização das publicações com coordenadas geográficas e países, são derivados das filiações do autor (sempre que disponíveis). Os detalhes deste processo serão discutidos abaixo, mas foram utilizadas duas fontes principais de localização.
O mapa de geocodificação (API Google [10]) é conveniente para este fim, mas limitações sobre o uso livre proíbem a utilização em larga escala. A primeira fase de geocodificação foi portanto, concebida para analisar os campos de texto de afiliações livres, com base em GeoNames [11] .
A última fonte de dados externos usados neste projeto são as formas geográficas dos países, derivadas a partir do repositório de dados NaturalEarth [12].
Resumidamente, a parte tecnologica do projeto depende de inúmeros “tijolos” de softwares Open Source. Sem cita-los em detalhes, os principais componentes são: Play [18], Spark [ 16 ] e a Scala para o backend. A aplicação final web foi desenvolvida em JavaScript, utilizando a biblioteca React [13] e bastante dependentes da d3.js [14] para os componentes gráficos. Embora o código publicado foi executado em um laptop com SSD (Solid State Disk), a tecnologia utilizada é originalmente destinada para se conectar a um cluster Hadoop, por uma questão de escalabilidade.
Aquisição dos Dados
A etapa de aquisição dos dados consiste em baixar dados originais e transformá-los em um formato acessível e explorável.
Método
Download dos arquivos Medline
Como mencionado na seção de material, o arquivo de citações Medline pode ser baixado (uma vez que o contrato de licença tenha sido confirmado). Embora o método pareça trivial, o comando para a aquisição da autorização de reprodução mais fácil é:
lftp -e 'o ftp://ftp.nlm.nih.gov/nlmdata/.medleasebaseline/gz && mirror --verbose && quit'
Geolocalização
Um passo-chave da preparação de dados é atribuir uma latitude e longitude e um país para as citações. O formato XML de citações Medline expõe uma lista de autores [9] . Exemplo de detalhes do autor do artigo:
<Author ValidYN="Y"> <LastName>Lill</LastName> <ForeName>Jennie R</ForeName> <Initials>JR</Initials> <AffiliationInfo> <Affiliation>Genentech, South San Francisco, California 94080, USA.</Affiliation> </AffiliationInfo> </Author>
“Affiliation” é, portanto, o campo a ser mapeado com as coordenadas geográficas.
Google GeoCoding API
A maneira mais fácil de converter um campo de texto endereço em coordenadas é usar o Google Geocoding API [10] . É uma camada subjacente que mapeia um endereço para uma posição ao utilizar o Google Maps ou o Google Earth.
A API REST está disponível, através da uma URL:
https://maps.googleapis.com/maps/api/geocode/json?address=Genentech,+South+San+Francisco,+California+94080,+USA&key=YOUR_API_KEY
Onde o “YOUR_API_KEY” é o valor que será solicitado para o registro na API do Google. A saída em JSON pode ser “parseado” para resolução de conflitos (o endereço coreto foi localizado? Que coordenada? Qual país?). A API Java também está disponível para auxiliar a análise e tornar o processo ainda mais simples [15].
No entanto, uma grande limitação é o uso gratuito da API do Google. O limite diário é definido para ser 2.500 requests, o que a torna de difícil utilização quando aproximadamente oito milhões endereços exclusivos de filiação devem ser localizados. Existem outras soluções on-line (como MapQuest), mas sofrem das mesmas limitações de uso ou mostraram-se muito inclinadas apenas para os Estados Unidos. Uma solução off-line artesanal haveria, portanto, de ser desenvolvida.
A implementação do nosso método de geocodificação consistiu em:
- A tentativa de resolver afiliações pela solução GeoNames descrito na próxima seção;
- As afiliações não resolvidas foram então classificadas segundo a recorrência (a mais comum em primeiro lugar) e uma chamada diária para a API do Google realizada para tentar localizar as primeiras 2.500. Por razões de este projeto ser apenas uma POC e devido às limitações de tempo, esta segunda etapa foi aplicada apenas por alguns dias, obviamente para testar a relevância abordagem.
Uma solução baseada em GeoNames
GeoNames é uma base de dados geográfica abrangente[11]. Assim como a API do Google Maps, ela fornece uma API REST para ser consultado, e com limitações semelhantes. No entanto, o banco de dados subjacente pode ser baixado gratuitamente em formato tabular, com vários pontos de vista. A solução ad hoc apresentada abaixo não é perfeita, mas mostrou-se relevante o suficiente para resolver a maioria das situações no projeto atual.
Muita informação está disponível na base de dados GeoNames (como moeda, formato de código postal...), mas apenas um subconjunto é realmente utilizado na implementação atual. A nossa solução usa três arquivos, todos com suas chaves de relacionamento:
- txt: códigos ISO de países e nomes;
- txt: nomes, latitudes, longitudes, países e população para cidades com mais de 15.000 habitantes;
- txt: nomes alternativos de países e cidades.
O algoritmo para localizar campo de endereço não é tão simples por duas razões principais.
- O campo está em texto livre ordenado apenas por autores em tempo de submissão de trabalhos, sem indicações claras sobre o padrão adotado.
- Embora possam ser inequívocas para um pesquisador lendo o jornal, essas informações oferecem um desafio do ponto de vista de automação. Aqui estão alguns exemplos:
- "Colégio de Médicos e Cirurgiões da Universidade de Columbia, New York, NY, EUA",
- "CJ. N. Adam Memorial Hospital, Perrysburg, NY ", sem qualquer país;
- "Tripoli", Além de vários erros de ortografia, é uma cidade em três países;
- Informações de e-mail às vezes acabam no campo de afiliação;
- Múltiplas filiações para um autor podem ser preenchidas;
- A capital da Itália pode ser soletrada _"Rome"_ou "Roma" ...
Muitos lugares têm vários nomes comuns: "New York", "New York City”, "Nova York".
"Springfield, EUA" pode apontar para onze cidades diferentes com mais de 15.000 habitantes.
Para tornar o problema ainda mais complexo, algumas filiações não fornecem qualquer país como a "faculdade de Oxford" ou "Departamento de Medicina da Universidade de Washington, Seattle 98195" ou fornecer diferentes profundidades, tais como endereço, código postal etc. Para dificultar ainda mais o problema, nós também poderíamos mencionar países que não existem mais ou tiveram seu nome alterado: "USSR", "Hong Kong" ou "Tchecoslováquia".
Se por um lado a API do Google Maps provou ser eficiente para muitos casos de ambiguidade, por outro ela depende de muito mais informação para isso. Por isso, criamos uma estratégia multi-etapas para abordar as situações mais comuns. O objetivo é extrair pares de cidade/país e procurar fora da base de dados comuns tais informações. Os passos principais são os seguintes:
- Remover e-mails, números de referência do cabeçalho, e utilizar apenas a primeira filiação quando várias estão presentes, usando separador por pontos (com exceção das abreviaturas comuns);
- Dividir a string em blocos ao longo de separadores por vírgula;
- Remover os blocos com estrutura de código postal;
- Com todas as combinações de dois elementos entre os últimos três blocos, procurar na base de dados GeoNames para correspondência:
- Par de cidades / país,
- Par de cidades / país, com nomes alternativos,
- Cidade única,
- Única cidade, com nomes alternativos;
- O processo é interrompido na primeira correspondência na etapa anterior;
- Se vários locais estão combinando, elas são classificadas segundo a contagem da população e o primeiro é mantido quando a proporção da população com o segundo é maior do que 10.
Como discutido abaixo, alguns lotes de associações não são resolvidos de forma certeira, mas a maioria são. Por mais imperfeito que possa ser, o método apresentado baseia-se em compensações empíricas.
Para ilustrar o método, os exemplos podem ser encontrados nos testes unitários do projeto[1].
Implementação
Além das citações Medline originais, apenas algumas informações foram mantidas em prol deste projeto: data de publicação, título, resumo e lista do autor. Eles foram salvos no formato parquet em um HDFS Hadoop para permitir o processamento distribuído com o framework spark[16]. Embora ele se baseie no formato orientado a hdfs, a parte de aquisição dos dados foi realmente feito em um simples laptop Mac, executando os procedimentos localizados no diretório ch/fram/medlineGeo/crunching/tools [1].
Resultados
Agora é hora de ver os números e medir o enriquecimento que os dados geraram. À medida que os dados haviam sido processados na plataforma Hadoop, utilizamos o Apache zepelim para a análise de dados [17]. Sendo uma aplicação baseado em plataforma web, permite que os usuários manipulem interativamente dados hospedados no hadoop com programação no Scala (Java ou Python) e Spark [16].
Método de desempenho da Geolocalização
Dos 23 milhões de citações, 8.7 milhões de campos de filiação únicos foram extraídos. Por exemplo: "Department of Biology, Massachusetts Institute of Technology, Cambridge 02139" refere-se a 724 publicações. Como que muitas dessas publicações poderiam ser atribuídas a uma localização geográfica especifica por cada um dos métodos anteriormente descritos?
65% foram resolvidos pela estratégia com base nos GeoNames personalizados. Entre os restantes, 75% foram atribuídos pela API do Google geocodificação. Embora esta segunda etapa não foi aplicada a todo o conjunto por motivos de tempo (o que teria levado 1.218 dias, com o limite de acesso gratuito!); é possível prever que 91% dos endereços globais poderiam ser resolvidos.
Agora podemos medir quantas publicações poderiam estar ligadas a uma localização geográfica.
Evoluções das citações localizadas através do tempo
Em outubro de 2015, mais de 23 milhões de citações foram baixadas. Embora algumas publicações do fim do século 21 foram registadas, o volume aumentou drasticamente após a Segunda Guerra Mundial, tal como mostrado na figura 3.
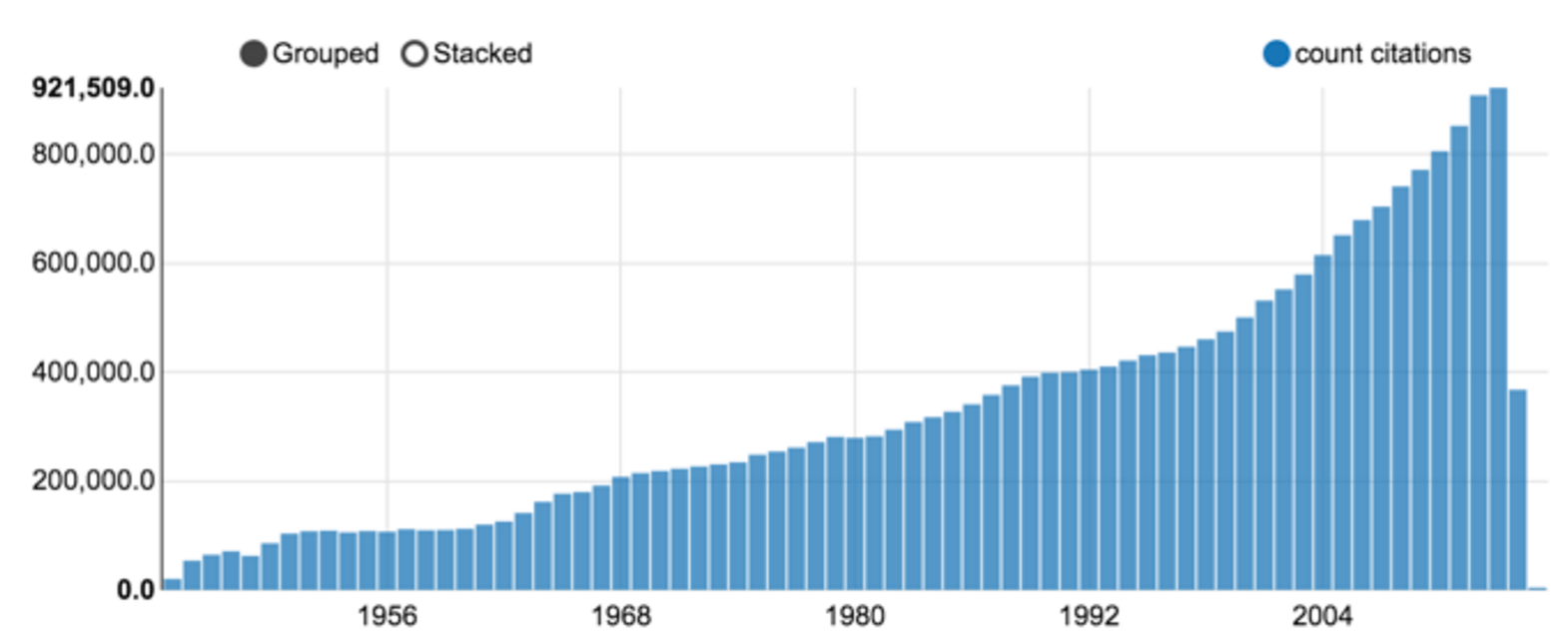
Figura 3: contagem de citações Medline por ano (um gráfico Zeppelin).
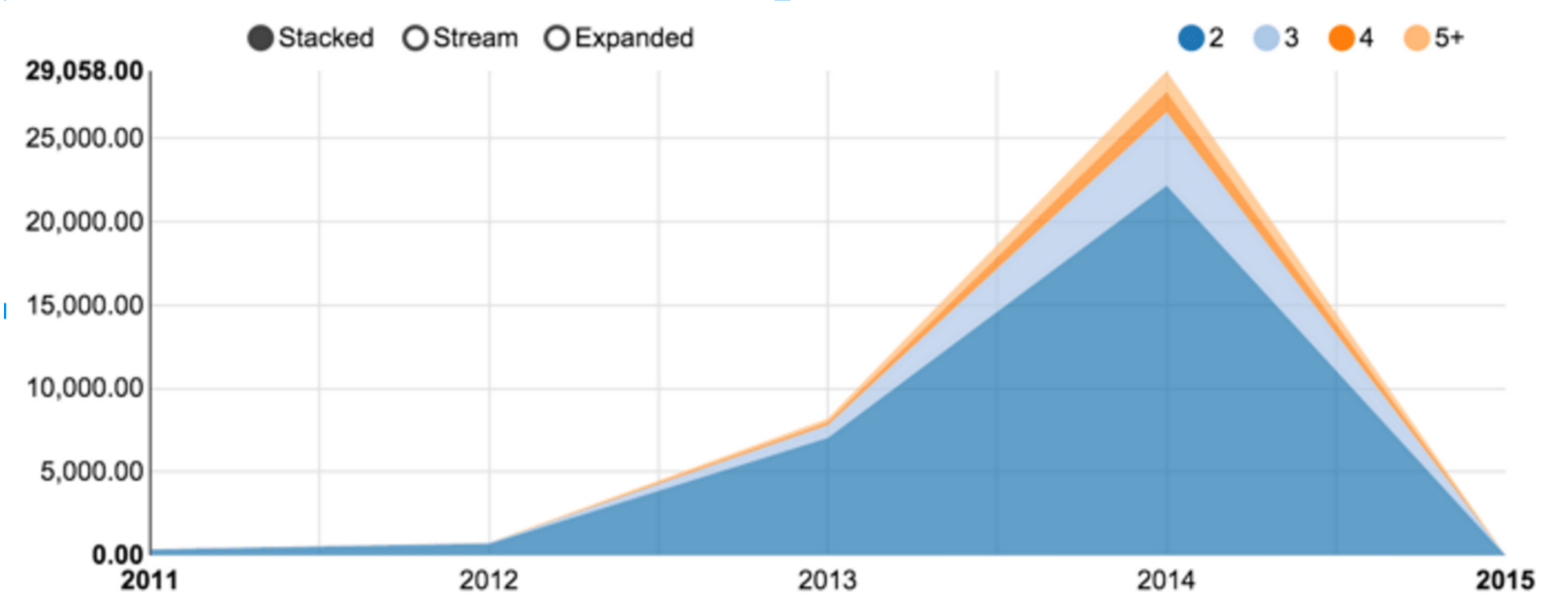
Entre essas 23 milhões de citações, 9 milhões poderiam ser associadas a pelo menos um local, como mostrado na Figura 4. Tendo-se em meados dos anos oitenta, a percentagem foi estabilizada em cerca de 70% da produção total. A Figura 5 mostra o número de publicações relacionadas com dois ou mais países. Os números são relativamente baixos devido à tendência de preenchimento de afiliação apenas para o primeiro autor. Além disso, a taxa de resolução da localização afeta profundamente a citação com autores provenientes de vários centros de pesquisa.
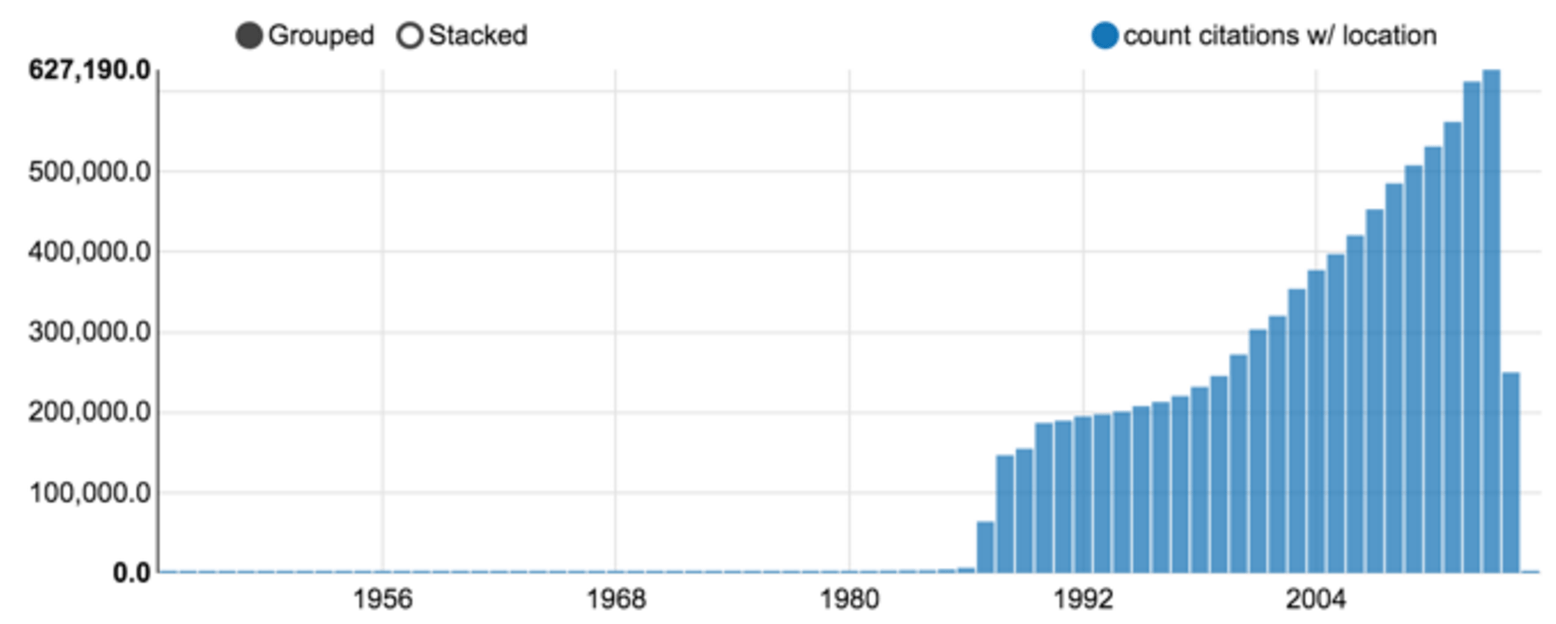
_ 
Navegando através de publicações geograficamente localizadas
Uma vez que as etapas de aquisição de dados são executadas, as citações são anotadas com localização e armazenados em formato parquet. Embora possam ser lidos por várias ferramentas da pilha Hadoop, apresentamos dois componentes construídos para este projeto:
- Um servidor back-end: leitura, transformação e disponibilização dos dados através de uma API REST;
- Uma aplicação web de frontend, para exibir e interagir com representações gráficas, que se comunica com o back-end por meio da API.
Essa abordagem modular permite alterar a camada de apresentação, que poderia facilmente ser outro aplicativo web, scripts R ou inúmeras outras soluções.
O servidor de back-end[1]
O objetivo do back-end é fornecer acesso aos dados através de uma API REST. Por exemplo no link é esperado retornar uma lista de países com o número de publicações atribuídas em 2012. A saída deve ser estruturada (JSON) ou tabular (TSV).
Outro exemplo, para extrair todas as colaborações do país para 2002, pode-se ir ao link e obter:
[ { "year": 2002, "nbPubmedIds": 1, "countryFrom": "DE", "countryTo": "RU", "nbPubmedIdTotalFrom": 18100, "nbPubmedIdTotalTo": 3573 }, … ]
Entre muitas escolhas (nodejs/express, java/Spring, ruby/rails, python/django etc.), foram selecionados a combinação Scala/Play/Spark. Com base na JVM e combinando paradigmas funcionais e objetos orientados, escolhemos Scala [20] para ser uma linguagem para cálculos científicos e mais amplamente, a programação distribuída.
Play é um framework web, tanto para Scala e Java. Além do conforto do desenvolvimento prático, ele é naturalmente concebido para servir de programação reactive [20] , com grandes operações, interativas e resilientes.
O terceiro componente do trio é o Spark [16], um poderoso motor alocado originalmente em cima do Hadoop. Ele permite distribuir cálculos sobre grandes volumes de dados e é acessível em Java e Python, mas a linguagem natural é ... Scala. O projeto de ignição tem uma forte tração nos últimos anos, aproveitando o processamento em lote Hadoop MapReduce em uma abstração mais interativa e confortável. O quadro cresce continuamente, incluindo streaming de evento, aprendizagem de máquina, algoritmos de gráfico e uma interface R.
Agregação de dados via Spark lança um job Hadoop. Mesmo que o framework tenha tido grandes melhorias de velocidade sobre o sistema MapReduce original, dificilmente é suficiente para um uso interativo conveniente (tempos de resposta comuns pode chegar a minutos). Portanto, todos os pontos de vista clássicos são computados uma vez e colocados em cache e pode então ser entregues dentro de um décimo de segundo.
Como mencionado algumas vezes, a arquitetura de armazenamento selecionado para este projeto foi orientada a Hadoop. Deve, contudo, ser mencionado que esta escolha pode ser contestada. O volume de dados não é tão grande e por isso outras soluções, tais como ElasticSearch [21] poderiam ser consideradas. Nós tivemos uma tentativa com MongoDB [22], mas a agregação de dados não se mostrou com boa escala vertical.
O front-end web browser [2]
O segundo componente consiste em uma aplicação web rica. O moderno Javascript oferece uma infinidade de frameworks, como AngularJS, Ember ou Backbone. Embora todos eles podem mostrar vantagens claras em algumas situações, optamos pelo React [13], uma biblioteca de código aberto fornecido pelo Facebook. Juntamente com o padrão Flux [23], que tem atendido aos requisitos de visualização de dados em massa. Em complemento, dificilmente se pode evitar a versátil biblioteca d3.js [ 7 ] para construir representações gráficas interativas.
Propomos três diferentes tipos de pontos de vista:
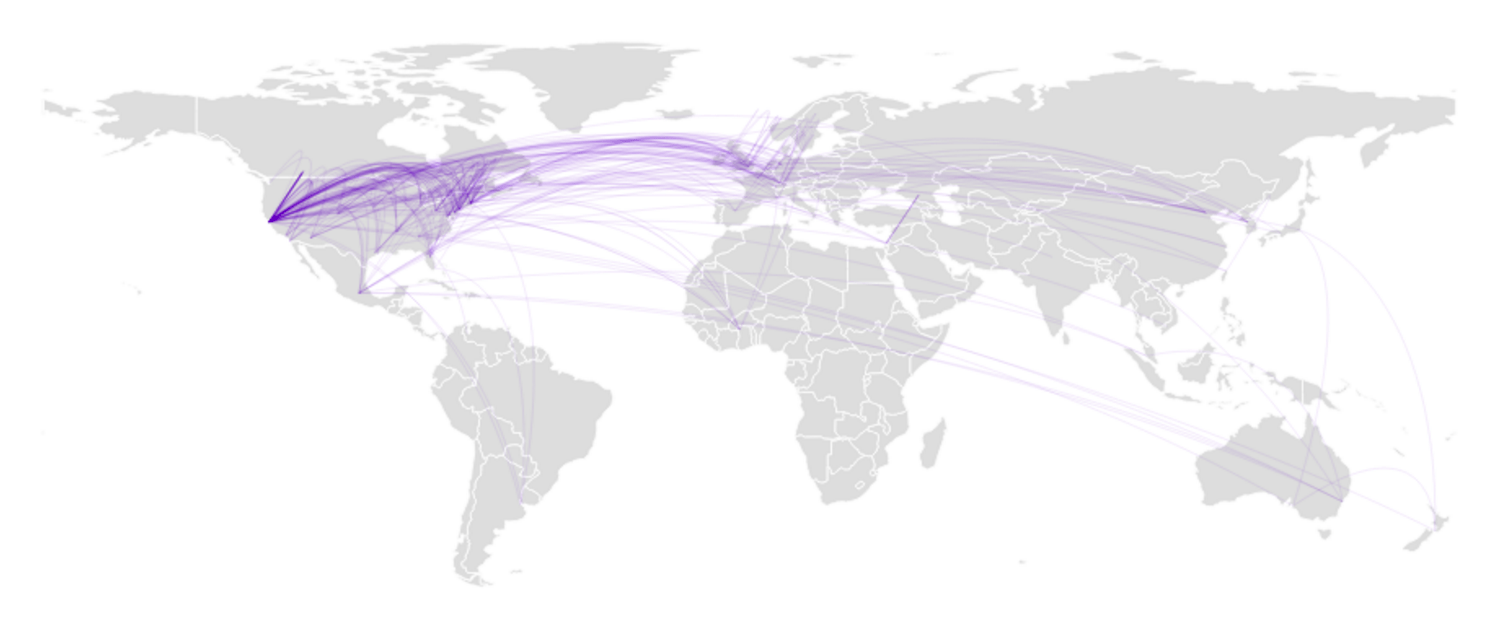
- Um mapa do mundo, com um mapa de calor para representar contagens de citações (Figura 6);
- Um gráfico de barras, com contagens de publicações por ano (Figura 7);
- Um gráfico de rede, exibindo colaborações entre países (figura 8).
Cada um desses pontos de vista pode ser manipulado por um controle deslizante seleção do ano para navegar em anos anteriores basta interagir e visualizar mais detalhes.
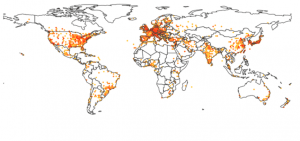
Um mapa-múndi de calor
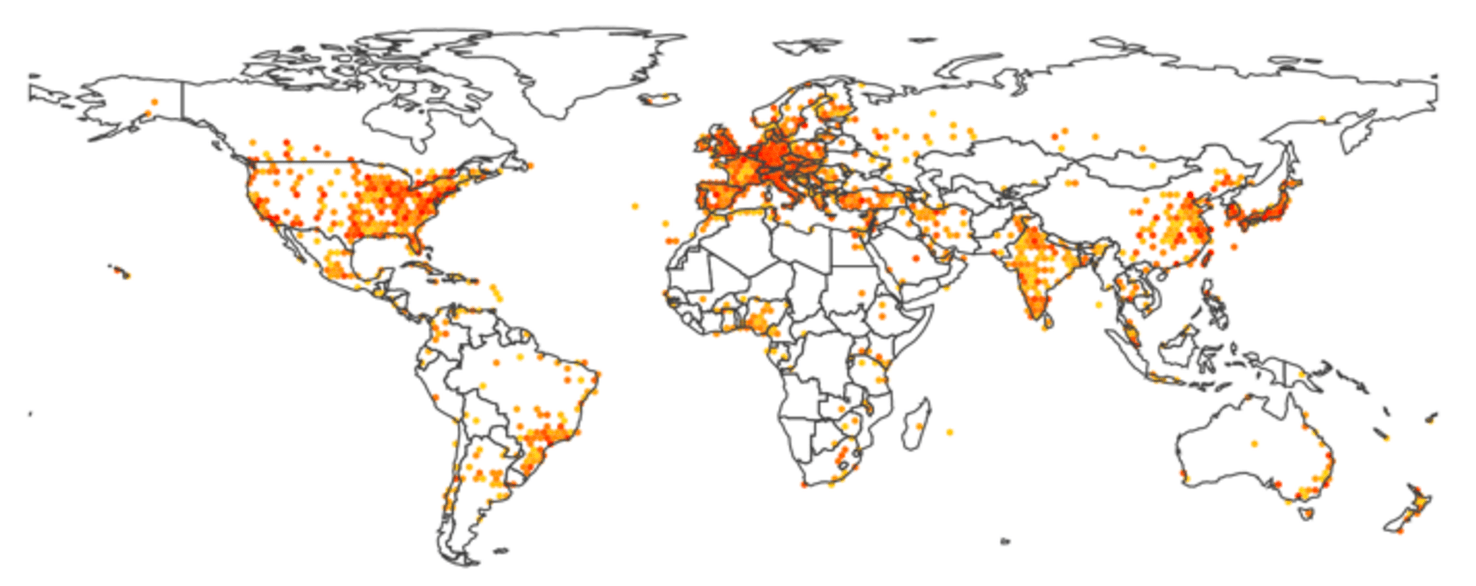
Figura 6: um mapa-múndi de calor, onde as cores que variam de luz laranja para vermelho mostra o número de publicações para o ano corrente.
Uma vez que citações poderiam ser atribuídas a coordenadas geográficas, parecia natural exibi-las em um mapa do mundo. Os resultados apresentados na Figura 6 mostram uma pavimentação hexagonal, com a cor que indica o número de locais de publicações na área. Usando o controle deslizante para navegar ao longo dos anos revela, por exemplo, o recente aumento dramático da produção dos países BRICS.
D3.js foi combinado com topojson para uma prestação perto ideal de fronteiras de países, permitindo sobrepor outras informações, tais como os links exibidos na figura 2.
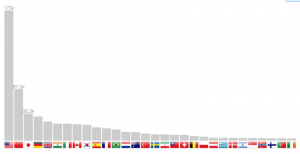
Contagem de publicação por país
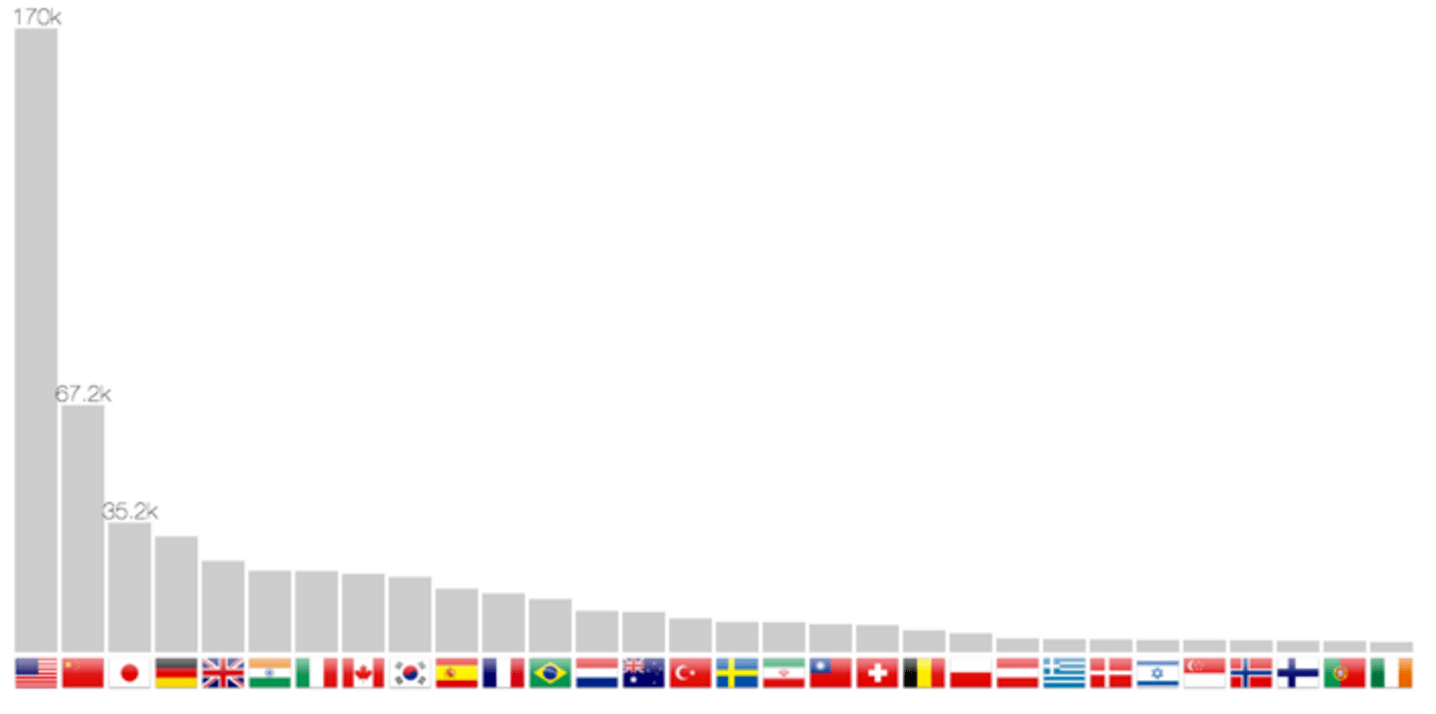
O método de localização permite não só para voltar coordenadas, mas também o país. Por isso, é possível construir um gráfico de barras na figura 7. A rolagem ao longo dos anos faz com que as barras de deslizem de uma posição para outra, portanto, seguindo uma progressão de países, como a China nos últimos vinte anos.
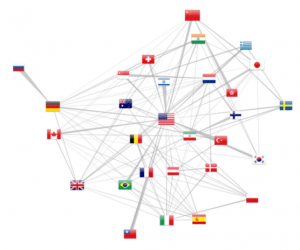
Gráfico de colaboração por País
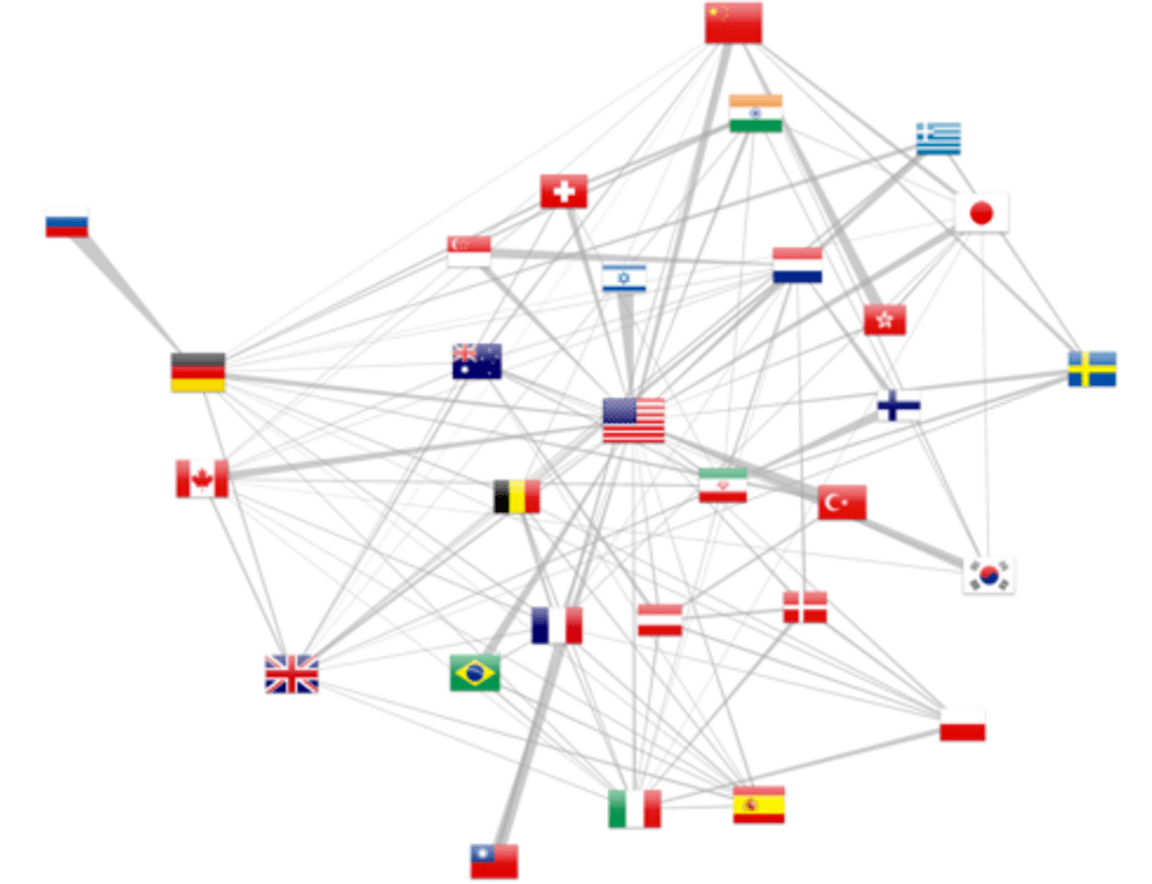
As várias citações afiliadas permitem retirar colaborações entre países (pelo menos a partir de 2012, como revelado pela figura 5). O modelo de força atrai mais fortemente os países com mais colaborações, enquanto o número total de publicações é relatado pelo tamanho da bandeira. Além disso, d3.js permite desenhar arestas trapezoidais, em que a espessura de uma extremidade mostra a importância relativa da colaboração. Por exemplo, no canto superior esquerdo, a Rússia está exclusivamente ligada com a Alemanha, ao passo que este último país como outras colaborações. A mesma observação pode ser feita para a relação Israel-EUA.
Deve-se ter em mente que esta representação é apenas uma amostra de co-publicações, assim como os autores podem não ter apresentado várias filiações ou os artigos podem não ter sido resolvidos pelo método de localização. Nós só podemos tratar de uma amostra de colaborações reais. Os números são, no entanto, os mais relevantes nos últimos anos, na sequência do aumento de citações com múltiplos autores filiados. Finalmente, a taxa de elucidação em 65% para um único endereço cai para 42% para publicações com dois endereços (0,65 2). Estendendo o método de geolocalização para o Google Map API, portanto, foram resolvidos 83% desses casos.
Executando o Aplicativo
Para fins de desenvolvimento, ambos os componentes podem ser clonados a partir do github [1, 2] e começou de forma independente, como descrito nos respectivos arquivos README.md.
Para um uso mais conveniente, uma imagem docker foi criada. Esta imagem foi publicada apenas para demonstração. Para limitar memória e CU footprint, o backend JVM não foi empacotado e os dados são armazenados em cache na aplicação em NodeJS:
docker run -p 80:5000 alexmass/medline-geo-standalone
Os teste contínuos foram hospedados pelo Travis [24], um sistema de integração contínua on-line com acesso livre para projetos Open Source.
Conclusões
Nós apresentamos uma abordagem para atribuir informações geográficas as publicações científicas, com base no índice de citações Medline. Além disso, vimos como um stack Big Data pode ser usada com uma arquitetura modular através de uma exposição de dados via API.
Se esses dados podem revelar fenômenos interessantes, acreditamos que esta abordagem pode ser estendida para cavar ainda mais sobre este conjunto de dados ou outros (arxiv.org), analisando conteúdos abstratos por exemplo, ou agregar outras fontes de informação (como o PIB anual).
Em uma escala maior, demonstramos como o ecossistema Hadoop abre novas rotas para mergulhar na análise de grandes conjuntos de dados, a um custo relativamente baixo.
Agradecimentos
Eu gostaria de agradecer aos contribuintes para que esse trabalho apresentado. Entre eles, Nasri Nahas e Catherine Zwahlen para semear a idéia. Martial Sankar para discussões esclarecedoras sobre os métodos geolocalização. Por último, mas não menos importante, os meus colegas da OCTO Technology Suíça pelo seu feedback completo.
Referencias
[1] https://github.com/alexmasselot/medlineGeoBackend [2] https://github.com/alexmasselot/medlineGeoWebFrontend [3] “Les formes spécifiques de l’internationalité du champ scientifique”, Yves Gingras. Actes de la recherche en sciences sociales, 2002 [4] “L’internationalisation de la recherche en sciences sociales et humaines en Europe (1980-2006)”. Yves Gingras et Johan Heilbron. L’espace intellectuel en Europe, 2009 [5] “International scientific cooperation : the continentalization of science”<sp