Event-Driven Architecture chez Octo : épisode 3, les services AWS et la config
Bon. Si vous avez survécu à l'épisode 2, vous méritez une récompense. La voici : cette fois, on arrête de parler théorie et on construit pour de vrai.
Petit récap pour ceux qui débarquent. Dans l'épisode 1, on a vu le pourquoi: un vieux legacy, des SaaS à faire dialoguer, et le choix de l'Event-Driven Architecture pour mettre tout ce petit monde d'accord. Dans l'épisode 2, on a enchaîné avec la théorie: les patterns, les garanties qu'on n'a presque jamais, l'idempotence (vous vous souvenez, le personnage principal). Aujourd'hui, place à la pratique: du vrai code, de la vraie infra, et promis, des vrais schémas.
Et pour pas rester dans l'abstrait, on va suivre un seul et même événement de bout en bout, du début à la fin de son voyage : une candidature qui change de statut sur SmartRecruiters, et qui finit par déclencher une notification dans Mattermost. C'est un cas qui tourne vraiment chez nous, donc le code que je vais vous montrer n'est pas un exemple sorti d'un tuto, c'est ce qui est en prod (à quelques secrets masqués près, on n'est jamais trop prudent).
Côté stack, on est full AWS : EventBridge en chef d'orchestre, API Gateway en porte d'entrée, Lambda un peu partout, et SQS pour faire tampon. Si vous n'êtes pas sur AWS, ne fuyez pas: les briques ont des équivalents ailleurs, et les concepts, eux, sont les mêmes partout.
Dernière chose, à la base je voulais tout caser dans un seul article. Et là je compte les lignes et clairement on n’y est pas… Donc c’est parti pour un pti découpage. Aujourd'hui, c’est donc le trajet complet d'un événement. Dans le prochain, on verra comment rendre tout ça robuste et industrialisé pour la prod avec de l’idempotence, de l’observabilité, des modules réutilisables etc…
Pourquoi EventBridge ?
Message broker ou event broker ?
Premier piège dans lequel on a failli tomber : confondre message broker et event broker. Ça se ressemble, mais ce n'est pas la même philosophie.
Un message broker (SQS, RabbitMQ, …), c'est fait pour acheminer un message d'un point A vers un point B. Souvent du point-à-point, le message est consommé une fois par un destinataire, puis il disparaît. On est assez proche de la logique de commande : "tiens, voilà un truc à traiter, débrouille-toi avec". C'est parfait pour distribuer du travail, mais ça suppose que l'émetteur sait qui va consommer.
Un event broker (EventBridge, Kafka, …), c'est une autre intention : on publie un événement sans savoir qui va faire quoi. Plusieurs consommateurs peuvent réagir au même événement, indépendamment les uns des autres, avec du routing par règles. C'est le pub/sub de l'épisode 2, et c'est exactement la nuance "ça s'est passé" plutôt que "fais ça", mais cette fois côté infra.
Vous l'aurez compris, pour faire de l'EDA, c'est l'event broker qu'on veut. Le découplage qu'on cherchait depuis l'épisode 1, il vient de là.
Et pourquoi EventBridge en particulier ?
Okay on veut donc un event broker, mais on prend lequel ? On aurait pu partir sur Kafka, mais ça voulait dire opérer un cluster, le surveiller, le mettre à jour… bref, de l'infra à bichonner. Or on est une petite équipe, et perso j’aime faire beaucoup avec peu.
EventBridge cochait toutes les cases :
- Intégration à AWS: ça tombe bien, toute notre infra est déjà dessus, on joue déjà avec des lambda, de l’api gateway, … Et interconnecter tout ça à eventbrige c’est 4-5 lignes grand max.
- Serverless: on gère rien, les patchs, les clusters tout ça bah c’est AWS qui fait :)
- Pay-per-user: Perso j’aime faire comme au magasin, je paye ce que je prends et pas le reste. Ici on paye à l’événement publié, si y’a rien qui tourne la nuit ça nous coûte 0 !
Concrètement, créer notre bus ça revient à ça :
resource "aws_cloudwatch_event_bus" "bus" {
name = "octo-bus"
}
Oui, c'est tout. Juste une ressource Terraform et notre chef d'orchestre est né.
Pas de serveur à provisionner, pas de capacité à dimensionner, et pour une petite équipe comme la notre ça fait une grande différence.
En vrai chez nous on rajoute au nom un workspace terraform pour avoir un bus par environnement (dev1, dev2, démo, prod). Mais pour que le code soit plus lisible je vais enlever cette notion des exemples de mon article.
La grande transhumance
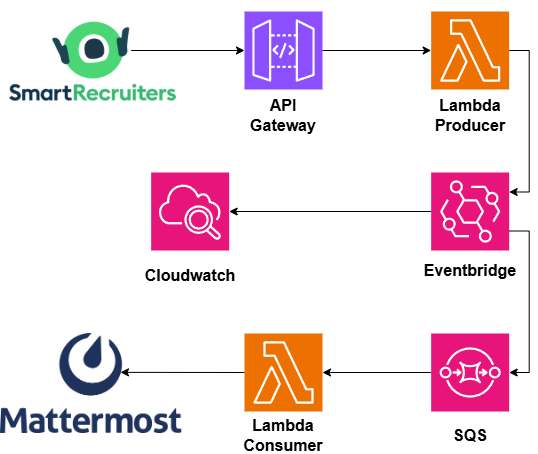
Avant de plonger dans chaque brique, regardons le trajet complet de notre événement.
Notre candidate, appelons-la Camille, vient de passer au statut "recrutée" dans SmartRecruiters. Voici ce qui se passe, étape par étape :
- SmartRecruiters, grâce à un webhook que l’on a configuré, appelle notre API Gateway.
- API Gateway déclenche une Lambda "producer", qui va chercher les détails utiles (le candidat, le job, la tribu…) et construit un événement métier propre.
- La Lambda publie cet événement sur le bus EventBridge.
- Le bus applique ses règles: chaque règle qui matche l'événement le pousse vers une file SQS.
- Chaque SQS déclenche une Lambda "consumer" qui fait le boulot. Ici c’est de poster un message dans Mattermost pour indiquer qu’il y a une nouvelle embauche.
Et si vous remettez le vocabulaire de l'épisode 2 par-dessus, vous retrouvez vos petits : le producer qui appelle l’event broker et le consumer qui récupère en bout de chaîne.
Alors oui, vous allez me dire qu’il y a un intrus: SQS. En fait c’est un invité bonus qu'on n'avait pas en théorie: un tampon entre le bus et le consumer, dont on verra l'intérêt plus bas.
Petit détail qui a son importance : en parallèle de tout ça, une règle attrape-tout copie chaque événement qui passe vers CloudWatch. Comme ça, quoi qu'il arrive, on a une trace de tout ce qui a transité sur le bus, très pratique pour le debug ;)
Avec un beau schéma, ça donne ça :
Le producer
Premier maillon de la chaîne : le producer. Son job, c’est de prévenir qu’il s’est passé quelque chose. Ici, SmartRecruiters qui nous prévient qu'une candidature a bougé.
Mais du coup, comment SmartRecruiters nous préviens ? Car on n’a pas la main sur son code… La solution que l’on a mis en place chez nous, c’est d’utiliser ses webhooks. Le producer est donc une Lambda exposée derrière une API Gateway.
SmartRecruiters tape sur une URL, l'API Gateway reçoit la requête et déclenche la Lambda. Côté Terraform, la définition de la Lambda est volontairement simple :
resource "aws_lambda_function" "producer" {
function_name = "bus-producer-application_updated"
handler = "index.handler"
memory_size = 256
package_type = "Zip"
role = aws_iam_role.producer.arn
runtime = "nodejs22.x"
architectures = ["arm64"]
timeout = 10
s3_bucket = var.s3_bucket_id
s3_key = var.application_updated_key
environment {
SR_CLIENT_ID = “My_Client_Id”
SR_CLIENT_SECRET = “My_Secret_Id”
}
layers = [var.generic_layer_arn]
}
Rien d'exotique : Node 22, arm64 (moins cher et un poil plus économe en énergie que x86), 256 Mo de RAM, 10 secondes de timeout. Le code est tiré d'un S3, et on lui attache un layer "generic" qui contient nos services partagés (le client SmartRecruiters, le logger, etc.).
On reparlera des layers dans le prochain article plus en détail.
Un mot sur la sécurité de l'API Gateway
Avant d'aller plus loin : exposer une Lambda sur Internet via API Gateway, ça veut dire laisser sa porte ouverte à tout internet. Et une porte, ça se protège. AWS propose plusieurs mécanismes, à choisir selon le contexte :
- Les clés d'API: le client doit présenter une clé valide. Simple, mais ça ne fait que de l'identification, pas une vraie authentification forte.
- Les authorizers Lambda: une micro Lambda qui valide la requête (token, signature…) avant de laisser passer. L’avantage c’est qu’on a la main à 100% sur code.
- L'autorisation IAM: si l'appelant est un autre service AWS, on s'appuie sur les rôles IAM.
- AWS WAF: pour rajouter une couche de filtre de sécurité contre les requêtes malveillantes, limiter le rate, etc…
De la donnée brute à l'événement
Une fois la requête validée, le vrai boulot commence. SmartRecruiters ne nous envoie que 3 identifiants pour retrouver le candidat, le poste et la candidature, soit vraiment pas grand-chose. Comme on l'a vu dans l'épisode 2, chez nous on veut des événements autosuffisants (l'Event-Carried State Transfer), nos consumers ne devraient pas avoir à rappeler SmartRecruiters pour bosser.
Donc le producer doit enrichir ce qu’il reçoit du webhook, il va chercher le candidat, le job, les propriétés de la candidature (la tribu, le grade, le type de contrat…) via l'API SmartRecruiters, et il assemble tout ça dans un événement métier complet.
import { EventBridgeClient, PutEventsCommand } from '@aws-sdk/client-eventbridge';
import SmartrecruitersService from '/opt/services/smartrecruitersService.mjs';
export const handler = async event => {
const body = JSON.parse(event.body);
const smartrecruitersService = new SmartrecruitersService();
// On enrichit : candidat + job
const candidate = await smartrecruitersService.get(`/candidates/${body.candidate_id}`);
const job = await smartrecruitersService.get(`/jobs/${body.job_id}`);
const busEvent = {
version: '1.0',
candidate: {
firstName: candidate.firstName,
lastName: candidate.lastName,
},
job: {
id: body.job_id,
title: job.title
}
};
// Et on publie sur le bus
const eventbridge = new EventBridgeClient();
await eventbridge.send(
new PutEventsCommand({
Entries: [
{
Source: 'octo.smartrecruiters',
DetailType: 'application_updated',
Detail: JSON.stringify(busEvent),
EventBusName: process.env.BUS,
},
],
})
);
return { statusCode: 202, body: 'ok.' };
};
Le cœur de tout ça, c'est le PutEventsCommand. Si on regarde ce qu’on lui envoie :
Source: qui émet l'événement. Iciocto.smartrecruiters. C'est notre convention de nommage à nous, vous pouvez mettre ce qui vous inspire le plus.DetailType: le type métier de l'événement.application_created,application_updated, etc… C'est l'équivalent dutypeau passé dont on parlait dans l'épisode 2).Detail: la payload, sérialisée en JSON, c’est notre événement autosuffisant.
Notez aussi le **return 202** pour indiquer à SmartRecruiters qu’on a bien reçu et traiter le webhook. Cela va éviter qu'il re-tente à l’infinie de l’envoyer, le découplage commence dès la porte d'entrée.
Un producer, ça peut être plein de choses
Jusqu'ici on a vu un producer "webhook" : un SaaS externe nous tape dessus, on transforme, on publie. Mais c'est juste un cas parmi d'autres. N'importe qui capable de publier un événement sur notre bus peut devenir producer. Ça peut être une autre Lambda, un service interne, un script… ou carrément une de nos applications.
Chez nous c’est le cas de notre fameux legacy, Octopod, le backoffice de 13 ans dont on parle depuis l'épisode 1. Mais comme c'est une grosse appli historique, on a dû composer avec deux réalités différentes, et on a fini avec deux mécanismes complémentaires.
Cas 1 : Octopod émet ses propres événements
Pour certains événements métier qu'Octopod réalise depuis des années, le plus simple et le plus propre, c'est qu'Octopod les publie lui-même les événéments. Là où dans son code une action métier se produit, on ajoute un PutEvents. C'est l'EDA dans sa forme la plus pure : l'application dit explicitement "voilà, ce qui vient de se produire".
Concrètement, côté Octopod, ça ressemble à ça :
eventbridge.put_events({
entries: [{
source: "octo.octopod",
detail_type: "project_created",
detail: {
version: "1.0",
project: { id: project.id, name: project.name }
}.to_json,
event_bus_name: ENV["BUS"]
}]
})
On retrouve nos trois champs (source, detail_type, detail), exactement comme dans le webhook SmartRecruiters. Côté bus, un project_created émis par Octopod est un événement comme un autre. Et derrière, des consumers réagissent, par exemple créer une carte Trello. Octopod, lui, ne sait pas qu'il y a un consumer Trello au bout, et c'est très bien comme ça.
C'est la voie idéale. Le souci, c'est qu'elle demande de toucher au code de l'appli. Pour les nouveaux événements, aucun problème. Mais pour instrumenter 13 ans de legacy partout où une donnée change, c’est plus compliqué... Beaucoup de code et de risques...
Cas 2 : on écoute la base avec du CDC
D'où le second mécanisme, pour tout ce qu'on ne veut pas instrumenter à la main : le Change Data Capture (CDC). L'idée est simple, plutôt que de demander à Octopod d'émettre des événements, on écoute les changements de sa base de données. Dès qu'une ligne bouge dans certaines tables (un collaborateur, un groupe…), on capte la modification et on la transforme en événement sur le bus. Octopod ne sait même pas que le bus existe. Zéro ligne de code modifiée.
Techniquement, c'est AWS DMS (Database Migration Service) qui fait le gros du travail. On le configure en mode cdc (capture des changements uniquement), on lui dit quelles tables surveiller, et il pousse les changements dans un flux Kinesis.
resource "aws_dms_replication_task" "octopod" {
replication_task_id = "octopod"
migration_type = "cdc" # on ne capture que les changements
# ... source = base Octopod, cible = flux Kinesis ...
table_mappings = jsonencode({
rules = [
{ rule-action = "include", object-locator = { table-name = "groups" } },
{ rule-action = "include", object-locator = { table-name = "people" } },
# ...
]
})
replication_task_settings = jsonencode({
BeforeImageSettings = {
EnableBeforeImage = true # on capture aussi l'ancienne valeur sur UPDATE/DELETE
FieldName = "before"
ColumnFilter = "all"
}
})
}
Le EnableBeforeImage mérite une petite attention, il va permettre d’avoir l'état avant la modification, pas seulement après. Très pratique, car ça permet de savoir ce qui a changé et pas juste "il s'est passé un truc sur cette ligne".
Une Lambda producer est ensuite branchée sur le flux Kinesis, et son boulot comme pour le webhook c’est de transformer les enregistrements bruts en événements bien typés.
for (const record of event.Records) {
// les données Kinesis sont encodées en base64
const payload = JSON.parse(
Buffer.from(record.kinesis.data, 'base64').toString()
);
const { operation, 'table-name': table } = payload.metadata;
entries.push({
Source: 'octo.cdc',
DetailType: `octopod_cdc_${table}_${operation}`, // ex. octopod_cdc_people_update
Detail: JSON.stringify({
version: '1.0',
after: payload.data, // la ligne après modification
before: payload.before, // la ligne avant (grâce au BeforeImage)
}),
EventBusName: process.env.BUS,
});
}
await sendEventsInBatches(eventbridgeClient, entries); // par paquets de 10 (limite EventBridge)
Si vous partez sur cette solution, attention il y a un effet bizarre lors des événements de type "delete", c’est after qui contient les données de la ligne supprimée et non before.
Le routing : comment le bus sait à qui parler
Okay, notre événement est dans le bus. Maintenant, on en fait quoi ? C'est là qu'interviennent les règles (rules) d'EventBridge. Une règle, c'est globalement un filtre, "tel type d'événement, envoie-le vers telle cible". Tout le routing du système tient là-dedans.
Une règle, c'est juste un filtre
Dans sa forme la plus simple, une règle matche sur le detail-type :
event_pattern = jsonencode({ "detail-type" = ["application_updated"] })
Traduction : "tout événement de type application_updated, ça m'intéresse". Mais EventBridge va beaucoup plus loin : on peut filtrer sur le contenu de l'événement lui-même. Et c'est là que ça devient vraiment intéressant. Si on regarde notre règle pour la notification de bienvenue d’une nouvelle embauche.
event_pattern = jsonencode({
"detail-type" = ["application_updated"],
"detail" = { "status" = ["HIRED"] }
})
Là, on ne matche que les candidatures passées au statut HIRED. Une candidature qui passe en "entretien" ? La règle ne la voit même pas. Ce qui veut dire que le filtrage se fait au niveau du bus, pas dans le code du consumer.
Notre Lambda "notif Mattermost" ne sera réveillée que pour les recrutements confirmés, pas if status === 'HIRED' dans le code. Au passage cela génère aussi moins d'invocations inutiles, donc moins cher, et un consumer qui fait une seule chose perso j’aime bien car c’est clair et simple.
De la règle à la file
Une fois qu'une règle matche, elle pousse l'événement vers une cible. Chez nous, cette cible est systématiquement une file SQS (on verra pourquoi juste après)
resource "aws_cloudwatch_event_rule" "application_updated" {
name = "bus-consumer-application_updated"
event_bus_name = aws_cloudwatch_event_bus.bus.name
event_pattern = jsonencode({ "detail-type" = ["application_updated"] })
}
resource "aws_cloudwatch_event_target" "application_updated" {
rule = aws_cloudwatch_event_rule.application_updated.name
arn = aws_sqs_queue.application_updated.arn # la cible : une SQS
event_bus_name = aws_cloudwatch_event_bus.bus.name
role_arn = aws_iam_role.application_updated.arn # le droit d'écrire dans la file SQS
}
Le role_arn est important : pour qu'EventBridge ait le droit de déposer un message dans la file SQS, on lui donne un petit rôle IAM avec une seule permission, sqs:SendMessage sur cette file, pas besoin de plus.
Le fan-out : un événement, plusieurs réactions
Et maintenant, le moment que vous attendez depuis l'épisode 1, oui j’ai le droit de réver ;)
Qu'est-ce qui se passe quand plusieurs règles matchent le même événement ? Eh bien… elles se déclenchent toutes, en parallèle, indépendamment.
Reprenons Camille, notre nouvelle recrue. Son application_updated avec status: HIRED arrive sur le bus. Trois règles matchent :
- Une qui route vers la Lambda notif Mattermost (on prévient qu’une nouvelle embauche vient d’être réalisée)
- Une qui route vers la Lambda ticket JSM (on ouvre un ticket d'onboarding)
- Une qui route vers la Lambda Drive (on met à jour nos fichiers excel ^^).
Trois consumers, trois files, trois Lambdas, qui bossent chacun dans leur coin sans rien savoir des autres. Et le producer, lui, n'a émis qu’un seul événement. Il ignore totalement qu'il vient de déclencher trois actions.
Visuellement ça donne ça :
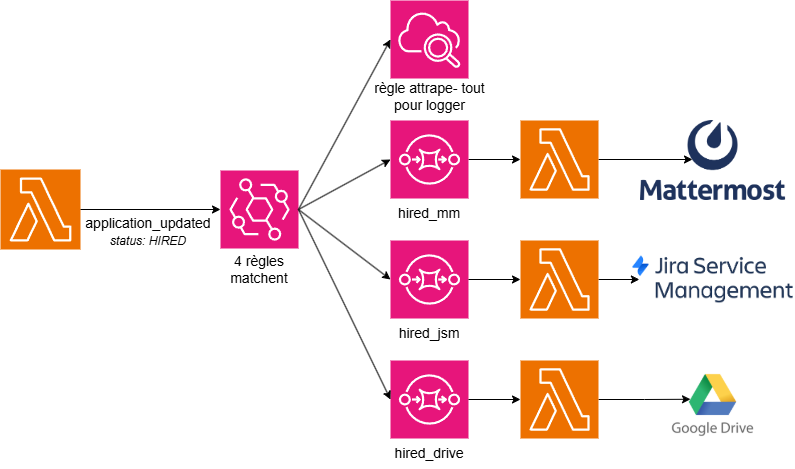
Et le meilleur, c'est ce qui se passe demain. Si on veut ajouter une quatrième réaction au recrutement, par exemple la mise à jour d’un outil RH, il suffit d’écrire une nouvelle règle, brancher une nouvelle Lambda, et c'est tout. Aucune modification côté SmartRecruiters, aucun risque de casser les trois consumers existants. Le découplage qu'on cherchait depuis l'épisode 1, il est là!
La règle attrape-tout
Dernière règle, et pas des moindres : celle qui matche absolument tout, pour copier chaque événement vers CloudWatch.
resource "aws_cloudwatch_event_rule" "bus-to-logs" {
name = "all-events-logs"
event_bus_name = aws_cloudwatch_event_bus.bus.name
event_pattern = jsonencode({ "source" : [{ "exists" : true }] })
}
Le pattern source exists est un petit hack bien pratique : tout événement a forcément une source, donc cette règle matche tout ce qui passe sur le bus. Résultat, on a une trace complète de chaque événement dans CloudWatch, sans effort. C'est un petit plus qui coûte pas grand chose, et la première brique d’observabilité que j’évoquerais plus longuement dans le prochain article.
Le consumer : SQS, Lambda… et la corbeille
La règle a déposé notre événement dans une file SQS, mais pourquoi ? Alors qu’EventBridge sait très bien déclencher une Lambda directement. Pourquoi s'embêter avec un service en plus ?
Pourquoi passer par SQS
Parce que ça va nous apporter trois choses qu'on ne veut pas coder nous-même :
- Un tampon. Si SmartRecruiters nous envoie 200 recrutements d'un coup (on peut rêver à une expansion florissante ^^), la file encaisse le pic et la Lambda dépile à son rythme. On va ainsi éviter 200 appels de lambda d’un coup.
- Les retries. Si le traitement échoue, le message reste dans la file et sera re-livré. On y revient juste après, car c’est pour moi l’intérêt principale.
- Du batch. C’est lié au tampon, plutôt que d’appeler la Lambda à chaque message, on va attendre un peu et envoyer plusieurs messages (batch_size), ce qui réduit le nombre d'appels et donc le coût.
Le branchement entre la file et la Lambda se fait avec un event source mapping, AWS surveille la file et invoque la Lambda quand des messages arrivent.
resource "aws_lambda_function" "application_updated" {
function_name = "bus-consumer-application_updated"
runtime = "nodejs22.x"
architectures = ["arm64"]
# ... dans le VPC, avec nos layers...
}
resource "aws_lambda_event_source_mapping" "application_updated" {
event_source_arn = aws_sqs_queue.application_updated.arn # la file
function_name = aws_lambda_function.application_updated.arn # …branchée sur la Lambda
enabled = true
}
Côté code, la Lambda reçoit les messages de la file, et chaque message contient l'événement qu'on avait publié.
const rawHandler = async record => {
const data = JSON.parse(record.body);
// ... Le code métier, ici poster le message dans Mattermost ...
};
// Le wrapper "lifecycle" ajoute des logs et traçabilité, mais on en reparle dans le prochain article
export const handler = withConsumerLifecycle(rawHandler);
FIFO ou standard ?
Par défaut, nos files sont standard : rapides, scalables, mais sans garantie d'ordre (souvenez-vous de l'épisode 2 : les événements peuvent arriver dans le désordre). Dans 90 % des cas, ça nous va très bien, par exemple la création d’un projet qui crée une carte Trello. Dans ces cas-là l'ordre n’a pas d’importance, on veut juste que tout soit créé.
Mais parfois, l'ordre est important. Si on prend cette fois la modification d'un projet, si une mise à jour "ancienne" est traitée après une plus récente, on écrase la bonne donnée avec une périmée. Pour ces cas-là, on bascule la file en FIFO.
resource "aws_sqs_queue" "application_updated" {
name = "bus-consumer-application_updated.fifo" # Il faut obligatoirement que ça se termine par .fifo
fifo_queue = true
content_based_deduplication = true
}
En FIFO, on traite généralement les messages un par un (batch_size = 1) pour préserver l'ordre. C'est plus lent, donc on l’utilise que quand l'ordre est vraiment critique.
DLQ, la poubelle d’SQS
Et voilà le moment où on est vraiment content d’avoir un SQS au milieu. Que se passe-t-il quand le traitement plante (Mattermost est down, un bug, une donnée inattendue) ?
Le message n'est pas perdu. Tant que la Lambda n'a pas confirmé le succès, SQS considère le message comme non traité : après un délai (le visibility_timeout) la Lambda est rappelée. Le message est donc automatiquement re-tenté. Mais pas à l'infini, sinon un message empoisonné bloquerait la file pour toujours. C'est le rôle de la redrive polic.
resource "aws_sqs_queue" "application_updated" {
name = "bus-consumer-application_updated.fifo"
visibility_timeout_seconds = 60
redrive_policy = jsonencode({
deadLetterTargetArn = aws_sqs_queue.application_updated-deadletter.arn
maxReceiveCount = 4
})
}
resource "aws_sqs_queue" "application_updated-deadletter" {
name = "bus-consumer-application_updated-deadletter.fifo"
}
Si on décrypte rapidement, après 4 tentatives ratées (maxReceiveCount), le message arrête de tourner en boucle et part dans la Dead Letter Queue. La file principale continue à traiter les suivants, et le message problématique est mis de côté, bien au chaud, pour qu'on puisse l'examiner.
Visuellement, voici le cycle de vie complet d'un message une fois dans la file
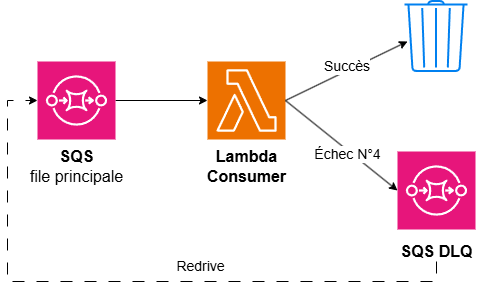
Et une DLQ, ça ne sert pas qu'à enterrer les morts. Une fois le bug corrigé (Mattermost de nouveau debout, le correctif déployé), AWS permet de rejouer (redrive) les messages de la DLQ vers la file d'origine : ils sont retraités comme si de rien n'était. C'est exactement le replay de l'épisode 2.
Et là, un rappel s'impose, vous savez de qui je vais parler. Si vos consumers ne sont pas idempotents, rejouer une DLQ peut re-faire des actions déjà réalisées. Le personnage principal n'a pas dit son dernier mot, car on l’a peu vu aujourd’hui… Mais il reviendra en force dans le prochaine article c’est promis!
Le boût du chemin
On est partis d'une candidature qui change de statut, et on a suivi l'événement sur tout son parcours : un producer qui le crée (webhook, émission directe ou CDC), le bus qui le route via ses règles, le fan-out qui le démultiplie vers plusieurs consumers, et chaque consumer qui le traite derrière sa file SQS (avec retries et DLQ pour encaisser les ratés). De bout en bout, sans qu'aucun maillon ne connaisse les autres.
C'est déjà un système qui tient debout. Mais entre "ça marche en démo" et "ça tourne en prod sans qu'on se réveille à 3h du matin", il y a un monde. Et c’est exactement ce que l’on verra dans le prochain article ;)
Aller un peu de spoilers
- L'idempotence pour de vrai
- L'observabilité, avec notre gestion de cycle de vie d’un consumer
- L'alerting automatique quand ça casse
- L’industrialisation avec des modules Terraform génériques qui font qu'ajouter un consumer prend trois minutes, les workspaces par environnement, et le déploiement via GitLab
- Nos galères bien réelles (coucou le
wal_leveldu CDC), histoire que vous évitiez les mêmes
À très vite pour la suite, et d'ici là, vous savez quoi : restez idempotents.