Feature Store : un outil clé pour la data science moderne
I) Quelles sont leurs origines, à quoi servent-ils et à qui sont-ils destinés ?
Une feature est une mesure d’une propriété d’une observation, plus prosaïquement, elle peut être l’âge d’un individu ou un mot extrait d’un texte. Les features, c’est l’or raffiné par les data scientists pour produire les modèles de machine learning.
Fréquemment, les problèmes qui surviennent dans un projet data science sont liés à ces features : à leur qualité ou à leur disponibilité notamment.
Un feature store est un point centralisé où retrouver ses features pour pouvoir les utiliser à travers divers projets.
Ils permettent de trouver des solutions à des problèmes récurrents dans la mise en production de modèle dans une organisation. Effectivement, ils sont pensés pour être particulièrement pertinents pour les entreprises ou les départements IA qui mettent en production beaucoup de modèles.
Les feature stores commencent à être utilisés dans la deuxième partie des années 2010, mis en place chez Uber, Michalengo (leur plateforme de ML qui sert aussi de feature store) a crû au point de gérer plus de 10 000 features au sein de l’entreprise. Depuis, des feature stores ont été adoptés par d’autres entreprises (retour d’expérience d’Atlassian).
Un florilège de problématiques qu’on retrouve régulièrement dans les projets data science que les feature stores cherchent à régler :
Faciliter le partage des features pour les réutiliser dans d’autres projets de l’organisation.
Au sein d’organisations, on voit souvent apparaître de la duplication de pipelines pour gérer un groupe de variables alors que ces pipelines sont déjà développés et maintenus, cela engendre des coûts supplémentaires (coût de développement, coût de gestion, de ressource calculatoire et de mémoire). En centralisant les features au sein d’une organisation (une entreprise par exemple), le feature store permet donc des économies de ressource.
Utiliser les mêmes features sur le dataset de training et de prédiction
Dans les projets de machine learning, les sources de données utilisées pour la prédiction et l’entraînement des modèles ne sont pas toujours les mêmes. Si le préprocessing des données n’est pas exactement le même entre les deux sources, apparaît ce qu’on appelle un biais d’apprentissage/invocation. Ce biais a un impact négatif sur la qualité des prédictions d’un modèle.
Il apparaît par exemple quand un développeur modifie la manière de calculer une feature sur la source de données utilisée pour la prédiction mais par négligence, pas sur la source utilisée pour l'entraînement.
Ou alors par erreur, quand le code source qui gère le data engineering sur le dataset de prédiction est erroné ou différent de celui qui gère le data engineering sur le dataset d’entraînement.
Cette situation peut survenir si les sources de données utilisées pour la prédiction et pour l'entraînement ne sont pas gérées par les mêmes équipes. Dans ce cas, il suffit d'un problème de communication pour qu'on se retrouve avec ce biais. Ainsi, il est possible que l'équipe qui gère la source de données pour la prédiction change la manière de calculer une feature sans se rendre compte qu'elle affecte un modèle en production.
Le problème est d’autant plus grave qu’il est parfois difficile à détecter car il ne lève pas toujours d’alerte.
Un feature store se charge de servir les features au moment de la prédiction (l’invocation) et au moment de l'entraînement. Puisqu’il contrôle les sources de données qu’il sert au moment pour la prédiction et de l’entraînement, il peut s’assurer de la cohérence entre ces deux sources.
Cela limite le risque d’apparition d’un biais d'apprentissage/invocation, on peut donc aller en production plus sereinement.
Monitorer l’historique des features, leurs métadonnées
Les feature stores permettent de facilement conserver des métadonnées sur les features, notamment leur historique. On peut, par exemple, conserver l’influence d’une feature sur les modèles dans où elle est utilisée. Et ainsi, mieux comprendre quelles sont les features les plus utiles pour résoudre un type de problème donné. On peut aussi mesurer l’évolution des features au cours du temps.
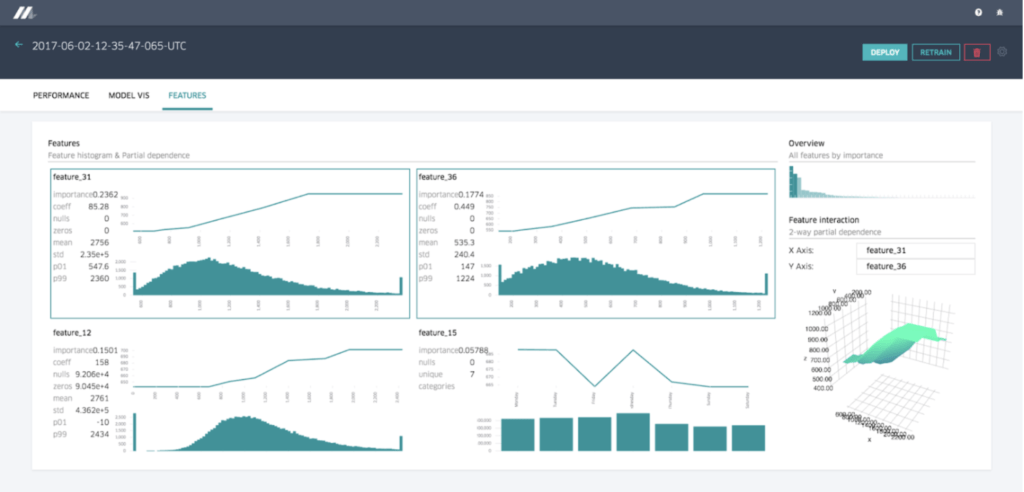
Rapport sur les features sur Michelangelo, la plateforme ML d’Uber
Faciliter et sécuriser la construction de dataset d'entraînement.
Pour éviter que les modèles soient entraînés sur des données de tests (on parle de feature leakage dans ce cas), les feature stores permettent de récupérer les données en utilisant un point temporel.
Il est possible d’aboutir au même résultat avec des jointures sur les tables. Néanmoins, lorsqu'on travaille sur des features provenant de plus d’une dizaine de table, cela permet d’éviter de faire un grand nombre de jointure, et ainsi:
- éviter de potentielles erreurs,
- simplifier et accélérer la requête de données.
Faciliter la découverte des features déjà calculées au sein de l’organisation.
Certains feature stores offrent une interface pour faciliter la découverte de nouvelles features pour les data scientists.
En effet, lorsque le feature store devient mature, il tend à contenir un grand nombre de features. Il devient alors important pour une équipe de data scientists de pouvoir explorer les variables existantes, leurs caractéristiques ou leurs origines.
II) Quelle est l’architecture d’un feature store******, comment fonctionne-t-il ?**
Généralement, les feature stores offrent quatre fonctionnalités (modules):
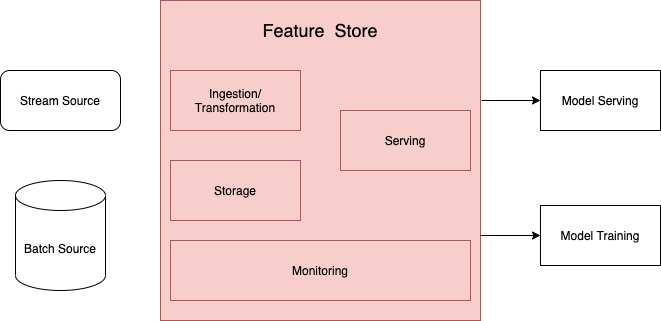
schéma d’un feature store
Serving: La cohérence des données est importante au moment de l'entraînement (Model Training) et de la prédiction (Model Serving) pour éviter une baisse de performance des modèles (voir partie 1).
Il n’est pas toujours simple de vérifier la cohérence des données. En passant par un _feature stor_e, on limite ce risque puisqu’il est utilisé pour récupérer les données tant au moment de la prédiction que de l'entraînement.
Les bases de données qui conservent les données pour la prédiction et l'entraînement sont très corrélées, en général l’une se base sur l’autre.
Un feature store offre un SDK en Python, Go et Java pour récupérer les données qui servent à l’entraînement et une API pour récupérer les variables pour la prédiction. L’API est désignée pour servir plus rapidement que le SDK. Effectivement, à l’inférence, les contraintes de temps sont plus importantes que pour l’entraînement.
Storage: Un feature store contient généralement deux bases de données, une BDD avec une grande profondeur temporelle (offline store), cette base contient les données qui sont servies via le SDK pour l'entraînement des modèles. Le feature store contient aussi une BDD qui contient les données les plus fraîches et les données en streaming (online store), elle est plus performantes pour servir plus rapidement.
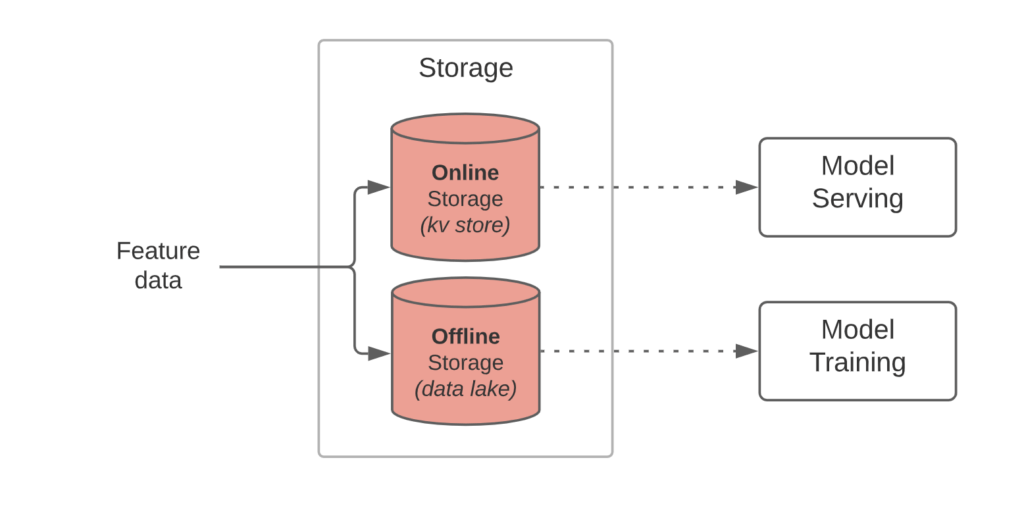
Schéma des deux types de base de données utilisé sur un feature store (source)
Ingestion/Transformation: Les sources de données peuvent être facilement connectées au feature store. Certains feature stores vont uniquement chercher à ingérer les données et d’autres vont aussi permettre d’appliquer des transformations sur les données.
Monitoring: La qualité des données peut être évaluée en mesurant un potentiel changement des propriétés statistiques des données.
Enfin, il est aussi possible de monitorer des variables plus techniques comme l’utilisation de la feature, la latence ou le pourcentage d’erreurs.
III) Un exemple d’utilisation de feature store
Les feature stores sont encore relativement jeunes, mais on retrouve déjà plusieurs implémentations open-source ou propriétaires de feature store.
- En open-source, Feast peut être déployé sur n’importe quel cloud provider (AWS, GCP, Azure).
- Une solution open-source alternative est celle de Logical Clocks : Hopsworks, disponible en solution managée sur Azure et AWS, il peut aussi être installé on-premise.
- Amazon offre un feature store propriétaire avec le service Amazon Feature Store.
- Les développeurs de Michelangelo ont aussi développé Tecton, un service de feature store propriétaire, il offre des fonctionnalités comparables à celle de Feast.
Dans notre cas, on va se concentrer sur la solution open-source Feast. Historiquement, Feast a d’abord été pensé pour être une solution qui fonctionne sur GCP avant d’être porté sur d’autres clouds. On peut utiliser les services managés AKS (Azure) ou EKS (AWS) pour créer l’architecture sous-jacente de Feast ou encore utiliser Kubeflow. Pour tester simplement Feast, il est aussi possible d’utiliser docker-compose.
On peut remarquer que Feast est composé de plusieurs conteneurs:
- un service Feast-Core qui sert de registre pour toutes les features définis dans le feature store, il interagit avec une base de données postgres où il enregistre les métadonnées sur les features,
- un conteneur Feast-Online-Serving qui sert d’API pour servir les features,
- une base de données Redis utilisée comme un online store,
- un job-service qui sert à orchestrer les jobs qui mettent à jour l’online store (la BDD Redis).
En plus de ces éléments, le docker-compose contient aussi un conteneur Jupyter et un kafka pour simuler le fonctionnement du feature store. Le jupyter notebook contient un tutoriel sous la forme d’un notebook pour prendre en main Feast (j’ai suivi cet exemple).
Pour définir et ingérer de nouvelles features, on passe par les entités et les feature tables. Une entité est une feature utilisée pour représenter un objet sous la forme d’un identifiant entier. Par exemple, on peut avoir comme entité customer, order ou driver (un ID).
Une feature table est une suite de features liées à une ou plusieurs entités. Elle permet aussi de définir la source des features.
Par exemple, pour définir de nouvelles entités, feature et features table, on a :
client = Client()
driver_id = Entity(name="driver_id", description="Driver identifier", value_type=ValueType.INT64)
acc_rate = Feature("acc_rate", ValueType.FLOAT)
conv_rate = Feature("conv_rate", ValueType.FLOAT)
driver_statistics = FeatureTable(
name = "driver_statistics",
entities = ["driver_id"],
features = [
acc_rate,
conv_rate
],
batch_source=FileSource(
event_timestamp_column="datetime",
created_timestamp_column="created",
file_format=ParquetFormat(),
file_url=driver_statistics_source_uri,
date_partition_column="date"
)
)
client.apply(driver_id)
client.apply(driver_statistics)
Penchons-nous sur l’architecture de Feast, un schéma détaillé est disponible dans la documentation :
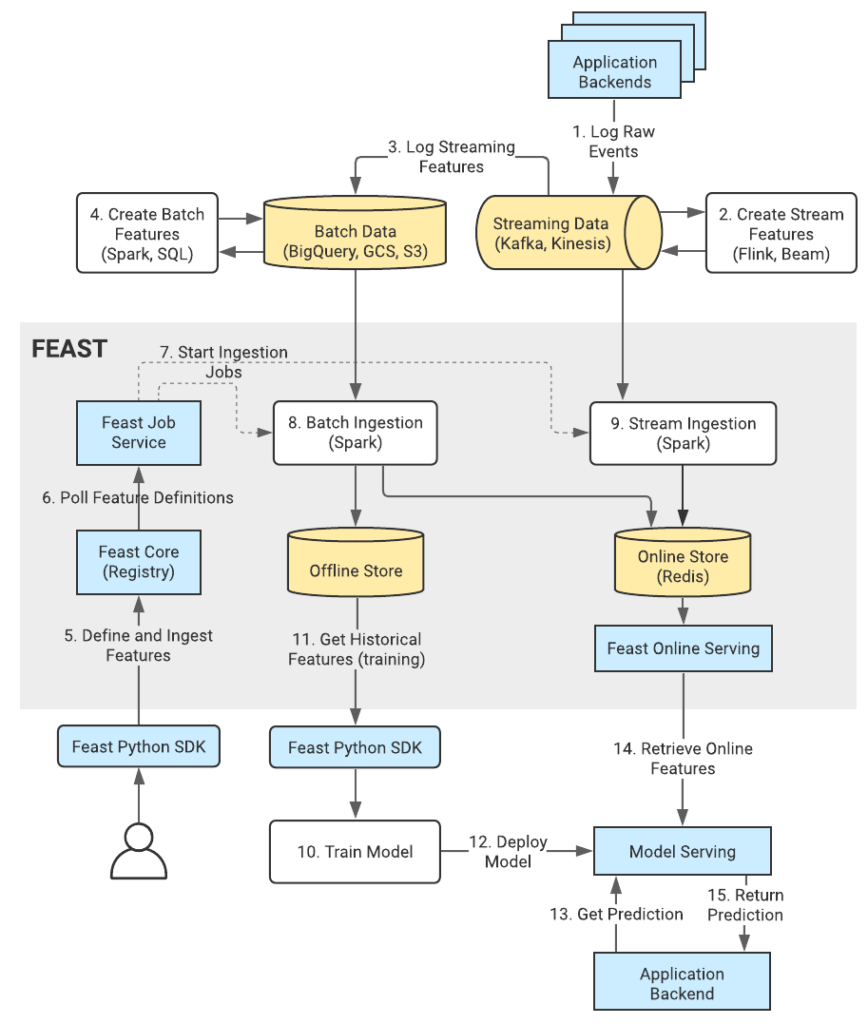
Architecture de Feast (source)
Sur le schéma, on peut voir que la partie “ingestion de données” est en pointillé, c’est parce que les jobs d’ingestions à partir d’une source batch ne sont pas intégré à Feast, ces jobs d’ingestions doivent être gérés et orchestrés avec un outil d’ETL.
De plus, Feast ne contient pas d’offline store, les données sont directement récupérées depuis la source (un datalake ou un s3 par exemple).
Donc, Feast est encore assez immature sur la gestion de données batch, (l’ajout d’un offline store est sur la feuille de route du projet).
On nous montre aussi comment récupérer les données depuis un offline store, on donne à Feast une suite d'entités ainsi qu’un timestamp pour chacune d’entre elles. Il va automatiquement faire une jointure pour sélectionner l’observation la plus récente par rapport au timestamp de l’entité dans chacune des features tables. Si aucune observation n’est suffisamment récente (le délai maximum entre le timestamp de la requête et le timestamp de l’observation est dépassé), alors la valeur de la feature est égale à zéro.
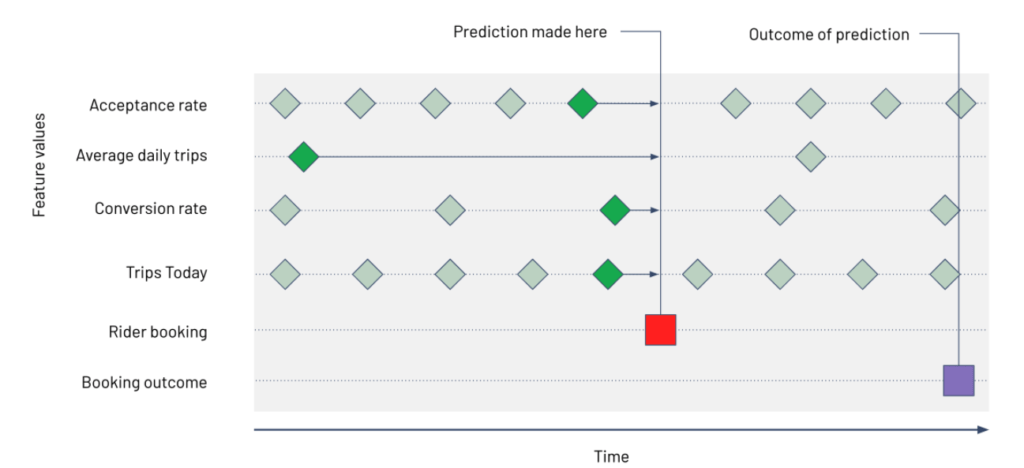
Schéma qui montre le fonctionnement du point in time join (source)
Dans le schéma ci-dessus, on montre en exemple comment le point in time join permet de récupérer uniquement les informations qui sont censées être connues par le modèle au moment de la prédiction.
L’appel pour récupérer les données:
job = client.get_historical_features(
feature_refs=[
"driver_statistics:avg_daily_trips",
"driver_statistics:conv_rate",
"driver_statistics:acc_rate",
"driver_trips:trips_today"
],
entity_source=entities_with_timestamp # pandas df with entity and timestamp
)
**Enfin, en ce qui concerne l’******online store, deux méthodes sont possibles pour faire en sorte qu’il soit à jour et contiennent des données:
- On peut lui faire ingérer les données qui sont contenues dans l’offline store de manière régulière. On peut aussi paramétrer sur quelle plage temporelle on veut que les données soient ramenées sur l’online store.
job = client.start_offline_to_online_ingestion(
driver_statistics, # une feature table
datetime(2020, 10, 10),
datetime(2020, 10, 20)
)
- On peut le connecter à une source de données en streaming (compatible avec Kafka et Kinesis).
driver_trips.stream_source = KafkaSource(
event_timestamp_column="datetime",
created_timestamp_column="datetime",
bootstrap_servers=KAFKA_BROKER,
topic="driver_trips",
message_format=AvroFormat(avro_schema_json) # le schéma de données
)
client.apply(driver_trips)
Feast offre les fonctionnalités clés d’un feature store. Ainsi, il est possible d’effectuer les tâches suivantes :
- créer simplement de nouvelles features.
- récupérer les données d’entraînement via un SDK en python.
- utiliser l’API pour récupérer les données les plus fraîches de manière performante.
Après avoir pris en main l’outil quelques heures, j’ai déjà pu en ressortir quelques conclusions. Pour les points positifs on peut noter que :
- Il est assez facile à prendre en main,
- Il offre un système bien pensé pour récupérer les features historiques sans leakage,
- On peut servir des features rapidement.
Néanmoins, il a aussi quelques défauts :
- manque de documentation,
- manque de maturité (pas d’offline store),
- il est assez lourd, beaucoup de composants nécessaires et,
- peu de feedback de développeurs.
Sur la dizaine de jours depuis que le répertoire du projet est installé sur ma machine, une vingtaine de commits ont atterri sur master ce qui montre que les équipes qui travaillent sur Feast sont encore très actives. De quoi être optimiste quant au futur du projet.
Conclusion
Les feature stores sont de nouveaux outils qui permettent de mieux gérer les features, ils font partie de la vague d’outils de machine learning opérationnels (ML OPS) qui cherche à mettre en place le machine learning en production et à l’échelle.
Ils sont assez peu utiles s’ils sont appliqués pour un seul projet, ils brillent surtout lorsqu’ils sont implémentés à l’échelle de toute une organisation. D’abord apparu comme une solution propriétaire, des alternatives open-source commencent à être mises en place.
Ils sont intéressants pour les équipes qui appliquent l’IA à moyenne ou grande échelle, ont des difficultés à éviter le biais d’apprentissage invocation ou les data leakage et cherchent à tester des solutions pour rationaliser leur gestion des _features q_uitte à être les early-adopters de cette solution. Pour les autres, il faudra encore attendre pour que les feature stores deviennent plus courants et plus stables.