Event Sourcing & noSQL
I saw the talks of Greg Young about CQRS & especially “Event Sourcing” a couple of times and each time, I really really tell myself this pattern is just “génial” (the way we say it in french) even if Martin Fowler wrote about it in 2005 and deals in details with implementation concerns and issues (especially in the cases of integration with external systems).
Event Sourcing : stop thinking of your datas as a stock but rather as a list of events... When you look at your database, you look at a stock. For instance, you have X millions of clients, each of them have personal datas like maiden name or address. When you look at these clients, you cannot understand the history of each client. You can just have the current state. The main idea (or mindset shift) behind Event Sourcing is to look at your database not as a stock but as a series of events that can be used to build the current stock. This is more obvious if you think of your bank account. The stock is your balance : how much money you have. The events are all the operations (credit or debit) that occured and “created” the balance.
So with this perspective, some of our systems can be viewed like this. Instead of having one stock, you have one event log (typically for write queries) 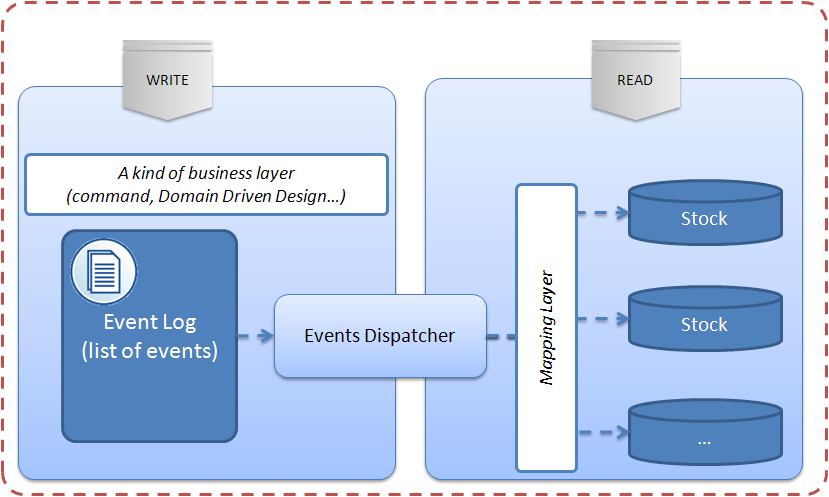
There are also a couple of important things in “Event Sourcing” : - the messages that are broadcasted into the “events dispatcher” (and so are used to build the stock) must be exactly the same than the events stored in the Event Log. If not, you will loose the event replay capabilities of the system. A tricky point would certainly be to detect errors and know you need to replay the logs... - the longer your system will live, the more events you will have and a complete rebuild will certainly become impossible or at least too long. You will so have to find a way to build trusted snapshot of your stocks and thus clean, periodically, the event log. Another tricky point.
Event Sourcing tells nothing about the storage layer of the stock(s). You can of course use a relational database and inherit the power of SQL language. You could also use a simple cache if it fills your needs.
Event Sourcing tells nothing about the Events Dispatcher. Maybe you just want it to be a coding pattern and your Events log and stock will be different tables from the same database. Maybe you will have to introduce a kind of MOM (typically like OpenAMQ) and have different databases. Maybe you will want to add CEP to your Events Dispatcher and so being able to generate more complex events...
At last, Event Sourcing tells nothing about the “Event Log” storage and you can of course use a relational database. But imagine a system where you need, for write queries, a high available, fault-tolerant system with a high throughput. In that case, noSQL could be a great solutions. You just store the events as key/value pairs... And “Event Sourcing” could resolve the limited querying capabilities of most of the noSQL solutions by querying the stock.
Then of course this is not for free and the systems will be more complex : more code to write, more storage to manage, and event mechanism to monitor...But you can have, if you need it, the best of the two worlds : high throughput and availability for write queries, (powerful) SQL language for read queries. In brief, I guess we are entering the BASE World...