Gather shopping receipts: architecture overview
Following our first post (in French) concerning the business challenges raised by the data collection and analysis in the retail sector, we will now present a use case with its associated issues. We will see how to face them based on modern technologies that have already proven themselves in Web giants: Kafka, Spark and Cassandra.
Context
A retail store actor would like to retrieve and process data in real-time such as issued receipts, the flow of goods between his suppliers, warehouses and stores, and user path on his e-commerce website.
For example, he would like to get in real-time the turnover performance of each product category compared to the same day of the previous week (see graph below) so as to initiate marketing actions quickly.

We will later describe an architecture that allows the development of such a feature while still having the possibility to meet use cases related to the monitoring of the stock, flow of goods, or user path on the e-commerce website (and drive store).
Here are the issues we have to address:
- High information flow
Each store banner of our 10,000 stores produces an average of 10 receipts per minute. As part of our study, we have worked with denormalized receipts, approximately 3 kilobytes each, it creates a flow of receipts of a few megabytes per second. Goods movements can also represent a flow rate of same order. By contrast, monitoring customer actions on the e-commerce website (clicks, page views) may generate a stream of tens of megabytes per second. As a first approach, we need to handle a global flow in the order of 100 megabytes per second.
- Large amount of data to process
The previous point logically leads to a second problem: the amount of data to be stored can become significant over time. Our data warehouse will have to ingest terabytes of data each year. This is where conventional relational DBMS start to suffer: beyond a few terabytes of data, performing simple queries with joins, groupings and aggregates can become an ordeal. We no longer talk about time required to grab a coffee, but to come back the next day! Besides the problem of required storage space (the cost of storage is falling), we have to be able to handle efficiently such volumes of data: if one hopes to be responsive at D+1, a few hours must be enough to our batch execution, allowing to fix in real time the turnover calculation.
To meet this need, our architecture will have to include following characteristics:
- Distributed
All data will roughly weigh tens of gigabytes per day. Such data volumes need a high storage capacity and processing power that may be beyond what is feasible for a single machine.
- Fault-tolerant
Falling (temporary failure, or permanent loss) of any node should not be fatal for the data processing, for a simple reason: the absolute necessity to have access to our real time turnover, so that we can make decisions quickly and at any time, even if a machine has fallen. We do not tolerate the failure of our batches: if treatment lasts a few hours, say 5h, the failure of one node after treatment shall not interfere with it, to effectively exploit the results of our batches at D+1.
- Without single point of failure
Regardless of the node that falls, the system must keep on running properly (loss of performance due to the reduction of resources within the cluster is however inevitable, off-cloud). One should also avoid bottlenecks that would disrupt our architecture performance in case of over-activity.
- Horizontally scalable
If the volume of data handled or treatments on these become too substantial for a cluster, the addition of one or more nodes in the cluster must split the overload and bring the system back to a stable state. Indeed, we work mainly on our 10,000 physical stores. The takeover of a competing group, opening stores abroad, or the resurgence of our drive / e-commerce business should not call into question the architecture.
- Available rather than consistent
The CAP theorem forces us to adjust the slider between availability and consistency of our system. In our use case, it is better to have our indicators about turnover always available, even if they are slightly incorrect. Indeed, a difference of a few receipts is acceptable.
Modeling data and its flow:
Each receipt is composed of meta information such as the store number, the emission time, the loyalty customer card number (if any) and lines corresponding to purchased items (item, quantity, unit price). The example below illustrates a receipt in JSON:
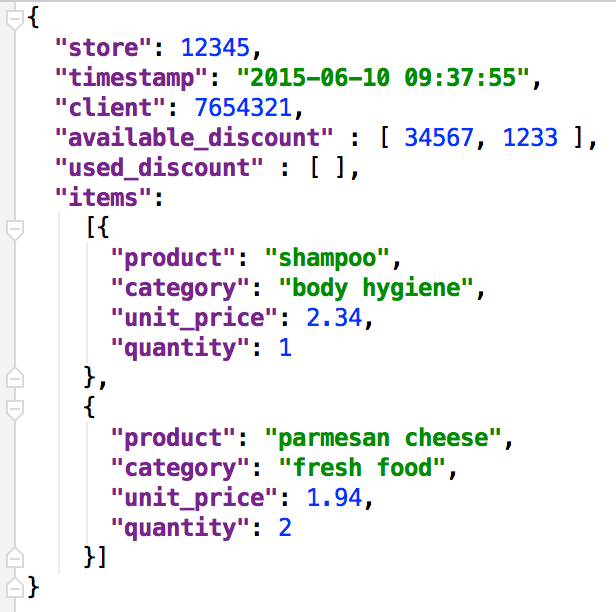
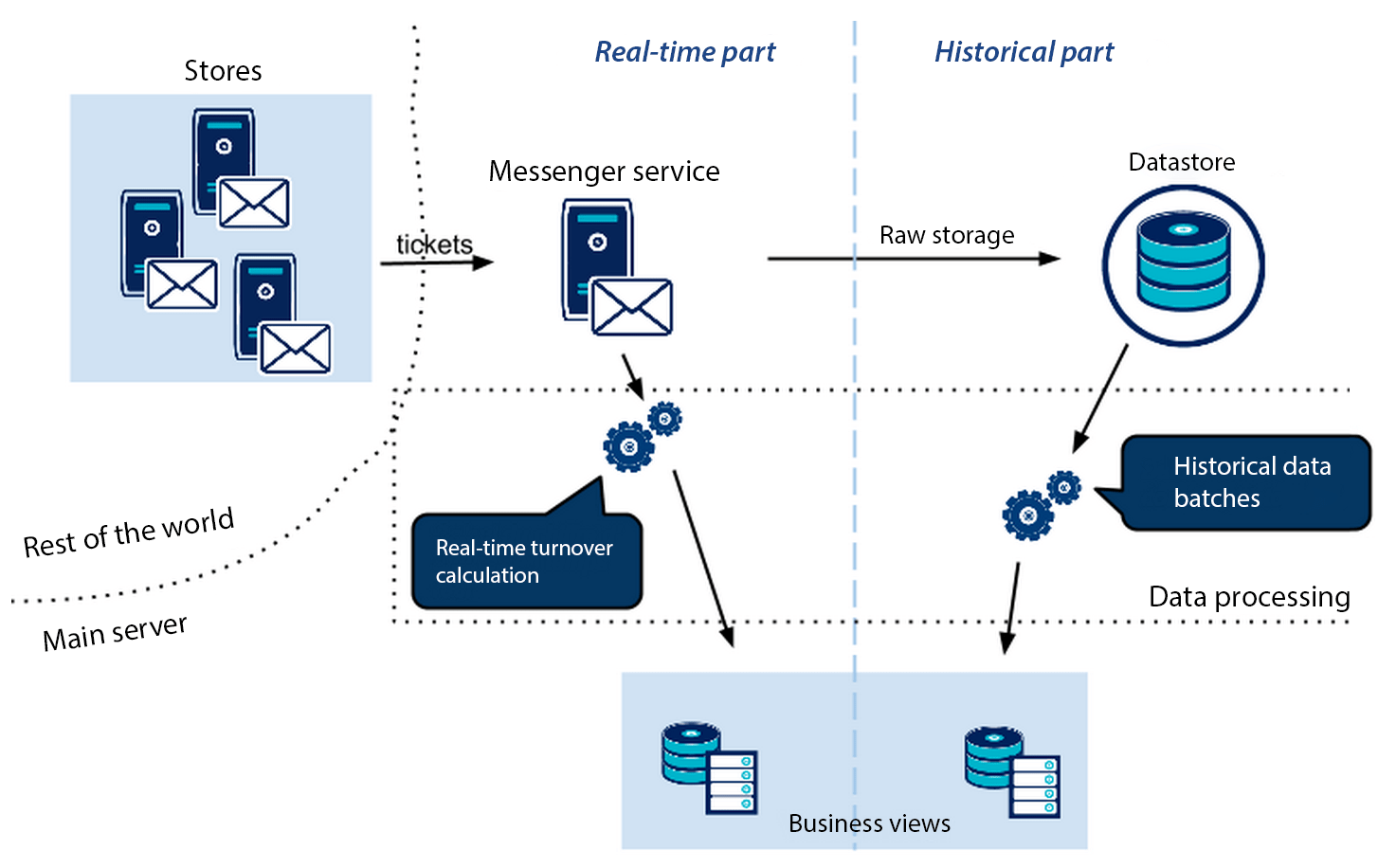
Each store pushes the receipts in the tail of a central messenger system to be treated. Such a system allows to decouple the emitting applications from the receiving ones, but also to take over the peaks of receipts (Saturday at 11am, for example) by smoothing the load for processing applications. Then, the receipt is stored in an immutable database. Along with this, it is directly processed by a calculation engine for the appropriate data to be extracted (turnover per category). The result of this treatment along the way updates the view, offering real-time performance of the group. Regularly, every night for example, a batch will be run to recalculate the turnover per day, category, store etc... to correct deviations and take into account the after-sale service returns.
The following illustration provides an overview of the architecture:
We will now see what technologies we can use to address the problem.
Choice of the data warehouse:
We can think of two ways to store our receipts within the database:
- JSON:
The receipt is stored as such within the database and we index the relevant fields, such as date and category in our case. This can be done using a conventional distributed file system such as HDFS or a document oriented DB such as MongoDB or Couchbase.
- Columns format:
The receipts having a fixed structure and already known, a column-oriented database such as Cassandra or HBase is a viable solution for our use case.
Cassandra has remarkable performance. In writing, tuples are first added sequentially to a commitlog as well as in in-memory tables, thus insertions are in constant time, with a latency that can be of the order of a few milliseconds (this depends on the cluster topology and on the selected level of consistency). Furthermore, the column-oriented design and the physical grouping of data by partitioning key make Cassandra competitive as well in readings when loading large amounts of data in Spark for analytical batches. Cassandra will then be our first-choice solution for our database.
Note that it is perfectly possible to choose any other technology for the data warehouse, or even to use several (eg Cassandra and HDFS).
Data Modeling in Cassandra
In the relational world, we would use several tables: one for the header of receipts containing meta-information, one for each line of the receipt containing the product, one that would be the repository of products, etc... In the NoSQL world, it is quite common to de-normalize data: we prefer high performance in reading and writing times rather than reducing the cost of storage. Simplistically, one could model the receipts as follows:

Migrating from a relational DB to Cassandra needs to rethink its data schema because Cassandra's philosophy is thought as a distributed system, and therefore it is totally different from conventional DBMS. One has indeed to think of modelling its tables based on predicted queries rather than data structure. In our example, the chosen compound key will only allow us to do a limited type of queries: we have used as partitioning key “day, store_id” and as clustering key “id_receipt”. Thus, possible filters on our queries must imperatively contain a day and a “store_id”. For example, the query: Give me all receipts purchased on “2015-04-12” in the store 345 will be an acceptable query, but the following will not: Give me all the receipts purchased in the “tidbit” category.
Data processing
In our use case, we have several needs: compute the turnover of the current day in real time and compute the turnover of the day before in order to allow comparison. The first operation requires real-time computation, whether the other one requires a D+1 batch.
D+1 Batch
Apache Spark is a distributed computing framework that generalizes MapReduce, it allows you to chain jobs while keeping intermediate datasets in memory, increasing performance over traditional MapReduce implementations. Featuring a Cassandra connector and a rich ecosystem including machine learning or real-time processing of large data volumes, this solution is ideal.
Real Time
Two tools stand: Apache Spark Streaming and Apache Storm. Storm is a CEP type of framework (Complex Event Processing) used to process events (logs, visited pages, alerts ...), one event at a time. Spark Streaming is based on the Spark calculation core, it performs its jobs by micro-batches.
In our use case, the one in which the calculation itself has to be done, rather than event management, Spark Streaming is naturally more appropriate: we receive structured digital data (receipt lines) that we will gather and process in parallel. We will also benefit from the homogeneity of Spark ecosystem: Spark batches code can be reused to write Spark Streaming jobs without even needing to change the core. This is the power of Spark ecosystem: we manipulate RDD (or Data Frames, they are the data sets in Spark) in both cases, we could then apply the same operations, with the same code. Finally, Spark also has SparkML API for machine learning, which extends the range of possible use cases.
Input flow
It is now missing one more stone to the edifice. We have seen how to store and process receipts, but it lacks a messaging system to allow stores to supply our Spark / Cassandra with high throughput. Apache Kafka is a MOM (Message Oriented Middleware) distributed, scalable, fault tolerant and without single point of failure. It can be both used as a publish / subscribe messaging system and as a queue. Originally developed by LinkedIn, Kafka has experienced a rise in popularity partly because it is open-sourced and it offers impressive performance compared to its competitors. In our case, it will not only decouple client applications (stores) from processing ones, but also smooth the load so that Spark Streaming and Cassandra can work at optimal speed.
Complex Queries in Cassandra?
As we know in Cassandra server side, joins do not exist, like group by or even aggregate functions like sum, max or min. In fact, we can only retrieve raw data, without pre-processing. We have the ability to filter the data (where clause), but without forgetting the constraints due to the composite key concept. Implement secondary indexes in Cassandra is not recommended because it is often misunderstood by users accustomed to conventional DBMS, so we must understand the concept and handle them with care. All this brings us to a question: given the constraints that go with Cassandra, is it possible for us to make customized requests, not predicted when we did the table design? Give me the value of turnover by category for the store No. 420 August 12, 2015.
This is possible, for example using Spark. An example of code to respond to such a request:
// We set the structure of the tuples that we will manipulate in our DataFrame
case class Produits(category : String, turnover : BigDecimal)
// We get the tuples from Cassandra table
sc.cassandraTable("retail","raw_receipts")
.select("products")
// We filter at Cassandra level whenever it is possible, in order to give only meaningful information to Spark
.where("day=? and id_store=?", "20150812", "420")
// splitProductLust bursts products lists from each of our rows into multiple Products class objects
.flatMap(splitProductLust)
// We map our tuples using the category as a key
.map(product => (product.category, product.turnover))
// The reduction step will calculate the sum of the values (turnover) by key (category)
.reduceByKey(_ + _)
// We display the result for each category
.foreach(println)
Running this bRunning this batch will take at least several seconds (or minutes, or hours, depending on the volume). In all cases, such a batch does not respond to queries with time of the order of one second. We must then provide in advance the answers of expected queries through running regular batches which will build the views or continually feed views through Spark Streaming. We can even combine these two techniques: it is the foundation of the lambda architecture.
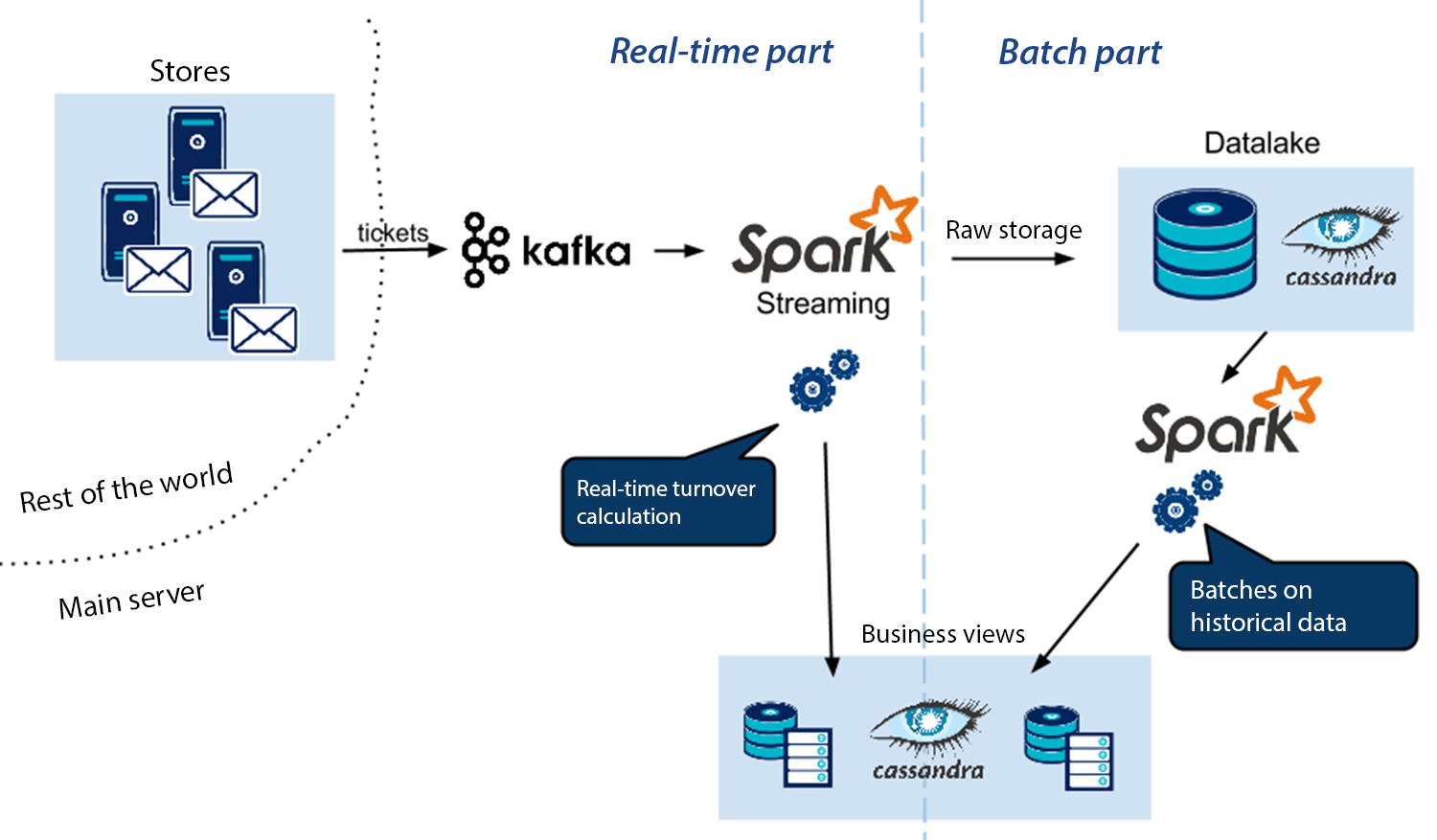
Kafka-Spark-Cassandra platform
So here are our architecture and associated technologies:
{kind=link}
In the following paragraphs, we will explain the operation of the interfaces between Kafka and Spark and between Spark and Cassandra.
From Kafka to Spark
Messages are sent by client applications (our banks in this case, or shops) to topics, and then consuming applications can subscribe to those topics. Topics (in our case, we will use a topic "receipts") contain a number of user-defined partitions. For a given topic, each partition is assigned to a Kafka broker (messenger node). Increasing the number of topic partitions can increase the level of parallelism as well as the topic messages consumption. Each message is a pair (key, value), with the key that will define which partition the topic will handle the message and value. Our message (here the receipt).
Spark Streaming will subscribe to a 'receipts' topic and get each receipt as a stream:
// The stream is splitted into RDDs, each part representing a 2 seconds interval
val ssc = new StreamingContext(sparkConf, Seconds(2))
// We subscribe to the “receipts” topic
val topicsSet = Set("receipts")
// Kafka brokers list
val kafkaParams = Map("metadata.broker.list" -> "kafka1:9092,kafka2:9092")
// We create the Spark stream from Kafka stream
val lines = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, topicsSet)
// We are now able to deploy the turnover calcultation
The stream is divided into RDDs, which is the data format used by Spark. RDDs are also divided into partitions, which are composed of tuples. In our case, a tuple can represent a receipt. By default, an RDD partition is processed by CPU core by "worker" Spark (node): for example, 24 partitions and not more could be processed by 3 Spark worker nodes with 8 cores each. The Kafka-Spark connector offers a high-level interface that will allow to directly map each RDD partition to each Kafka topic partition.
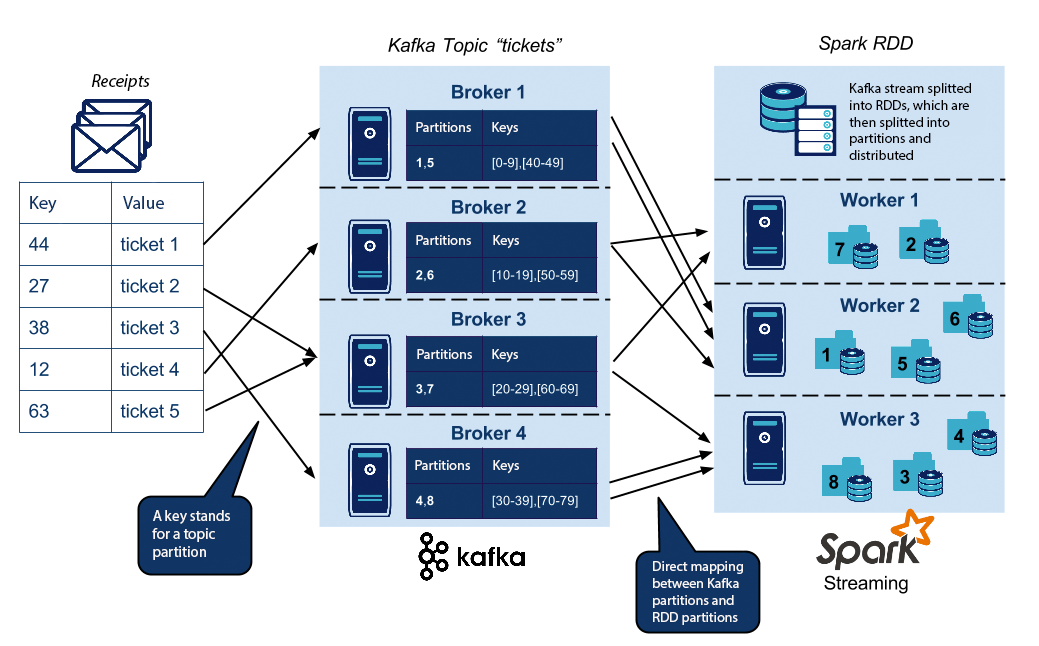
The first operation of our micro-batch Spark is to retrieve messages from the Kafka topic. By default in Spark, a CPU core is allocated for each task. However, retrieve messages from a partition of a Kafka topic is considered as a task. Thus, it may be wise to partition its Kafka topics as follows:
count(partitions_topic_kafka) = 2 * (coeurs_CPU_cluster_spark)
In this way, it effectively takes advantage of our CPU resources of our Spark cluster. Indeed, if count(partitions_topic_kafka) < count(coeurs_CPU_cluster_spark), the message recovery phase within Kafka will result in a RDD containing less partitions than the number of CPU cores available. To fully take advantage of CPU resources in the following operations, it will be useful to reorganize our RDD (upwards), which leads to shuffle (network traffic, to avoid because of performance cost). So as to reduce the impacts caused by unbalanced Kafka topics and to avoid OutOfMemoryError, it is preferred to use 2 or 3 as the multiplication factor in the above equation, as suggested by documentation.
One can also take advantage of partitions mapping between Kafka and Spark from adapting our key upon issuance of our Kafka messages. For an operation such as reduceByKey(), having its RDD already partitioned with the correct key avoids shuffle and thus improve performance of its jobs.
Once our data, ordered by store and category, are available via our Stream, we can then persist them into Cassandra.
From Spark to Cassandra
In parallel to "live" treatment of our receipts, we store them in our database in raw format using spark-cassandra-connector. This project developed by DataStax allows to easily interface Spark and in an effective manner with Cassandra.
// We save our calculation results into Cassandra
turnover.saveToCassandra("retail", "raw_receipts")
Using the default settings, this operation will persist batch receipts by taking care to group together tuples with the same Cassandra partition key. More generally, the connector leverages partitioning concept in Spark as well as in Cassandra during reads and writes because it allows to map a Spark tuple group to Cassandra partition (similar to Kafka - Spark connector).
Conclusion
We have just given ideas to develop an architecture answering a use case based on distributed, fault-tolerant and scalable open-source technologies. This example shows potential of the Kafka-Spark-Cassandra platform for the implementation of real-time architectures. Thanks to the features offered by Spark, we have a nice set of tools to process data. Increasingly used, this trio encounters positive feedback. However, it is required to deeply understand how each of these technologies works to correctly model its data, avoid mistakes and take full advantage of its cluster resources.