Évolution vs. stabilité : comment piloter la fiabilité de ses services ? Compte-rendu du talk de Simon Lefort et Simon Devineau à la Duck Conf 2024
Cette année, j’ai pu revenir à la DuckConf au Pavillon Chesnaie du Roy en tant que participant. Le plaisir est différent mais toujours au rendez vous ! Le talk qui m’a le plus appris, en me sortant de mon expertise : Slow.tech : l'écoconception numérique sera radicale ou ne sera pas ! Et celui que je vais vous raconter traite du pilotage de produit par l’équilibre entre l'évolution et la stabilité.
Que viennent nous raconter les 2 Simon ? Déjà, il y a de la publicité mensongère, on m’avait promis 2 Simon ! L’un des 2 a dû décommander, pas de soucis : le talk parle de fiabilité (c’était un sujet identifié, accepté et owned) … c’est un peu méta comme talk 😀 : ça s’est super bien déroulé le jour J, encore bravo fois 2 aux 2 Simon !

Du PoC au clash
Tout débute par un PoC avec une base de données où l’utilisateur admin (dont le mot de passe est connu par toute l’équipe) est exposée sur internet et finit en Production. La suite de l’histoire vous donnera sûrement un goût de “déjà vu” : la vision Produit priorise les fonctionnalités alors que la vision Technique cherche à sécuriser l’accès à la base de données. L’incompréhension fait monter l’irritation et donne le sentiment à Simon d’être le dernier rempart de la sécurité du système.
Pourquoi est-ce souvent l’Ops qui s’en préoccupe ? Pourquoi l’Ops se retrouve-t-il régulièrement à définir ses propres priorités ? Pourquoi est-ce si difficile de prioriser la fiabilité en regard des évolutions fonctionnelles ?
Nous mettons souvent dans la balance “propriétés fonctionnelles” versus “propriétés non fonctionnelles”. Dont celles qui nous intéressent aujourd’hui : l’évolution et la fiabilité. Soit je livre une nouvelle fonctionnalité aux utilisateurs finaux, soit je travaille sur la capacité du système à fonctionner sans défaillance et inspirer confiance.
Qu’est-ce que la fiabilité et selon qui ?
La réponse variera selon le type de population :
- un utilisateur final : “le site est fonctionnel”
- un C-level : “mes équipes livrent dans les temps”
- un développeur : “je peux introduire un changement sans tout casser”
- un opérateur : “j’ai une maîtrise du système, je suis capable de comprendre un incident à partir des informations à ma disposition”
Si l’affirmation est avérée selon le type de population alors le service est considéré fiable et inspire la confiance.
“La fiabilité est la propriété non fonctionnelle la plus importante d’un produit.
Sans cela, le reste ne sert à rien”
Une fonctionnalité présentée en démonstration d’itération, mais inutilisable une fois livrée en production ou ne résistant pas aux pics de charge, perdra toute sa valeur métier.
“C’est pas fonctionnel, mais ça fait partie du produit, donc il faut s’en occuper” nous disaient Borémi et Grégoire dans la conférence “Pourquoi le best of des services managés ne vous sauvera pas (complètement)”.
Pourquoi est-ce si difficile de prioriser la fiabilité ?
Les Simon nous partagent 5 constats fréquemment rencontrés à l’origine de cette difficulté à prioriser la fiabilité :
La fiabilité est implicite
Personne ne dit : “je veux ce produit ET qu’il fonctionne”. Tout le monde s’attend à ce que ce soit le cas. Or les conditions d’exécution ne sont pas explicitées, c’est forcément la voie à la libre interprétation des exigences de fiabilité par les équipes qui réalisent la fonctionnalité.
Illustrons ce propos par 3 petits cochons qui doivent chacun construire une maison. Une maison de paille, de bois ou de brique ?

Si chaque maison a les mêmes propriétés fonctionnelles, le cochon qui a construit sa maison en brique aura investi plus d’énergie et de temps pour réaliser et livrer sa maison. En revanche, il aura correctement interprété les exigences de fiabilité dans le contexte d’un loup qui souffle avec une force dévastatrice.
La motivation extrinsèque demande de la discipline
La matrice d’Eisenhower nous propose un modèle de priorisation des tâches selon l’urgence et l’importance.
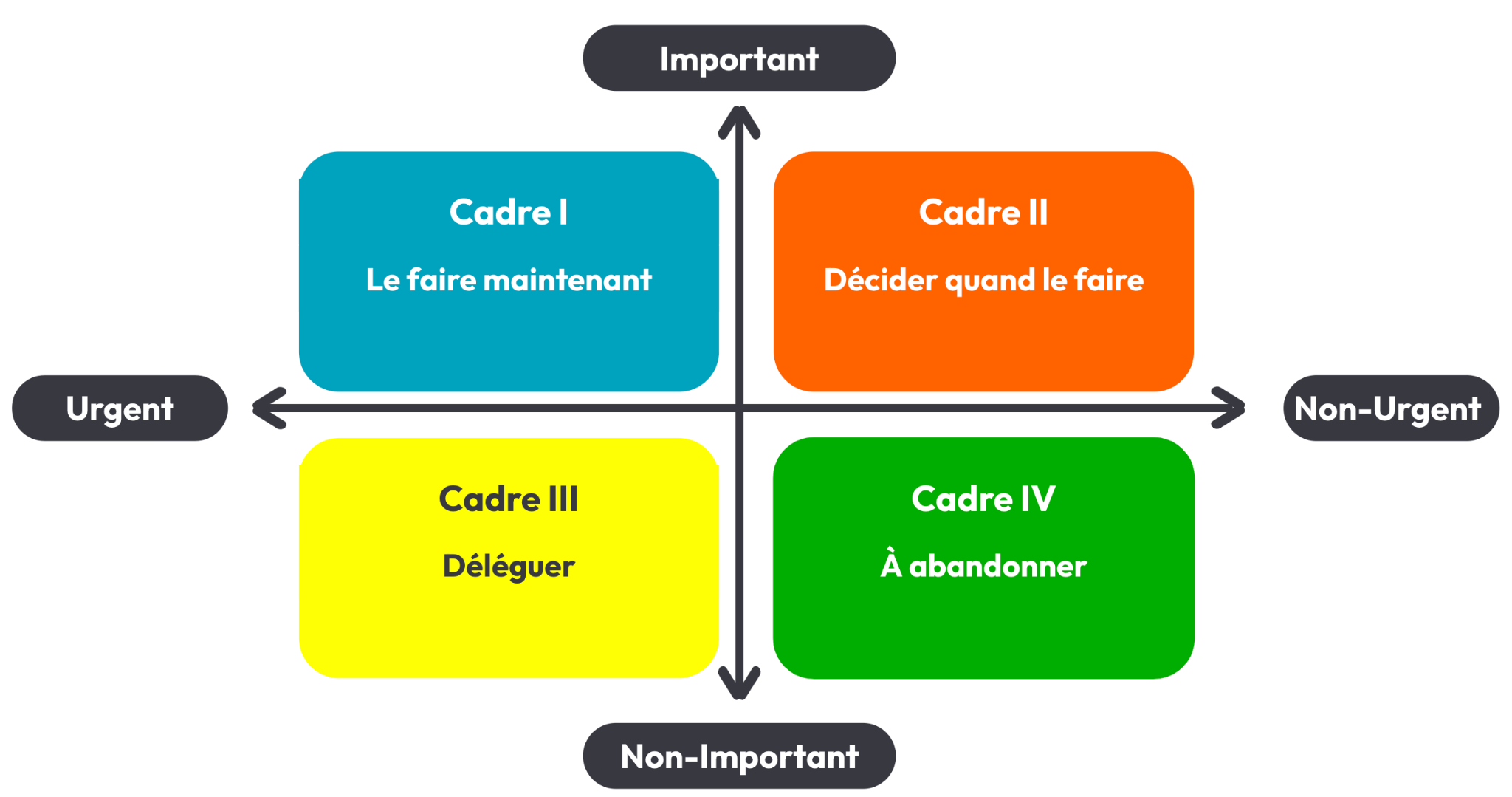
Les tâches non urgentes seront déléguées ou abandonnées. Les tâches importantes et urgentes (cadre 1) seront portées par des acteurs externes à l’équipe et ne feront pas l’objet de débat. Et enfin, les tâches du cadre 2 (importantes et non urgentes) feront l’objet de planification. C’est principalement dans ce dernier cadre que le travail en continu sur la fiabilité va se jouer. Ce travail en continu demande de la persévérance et de l’énergie : être proactif en continu (et pas que réactif) demande de l’auto-motivation.
Tous les murs n’ont pas encore été brisés
L’Agile a assuré la communication entre le Métier et les équipes de développements avec des cycles courts permettant d’évaluer et de s’adapter aux enjeux métiers. Le DevOps est venu étendre l’Agilité vers le monde des opérations en favorisant la collaboration entre le monde du développement et de la production pour réduire le Time To Market et améliorer la qualité en continu.
Quels sont les canaux de communication entre le Métier et les Ops ? La relation est souvent inexistante, les Ops sont assez loin du Métier. Ces derniers ne sont pas forcément conscients du travail effectué par les Ops parfois vu comme un centre de coût. Le budget des opérations trouvera souvent du financement à travers le budget du Métier. Grossièrement avec un cliché : “l’infra n’apporte pas de valeur métier, c’est un centre de coût donc les frais doivent être limités”. Dans cette situation, c’est un peu la croix et la bannière pour aller chercher un financement, pire la communication avec le Métier pourrait être indirecte en passant par l’équipe de développement.
La boucle de feedback qui n’arrive pas (encore)
Les évolutions ou corrections fonctionnelles auront une boucle de feedback relativement simple : après la release, l’équipe va chercher à recueillir de la mesure ou des retours utilisateurs. Pour mesurer la fiabilité d’un système, les axes seront l’intervalle de temps entre 2 incidents ou l’impact des incidents. On se retrouve dans une contradiction à attendre un incident (pour valider nos hypothèses de travaux) et espacer le temps entre 2 incidents (pour garder la fiabilité du système).
Exemple : suite à un incident, le système ne nous remontait pas assez d’information ou pas assez finement. L’équipe ajuste le tir avec des modifications dans le code, celles-ci sont livrées en production … et l’équipe se retrouve à attendre la prochaine occurrence de l’incident pour valider si ça fiabilise le système (bon ok, il y a toujours l’option de déclencher l’incident volontairement pour tester en production avec du Chaos Engineering mais vous avez compris le paradoxe).
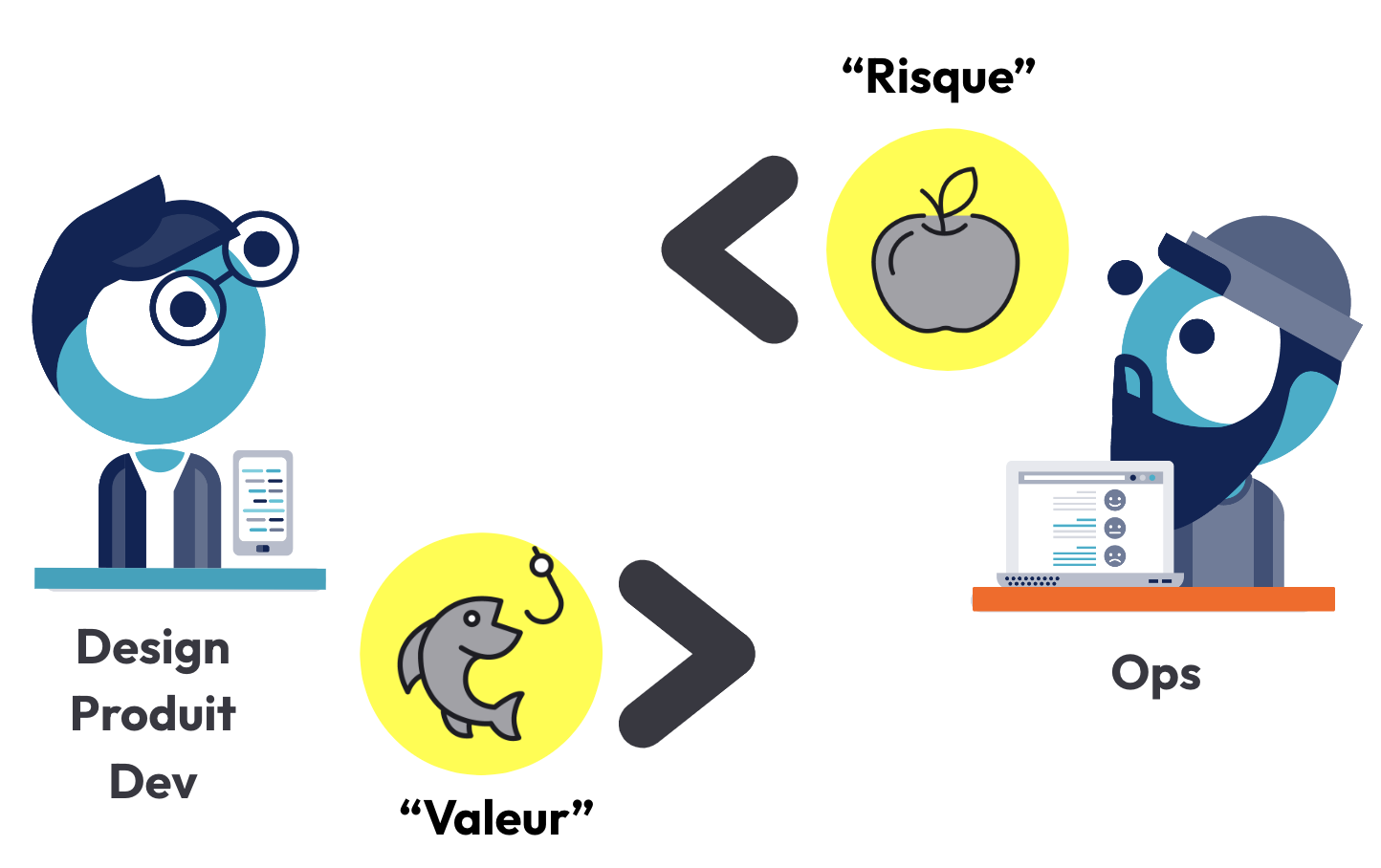
La monnaie d’échange de priorité est différente
Dans le cas où le canal de communication existe avec toutes les parties prenantes, la priorisation des sujets se fait souvent par la négociation. Dans le cas de la fiabilité, l’étalon de mesure n’est pas celui utilisé pour les évolutions. Les évolutions vont plutôt parler par le prisme de la valeur alors que la fiabilité s’exprimera par le risque. Comment dialoguer et comparer lorsque nous ne parlons pas le même langage ?
5 idées pour prioriser la fiabilité
1. Attendre que la prod tombe (mauvaise idée)
L’approche est purement réactive, les équipes sont dos au mur et doivent gérer la pression des usagers mécontents. Dans ce malheur, toutes les parties prenantes seront au moins réunies autour d’une table (une war room, une salle de crise, une visio avec 20 personnes, …) et la discussion sur la priorisation des sujets de fiabilité pourrait être entamée.
2. Dédier des phases de projets à la fiabilisation (encore une mauvaise idée)
Quelques semaines avant d’ouvrir le service en production : “J’ai toutes mes fonctionnalités par contre les tirs de perf, la campagne de sécurité, etc … ont remonté quelques défauts. Nous allons donc nous concentrer là-dessus et ne traiter que ces sujets”. Si l’objectif est “simple” (on ne s’occupe que de ça), la nature du travail change, c’est de la gestion de risque et non de la valeur. Du jour au lendemain, le paradigme change et les équipes doivent apprendre en marche forcée. Les conséquences peuvent amener à repenser l’architecture ou faire du refactoring de code, … C’est donc potentiellement plus coûteux au global de rendre un système fiable a postériori qu’au fur et à mesure.
Ces mauvaises idées commencent à ressembler à une mauvaise pub non ? Promis, la suite a plus de sens !
3. Dédier 20% de la bande passante à la fiabilité
La fiabilité (tout comme la dette technique) est traitée au fil de l’eau. Les équipes sont sensibilisées au sujet et apprennent en marchant. Les 2 paradigmes (gestion de la valeur et gestion du risque) sont vécus en parallèle. La négociation est moins un sujet, car c’est inclus dans la planification par défaut.
4. Déployer en production rapidement et plus souvent
Simon nous rappelle ici une des pratiques Agile : découper et livrer des petits incréments en production pour mesurer, valider des hypothèses et ajuster le système. L’ajustement se fera sur le plan fonctionnel ET de celui de la fiabilité. Le périmètre des chantiers de fiabilités porte sur l’application comme son infrastructure, déployer ces incréments de fiabilité avec un feedback rapide laisse l’opportunité aux développeurs d’appréhender la production petit à petit.
5. La satisfaction utilisateur : la monnaie commune entre le métier et les opérations
Ils nous en parlaient plus tôt, il faut trouver un langage commun pour négocier. Que ce soit une évolution fonctionnelle ou de la fiabilité, regardez le sujet sous le prisme de la satisfaction client. Évolution puis fiabilité ? Inversez le paradigme ! Est ce que mon produit est assez fiable pour satisfaire mes utilisateurs ? Si oui, est ce que mon produit est fonctionnellement assez riche pour satisfaire mes utilisateurs ?
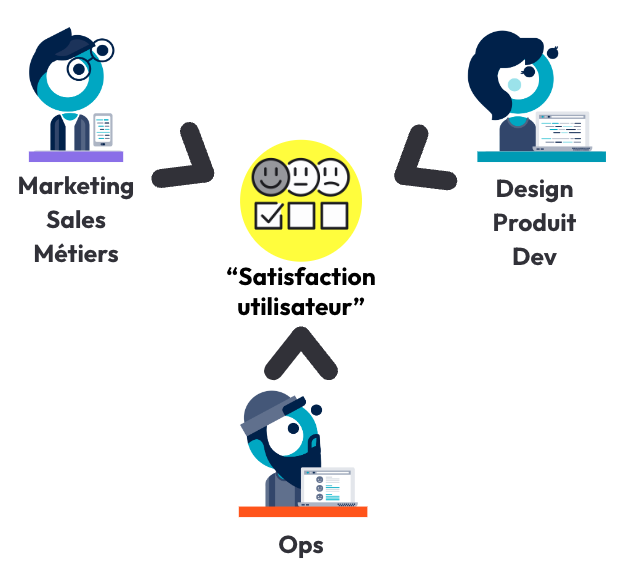
La réponse à la question sur la fiabilité doit rester une histoire de produit : cette satisfaction doit se définir avec le métier et mesurer. Pour ce faire, les SLI et SLO sont un bon point de départ. Le SLO (Service Level Objective) est le contrat défini entre toutes les parties Métiers, Dev et Ops qui fera office d’arbitre pour trancher si les utilisateurs sont satisfaits de la fiabilité et ont confiance dans la produit. Le SLI (Service Level Indicator) est la mesure liée à l‘objectif. Un exemple simpliste : “Je suis satisfait si 9 vidéos sur 10 sont chargées en moins d’une seconde sur mon site de streaming vidéo”. Dans ce cas, les points de mesures se positionneront sur le temps entre un clic sur le bouton PLAY ▶️ et le démarrage effectif. Si ce temps n’est pas respecté pour 9 vidéos sur 10, alors la priorisation sera mise sur la fiabilisation de cette fonctionnalité.
Takeaways
- La Fiabilité est la propriété non-fonctionnelle la plus importante d’un produit
Sans cela le produit n’est pas utilisable - La Fiabilité est avant tout un sujet “produit”
Trouvez la monnaie d’échange pour établir un dialogue entre le Métier, Dev et Ops - Faites entrer les initiatives de fiabilisation et d’évolution dans le même backlog
La vision produit doit être unifiée et pilotable depuis un seul point d’entrée - Utiliser les SLI/SLOs pour arbitrer entre fiabilité et évolution Définissez ensemble et mesurer ce qui est satisfaisant pour garder la confiance des utilisateurs pour prioriser
Ce que j’ai apprécié dans ce talk
La réflexion des Simon suite à une conversation familière sur la sécu et les enjeux métiers a débouché sur un talk avec une prise de recul et des propositions pour rationaliser la prise de décision autour de pratiques partagées avec les parties prenantes.
La fiabilité est une question de perspective, si elle n’est pas explicite, cela laisse place à de l’interprétation. Ça tombe sous le sens pourtant ça a le mérite d’être formulé et rappelé.
La motivation sur la planification de la fiabilité demande plus d’énergie … ça fait tellement écho à des expériences passées. Je me demande encore comment la renouveler ou la maintenir ? Quelques leviers : aller voir ce qu’il se fait ailleurs (en conférence par exemple) pour s’inspirer, déléguer ou faire tourner le porteur sur ces sujets, prendre des vacances pour souffler un peu et avoir des rotations ou nouvelles arrivées dans l’équipe permettent de redynamiser le collectif.
J’ai hâte d’avoir la prochaine discussion pour arbitrer entre fiabilité et évolution avec de la satisfaction utilisateur au centre du débat, et vous ?
Liens et références
- https://blog.octo.com/compte-rendu-matinale-accelerate-la-vitesse-conditionne-lexcellence-un-nouveau-paradigme-dans-le-developpement-logiciel
- https://blog.octo.com/compte-rendu-sre-decouvrez-les-pratiques-de-run-de-demain-par-adrien-boulay-la-duck-conf-2022
- https://blog.octo.com/slo-la-puissance-insoupconnee-des-metriques
- https://www.fnac.com/livre-numerique/a11784658/Jez-Humble-Accelerate
- https://sre.google/sre-book/table-of-contents/