From the field: trends about data architecture
As a data architect, I had over the last years the opportunity to witness and to contribute to clients’ data transformation across various industries. Whether they are business needs, pieces of data strategy or architecture topics, I have seen a strong diversity in organizations’ challenges and appointed solutions but also very similar ones, nurturing over the time both my view on trends and my convictions about them.
In this blog post, I propose to share some of these trends and convictions including data products, as-a-service data capabilities and user empowerment.
Trend #1 - Shifting from datasets to data products
Data products as extended datasets
Prior to speaking about data products, we should start with datasets. It is the commonly-used wording to literally designate a set of data. And it designates nothing else but a set of data handled as an artefact by itself.
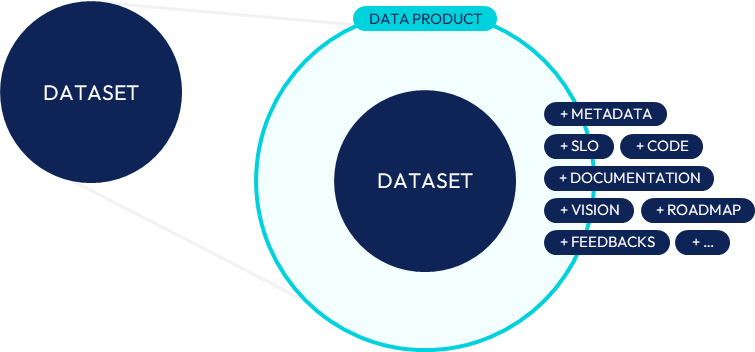
Data product, as an extended dataset.
By infusing a bit of product into data, we have extended datasets with new elements such as metadata (describing the data itself), documentation, pipeline code, service level objectives (SLO) but also product-typical ones such as vision, storymap, user feedbacks and satisfaction monitoring, etc. This extended view contributed to the shift from dataset to data product.
Thus, a data product becomes a new type of artefact standing as the new elementary unit of a data architecture. In addition, it is driven by its value proposition to consumers, like any digital products. Differently said, no value to data consumers means no data product.
Drivers for data products
Beyond such a shift, data products are thought and designed to foster efficiency in data sharing across an organization, making any of them useful, used and reusable.
Useful
A data product is expected to be useful as it embodies an altruistic approach to data, aiming to support other data products with value-added data, thereby creating an ecosystem of producers and consumers. It thus becomes valuable.
Used
A data product is used because there is a need, because value can be extracted out of it and also because its proposed data is trusted. Value and trust are closely related as no trust in data generally leads to not consuming.
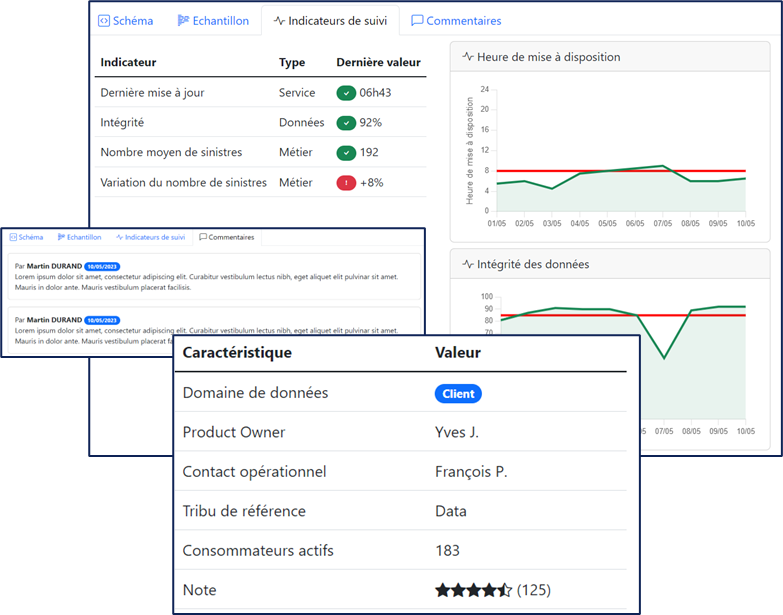
Example of data product metrics exposure.
Transparency is a key dimension in guaranteeing trust in data in organizations, via for instance the exposure of a history of measurements of various technical and business-oriented metrics to then let consumers decide whether or not the data product complies with their quality expectations. It may for some as it may not for others.
Reusable
A data product is expected to be reusable to accelerate data sharing across data products following the build once, use many times principle.
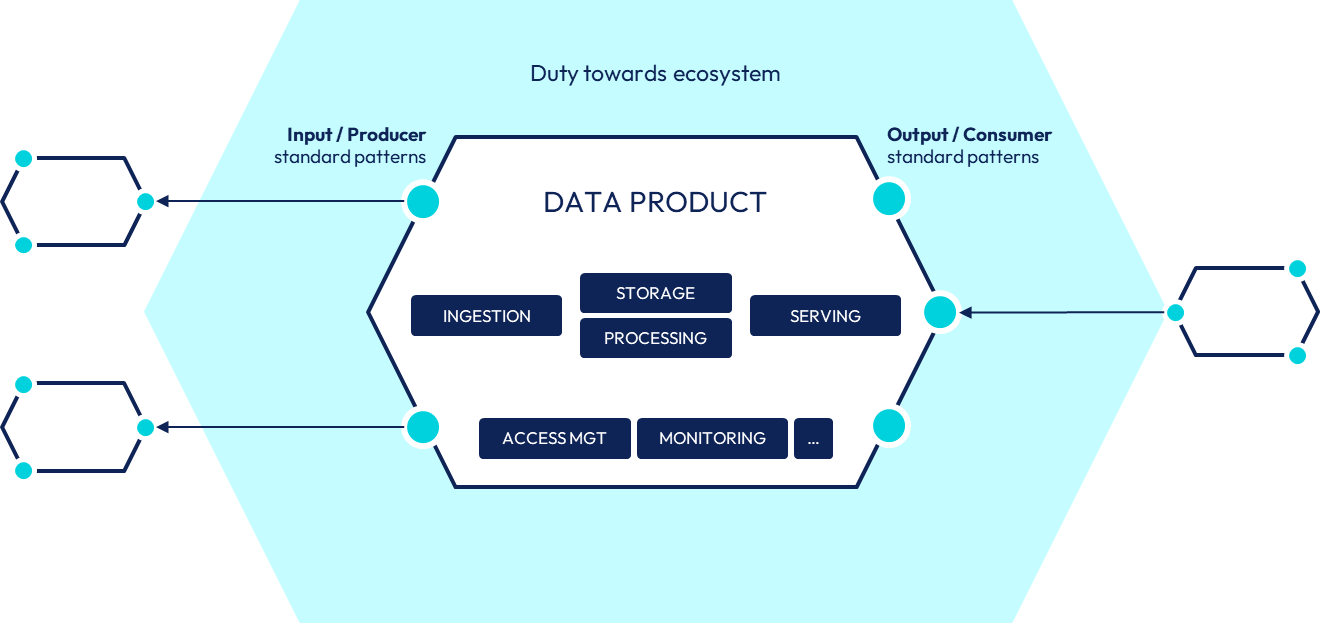
Zoom on data product components and surrounding ecosystem.
However, such reusability requires rigour and accountabilities towards the ecosystem of data products in terms of standardization to reduce complexity: aligned consuming and producing patterns, consistent business data modeling across data domains…
In a nutshell
A data product is an augmented view of a standard dataset.
A data product is the most elementary unit in a data architecture.
A data product meets design characteristics that are to be derived within each organization based on IT standards and expected benefits or issues to be solved.
Trend #2 - Making data products real
Centralize the access to the list of data products
Data catalog, data marketplace, data portal… Each organization comes along with its own name for this critical component. However, the central aspect of it is something about which all agree: making data sharing possible means as a very first step being aware of what is existing. And although data products may be spread across multiple platforms, from a consumer perspective, the entire legacy must be listed and searchable from a single UI for the sake of user experience.
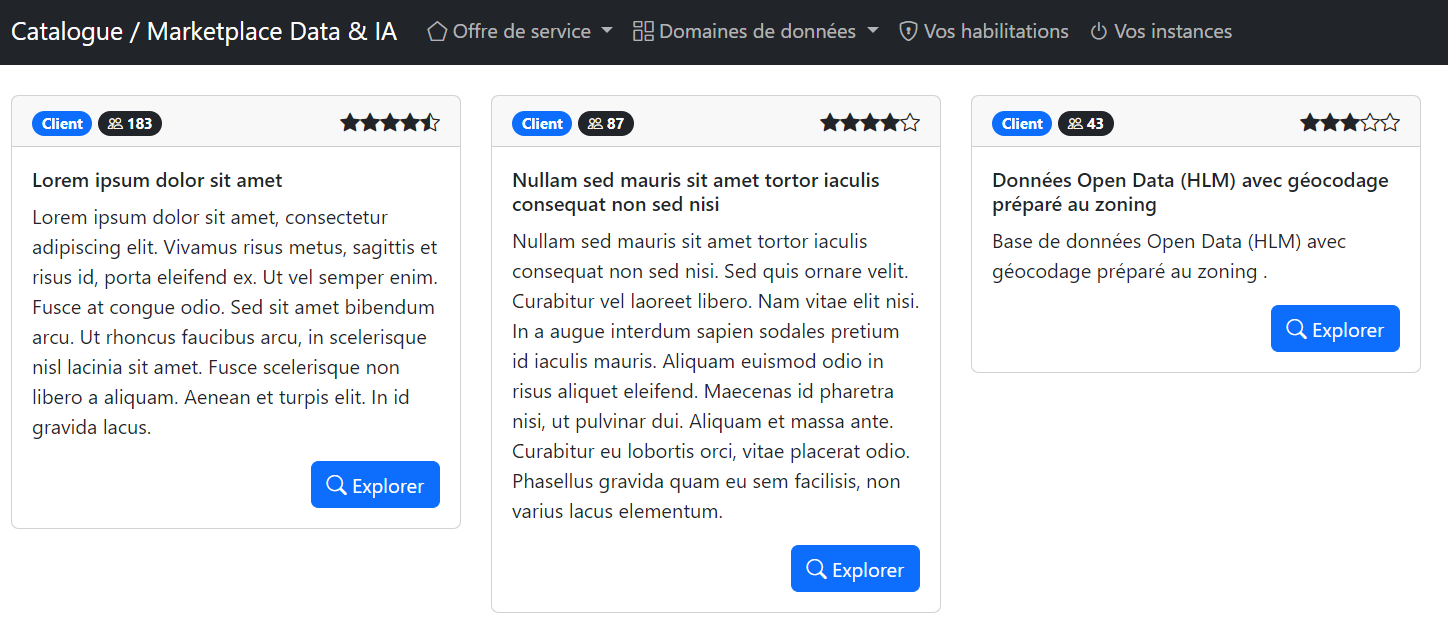
Example of a standard list of data products.
Automate data products information updates
Such a central data catalog must live along with the data products releases to keep up-to-date. Through product culture, promoting closer relationships with consumers also induces faster data product evolution and fixing cycles. And so should its catalog information over these cycles.
Leveraging programmatic interfaces in data product code to update on release the data catalog with all information about metadata, documentation, etc is a must-have to guarantee alignment between code and data product information.
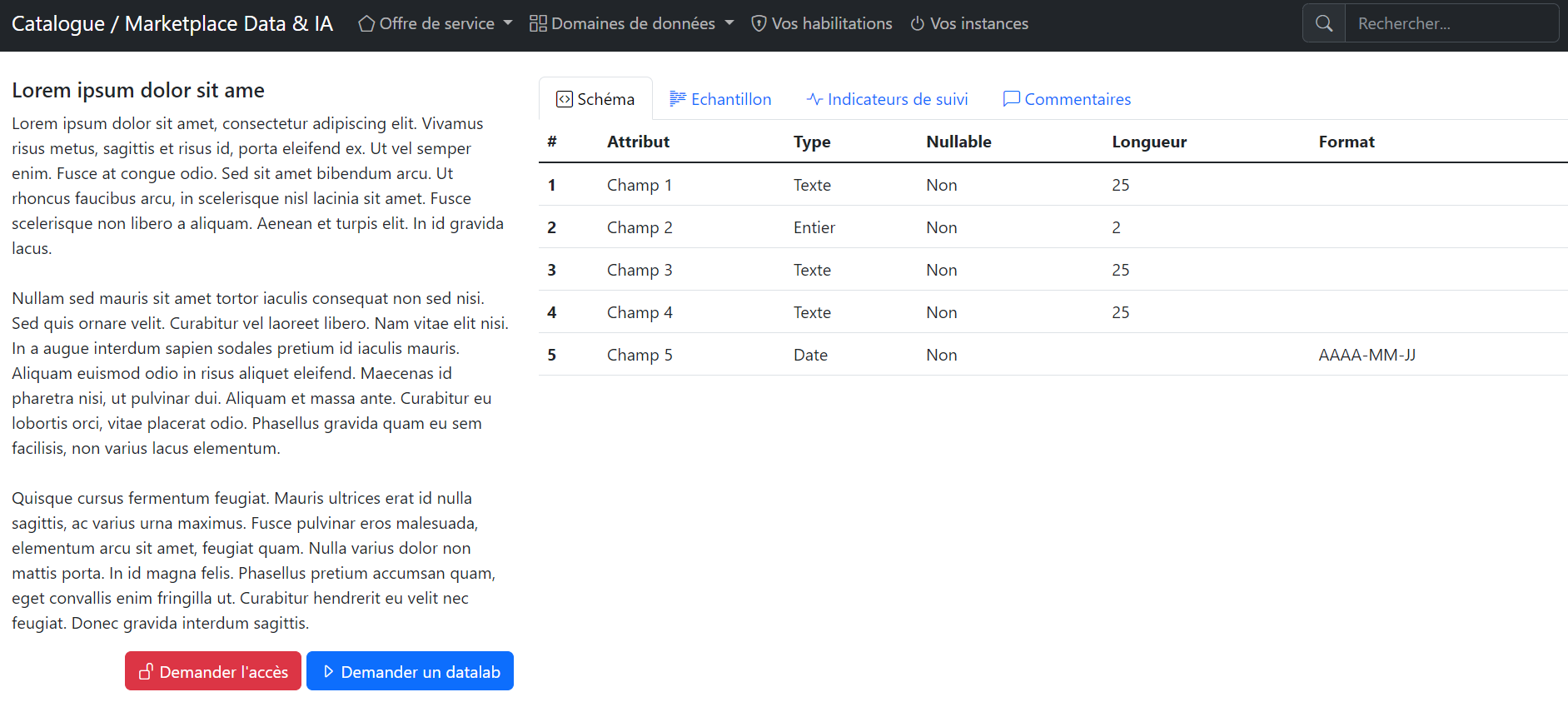
Example of data product first level of documentation.
Standardize producing and consuming patterns
The more standardized are data products in terms of architecture and design principles, the easier they will enable data sharing. Beyond the interfaces to a central data catalog that are to be common to all data products, ingestion (input) and serving (output) patterns are also main design elements to harmonize.
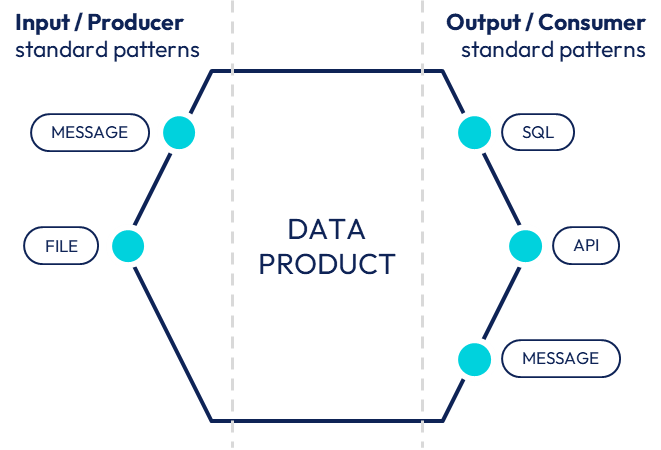
Example of producing / consuming pattern for a data product.
Following a pragmatic approach, data products are expected to all serve their data the same way: for instance, via SQL-queryable interface, via flat files… A large variety of use cases sometimes lead to a large variety of consuming / producing patterns. So, how to meet both pragmatic standardization and diversity of such patterns?
One possible solution is about introducing minimal but mandatory patterns while allowing additional but optional ones. All data products may be required to serve their data through SQL-queryable interfaces while some of them might extend their consuming patterns with flat files or message queue when relevant.
Consistently manage access rights to data products
Standardization is also about access right management over the various data products. Several benefits are seen in having a central approach of this data security topic when it comes to submit access requests and to actually provide access:
One single experience for users to request access to a data product, including automated (but not systematic) approval process and tracking over the time
One single experience for data product owners to have at any point of time a clear view about who is accessing their data product, for which usage and for which period of time
One single granularity (e.g. table-level, bucket-level…) and way to apply access to a data product to avoid workarounds
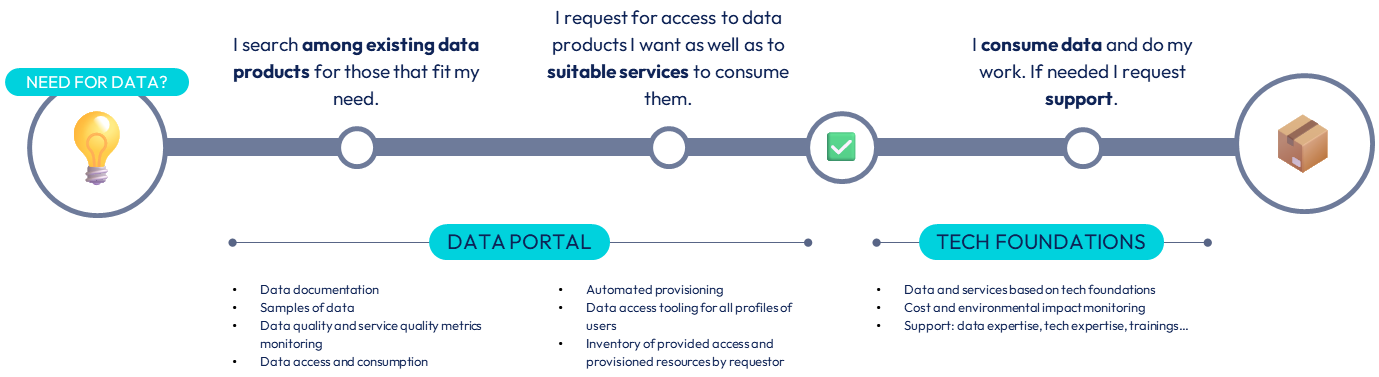
Simplified view of a user experience workflow in access data products.
Note that data product owners are accountable for the compliance of their respective data products regarding data protection rules of its organization.
Design your own data product framework
As seen before, the standardization of some data product design elements contributes in accelerating their ability to serve other data products (data sharing, reusability) through simplification. Such a consistency can be achieved through the definition of a first data product architecture framework aiming at stating what is mandatory and what is optional to any data products.
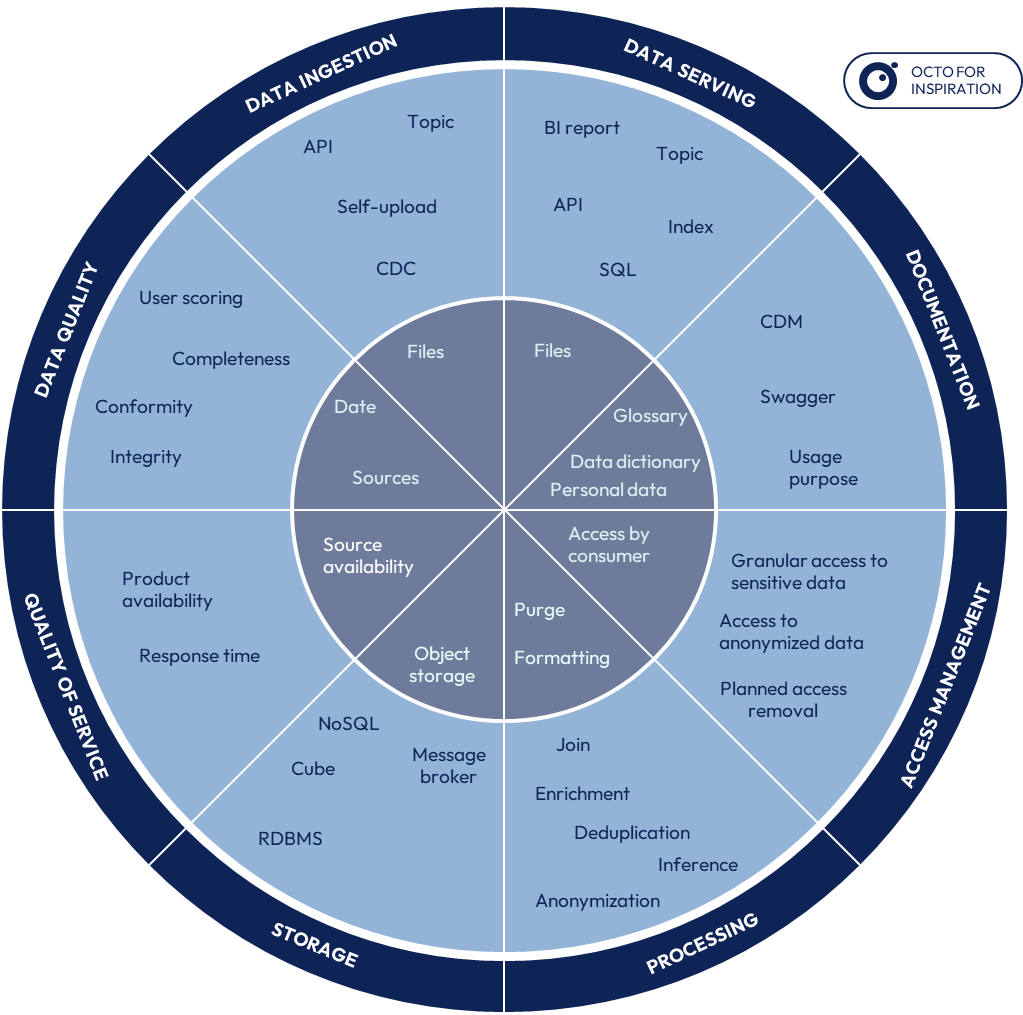
Example of a data product architecture framework (mandatory in grey, optional in light blue).
Above is the overview of such a framework that can be used as an initial version. For instance, data ingestion and serving are mandatorily based on flat files, both relying on object data storage. As data quality metrics, it is expected that each data product shares data freshness (“date”) along with data sources reception status (“sources”).
Note that this framework can keep evolving in the future. Associating to such changes the different data product teams is essential to include operational feedbacks and facilitate adoption of new versions.
In a nutshell
Data product oriented architecture requires consistency and standardization to maximize benefits.
Data products enable team and consumer autonomy and require responsibilities in return.
Data portal / catalog is the unique entry point for all consumers of data products.
Trend #3 - Consume data capabilities as-a-service
Move from coexisting platforms to unified platform
Looking back over the 1990s, data has always been there, stored, processed and served through infocenters, data warehouses or, more recently, data lakes or platforms. What has changed however is the variety of use cases data was expected to be involved in. Infrastructure assets built in organizations to support data were quite specialized by family of use cases (BI / Reporting, Advanced Analytics / AI, Operational) and very few were actually able to cover several of them, mainly for technology maturity reasons.
Organizations had to add new infrastructures to provide capabilities to support new families of use cases. However, at this point of time, datasets and infrastructures were highly coupled, meaning that one dataset had to be replicated to be used in the coverage of different types of use cases.

Overview of non-exhaustive list of data-related technologies (source: firstmark.com).
Over the last decade, the market of data technologies has significantly scattered into smaller and specialized vendor solutions, generally relying on common and open standards to ease integration and interoperability with the rest of the tech ecosystem. We have moved from coexisting data platforms or infrastructures to a unified ecosystem of capabilities provided by various underlying solutions, where datasets are much less coupled to these capabilities.
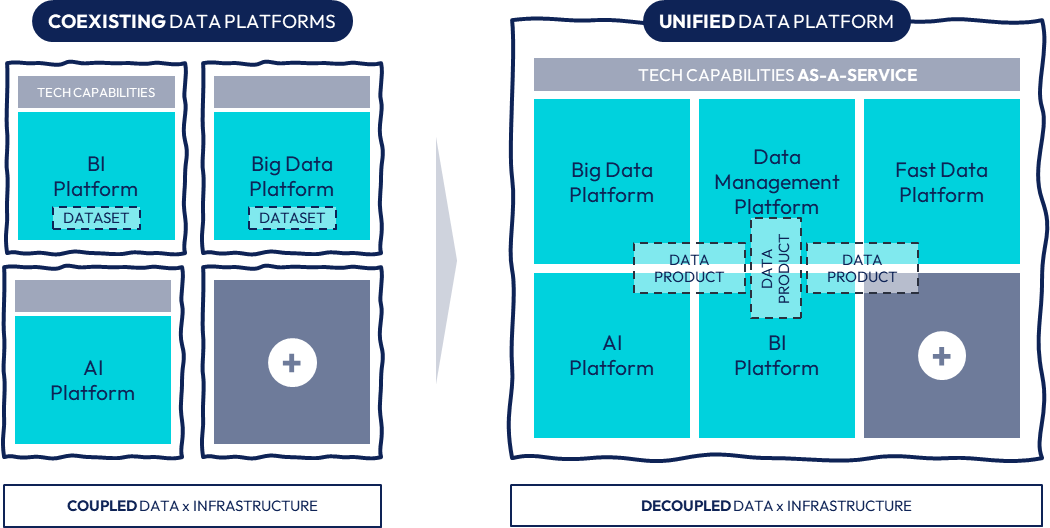
Shifting from coexisting platforms to unified data platform.
With the emergence of data product oriented architectures and the shift from datasets to data products, such a unified view enables data products to pick and choose within the as-a-service capabilities made available by the organization the right data services to better serve their consumers.
Develop a data service offering as-a-product
Real accelerators to all data product teams, as-a-service capabilities are by themselves a product to envision, design, build and run. But it is only the emerging part of a larger element named data service offering and that proposes to these teams more than just tech accelerators or assets.
In addition to these tech assets, a data service offering should also include a catalog of services towards data product teams and users in order to be supported in the proper use of such assets. These services can be about audits, expertise, training, etc.
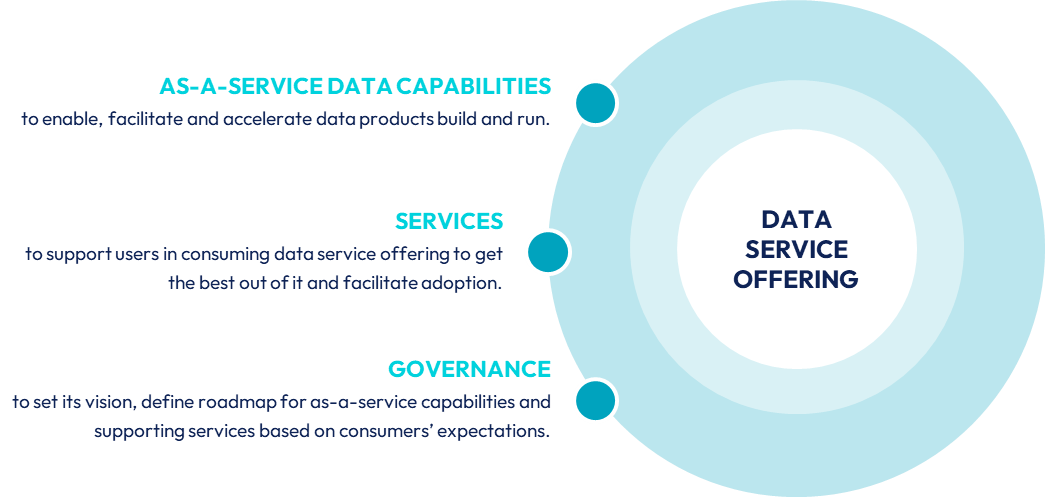
The three main components of a data service offering.
And like any products, the service offering must come with a clear governance that will set and share a vision and the suitable roadmap by collecting feedbacks from users about existing tech assets and services but also by preparing the next ones to align business requirements and assets availability as much as possible.
In a nutshell
A data infrastructure proposes capabilities to facilitate data products build and run.
A data infrastructure is an owned product with its own vision and roadmap.
Data infrastructure is one product of a service offering including not only tech capabilities but also services to consumers (e.g. training) to guarantee the proper use of such capabilities for their data products.
Trend #4 - Empower users with data to leverage organization scale
Among the trends emerging from business needs, there is one that is massively requested by the population of business users: their empowerment in accessing and manipulating data. Depending on organization and the width of empowerment, it may take different forms or names such as data democratization, self-service data preparation, self-service reporting, etc.
Different populations of users, one common goal
Whereas I used to classify populations of users in some categories such as business users, business data analysts or data engineer / scientist, all of them have the same objective: use data to answer questions in link with organization business strategy. Some build industrialized data pipelines, others design machine-learning models or analyze metrics.
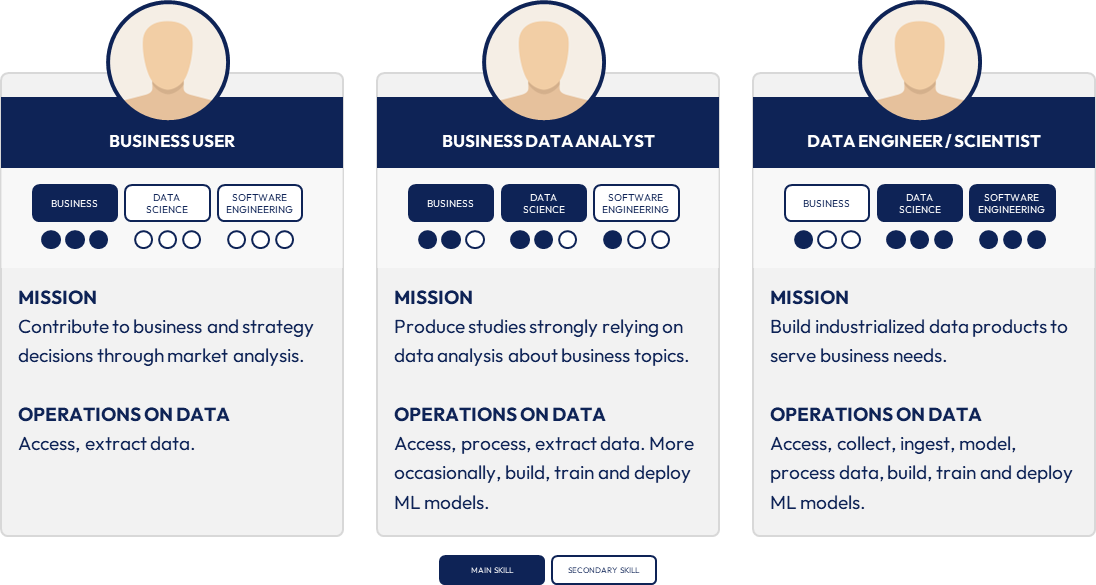
Example of a high-level classification of users.
What differs however is the skillset of each of these populations and how they expect to fulfill their objective. Business users are definitely more business-oriented than tech-oriented and the reverse is generally true for data engineers.
But beyond the comparison, it must be understood that the same objective cannot be met the same way, meaning with the same tooling, for all populations. It definitely requires to fit the skillset of consumers to actually empower them. The data service offering seen in the previous part is here to guarantee that a proper tooling is available to all identified families of data consumers.
Expected benefits
Enhanced reactivity: quickly answering adhoc requests, studies…
Reduce dependency on delivery teams: keep delivery teams focused on industrialized data products.
Refine requirements prior to delivery: test, explore, refine use cases, rules prior submitting them to delivery teams.
Comply with data protection: reduce risks for shadow IT and data dissemination out of authorized platforms.
Challenges to tackle
Keep autonomy under control: reduce risks for shadow IT and data dissemination out of authorized platforms.
Efficient access management process: improve permission granting process through automation and reactive approvals, keep track of identity and purpose of granted accesses.
Scalable data capabilities: with significantly higher number of users, platform capabilities must be ready to address such new workloads.
Monitor resources and usages: avoid cost drift due to the misusage of provided services.
Ways to empower users
Going further, several paradigms exist today to increase autonomy of business users in handling data:
Low-code / No-code: data democratization through low-code / no-code with solutions (e.g. Dataiku, Prophecy).
Generative AI: perspectives from GenAI to create new opportunities for data self-service but still are at experimental stage (e.g. LakehouseIQ, LangChain, Databricks Genie)
Skilling: skilling business users about data and coding as a way to democratize data access and operations.
In a nutshell
Business users and data engineers have different data skillsets and must therefore have their needs covered differently.
Enabling standard data capabilities for business contributes in maximizing value out of data.
Empowering business users provide autonomy in exploring and tuning use cases, allowing data product teams to refocus on industrialization only.
A clear governance must be defined to avoid misusing capabilities, such as shadow / pirate industrialization of use cases.
Conclusion
Although they are named trends, these trends briefly introduced in this blog post do not apply to all organizations. If so, they probably do not have one single solution fitting all organizations. Contextualizing and customizing while searching for solutions to address such challenges remain for data architects the starting point to achieve pragmatic and realistic solutions.
Note that many other trends or challenges are faced by organizations today and would also have deserved being mentioned and detailed in this blog post: data platform modernization, living with legacy, hybrid data platform, sovereignty, reversibility…
–
Notes
- Data catalog / marketplace screenshots are based on a web mockup.
References
- L’architecture de la donnée comme un produit : pourquoi et comment (La Duck Conf 2023, Olivier Wulveryck, Olivier Acar)
- Pour être "data-centric, faut-il centraliser ? (La Duck Conf 2021, Renaud Andrieux, Julien Assémat)
- Data Mesh: Delivering Data-Driven Value at Scale (April 2022, Zhamak Dehghani)
- Various contents and figures from Antoine Gaudelas (OCTO Technology), Jean-Baptiste Larraufie (OCTO Technology) and Meriam Bouguerra (OCTO Technology)