Monitoring Kubernetes avec Prometheus et Grafana
« Ce que je ne mesure pas ne m’appartient pas ». Ce célèbre adage nous a souvent été répété par l’un de nos clients. C’est d’autant plus vrai lorsqu’il s’agit des systèmes distribués et dynamiques qui peuvent s’avérer complexes à monitorer. Au travers de l’exemple de Kubernetes, voyons les limitations des solutions de métrologie historiques, les nouveaux enjeux à adresser et de quelle manière le couple Prometheus et Grafana tente d’y répondre.
Problématique
Sans revenir en détail sur son architecture complète, un cluster Kubernetes est constitué d’un certain nombre de composants logiciels installés sur des machines virtuelles ou physiques. Une implémentation générique pourrait ressembler à ça :
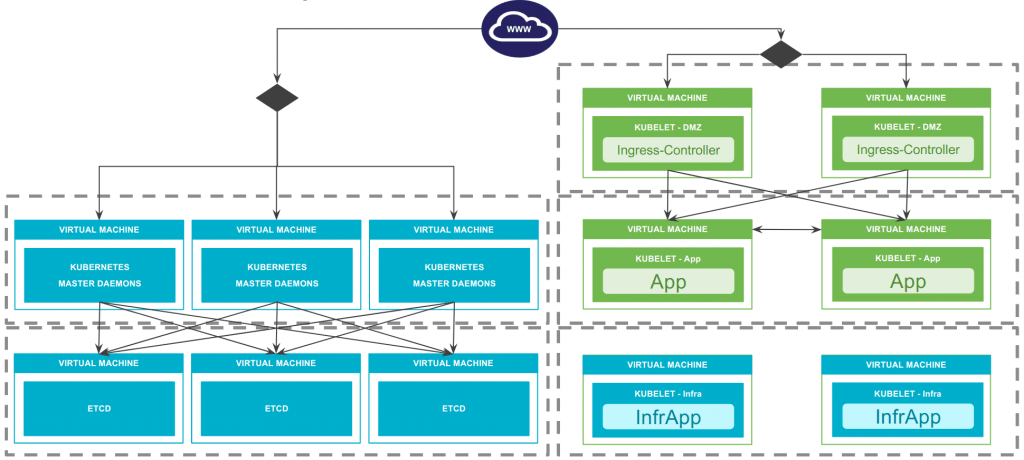
Nous retrouvons ici un cluster etcd, des rôles Kubernetes masters (API server, controller-manager et scheduler), des nodes Kubernetes (Kubelets). Superviser ces composants ne pose pas de problème particulier, et utiliser nos outils de monitoring historiques est tout à fait possible. Après tout, il ne s’agit que de disques, de machines, de CPU, de mémoire et de processus en écoute sur des ports. Rien de bien nouveau.
Cependant, et c’est ici que la donne change : un cluster Kubernetes, c’est aussi un certain nombre d’objets logiques, conceptuels, répartis sur plusieurs machines, avec un cycle de vie potentiellement très court.
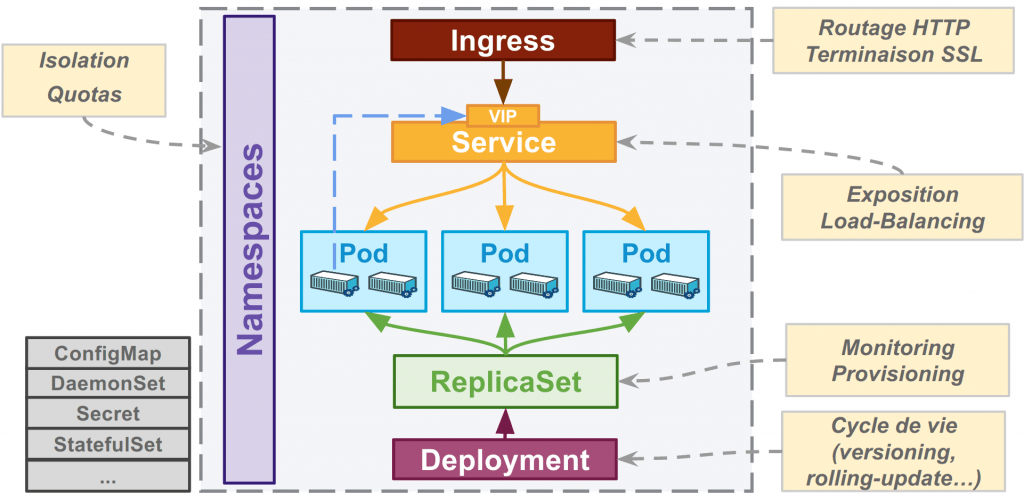
Nos anciens outils de monitoring se révèlent bien à la peine pour superviser des objets aussi dynamiques qu’un Pod ou autre ReplicaSet. Un pod n’est hébergé sur un nœud que pour une durée assez courte, il est fort probable qu’un crash ou un redéploiement d’une nouvelle version le fasse réapparaître ailleurs.
La plupart des solutions de supervision ou de métrologie du marché n'implémentent pas les paradigmes suivants :
- Découverte des métriques au fil de l'eau. Les indicateurs collectés sont découverts au fur et à mesure qu’ils sont remontés sans avoir besoin de les pré-déclarer.
- Webisation des composants. De plus en plus de composants exposent une interface HTTP (IHM ou API). Si le monitoring pouvait profiter de cette orientation, l’intégration serait grandement simplifiée.
- Cycles de vie courts. Les indicateurs et les composants qui les portent ont des vies très courtes, liées notamment aux déploiements des conteneurs, aux redimensionnements des pools. Reconfigurer le monitoring doit se faire à chaud et très fréquemment.
- Vision dynamique. Les systèmes de monitoring doivent avoir la capacité à s’intégrer avec des systèmes d’auto-découverte pour s’adapter en permanence aux évolutions de la topologie d’infrastructure.
- Vision distribuée d’éléments constitués de plusieurs indicateurs. Avoir une vraie garantie du bon fonctionnement d’un service ne peut pas nécessairement se déterminer en regardant localement l’état d’une machine ou d’un processus. Il est parfois nécessaire d’agréger ou corréler des remontées de plusieurs machines.
C’est donc conscientes de ces nouveaux enjeux, que des solutions font leur apparition ces derniers mois/années sur le marché. Nous parlons ici de InfluxDB, Prometheus, Hawkular et d’autres. Ils viennent s’ajouter à une liste de solutions de monitoring déjà bien fournie :

Nous prenons le parti de ne nous focaliser que sur deux outils que nous pensons très prometteurs : Prometheus et Grafana. Leur ADN nous semblent en phase avec les paradigmes que nous recherchons. Leur simplicité de mise en œuvre est un plus.
Principe de fonctionnement de Prometheus
Un modèle de fonctionnement extensible
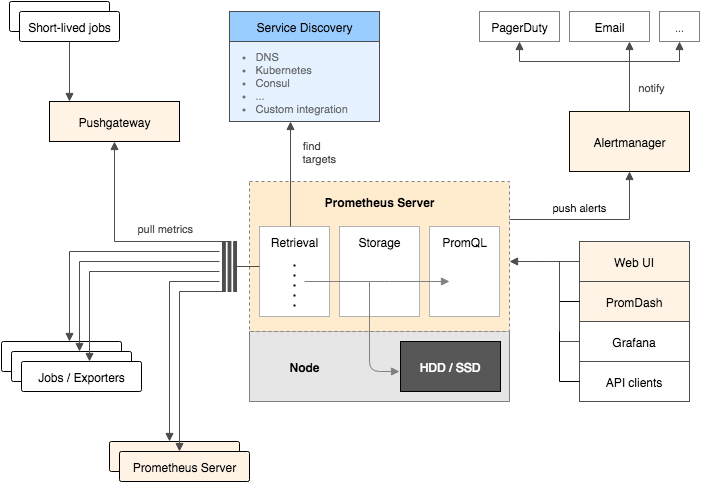
Le modèle de fonctionnement de Prometheus est extensible par construction, basé avant tout sur un modèle de type pull : Prometheus, au travers d’une configuration statique et / ou dynamique (via les service discoveries), interroge régulièrement des exporters qui fournissent des métriques. Il persiste par la suite les données collectées dans une base locale sur disque. Réalisant à la fois les fonctions de collecte, de stockage, et d’exposition des métriques par une API, il est plus simple à installer qu’une architecture basée du InfluxDB, laquelle nécessite des collecteurs en amont.
Prometheus permet, via son API, à des outils de dashboarding tiers (Grafana est l’option la plus répandue) de se connecter. Un langage de requêtage nommé PromQL permet de sélectionner et traiter des métriques :
- Filtrage des indicateurs par labels (inclusion, exclusion, expressions rationnelles).
- Génération de vecteurs (plusieurs valeurs d’un indicateur sur une fenêtre temporelle par exemple) sur lesquels il est possible d’appliquer des fonctions et opérateurs d'agrégation (min, max, moyenne glissante, somme…).
Une URL de métriques
L’approche de Prometheus pour la collecte de métriques est le modèle pull sur des URL exposées en HTTP. Un format d’exposition de métriques générique est défini pour que les applications puissent présenter des indicateurs :
# HELP rest_client_request_status_codes Number of http requests, partitioned by labels
TYPE rest_client_request_status_codes counter
rest_client_request_status_codes{code="200",host="10.240.0.10:6443",method="PATCH"} 3
rest_client_request_status_codes{code="200",host="10.240.0.10:6443",method="PUT"} 1305
rest_client_request_status_codes{code="200",host="10.240.0.10:6443",method="DELETE"} 3
rest_client_request_status_codes{code="200",host="10.240.0.10:6443",method="GET"} 2758
rest_client_request_status_codes{code="201",host="10.240.0.10:6443",method="POST"} 58
Chaque métrique est décrite (champ HELP), typé (champ TYPE) et multivaluée au travers de labels (code, host et method sont ici 3 labels avec des valeurs permettant de différencier les instances de la variable rest_client_request_status_codes).
Chaque composant ou application a donc la possibilité d’exposer cette URL par le moyen qui lui semble le plus adapté : d’une simple réponse HTTP générée manuellement à l’utilisation de SDK très évolués (il en existe dans de nombreux langages). Citons quelques pratiques usuellement rencontrées :
- Des démons dits node-exporters sont installés sur les machines pour exposer des métriques systèmes traditionnelles (CPU, RAM, disques…). Ces agents existent pour Linux et Windows, (avec respectivement node-exporter et wmi-exporter).
- Les applications, qui le souhaitent, utilisent le SDK Prometheus pour simplifier l’exposition de métriques et ajoutent leurs propres métriques personnalisées.
- Des composants logiciels sur étagère sont nativement équipés de cette fameuse URL. À titre d’exemple, les démons etcd, les services Kubernetes (APIserver, kubelet via cAdvisor), le démon Prometheus lui-même sont équipés de ladite URL.
- Pour les applications Java, des passerelles exposent les indicateurs natifs JMX sous une URL au format Prometheus (https://github.com/prometheus/jmx_exporter)
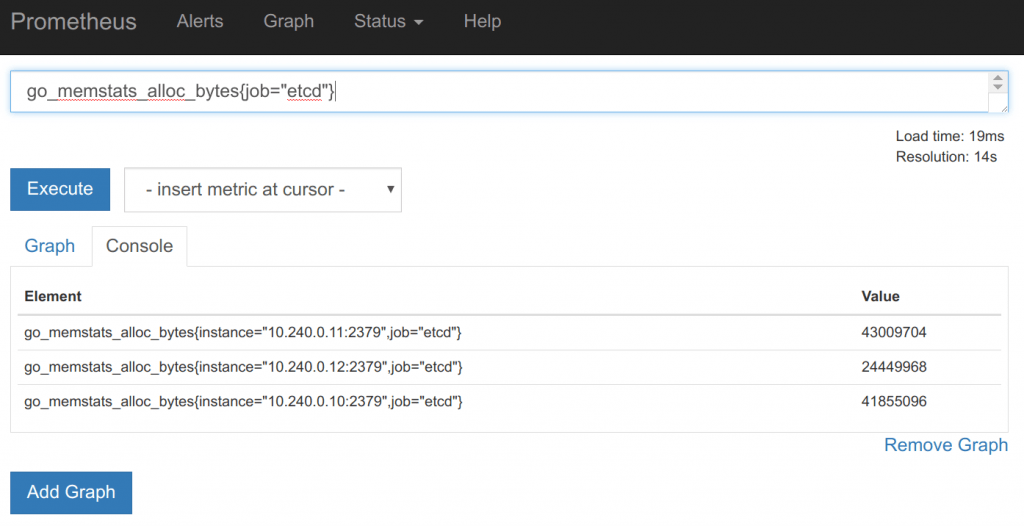
Pour illustrer le fonctionnement de cette URL, prenons le cas d’etcd. Sur le port standard d’etcd (2379), l’URL /metrics retourne un ensemble de métriques. Certaines sont directement fournies par le SDK. Etcd étant écrit en Go, de nombreux indicateurs commençant par go_ sont présents dans les métriques retournées. Voici un extrait de certaines de ces variables :
# HELP go_goroutines Number of goroutines that currently exist.
TYPE go_goroutines gauge
go_goroutines 21
HELP go_memstats_alloc_bytes Number of bytes allocated and still in use.
TYPE go_memstats_alloc_bytes gauge
go_memstats_alloc_bytes 1.353488e+06
HELP go_memstats_alloc_bytes_total Total number of bytes allocated, even if freed.
TYPE go_memstats_alloc_bytes_total counter
go_memstats_alloc_bytes_total 1.353488e+06
HELP go_memstats_buck_hash_sys_bytes Number of bytes used by the profiling bucket hash table.
TYPE go_memstats_buck_hash_sys_bytes gauge
go_memstats_buck_hash_sys_bytes 1.442912e+06
HELP go_memstats_frees_total Total number of frees.
TYPE go_memstats_frees_total counter
go_memstats_frees_total 181
HELP go_memstats_gc_sys_bytes Number of bytes used for garbage collection system metadata.
TYPE go_memstats_gc_sys_bytes gauge
go_memstats_gc_sys_bytes 169984
HELP go_memstats_heap_alloc_bytes Number of heap bytes allocated and still in use.
TYPE go_memstats_heap_alloc_bytes gauge
go_memstats_heap_alloc_bytes 1.353488e+06
HELP go_memstats_heap_idle_bytes Number of heap bytes waiting to be used.
TYPE go_memstats_heap_idle_bytes gauge
go_memstats_heap_idle_bytes 745472
HELP go_memstats_heap_inuse_bytes Number of heap bytes that are in use.
TYPE go_memstats_heap_inuse_bytes gauge
go_memstats_heap_inuse_bytes 2.00704e+06
HELP go_memstats_heap_objects Number of allocated objects.
TYPE go_memstats_heap_objects gauge
go_memstats_heap_objects 6348
Les développeurs d’etcd ont enrichi les indicateurs standard par des métriques spécifiques à l’application. Par convention, ils ont choisi de préfixer toutes leurs métriques personnalisées par « etcd_ ». Par exemple la métrique etcd_server_has_leader renvoie simplement si le serveur etcd interrogé a bien connaissance d’un leader dans le cluster.
# HELP etcd_server_has_leader Whether or not a leader exists. 1 is existence, 0 is not.
TYPE etcd_server_has_leader gauge
etcd_server_has_leader 1
Si vous souhaitez instrumenter vos propres applications via une URL de métriques, la documentation de Prometheus indique la liste des langages supportés. La documentation de chacun des langages, et les exemples, comme celui en langage Go montre avec quelle simplicité il est possible de fournir rapidement des métriques personnalisées.
Visualisation
La visualisation des métriques stockées dans Prometheus intervient à plusieurs niveaux.
Prometheus
Prometheus dispose d’une interface Web simpliste mais toujours utile dans des cas de requêtages PromQL manuels et graphes simples et pour vérifier le paramétrage du serveur.
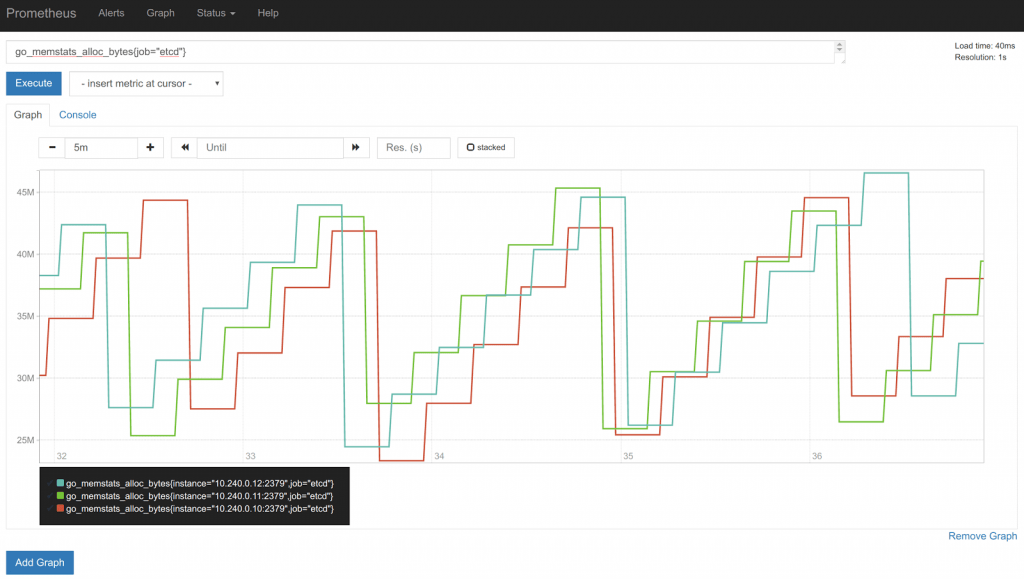
Grafana
Grafana est une interface Web de graphes multi-sources qui est notamment capable d’afficher des données issues de Prometheus. C’est principalement cet outil qui est utilisé : il dispose de capacités de présentation très poussées, notamment via des dashboards, paramétrables.
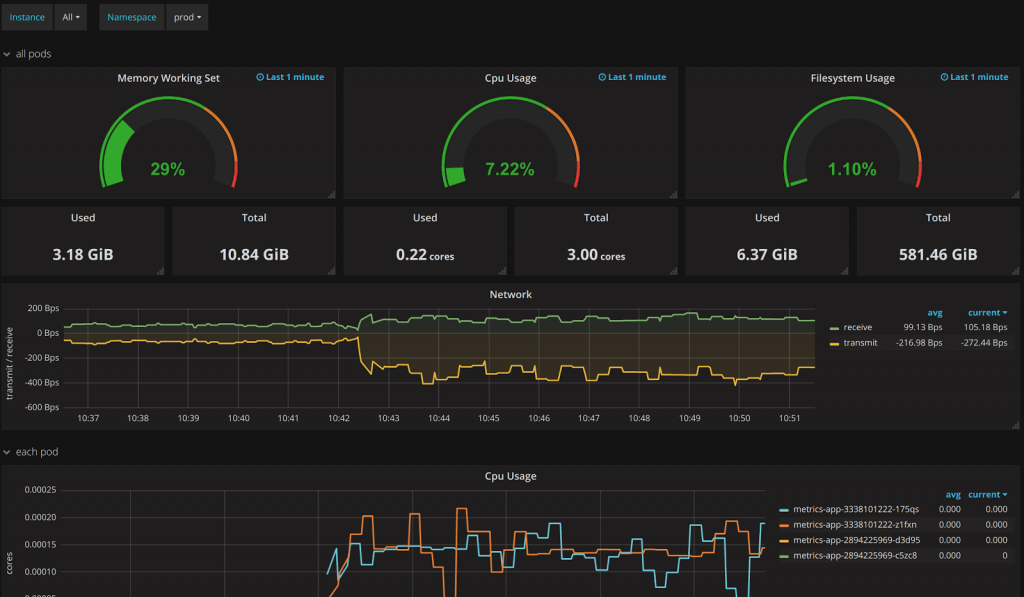
La communauté de Grafana est très active et propose en téléchargement des dashboards dont beaucoup se basent sur des données Prometheus. Un moyen très rapide pour initier des écrans spécifiques à des composants standards.
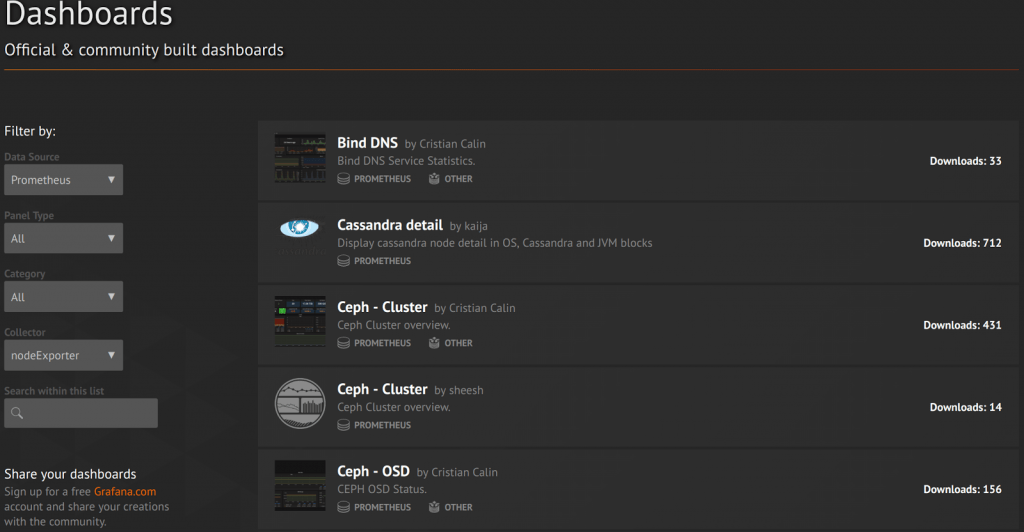
Alerting
Le modèle de génération d’alertes à partir de métriques Prometheus via deux mécanismes :
- Via la configuration de règles (rules) dans Prometheus. Une requêtes PromQL, une condition (dépassement de seuil sur une durée) et un vecteur de notification (slack par exemple). Le moteur Prometheus prend en charge la détection des seuils et délègue à un composants Prometheus alert-manager le soin de déclencher des notifications vers des services tiers. Avantages de cette solution : le moteur est autonome pour appliquer des seuils. Inconvénients de cette solution : le fichier de règle est à ce jour un fichier statique et un redémarrage (ou un kill -HUP) est nécessaire pour que tout changement soit pris en compte.
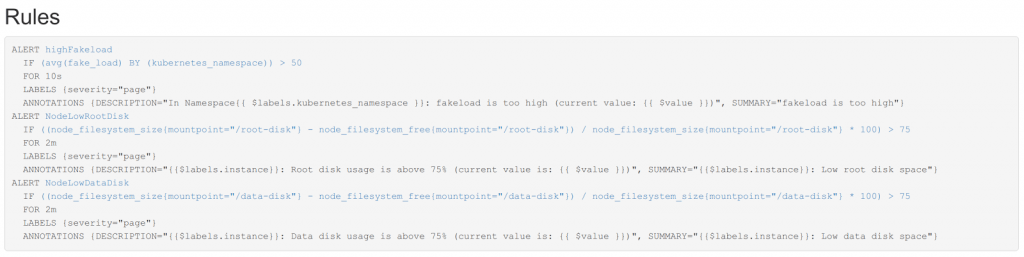
Une fois levée, l’alerte s’affiche dans la console Prometheus :
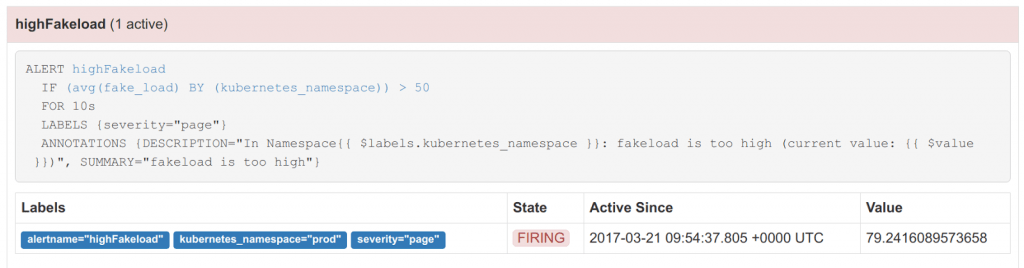
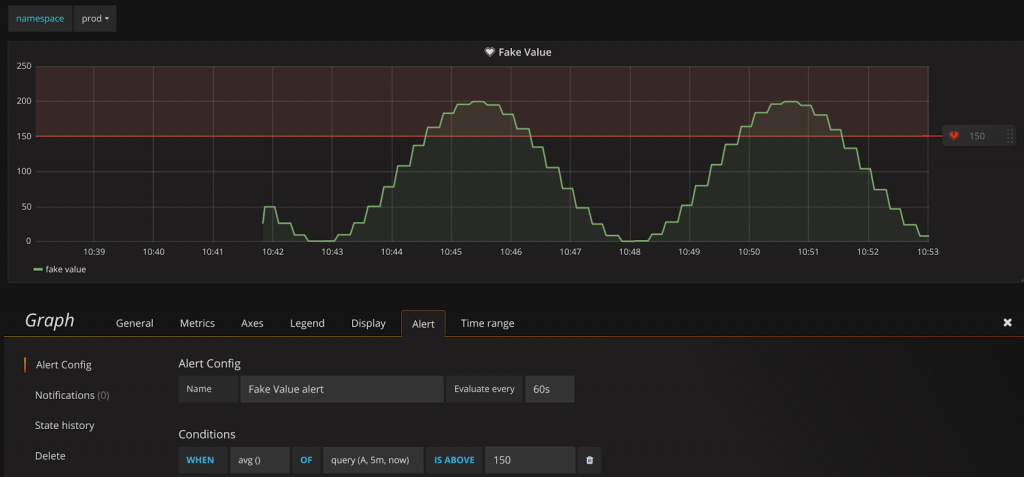
- Via Grafana qui est désormais capable de mettre des alarmes sur des métriques issues de Prometheus Avantages de cette solution : le positionnement des seuils est fait à chaud, directement en déplaçant un curseur sur les graphes. Une ligne rouge matérialise naturellement les seuils sur les graphes. Un petit cœur (vert ou rouge) montre simplement le niveau de l’alerte. L’intégration visuelle est complète. Inconvénients de cette solution : Grafana qui était jusqu’à présent cantonné à des fonctions de visualisation de graphes devient un composant critique puisque s’il tombe les alertes ne sont plus remontées. Citons également le fait que les requêtes paramétrées ne sont pas éligibles à servir de source pour des alertes.
Limitations
Par rapport à des composants plus historiques comme Nagios ou Zabbix, le travail de configuration est plus important : Les solutions historiques sont très bien fournies en templates et autres pré-configurations pour des éléments de monitoring classiques. La communauté Grafana, qui partage activement des dashboards pour tous types d’applications et de système compense en partie ce manque.
On peut également reprocher à Grafana le manque de certaines fonctionnalités classiques de Nagios/Zabbix comme des contrôles d'accès avancés ou des dépendances entre les alertes. Si le premier point n'intéressera pas tout le monde, le second est déjà identifié par Grafana qui prévoit de le gérer dans une prochaine version.
Nous ne disposons pas encore suffisamment de retour d’expérience sur les performances de collecte ni du dimensionnement des serveurs Prometheus. L’absence de capacité de partitionnement (sharding) est à la fois un avantage (une installation très simple) et une limitation sur des gros parcs à superviser. Certains articles de blog mentionnent des millions d’indicateurs collectés toutes les 10s, ce qui paraît déjà suffisant pour des parcs assez volumineux.
Mentionnons également le projet Cortex (actuellement en pré-ß) qui vise à réimplémenter un serveur Prometheus multi-tenant et scalable horizontalement.
La profondeur d’historique par défaut de Prometheus est de 15 jours. Même s’il est techniquement possible d’augmenter cette valeur, il n’est pas conseillé de mettre des années de profondeurs. Les développeurs du logiciel expliquent clairement que Prometheus se positionne plus comme un système de persistance à court et moyen terme et non à long terme comme InfluxDB. À noter également des travaux en cours pour tenter de précisément utiliser InfluxDB, soit comme un système de débordement, soit un backend à part entière. Affaire à suivre…
Conclusion
À qui s’adressent les indicateurs ? L’intérêt du couple Prometheus / Grafana est de donner de la visibilité aux Ops, sur l’état de leurs clusters distribués. Les indicateurs CPU, RAM, disque vont permettre de gérer le capacity planning et d’anticiper les incidents relatifs à la plateforme. Quant aux développeurs, ils pourront par le biais du SDK Prometheus ajouter leurs métriques et mesurer ce qui a de la valeur à leurs yeux : codes http, latence par page, déploiements de l’application… L’association des indicateurs Dev & Ops donnera la possibilité de mettre en corrélation l’impact de l’infrastructure sur l’application et inversement.
Le couple Prometheus / Grafana fournit un ensemble très intéressant pour les systèmes dynamiques et distribués comme Kubernetes, mais l’est plus généralement pour tout type de besoin de monitoring. Le duo de choc offre un bon compromis entre des solutions simplistes et trop rigides et des offres plus complexes à mettre en œuvre.
Le mécanisme d’exposition de métriques par une URL est par construction facile à implémenter et l’ajout de métriques personnalisées trivial. Nous sommes convaincus que c’est ce genre de simplicité d’implémentation dans les applications qui permettra d’améliorer leur supervision, technique et fonctionnelle. Attention tout de même bien à mettre un mécanisme de contrôle ou de limitation d’accès pour vous assurer que des informations sensibles ne fuitent pas via ces URLs.