Fractales et regard Lean pour simplifier le pilotage d’un train SAFe (Partie 1)
Dans cet article, nous souhaitons montrer comment le regard Lean originel peut aider à simplifier le regard sur une organisation SAFe et concentrer les équipes sur les bons sujets; à savoir livrer de la valeur au client.
Nous nous appuierons pour cela sur :
- un contexte spécifique de programme SAFe chez un grand acteur du numérique français ;
- l'image du modèle des fractales pour appréhender plus facilement le dispositif ;
- la distinction entre valeur opérationnelle et valeur business ;
- l'utilisation des principes Lean de flux tiré et de boucles de rétroaction rapides pour piloter l'ensemble du dispositif en se concentrant sur la valeur.
Cette première partie de l'article se concentre sur les points #1 et #2. La présentation du contexte, du problème et de ses causes dans le cadre d'un programme SAFe chez un grand acteur du numérique ; et la présentation du principe des fractales comme moyen de visualiser plus simplement le pilotage de l'ensemble du dispositif.
Introduction : regard Lean et simplification du flux
UX = Simplification
Jesse James Garrett est l’inventeur de la discipline User Experience. Dans sa remarquable présentation à l’USI en 2012, il explique qu’un élément essentiel du design d’un service numérique est sa capacité à limiter les choix proposés à l’utilisateur pour soulager la charge cognitive et simplifier l’utilisation dudit service.
Cette capacité de simplification pour concentrer l’attention de l’utilisateur sur les sujets les plus importants est une des valeurs irréfutables du design de l’expérience utilisateur.
Si on transpose cette vision simplificatrice au monde des méthodes et de l’agilité, on peut mesurer le challenge extraordinaire qui est alors proposé aux entreprises qui, se voulant être agiles, mettent en œuvre le framework SAFe. Malheureusement, la relation SAFe et l’agilité n’est pas si directe : Jurgen Appelo plaisantait ainsi que la métaphore du train était probablement la moins agile que l’on puisse imaginer.
Regard Lean Vs. Lean Mindset de SAFe
Le blog #hypertextual a expliqué comment SAFe avait mal compris le Lean Mindset, utilisé comme un buzzword parmi une kyrielle d’autres dans ce produit marketing du monde de conseil. De la même façon que l’UX simplifie l’usage des applications, on pourrait de la même façon présenter le Lean comme une Flow Experience qui simplifie l’utilisation du flux de valeur et restreint le champ d’attention de chacune et chacun sur la valeur client.
Comme le dit fréquemment l’expert Lean et Agile Régis Médina, “le Lean nous aide à enlever la m****e des yeux” : nous vous proposons donc de regarder cet article comme un moyen de vous abstraire de l’inutile dans l’agilité à l’échelle pour n’en conserver que l’essence du flux.
Une démarche essentielle car, de la même façon que les frameworks de langages de programmation objet (en particulier Java) ont apporté des niveaux d’abstraction d’une complexité souvent inutile dans les DSIs durant les années 2000 et 2010 (voir cet article de Ilya Suzdalnitski : Object Oriented Programming : The Trillion Dollar Disaster), on pourrait avancer que SAFe apporte aujourd’hui une complexité organisationnelle inutile et très coûteuse : nous sommes passés de l’ingénierie logicielle à l’ingénierie organisationnelle et, dans les deux cas, le client a été le grand perdant.
1. Etude de cas
Des équipes remarquables
Dans l’organisation que nous accompagnons, les nombreuses équipes (plus de trente) ont déjà accompli des choses remarquables : elles livrent en production au terme de chaque itération ; elles pilotent le Delivery avec des indicateurs Accelerate ; elles sont alignées sur la livraison de valeur à travers des User Stories ; malgré la formidable croissance du dispositif (passé de 6 à 35 équipes en un an) elles continuent à livrer régulièrement à leurs clients en production en maîtrisant la qualité (très peu de bugs en production).
Il s’agit d’un programme de plusieurs dizaines de millions d’euros : nous avons déjà croisé des programmes aussi importants qui n’avaient rien livré en production. Tout cela est, comme expliqué plus haut, remarquable. Pour encadrer cette hyper-croissance (passée de six équipes à trente de plus en un an), l’entreprise a opté pour un framework SAFe minimal qui essaye de se concentrer sur l’essentiel. Il s’agit d’un cas d’implémentation différent de celui évoqué plus haut, à savoir des grandes organisations existantes qui passent à SAFe pour “devenir agiles”.
Problème
Au final lorsque l’on regarde le delivery de l’Incrément Produit (PI) à son terme, tel qu’il est suivi grâce à JIRA par l’équipe, on obtient 81% de taux d’avancement. L’unité utilisée ici est le Story Point. Cela veut dire que la somme des Story Points livrés dans les User Stories DONE du PI est de 81% de la somme totale des US du PI.
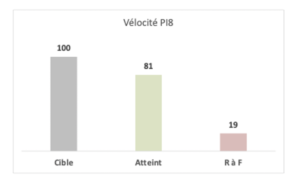
Vélocité programme en Story Points
__L’indicateur du client__
Cela peut sembler un bon résultat au premier regard. Dans la vision des équipes, ce qui compte c’est de livrer des User Stories, parce que les Story Points sont l’indicateur clef d’avancement du programme, et ce indépendamment des Features auxquelles elles appartiennent.
Mais si on regarde depuis la perspective des clients, l’unité d'œuvre qui représente de la valeur pour eux ne sont pas les __User Stories__ mais les __Features__ (ensemble cohérent et spécifique de User Stories) qui représentent des fonctionnalités complètes, permettant d’accomplir quelque chose de valeur pour ces utilisateurs et utilisatrices_._
Nous sommes dans la construction de la première itération majeure depuis le premier MVP (en production avec un client). Ces fonctionnalités représentent un Minimum Viable Product (MVP) pour la seconde génération de clients et un second ensemble cohérent de User Stories. Et là, le résultat n’est plus le même.
Il y a dans le Product Incrément l’objectif de livrer 193 Features et seulement 117 sont livrées soit seulement 60%.
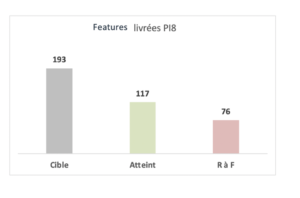
Vélocité Programme en features livrées
Lorsque nous accompagnons une équipe, la question Lean que nous nous posons toujours est celle de Art Byrne : qui doit apprendre quoi pour réussir ? Dans ce cas précis, l’ensemble de ce programme SAFe doit apprendre collectivement à aligner l’ensemble des flux de valeur et des activités pour livrer des Features.
__Analyse des causes__
Avant de se précipiter dans des solutions, prenons un moment pour comprendre les problèmes réels et spécifiques rencontrés par ces équipes, sur ce programme.
Un Scrum Master (à un niveau de maturité très avancé) me répondra ainsi, alors que je lui demande pourquoi ils ne terminent pas telle Feature pour laquelle il ne reste qu’une petite User Story : “nous avons préféré travailler sur une autre US plus complexe (i.e qui apporte plus de Story Points) et qui apporte plus de valeur que cette petite US à faible valeur”.
On voit ici une autre dimension de la sous-optimisation que permettent SAFe et JIRA : les équipes concentrent leurs efforts pour sortir des US (et les Story Points correspondants, car c’est l’indicateur d’avancement suivi) plutôt que terminer des _Features (_et donc livrer de la valeur pour les utilisateurs). Ainsi, dans le cas de cette équipe, plusieurs Features sont engagées mais aucune n’est terminée.
__Gestion des dépendances__
Une seconde cause de problème est liée à la gestion des dépendances. Comme le produit est encore jeune, des développements en parallèle sont menés dans les différentes équipes produit. Ces dernières ne peuvent pas s’appuyer sur des API existantes : elles doivent d’appuyer sur des APIs en cours de développement. Cela cause de nombreux sujets de dépendances entre équipes produit.
Un exemple : une équipe B qui doit livrer une dépendance (API à consommer) à une équipe A va, durant son sprint, en changer la signature sans mettre à jour la documentation (parce qu’elle n’a pas le temps). L’équipe B a terminé sa User Story et elle compte les Story Points correspondants comme DONE alors que l’équipe A ronge son frein et doit perdre 2 jours à changer son implémentation d’invocation de l’API de l’équipe B. Nous avons vu ainsi une équipe A qui a dû réécrire cinq US à trois reprises ! Un bel exemple de sous-optimisation.
Autre sujet de dépendances : l’API livrée ne retourne pas toutes les informations attendues par l’équipe C car pour elle il était implicite que l’API de l’équipe D allait retourner telles ou telles informations. Un échange rapide avec la Scrum Master de l’équipe D montre qu’elle sait quelle contre-mesure utiliser pour éviter ce genre d’écueil : un atelier parcours client. Mais elle concède ensuite qu’elle n’a pas eu le temps de mener cet atelier.
Cet exemple de déconnexion entre l’indicateur suivi par les équipes et celui qui est important pour le client illustre parfaitement comment le Lean Mindset de SAFe est envisagé et pourquoi ce framework forme avec l’outil JIRA un des suspects principaux dans l’enquête sur la mort de l’agilité, telle que la définit “Pragmatic” Dave Thomas, un des signataires du manifeste. Comme le rappelle Mary Poppendieck dans cet entretien : “Measure is the way you shape the work, don’t mess with it”.
__Des Features qui ne sont pas Ready__
Dernier point de blocage identifié : des entrants KO. En regardant de plus près un échantillon de 73 Features avec les Scrum Master et PO concernés d’une dizaine d’équipes, on se rend compte que 28 sur 73 (38%) sont entrés en phase de réalisation sans être Ready. Ce qui veut dire que de nombreux sujets n’étaient pas finalisés en termes de conception et de préparation de la réalisation, sujets qui ont causé des allers-retours, des attentes, du rework, du travail inutile : bref des gaspillages, de la frustration pour les équipes et des points de tension entre elles. Les causes principales identifiées sur cet échantillon [Note : une Feature peut être KO pour plusieurs raisons] :
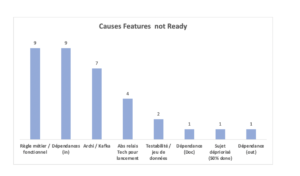
Histogramme causes de dépendances KO
On voit bien ici l’importance (sur laquelle nous reviendrons plus loin) d’avoir des entrants de qualité pour aider l’équipe à réussir son Delivery. Une des équipes a ainsi décidé d’avancer sur leur features malgré l’absence de revue par l’équipe d’architecture (celle-ci n’a pas pu valider l’architecture avant le lancement de la réalisation de cette feature). Lorsque trois semaines après, l’équipe d’architecture sera enfin disponible, elle identifiera un risque majeur au niveau des performances et leur fera refaire leur développement : trois semaines de travail pour 4 personnes mises à la poubelle.
Notons que l'on parle ici d’une Feature qui est Ready lorsque l’on démarre la phase de réalisation. Cela ne veut pas nécessairement dire lors du PI Planning. Si une Feature est suffisamment dégrossie (estimation macro, risques architectures identifiés) sans avoir une conception plus avancée, elle pourra tout de même entrer dans le PI, avec un ou deux sprints préparatoires pour la rendre Ready avant de lancer la réalisation. Il est important d’accepter une incertitude plus importante, à explorer, au niveau d’une Feature que d’une User Story. Les travaux d’introspection et d’analyse menés suite à la livraison de la Feature (voir plus loin dans la description du Flux Tiré pour le pilotage des Features) permettront de mieux explorer cette incertitude et d’en tirer des enseignements qui éclaireront les phases de conception futures.
2. Fractales : une image pour porter un regard Lean sur l’agilité à l’échelle
Définitions
Qu’est ce qu’un Fractale ? C'est un objet géométrique « infiniment morcelé » dont des détails récurrents sont observables à une échelle arbitrairement choisie. En zoomant sur une partie de la figure, il est possible de retrouver toute la figure (voir la définition Wikipedia). Cette figure géométrique a la particularité d’avoir des détails identiques quelle que soit l'échelle à laquelle on la regarde.
En d’autres termes, nous pouvons analyser un motif à un certain niveau d’observation et si on zoome ou dézoome à d’autres niveaux d’observation, on retrouve ce même motif, comme on peut le voir dans la courbe de Koch ci-dessous.
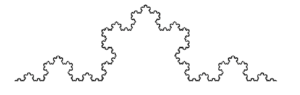
Courbe de Koch
Quelques exemples de fractales dans notre vie : La fougère, qui est composée de plusieurs fougères, le chou romanesco, les frontières d’un pays etc... ou encore cette vue hypnotisante d'un bord de mer.
{kind=link}
Fractales et agilité
Mais alors, quel est le lien entre ces notions de Fractale et d’Agilité à l'échelle ? Et bien on peut avancer que la première notion peut aider à expliquer la seconde. Peu importe le niveau où on se situe dans notre organisation, en zoomant ou dézoomant on retrouve le même motif de pilotage opérationnel.
On retrouve des questionnements similaires et un même découpage du processus à tous les niveaux de pilotage d’un programme SAFe. Le seul élément qui diffère est l’unité d’oeuvre autour de laquelle s’organise le questionnement, unité d’oeuvre spécifiée pour chacun des niveaux ci-dessous :
- équipe de Delivery (perspective opérationnelle) : l’unité d'oeuvre est la __User Story__
- Train, qui regroupe plusieurs équipes (perspective tactique) : l’unité d’oeuvre est la __Feature__
- Programme qui regroupe plusieurs trains (perspective stratégie produit dont il est fortement recommandé que ce niveau soit en connexion directe avec un Objective & Key Result - OKR de l’entreprise). L’unité d’oeuvre suivie est l’Epic ;
Pour la suite de l’article nous utiliserons ces trois niveaux de pilotage (et unités d'œuvre).
Notons qu’il correspond à chacun de ces trois niveaux de pilotage des niveaux d’incertitude différents : plus l’unité d’oeuvre est petite et plus l’incertitude est faible. On doit prendre garde à ne pas vouloir définir des niveaux de préparation trop détaillés a priori car sinon on retombe dans les travers du cycle en V et de l’Analysis Paralysis. Pour autant, il est important de travailler dans le cadre des étapes d’amélioration à la compréhension a posteriori des causes d’écarts entre le prévu et le réalisé (voir description pull flow). C’est dans l’exploration de ces écarts que gisent des potentiels d’apprentissage et des leviers de réduction des incertitudes pour les Features et Epic à venir.
[Note : dans un soucis pédagogique, le champ de cet article est restreint aux trois niveaux Epic, Feature et US - on pourrait tout à fait rajouter le concept d’Initiatives, en tant qu’agrégat d’Epics, mais cela n’apporterait qu’un niveau de complexité supplémentaire sans réelle valeur à la démonstration].
Les trois niveaux de Mike Cottmeyer
Le schéma ci-dessous, tiré de la présentation “Agile Program And Portfolio Management” de Mike Cottmeyer, décrit les trois Tiers, que l’on peut voir comme les trois niveaux de pilotage de l’agilité à l’échelle.
Depuis la perspective des Epic gérées au niveau du portefeuille projets, on peut zoomer et arriver au niveau des Features, gérées au niveau du programme, Features, qui, en s’agrégeant, composent une Epic.
En zoomant encore, on arrive au niveau des User Stories, gérées au niveau de l’équipe delivery, et on peut poursuivre l’exercice et arriver au niveau de tâches techniques qui composent la US. Un même motif se répète à une granularité plus fine à chaque fois que l'on explore notre organisation à l'échelle.

Piloter le programme en flux tiré
Dans sa présentation, Cottmeyer propose de piloter le Delivery au niveau des équipes avec une approche Scrum (validée et éprouvée) et de piloter le pilotage des unités d’oeuvre de plus haut niveau (Features et Epic) avec un pilotage en mode Kanban en utilisant le principe au coeur du Lean : le flux tiré __(Pull Flow)__.
Dans ce principe exigeant mais vertueux, l’ensemble de l’organisation se cale au rythme du client ce qui signifie que :
- on définit le nombre __d’Epic__ et de __Features__ à livrer par unité de temps. Dans l’exemple du programme cité plus haut, il y a 200 Features à livrer par incrément de 10 semaines : cela fait donc 20 Features par semaine ;
- on limite le travail en cours (WiP - Work In Progress) avec le fameux principe du Stop Starting, Start Finishing. On ne démarre pas au niveau d’une équipe de nouvelle Epic ou Feature tant que la précédente n’est pas terminée (ce que ne font pas aujourd’hui les équipes du programme vu plus haut car 1/elles se concentrent sur les Story Points livrés et 2/sont bloquées sur de nombreux sujets : dépendances, disponibilité environnement, disponibilité rôles clefs tels que Architectes etc …).
- l’ensemble de l’organisation se met à la disposition des équipes, chaque jour, pour supprimer les obstacles qui les empêchent de sortir telle Feature ou telle Epic. On peut ainsi “renverser la pyramide” et s’assurer que les niveaux de pilotage supérieurs se mettent au service des équipes de Delivery qui livrent la valeur opérationnelle : le Servant Leadership en action ;
- les objectifs non atteints ouvrent des espaces de réflexion et d’amélioration à travers l’analyse des causes spécifiques des problèmes rencontrés pour identifier des contre-mesures actionnables à tester au plus vite et mesurer leur efficacité. Il s’agit là du but suprême du flux tiré : rendre visibles chaque jour les problèmes pour forcer les équipes à les traiter selon le Plan-Do-Check-Act (PDCA) et la méthode scientifique (i.e comprendre les causes, tester des contre-mesures, mesurer et faire évoluer leurs standards) et ainsi, à mesure qu’elles produisent, développer une connaissance plus profonde de leur flux de valeur, enseignements qui sont ensuite partagés dans les communautés de pratiques.
Après avoir présenté dans cette première partie le cas d’étude et la métaphore des fractales pour se projeter plus facilement dans chacun des niveaux de pilotage du train SAFe, nous vous proposons dans la seconde partie de cet article, de :
- mieux distinguer valeur business et valeur opérationnelle (afin de …) ;
- … comprendre comment le lean aide à construire un pilotage plus simple de l’organisation SAFe, sur la conception, le delivery et l’amélioration continue, en concentrant l’attention de l’ensemble de l’organisation sur ces deux notions de valeur.