Monter une filière No-Code - retours d'expérience dans la data avec Data Fusion - Part II/III
Cet article est le deuxième d’une série de 3 qui traitent d’un retour d'expérience autour de l’organisation d’une filière No-Code dans la data et avec l’outil Data Fusion de Google.
Article 1 - Contexte, cadre et description du projet
Article 2 - Les limites, les difficultés et les parades
Article 3 - Évaluations de Data Fusion et conclusions projets
Limites de l’approche No-Code
N’est pas ‘citizen developer’ qui veut

Le No-Code peut limiter le besoin de compétences techniques spécifiques, mais il ne peut pas faire de choix pour l’utilisateur. Dans le monde de la Data, les choix ont une importance d’autant plus cruciale qu’ils auront un impact sur des volumes de données très importants et sur les coûts et les performances associées.
Qui dit travailler avec des données, dit aussi bien souvent avoir accès à des espaces de stockage de ces données. Un utilisateur inexpérimenté et mal guidé pourra, le plus souvent par inadvertance, impacter les données de production (suppression, corruption, doublons, …). De même, certains choix comme l’outil de stockage ou la méthode d’indexation des données doivent être réfléchis selon leur utilisation.
Le No-Code dans le monde de la Data ne supprime donc pas le besoin de compétence en Data Engineering, mais il permet de mutualiser cette compétence sur plusieurs équipes, et donc d’en réduire la dépendance.

N’est pas ‘citizen developer’ qui veut
Ne pas tordre les outils

Data Fusion a été conçu pour être un ETL/ELT (Extract Transform Load/Extract Load Transform), et il doit être utilisé comme tel. Data Fusion doit être utilisé pour effectuer des transformations sur des données et les stocker afin qu’elles puissent être utilisées ultérieurement par des applications.
Voici les cas d’usage dans lesquels Data Fusion est adapté :
Réplication de base de données
Flux de données avec volumétrie/débit important (batch ou streaming)
Flux de données avec faible volumétrie/débit en batch (lancement du flux occasionnel ou régulier)
Cependant, Data Fusion ne doit pas être utilisé pour n'importe quel besoin de traitement de données. Voici une liste non-exhaustive de cas dans lesquels Data Fusion n’est pas adapté :
Flux de données avec faible volumétrie/débit en streaming (le cluster Dataproc va tourner 24/24 alors qu’il sera majoritairement inactif => coûts importants)
Traitements customs complexes
- Dans Data Fusion il existe des plugins permettant de coder des snippets de code pour implémenter des transformations de données customs. Il faut limiter l’utilisation de ces snippets aux cas où il n’y a pas d’alternative car
Un snippet de code est moins efficace car non optimisé pour être exécuté en parallèle
Un snippet de code est moins lisible que des plugins “no code”
Aucun test n’est effectué sur le code dans les snippets, il faut donc limiter la complexité du code au strict minimum
- Dans Data Fusion il existe des plugins permettant de coder des snippets de code pour implémenter des transformations de données customs. Il faut limiter l’utilisation de ces snippets aux cas où il n’y a pas d’alternative car

Ne pas tordre les outils
Les coûts peuvent s’envoler selon ses usages

Illustrations et exemples = https://blog.octo.com/no-code-ou-low-code-pour-une-application-de-gestion-developpee-avec-airtable-zapier-that-is-the-question/
En gestion de données, le coût d’une plateforme (hors coûts humains) provient principalement des sources suivantes :
Gestion de l’infrastructure qui soutient la plateforme
Ressources utilisées pour traiter les données (les runners)
Licence/Abonnement aux outils utilisés
Ces coûts sont dépendants des volumes de données traités, et de la façon dont ils sont utilisés. Dans le cas d’un volume de données plus important qu’anticipé, ou des cas d’usages non anticipés, le coût d’usage des outils “pourrait” exploser.
Par exemple, dans notre cas, une étude a été effectuée en envisageant deux scénarios, un scénario correspondant à une BU avec de faibles besoins en gestion de données (10 bases de données, 5 applications), et un scénario correspondant à une BU avec des besoins moyens (25 bases de données, 10 applications).
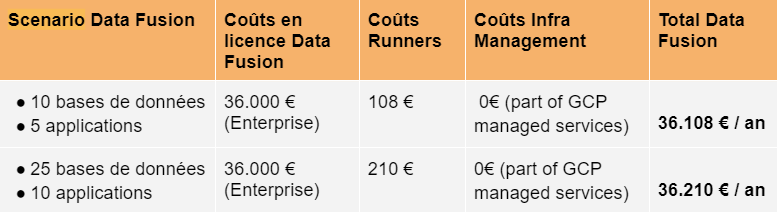
Le coût de licence peut varier selon le niveau de licence souhaité. Ici on considère le niveau de licence le plus élevé (i.e. Enterprise).
Attention, le coût des runners ne prend en compte que le processing par Data Fusion (taille du cluster X temps de run). A cela il faudra ajouter les coûts de stockage, requêtage de données éventuels (BigQuery, Cloud Storage, etc…) qui dépendent de l’utilisation qui en sera faite et dont la valeur est très variable selon les cas d’utilisation.
Les coûts liés à Data Fusion exclusivement n'explosent pas car la politique de Google reste la conquête d’utilisateurs sur son cloud et non la commercialisation de sa plateforme Data Fusion qui reste un moyen plus qu’un objectif. Les efforts, ou en tout cas sa stratégie masque à date les variations de coûts - ne pas être dupes non plus. Mais cela signifie aussi qu’à date si vos infrastructures mutualisées reposent sur GCP, la plateforme est particulièrement économique. Si vous n’êtes pas sur GCP, une étude s’impose et pour ce type de besoin cela reste clairement une opportunité à évaluer, car il sera plus facile de négocier avec un éditeur en phase de conquête, les prix catalogue n’ayant qu’une valeur informative.
Par ailleurs, une seule licence Data Fusion peut être partagée entre toutes les BUs. Concernant l’aspect multi-utilisateur, chaque BU aura alors accès à un namespace associé à un Service Account distinct. Si la cellule support prend en charge ce coût de licence pour l’ensemble des BUs, le coût pour une BU est donc de quelques milliers d’euros par an selon les utilisations.

Avec le No-Code lors du passage à l’échelle la facture peut vite monter… ou pas ;-)
Difficultés et parades d’une cellule support ; focus autour d’une filière data avec l’outil Data Fusion
Instanciations zombies
Les utilisateurs testent leur pipeline, évaluent la plateforme et puis les abandonnent, parce qu’ils ont validé ce qu’ils voulaient, parce que non convaincant, par flemme ou par simple oubli. Le souci est que cela consomme de l’espace de stockage, de la CPU et/ou de la bande passante s’ils tournent encore. Bref, c’est pas très éco-responsable tout ça et coûteux.
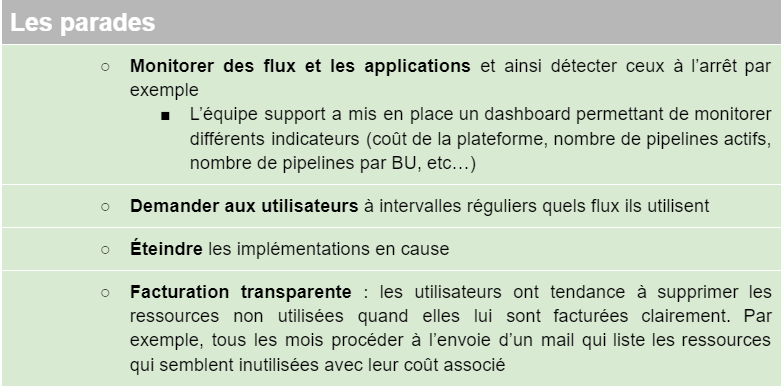

Potentiellement, il faut enterrer les instanciations zombies
Chute des performances
Une mauvaise conception des flux dans Data Fusion peut entraîner une chute des performances. Par mauvaise conception, nous entendons par exemple une mauvaise gestion du partitioning dans le stockage des données, ou l’utilisation d’un cluster Dataproc mal adapté aux besoins (trop petit ou trop grand).
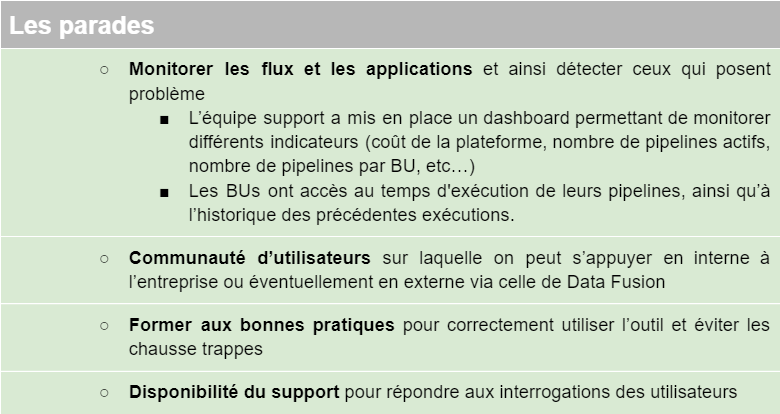

Une mauvaise conception des flux dans Data Fusion peut entraîner une chute des performances
Explosion des coûts
A l’inverse, la plateforme est très utilisée (succès + voir chapitre “Les limites”) ou bien les pipelines ne sont pas très bien optimisés et le coût d’usage alors explose.


Soyez prêt de vos sous, traquez l’explosion des coûts en cas de passage à l’échelle
Les équipes peinent à devenir autonomes sur la plateforme
Malgré le soutien de la cellule support, les tutoriels, les premières formations, les équipes sont à la traîne pour devenir autonomes sur la plateforme Data Fusion. Le manque de pratique pour certains ou simplement le fait que n’est pas “citizen developer” qui veut (voir chapitre “Les limites”) entraînent des pertes d’efficacité. Un comble sur ce type de plateforme !

Les développements custom prennent de plus en plus de place
La plateforme Data Fusion ne répondant pas suffisamment aux attentes des utilisateurs, ces derniers demandent de plus en plus de développements/adaptations spécifiques à la cellule pour répondre à leurs exigences. Au risque dans la durée d’avoir une plateforme No-Code plus spécifique (comme pour un développement à façon) que standard. Même si les développements spécifiques sont bien isolés et écrits dans les règles de l’art, le gain de productivité de l’approche par une plateforme No-Code fond du fait des coûts de maintenance dudit spécifique couplé aux coûts potentiels des tests de non régression lors de montée de version de la plateforme par exemple.


Les développements customs prennent de plus en plus de place, la solution devient de plus en plus compliquée à maintenir
La plateforme est buggée
La jeunesse de la plateforme Data Fusion et/ou parce qu’elle est encore peu utilisée présente des bugs y compris sur des fonctionnalités basiques. Le dynamisme de l’éditeur peut vite mettre fin à ce genre de situation et/ou avec l’aide de la cellule.


Data Fusion est une plateforme encore jeune
Gestion des responsabilités insuffisamment claire entre les ‘citizen developers’ et la cellule support
Gestion des erreurs/incidents
Au build, la base de connaissances, la communauté, la cellule support puis enfin l’éditeur si besoin permettront de résoudre l’incident. L’idée étant de faire en sorte d’aller le moins loin possible dans cette chaîne de résolution.
Au run, comme déjà évoqué, rendre les utilisateurs les plus autonomes possible est essentiel y compris dans la résolution des incidents. Toutefois, selon la criticité des erreurs, la cellule aura à suivre voire à intervenir.


Rendre les utilisateurs les plus autonomes possible; toutefois, selon la criticité des erreurs, la cellule interviendra
RGPD
Les plateformes américaines, les plus nombreuses dans les offres No-Code, sont incompatibles avec le RGPD européen (https://blog.octo.com/souverainete-et-cloud-quel-rapport/ ; chapitre “Les jurisprudences de la CJUE”). En résumé et pour faire simple, même si les données sont hébergées sur un serveur Européen, le droit américain est susceptible de s’appliquer et les données sont potentiellement mobilisables/interceptables à la demande d’un organisme de droit américains tels que la NSA, le FBI ou la CIA, etc. Enfin, les plateformes No-Code permettant un hébergement on premise sont rares et globalement limitent un de leur intérêt d’un déploiement rapide, transparent et automatisé pour l’utilisateur. Quelques points de vigilance s’imposent donc.

Note : Data Lineage inclus dans Data Fusion

Anonymiser les données
Et ensuite ?
Dans notre 3e et dernier article nous prolongerons l’appréciation de la plateforme Data Fusion au travers de l'évaluation de sa maturité en nous référant, entre autre, à notre grille d’analyse précédemment évoquée. Par ailleurs, on évaluera sa qualité au travers de son écosystème.
Nous terminerons l’article en tirant des conclusions générales sur le projet, le fonctionnement de la cellule support et sur la plateforme en particulier.