Extensions Kubernetes
Dans cet article, nous allons découvrir quelques types de plugins permettant d’étendre Kubernetes. La volonté de ces extensions est de permettre à des tiers de contribuer à des fonctions de Kubernetes sans impacter son cœur. L’objectif de la communauté Kubernetes à présent est avant tout à se stabiliser au travers d’une cure d’amaigrissement et de modularisation. Tout ce qui relève d’une implémentation spécifique se voit progressivement remplacé par une interface permettant de brancher différentes implémentations out-of-tree, c’est à dire en dehors du code source de Kubernetes. 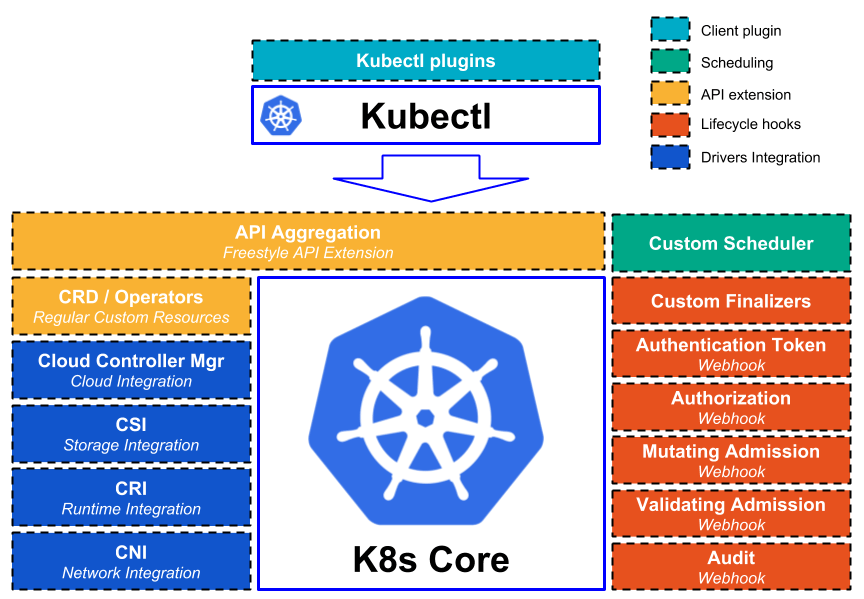
CNI : Container Network Interface
Probablement un des mécanismes les plus connus de Kubernetes, CNI permet d’interfacer plusieurs solutions d’interconnexion réseau, parmi lesquelles : Flannel, Calico, Weave… Nous n’allons pas nous éterniser sur cette interface, car son utilisation est relativement connue, puisque quasiment indispensable pour obtenir un cluster fonctionnel. Deux fonctions principales sont implémentées dans CNI :
- IPAM (IP Address Management) : pour l’allocation des adresses IP des conteneurs.
- Interface-creation : pour la création et/ou l’attachement technique de l’interface réseau qui va porter le conteneur. Derrière cette fonction se cache également toute la magie permettant aux conteneurs de pouvoir se joindre (via routage, overlay…).
CRI : Container Runtime Interface
Ce mécanisme d’extension permet de remplacer le moteur d’exécution de conteneurs. Historiquement réservé à Docker, Kubernetes a par la suite été capable de faire tourner des conteneurs rkt. L’arrivée de la couche d’abstraction CRI permet tout une famille d’implémentations allant jusqu’à de la virtualisation pour ceux qui n’aurait pas une grande confiance dans la conteneurisation. Une autre des motivations derrière cette interface était de pouvoir s’abstraire du démon Docker (devenu trop gros et avec des API mouvantes) en utilisant directement containerd ou cri-o. Aujourd’hui, la plupart des clusters Kubernetes que nous rencontrons n’utilisent pas encore cette interface et pilotent Docker en direct, à l’ancienne.
CSI : Container Storage Interface
Dernier né de la famille des C*I, CSI vient donc offrir une abstraction sur les stockages. À nouveau, différentes implémentations vont pouvoir venir proposer les fonctions de création, redimensionnement, attachement, montage [...] des volumes qui peuvent être utilisés dans nos chers conteneurs. Cette initiative vient remplacer les FlexVolumes, première tentative de modularisation des solutions de volumes de stockage.
Le suivi des différentes implémentations et de leur maturité se trouve ici. La bascule du mode de gestion des volumes actuel vers CSI va se faire probablement au fur et à mesure de la stabilisation des nouvelles implémentations.
Cloud-Controller-manager
L’apparition du cloud-controller-manager vise à extraire de notre bon vieux controller-manager toutes les fonctions relatives aux interactions spécifiques aux cloud providers. À nouveau, l’objectif est double : décorréler les cycles de vie du moteur Kubernetes de la logique de synchronisation des load-balancers, routetables et aux objets cloud et maintenir une taille raisonnable pour le controller-manager. Les implémentations cloud dans le cloud-controller deviennent progressivement obsolètes pour une bascule officielle avec la version 1.14 de Kubernetes. Le cloud-controller-manager devient un simple pod qui peut être lancé après le bootstrap du cluster. Il peut alors embarquer uniquement la logique du cloud que l’on utilise plutôt que tous comme c’était historiquement le cas. Pour les déploiements statiques qui n’utilisent pas d’intégration cloud, inutile de le démarrer.
CRD et Opérateurs : Custom Resource Definitions
Derrière ces termes barbares se cache un moyen d’extension de plus en plus populaire. Les CRD consistent à déclarer des nouveaux types de ressources qui ne sont pas natives à Kubernetes contrairement aux pods, services, replicasets… Devant la recrudescence des implémentations à tout vent des sites se sont spécialisés dans leur référencement et surtout le suivi de leur maturité. On trouve en vrac des ressources permettant de :
- Déployer des outils de monitoring. Nous utilisons très souvent prom-operator pour ce faire.
- Créer des bases de données de tout poil,
- Mettre en œuvre des stratégies de sauvegarde (comme Ark par exemple),
Vous l’aurez compris, le champ des possible est très vaste. L’intérêt de développer ses propres CRD réside dans l’utilisation native de fonctions Kubernetes : authentification et autorisations, traçabilité… Des SDK permettent de coder rapidement des opérateurs, en charge de s’abonner aux événements relatifs à ces nouveaux types de ressources. Libre aux développeurs de coder ce qu’ils souhaitent pour implémenter la logique derrière ces ressources personnalisées.
À noter que si une CRD n’a que peu d’intérêt sans son opérateur, l’inverse n’est pas forcément vrai. On peut tout à fait développer des opérateurs qui s’appuient sur des ressources existantes. Exemple : créer des enregistrements DNS en fonction des services ou des ingresses présents dans les clusters Kubernetes.
API Aggregation
Encore plus puissant que les CRD, l’API aggregation permet de créer de nouvelles portions de l’API Kubernetes, mais plus largement que les CRD pour lesquelles la liste des actions (verbes) est limitées aux classiques (get, list, watch, create, delete, use…). Ici, c’est tout un pan de l’arbre des URL qui peut être externalisé sur une application tierce : la vôtre, que vous aurez codée à façon.
Il existe un exemple concret pour illustrer l’usage de l’API aggregation : le kube-metrics-server. Remplaçant de Heapster, cet outil est en charge de collecter des métriques de base des pods et des nœuds (cpu, mémoire) et ainsi permettre les commandes kubectl top po, kubectl top no et surtout le fonctionnement des horizontalPodAutoscallers. L’installation de kube-metrics-server passe par la déclaration d’un APIservice, l’objet qui représente les portions de l’API qui sont présentes dans le cluster. En plus des APIservices standards, nous venons ajouter une nouvelle entrée :
---
apiVersion: apiregistration.k8s.io/v1beta1
kind: APIService
metadata:
name: v1beta1.metrics.k8s.io
spec:
service:
name: metrics-server
namespace: kube-system
group: metrics.k8s.io
version: v1beta1
insecureSkipTLSVerify: true
groupPriorityMinimum: 100
versionPriority: 100
Celle-ci pointe sur un service metrics-server dans le namespace kube-system, service fourni par un pod qui implémente la nouvelle API. Pour les curieux, l’installation du kube-metrics-server est détaillée ici. Une fois l’APIservice déclaré et le pod démarré, l’APIserver répond à une nouvelle route que l’on peut tester avec la commande suivante :
$ kubectl get --raw "/apis/metrics.k8s.io/v1beta1/nodes"
{"kind":"NodeMetricsList","apiVersion":"metrics.k8s.io/v1beta1","metadata":{"selfLink":"/apis/metrics.k8s.io/v1beta1/nodes"},"items":[{"metadata":{"name":"minikube","selfLink":"/apis/metrics.k8s.io/v1beta1/nodes/minikube","creationTimestamp":"2018-12-17T13:52:09Z"},"timestamp":"2018-12-17T13:51:46Z","window":"30s","usage":{"cpu":"567925956n","memory":"6380384Ki"}}]}
Si vous vous demandez comment choisir entre CRD et API aggregation, ce comparatif pourrait vous être utile...
Custom Scheduler
De manière beaucoup plus rare, on pourrait être tenté de remplacer le scheduler Kubernetes standard par un autre. Plus exactement, l’idée est d’en déployer un second à côté de celui par défaut. Une fois le déploiement effectué, il devient possible de spécifier le nom du second scheduler pour lui demander expressément de s’occuper du placement d’un pod :
---
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
schedulerName: my-scheduler
containers:
- name: my-pod
image: "nginx:1.15.7-alpine"
Un exemple d’implémentation est le Custom Scheduler poseidon qui se base sur un algorithme d’optimisation de contraintes afin de trouver la solution de placement optimale.
Custom Finalizers
Les custom finalizers permettent d'intercepter les destructions d'objets, en vue d'exécuter du code personnalisé. La terminologie fait référence aux destructeurs (finalizers) en programmation orientée objet. Le principe : Lorsqu’un objet (quelque soit son type) est créé, il est possible de déclarer une liste de finalizers sous la forme suivante :
---
apiVersion: v1
kind: Pod
metadata:
labels:
run: nginx
name: nginx
finalizers:
- finalizer.octo.com/pods
spec:
containers:
- image: nginx
name: nginx
Lors de la demande de suppression du pod d’exemple ci-dessus, celle-ci sera bloquée tant que votre code métier l’aura décidé. Libre à vous de coder la logique de votre choix pour effectuer les travaux de purge que vous souhaitez. Une fois le travail terminé, votre code doit simplement retirer l’entrée du champ metadata.finalizers[] pour débloquer et terminer la suppression de l'objet. Des finalizers standards sont déjà utilisés dans le fonctionnement normal de Kubernetes, notamment, pour gérer la destruction des namespaces, le verrouillage de la destruction des volumes utilisés.
Les Webhooks
Voyons à présent les dérivations qu’il est possible de venir placer dans le traitement standard d’une requête à destination de l’API server. Dans tous les cas de Webhook, l’API server est configuré pour envoyer à une application tierce - codée par votre soin ou trouvée parmi celles disponibles sur Internet, déployée statiquement ou sous forme de pods - une requête et attend en retour des informations complémentaires qui vont pouvoir poursuivre le traitement de la demande client. 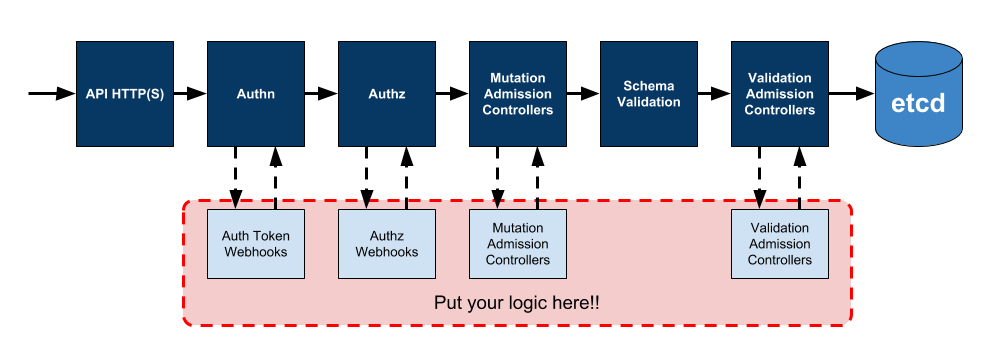
Authentication Token Webhook
Cette dérivation permet de déléguer l’authentification à base de “bearer token” à un tier. Ce dernier reçoit pour chaque demande d’authentification (modulo un cache local à l’API server) une requête HTTP POST d’un objet TokenReview :
{
"apiVersion": "authentication.k8s.io/v1beta1",
"kind": "TokenReview",
"spec": {
"token": "(BEARERTOKEN)"
}
}
Le tier a ensuite deux possibilités, la première est de répondre positivement à une demande d'authentification en envoyant une réponse contenant le nom d’utilisateur, l’uid et les groupes auxquels il appartient. Un exemple de réponse positive :
{
"apiVersion": "authentication.k8s.io/v1beta1",
"kind": "TokenReview",
"status": {
"authenticated": true,
"user": {
"username": "yati4tw@t.ki",
"uid": "42",
"groups": ["ops", "security"],
"extra": {
"extrafield1": ["extravalue1", "extravalue2"]
}
}
}
}
La seconde possibilité est une réponse négative au format suivant :
{
"apiVersion": "authentication.k8s.io/v1beta1",
"kind": "TokenReview",
"status": {
"authenticated": false
}
}
Un exemple pour ce mécanisme d’authentification très répandu est Guard. Il s‘agit d’un serveur qui peut répondre aux TokenReviews de l’API server en s’appuyant sur différents backends externes à Kubernetes, Google, LDAP, Azure pour valider les identités...
Authorization Webhook
Les Authorization Webhooks sont basés sur le même principe que les Authentication Webhooks, mais ils ont pour but de décider si l’action tentée par l’utilisateur est autorisée ou non. Elle prend la forme d’un message JSON de type SubjectAccessReview :
{
"apiVersion": "authorization.k8s.io/v1beta1",
"kind": "SubjectAccessReview",
"spec": {
"resourceAttributes": {
"namespace": "kittensandponies",
"verb": "get",
"group": "apps",
"resource": "deployments"
},
"user": "jane",
"group": ["group1", "group2"]
}
}
La question formulée dans l’exemple ci-dessus est le suivant : l’utilisateur jane (appartenant aux groupes group1 et group2) est-il autorisé à exécuter un get sur les deployments du namespace kittensandponies ?
Deux réponses peuvent être retournées. L’une positive :
{
"apiVersion": "authorization.k8s.io/v1beta1",
"kind": "SubjectAccessReview",
"status": {
"allowed": true
}
}
L’autre négative :
{
"apiVersion": "authorization.k8s.io/v1beta1",
"kind": "SubjectAccessReview",
"status": {
"allowed": false,
"reason": "user does not have read access"
}
}
Validating Webhook
Les Validating Webhooks peuvent être mis en œuvre pour ajouter des règles de validation spécifiques sur les créations / mises à jour / suppression d’objets. Pour armer un Webhook de type validation, il est nécessaire de créer un objet de type ValidatingWebhookConfiguration qui décrit dans quel cas invoquer notre Webhook (lors de quelles actions sur quels objets). Voici un exemple :
---
apiVersion: admissionregistration.k8s.io/v1beta1
kind: ValidatingWebhookConfiguration
metadata:
name: my-pod-verification
webhooks:
- name: pod-validation.yati4tw.io
rules:
- apiGroups:
- ""
apiVersions:
- v1
operations:
- CREATE
resources:
- pods
clientConfig:
service:
namespace: kube-system
name: my-svc-webhook
path: /validation
Parmi des cas d’utilisation possibles des ValidationWebhooks on peut lister :
- S’assurer que des labels spécifiques sont bien présents dans tous les objets créés
- Interdire les pods déployés avec des images en version latest
- Interdire la suppression d’objets spécifiques, quelles que soient les permissions de l’utilisateur
Cet article de blog vous montrera très clairement comment coder et, cerise sur le gâteau, tester unitairement un contrôleur en Go.
Mutating Webhook
Les Mutating Webhooks interviennent plus tôt dans la chaîne de traitement et ont la capacité d’altérer les objets (notamment en phase de création ou de modification). Ils sont donc modifiés à la volée quitte à parfois contredire ce que le client a réellement demandé. Un cas d’utilisation est Istio qui va installer un MutatingWebhookConfiguration (à l’identique d’un ValidatingWebhookConfiguration vu précédemment) pour intercepter les demandes de créations de pods en vue d’y injecter un sidecar.
Pour voir l’anatomie complète du fonctionnement des Mutating Webhooks (et des Validating Webhooks utilisés de concert) allez faire un tour sur cet article, il illustre très clairement le fonctionnement. Dans l’exemple suivant un pod de notre crû, exposé derrière un service dans le namespace kube-system va être invoqué pour toutes les demandes de création ou de modification d’un pod dans tous les namespaces labellisés tweak-my-pod="true".
---
apiVersion: admissionregistration.k8s.io/v1beta1
kind: MutatingWebhookConfiguration
metadata:
name: my-pod-labeller
webhooks:
- name: pod-mutation.yati4tw.io
clientConfig:
Service:
name: my-svc-webhook
namespace: kube-system
path: "/mutation"
rules:
- operations: ["CREATE", "UPDATE"]
apiGroups: [""]
apiVersions: ["v1"]
resources: ["pods"]
failurePolicy: Fail
namespaceSelector:
matchLabels:
tweak-my-pods: "true"
Audit Webhook
Le mécanisme natif des Auditlogs consiste à produire une ligne de log (en JSON) pour chaque action qui intervient sur l’API server. En activant l’Audit Webhook, au lieu d’écrire en local les lignes de log, l’API server invoque une URL pour externaliser le stockage ou le traitement des pistes d’audit. Cette possibilité est souvent inutilisée au profit œuvre d’une solution de collecte de logs locale à chaque nœud, comme FileBeat, Fluentd ou Fluentbit qui capture non seulement les Auditlogs sur les API server, mais aussi les autres journaux système et les logs des conteneurs en vue de les envoyer vers un puits de logs.
Et côté client ?
Pas de panique, il est également possible d’étendre le client (le fameux kubectl) pour enrichir son comportement. Même si à OCTO, nous n’avons pas encore eu l’opportunité d’utiliser ce mécanisme d’extension, on peut assez aisément imaginer des cas d’utilisation :
- Générer des kubeconfig standards en fonction du contexte de l’entreprise
- Procéder à la génération des données d’identité de l’utilisateur au travers d’une connexion OpenID Connect
De nombreuses idées sont déjà implémentées sont visibles ici. L'outil krew se positionne comme un outil similaire à homebrew, mais spécialisé dans la gestion des plugins kubectl.
$ kubectl krew search # show all plugins
$ kubectl krew install view-secret # install a plugin named "view-secret"
$ kubectl view-secret # use the plugin
$ kubectl krew upgrade # upgrade installed plugins
$ kubectl krew remove view-secret # uninstall a pluginw
Conclusion
Bien entendu, cette liste de moyens d’extension n’est pas complète, mais reflète une très forte capacité d’adaptabilité de Kubernetes. Certaines extensions peuvent paraître des gadgets ou des « plus » insignifiants, mais d’autres vont jouer un rôle majeur dans l’intégration de nos clusters avec le reste du SI, la sécurité, la traçabilité. Le travail de déploiement de Kubernetes ne se résume pas simplement à installer et démarrer un cluster. Il s’agit également d’identifier les configurations et intégrations à effectuer et le moyen de les mettre en œuvre au travers de ces extensions. Faites vos choix !!