Event-Driven Architecture chez Octo : épisode 2, la théorie
L'article précédent, c'était l'apéro. On a posé les bases et raconté le pourquoi du comment on s'est lancés dans cette aventure EDA chez Octo. Si vous l'avez raté, c'est par ici, et je vous attends, prenez votre temps.
Bon, vous êtes là ? Parfait.
Cette fois-ci, on rentre dans le dur. Au programme : théorie, concepts, modèles, patterns, et tous les mots qui font passer pour un alien en repas de famille. Bref, l'article à la fois chiant et utile. Chiant parce que bon, faut bien se le dire, la théorie un lundi soir c'est pas forcément le rêve. Utile parce que sans ça, vous allez vous prendre les pieds dans le tapis dès que votre premier événement va arriver deux fois (oui, ça va arriver, on en reparle).
Mais promis, je vais essayer que ça reste cool à lire.
Bon en vrai j’ai écrit ça au début et maintenant que l’article est bouclé il est quand même assez long et en plus presque pas d’images…
Mais je n’ai pas envie de le découper car au moins tout est au même endroit. Donc n’hésitez pas à prendre une pause, faire un petit tour dehors ou encore dormir pour que ça soit plus digeste ;)
Les fondamentaux : on se met d'accord sur les mots
Avant d'aller plus loin, faisons un petit tour du propriétaire. Rien de révolutionnaire si vous avez lu l'article 1, mais on va creuser un poil plus, parce qu'on va avoir besoin de ce vocabulaire pour la suite.
Anatomie d'un événement
Un événement, c'est juste un message d’un truc qui s’est passé. Mais attention, un message avec quelques règles, et surtout une structure qu'on retrouve presque partout :
{
"id": "evt_abc123",
"type": "ApplicationUpdated",
"timestamp": "2025-05-31T14:23:00Z",
"version": "1.0",
"source": "smartrecruiters",
"data": {
"applicationId": "app_42",
"previousStatus": "NEW",
"newStatus": "INTERVIEW"
}
}
Décortiquons rapidement :
id: un identifiant unique. Ça paraît anodin, mais ça va devenir vital quand on parlera d'idempotence.type: le nom de l'événement. Au passé, toujours.ApplicationUpdated, pasUpdateApplication. C'est un fait, pas une instruction.timestamp: quand l'événement s'est produit. Utile pour le tri, le debug, et accessoirement pour comprendre pourquoi ça marche pas.version: parce qu'un jour, votre événement va évoluer, et que ce jour-là vous serez bien content de pouvoir gérer les deux versions en parallèle. Un peu comme une version d’API.source: qui l'a émis. Pas obligatoire, mais ça aide énormément quand vous avez 15 producers et que vous cherchez à identifier la source du problème.data: le vrai payload, le contenu métier. Ce qu'il faut savoir pour réagir.
Vous trouverez plein de variantes dans la nature en fonction des équipes, des outils, de l’envie du moment, mais l'esprit reste le même : un identifiant, un type, un quand, et du contenu.
Les 3 rôles
On les a vus dans l'article 1, mais je remets une petite couche parce qu'on va beaucoup les croiser dans la suite :
- Le producer : celui qui émet les événements. Dans notre cas, ça peut être notre legacy quand un client fait une action, ou un SaaS externe via un webhook.
- L'event broker : le chef d'orchestre. C'est lui qui reçoit les événements et les distribue. Chez nous c'est EventBridge (mais on en reparlera dans un autre article).
- Le consumer : celui qui écoute et réagit. Ça peut être une autre app interne, une lambda, un webhook vers un SaaS, … En fait la même chose que pour le producer.
Petit point important qu'on n'a pas trop creusé la dernière fois : entre le broker et les consumers, il y a souvent une notion intermédiaire qui s'appelle topic (ou channel, ou stream, ou règle, selon les technos).
C'est en gros une catégorie d'événements. Un consumer ne s’abonne pas à tout ce qui passe mais seulement à un/des topics précis (recruitment-events, orders, user-activity, etc.). Sinon welcome dans spamland avec des events envoyés partout.
Voilà, normalement maintenant on parle la même langue, on peut passer aux choses sérieuses.
Les patterns à connaître
Bon, maintenant qu'on a le vocabulaire, attaquons les vrais morceaux. Il existe plein de patterns en EDA, mais on va se concentrer sur les quatre que vous allez croiser à peu près tout le temps. Les autres, c'est souvent des variantes ou des combinaisons de ceux-là.
Pub/Sub : le pain quotidien
Le Publish/Subscribe, c'est LE pattern de base de l'EDA. Tellement commun que j’en ai parlé sans le nommer dans l'article 1.
Le principe : un producer publie un événement sur un topic, et tous les consumers abonnés à ce topic le reçoivent. Le producer ne sait pas qui écoute, et il s'en fiche royalement. Il envoie, point.
Ce qui est beau là-dedans, c'est qu'ajouter un nouveau consumer ne demande aucune modification côté producer. Vous voulez qu'un nouveau service réagisse aux candidatures mises à jour ? Vous l'abonnez au topic, et c'est réglé. SmartRecruiters n'en saura jamais rien.
C'est l'opposé exact du modèle "je t'appelle directement" où il faut connaître son destinataire. Et c'est ce découplage qui rend tout le reste possible.
Petit ou Gros event ?
Avec les termes bien compliqués ça donne : Event Notification ou Event-Carried State Transfer ?
Alors là, on touche à une question qui a l'air anodine mais qui va vous hanter : combien de données on met dans l'événement ?
Il y a deux écoles, qui peuvent en vrai cohabiter.
L'Event Notification, c'est l'événement minimaliste. Il dit juste "hé, la candidature 42 a changé de statut", et basta. Si le consumer veut en savoir plus, il rappelle la source pour récupérer les détails.
{
"type": "ApplicationUpdated",
"data": { "applicationId": "app_42" }
}
- Avantage : léger, et le consumer a toujours la donnée la plus récente puisqu'il va la chercher au moment où il en a besoin. Moins de place pour stocker l’info.
- Inconvénient : ça recrée un couplage. Vu que le consumer doit appeler pour avoir les détails, et si la source est down, il est coincé. Pour moi on retombe un peu dans les travers qu'on essayait de fuir. De plus lors du debug c’est plus compliqué car on a un historique des events mais sans vrai infos utile dedans.
L'Event-Carried State Transfer, c'est l'inverse : on met tout dans l'événement.
{
"type": "ApplicationUpdated",
"data": {
"applicationId": "app_42",
"candidate": {
"name": "John Doe",
"email": "john.doe@test.com"
},
"previousStatus": "NEW",
"newStatus": "INTERVIEW",
"recruiter": {
"id": "rec_7",
"name": "Jane Doe"
}
}
}
- Avantage : le consumer est totalement autonome. Il a tout ce qu'il faut, il n'a personne à rappeler, et il se fiche que la source soit tombée.
- Inconvénient : les événements sont plus lourds donc plus cher en stockage, et la donnée peut être périmée au moment où elle est consommée (entre l'émission et la consommation, le statut a pu changer).
Quelle école choisir ? Comme souvent : ça dépend. Pour des trucs où la fraîcheur est critique, l'Event Notification a du sens. Pour maximiser le découplage et la résilience, l'Event-Carried State Transfer est souvent préférable. Perso j’ai une grande préférence pour le second. O, évite un max de dépendances et si je lis mon historique d’event je sais exactement ce qu’il s’est passé dans mon système.
Event Sourcing : l'historique comme vérité
Voici le pattern qui change la façon de penser.
Normalement, dans une appli classique, on stocke l'état actuel des choses. La candidature 42 est au statut "HIRED", point. Si vous voulez savoir comment elle en est arrivée là, ben… vous ne pouvez pas, l'info est perdue.
L'Event Sourcing renverse la logique : au lieu de stocker l'état, on stocke la suite des événements qui ont mené à cet état.
ApplicationCreated (statut: NEW)
ApplicationUpdated (statut: INTERVIEW)
ApplicationUpdated (statut: HIRED)
L'état actuel ? On le recalcule en rejouant les événements depuis le début. "HIRED", c'est juste le résultat de toute cette séquence. Un peu comme le fonctionnement de git pour les plus geeks :)
- Avantage : vous avez l'historique complet, "gratuitement". Audit, debug, "mais qui a changé ce statut et quand ?", tout devient possible. Et vous pouvez reconstruire l'état à n'importe quel instant du passé.
- Inconvénient : c'est plus complexe à mettre en œuvre, le stockage grossit, et recalculer l'état à chaque fois peut coûter cher (d'où les snapshots, mais on ne va pas creuser ça ici).
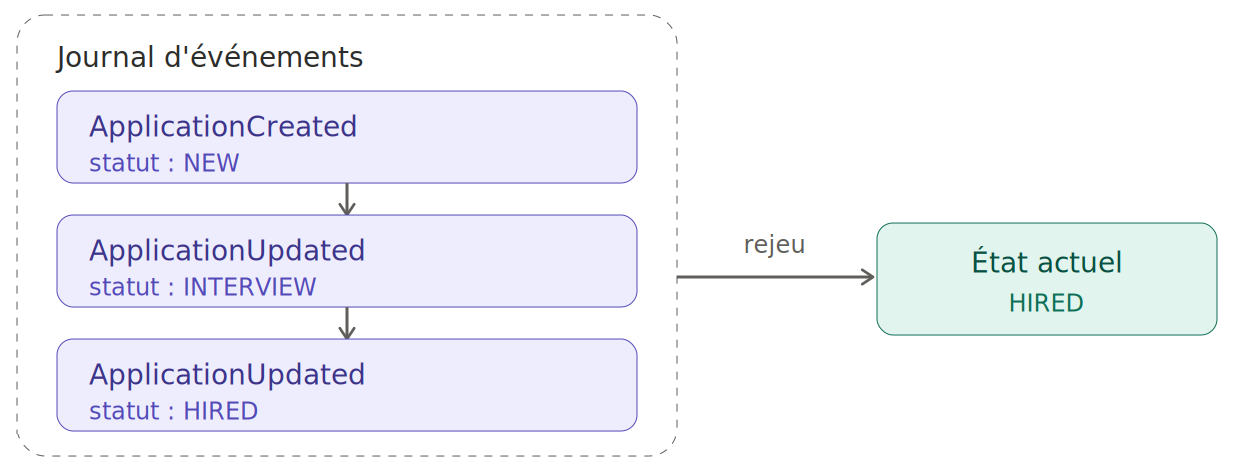
C'est puissant, mais ce n'est pas une obligation pour faire de l'EDA. Beaucoup de systèmes événementiels n'utilisent pas du tout d'Event Sourcing, c’est notre cas. Notre legacy garde sa gestion classique des états, après on peut tricher en regardant notre histoire d’événements.
À garder dans la boîte à outils pour les cas où l'historique a une vraie valeur métier.
CQRS : séparer la lecture de l'écriture
Et oui il est là, c’est notre acronyme dans l’EDA :)
CQRS, pour Command Query Responsibility Segregation. L'idée est assez simple : on sépare le modèle qui écrit les données de celui qui les lit.
Dans une appli classique, le même modèle sert à tout : vous écrivez et vous lisez avec les mêmes structures. CQRS dit : et si on avait un modèle optimisé pour l'écriture, et un (ou plusieurs) modèle(s) optimisé(s) pour la lecture ?
Concrètement : quand un événement modifie l'état (côté écriture), on met à jour en parallèle une ou plusieurs "vues" de lecture, déjà prêtes à être affichées. Le consumer de lecture n'a plus qu'à piocher dans la vue qui l'arrange.
- Avantage : chaque côté est optimisé pour son job. Les lectures sont rapides (les vues sont précalculées), et on peut avoir plusieurs vues différentes des mêmes données selon les besoins.
- Inconvénient : plus de complexité, et il faut accepter une cohérence à terme, entre le moment où on écrit et le moment où la vue de lecture est à jour, il y a un petit délai. Pas idéal si vous avez besoin de lire ce que vous venez d'écrire dans la milliseconde.
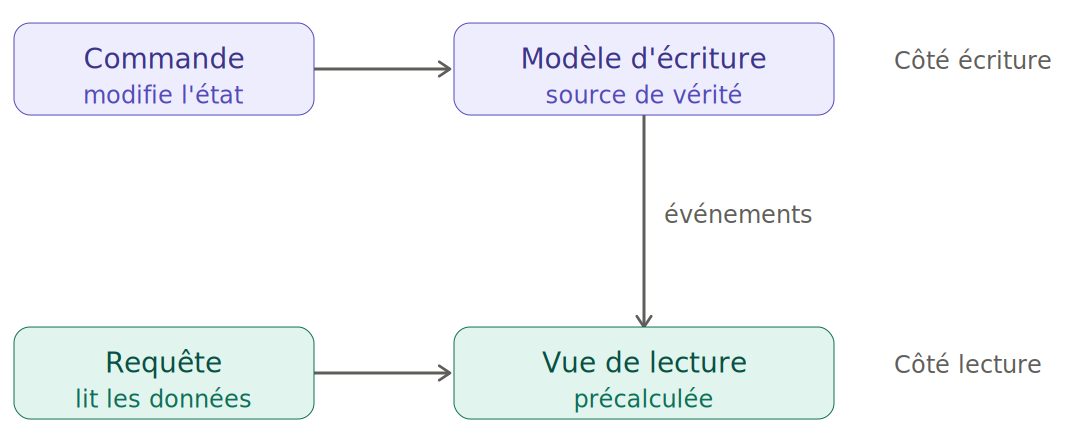
Vous verrez souvent CQRS et Event Sourcing marié, les événements servent à la fois de source de vérité et à mettre à jour les vues. Mais attention, ce ne sont pas des synonymes : on peut faire l'un sans l'autre.
Les à-côtés ultra-importants
Après de la théorie pure et dure, remplie de termes barbares, je vais maintenant casser quelques illusions autour de l’EDA. Quand on débute, on a tendance à supposer plein de choses : que chaque événement n’arrive qu’une fois, qu'ils arrivent dans l'ordre où ils ont été émis, et que tout se passe bien. Eh bien… non pas vraiment ^^
At-most-once, at-least-once, exactly-once
Il existe trois niveaux de garantie de livraison, et il faut bien comprendre ce qu'ils impliquent :
- At-most-once : l'événement est livré zéro ou une fois. S'il se perd en route, tant pis, il restera dans les limbes. Rapide, comme Flash McQueen, mais on peut perdre des événements. Rarement ce qu'on veut.
- At-least-once : l'événement est livré une fois… ou plus. En cas de doute (genre le broker n'a pas reçu la confirmation que le consumer a bien traité), il renvoie l'événement. Donc vous allez recevoir des doublons. C'est le mode le plus courant.
- Exactly-once : le Graal. Chaque événement est livré une fois pile, pas plus pas moins. Sauf que dans un système distribué, c'est extrêmement difficile à garantir réellement, et quand certaines technos le proposent, c'est souvent au prix de compromis et de performances. En pratique, vous le savez ne jamais faire confiance à 100% à un système info.
La conclusion ? Dans la vraie vie, 95% du temps ça va être du at-least-once. Ce qui veut dire qu'il faut partir du principe qu'un événement peut arriver plusieurs fois. Et là, comme par hasard, on va reparler d'idempotence (promi c’est vraiment pour bientôt).
L'ordering : vos événements arrivent dans le désordre
Autre illusion à briser : les événements arrivent obligatoirement dans l'ordre où ils ont été émis.
Imaginez : SmartRecruiters émet coup sur coup ApplicationUpdated (INTERVIEW) puis ApplicationUpdated (HIRED). Logiquement, votre consumer devrait les traiter dans cet ordre. Sauf que selon la techno, le partitionnement, les retries et les chemins réseau, le second peut très bien arriver avant le premier. Et là, votre candidat passe de "HIRED" à "INTERVIEW", ce qui est… gênant.
“Désolé John en fait t’es plus embauché on va refaire des entretiens” voilà un message bien cool à recevoir...
Pourquoi ça arrive ? Parce que garantir l'ordre global dans un système distribué et parallélisé, c'est coûteux. La plupart des brokers ne garantissent l'ordre que dans un périmètre limité (par exemple au sein d'une même partition, pour une même clé).
Comment s'en sortir ? Quelques pistes :
- Utiliser une clé de partitionnement (genre l'
applicationId) pour que tous les événements d'une même candidature passent par le même canal et restent ordonnés entre eux. - Inclure un numéro de séquence ou s'appuyer sur le timestamp pour détecter et s’adapter/ignorer un événement "en retard".
- Concevoir ses consumers pour qu'ils tolèrent le désordre quand c'est possible.
Je n’ai pas de solutions magiques à proposer, mais c’est important de l’avoir dans un coin de la tête.
L'idempotence : votre meilleure amie
Bon, on en a parlé au moins trois fois, il est temps de définir ce que c’est pour de bon.
Un traitement est idempotent si l'exécuter plusieurs fois produit le même résultat que de l'exécuter une seule fois. En clair : si le même événement arrive deux fois, votre système ne doit pas faire le boulot deux fois.
Un exemple parlant : si vous recevez deux fois ApplicationUpdated (HIRED), il ne faut pas envoyer deux mails de félicitations au candidat, ni créer deux tickets Jira. Une fois suffit.
Comment rendre un traitement idempotent ?
- Garder une trace des événements déjà traités (via l'
idde l'événement, vous vous souvenez pourquoi il était important ?). Avant de traiter, on vérifie : "je l'ai déjà vu, celui-là ?" Si oui, on l'ignore. - Concevoir des opérations naturellement idempotentes : "mettre le statut à HIRED" est idempotent (le refaire ne change rien), alors que "incrémenter un compteur" ne l'est pas.
L'idempotence, c'est vraiment LE truc à avoir en tête dès le début. Parce qu'avec de l'at-least-once, ce n'est pas une option, c'est une nécessité. Vous pouvez ignorer plein de subtilités de l'EDA au début, mais pas celle-là.
Quand ça part en vrille : replay et dead letter queues
On a vu que les événements peuvent arriver en double, dans le désordre, ou se perdre. Maintenant, parlons des cas où le traitement lui-même échoue. Parce que ça va arriver : un consumer qui plante, une API tierce indisponible, un bug, un déploiement foireux le vendredi à 17h… La question n'est pas si, mais quand. Voici l'arsenal pour s'en sortir.
Les retries
Et oui même nos événements ont le droit à une seconde chance.
Le premier réflexe quand un traitement échoue : réessayer. Souvent, l'erreur est temporaire (un timeout réseau, une API momentanément surchargée), et un simple nouvel essai suffit.
Sauf qu'il y a une bonne et une mauvaise façon de réessayer.
La mauvaise : retenter immédiatement, encore et encore, en boucle. Si l'API tierce est down, vous aurez beau spam ça ne marchera pas, et accessoirement vous pouvez saturer votre propre système. Pas malin.
La bonne : l'exponential backoff. On attend de plus en plus longtemps entre chaque tentative : 1 seconde, puis 2, puis 4, puis 8… L'idée est de laisser le temps au système d'en face de se remettre.
Mais on ne va pas réessayer à l'infini. Au bout d'un certain nombre de tentatives, il faut se rendre à l'évidence : cet événement ne passera pas. Et là, direction la poubelle.
Les Dead Letter Queues
Une Dead Letter Queue (DLQ), c'est une file d'attente à part où on envoie les événements qui ont échoué malgré tous les retries, notre poubelle. Plutôt que de les perdre dans les limbes ou de bloquer toute la chaîne, on les met de côté pour les traiter plus tard.
L'intérêt est double :
- On ne perd rien. L'événement maudit est stocké, on pourra l'examiner et comprendre ce qui a coincé.
- On ne bloque pas le reste. Sans DLQ, un événement qui n'arrive pas à passer peut coincer toute la file derrière lui (surtout si l'ordre compte). Avec une DLQ, on l'écarte et on continue à traiter les suivants.
Concrètement, une DLQ qui se remplit, c'est votre signal d'alarme : il s'est passé quelque chose qui mérite qu'on aille voir. D'ailleurs, surveiller le remplissage de ses DLQ devrait être un de vos premiers réflexes de monitoring (et tiens, ça tombe bien, c'est un sujet que je compte traiter dans un futur article).
Le replay : rejouer le passé
Une fois qu'on a identifié et corrigé le problème (un bug fixé, l'API tierce de nouveau debout), il faut bien retraiter les événements qui ont échoué (et qui sont dans une DLQ ^^).
C'est le replay : comme à la télé on rejoue des événements déjà émis.
Et le replay, ce n'est pas que pour les ratés. C'est une des belles propriétés de l'EDA, surtout si vos événements sont conservés quelque part. Quelques cas d'usage :
- Correction d’un bug : on rejoue les événements partis en DLQ une fois tout propre.
- Alimenter un nouveau consumer : vous ajoutez un service qui aurait dû réagir aux événements du dernier mois ? Vous rejouez l'historique, et il se met à niveau comme s'il avait toujours été là.
- Reconstruire une vue : en CQRS, si une vue de lecture est corrompue, on la régénère en rejouant les événements.
Mais, parce qu'il y a toujours un mais, le replay a un piège énorme : si vos consumers ne sont pas idempotents, rejouer des événements va refaire toutes les actions associées. Renvoyer les mails, recréer les tickets, redéclencher les notifications… Bref, le replay sans idempotence, c'est la catastrophe assurée.
Et oui, on reparle encore d'idempotence. À ce stade vous avez compris que c'est un peu le personnage principal de cet article.
Les pièges classiques
La théorie c'est bien, mais c'est en se vautrant qu'on apprend vraiment. Voici quelques pièges dans lesquels on peut tomber facilement. Si vous pouvez les éviter, vous gagnerez pas mal de cheveux blancs.
Le producer qui en sait trop
Le piège le plus sournois, parce qu'il annule l'intérêt même de l'EDA.
Ça arrive quand votre producer commence à se soucier de ce que font ses consumers. Par exemple, SmartRecruiters qui émettrait un événement EnvoyerMailDeFelicitations au lieu d'ApplicationUpdated. Vous voyez le souci ? Le producer décide de l'action à faire, au lieu de se contenter de constater un fait.
Le jour où vous voulez aussi créer un ticket, vous êtes obligés de toucher au producer pour qu'il émette aussi CreerTicketJira. Et on retombe pile dans le couplage qu'on voulait fuir.
La règle d'or : un producer constate, il ne commande pas. Il dit "ça s'est passé", pas "fais ça". Ce qu'on fait de l'événement, c'est l'affaire des consumers, et ça ne le regarde pas. Oui je l’ai déjà dit mais y’a des trucs ultra-importants dans la vie, la victoire des Spurs en playoffs et le producer qui s’en fout de ce qu'il se passe après.
L'événement fourre-tout
Autre classique : l'événement qui essaie de tout faire. Un seul type d'événement ApplicationChanged qui sert à la création, la modification de statut, l'ajout d'un commentaire, le rejet, l'archivage…
Résultat : chaque consumer doit éplucher la payload pour comprendre ce qui s'est vraiment passé, avec des if dans tous les sens. "Si c'est une création, alors… sinon si c'est un changement de statut, alors…" Bref, l'enfer à maintenir.
Mieux vaut des événements précis et bien nommés : ApplicationCreated, ApplicationStatusChanged, ApplicationRejected. Chaque consumer s'abonne uniquement à ce qui l'intéresse, et le code reste lisible. Un événement = un fait métier clair.
Oublier l'idempotence (c’est la dernière promis)
Je ne vais pas vous refaire le couplet, vous avez compris. Mais ça reste LE piège numéro un en pratique : tout marche nickel en dev, où chaque événement arrive bien gentiment une seule fois. Et puis ça part en prod, l'at-least-once fait son œuvre, les doublons arrivent, et là c'est le drame. Doubles mails, doublons en base, compteurs qui s'affolent…
Donc pensez idempotence dès le début, si vous ne voulez pas reçevoir 46 fois le même mail.
Le couplage implicite par le schéma
Celui-là est vicieux parce qu'on a l'impression d'être bien découplés alors qu'on ne l'est pas du tout.
Vos producers et consumers ne s'appellent pas directement, super. Mais ils partagent quand même quelque chose : la structure de l'événement. Le jour où vous renommez un champ newStatus en status côté producer, tous les consumers qui lisaient newStatus se cassent la figure d'un coup. Découplés sur le papier, mais reliés par un contrat implicite.
C'est pour ça que le schéma d'un événement est un contrat, à traiter avec le même sérieux qu'une API. On ne change pas un champ à la légère, on versionne (vous vous souvenez du champ version ?).
Une bonne pratique bonus
Aller parce que c’est la fin et que vous avez tenu bon jusque là, un petit bonus qui peut-être intéressant d’appliquer assez tôt, mais d’expérience on peut le faire plus tard aussi :)
Tracez vos événements avec un correlation id
Quand un événement en déclenche un autre, qui en déclenche un autre, à travers trois ou quatre systèmes, retrouver le fil devient vite un cauchemar. La solution : un correlation id, un identifiant qu'on génère au tout début d'une chaîne et qu'on propage dans tous les événements qui en découlent.
Du coup, quand quelque chose foire au bout de la chaîne, vous pouvez filtrer sur ce correlation id et voir d'un coup tout le parcours : "ah, tout est parti de cette candidature, elle a déclenché ça, puis ça, et ça a planté là". Sans ça, vous reconstituez le puzzle à la main dans cinq systèmes différents, et croyez-moi, ce n'est pas une partie de plaisir.
C'est un investissement minime au début pour un confort énorme quand les choses se compliquent. Et elles vont se compliquer.
On a survécu
Voilà, on est arrivés au bout de l'article chiant. Si vous êtes ici, bravo, vous avez désormais de quoi tenir une conversation sérieuse sur l'EDA sans bluffer (enfin, pas trop).
On a vu l'anatomie d'un événement, les grands patterns (Pub/Sub, CQRS, ...), les pièges et pleins d’autres trucs. Et surtout, vous savez maintenant ce qu'est l'idempotence (il fallait bien que je le replace une toute dernière fois).
Mais toute cette théorie, ça reste une partition tant qu'on ne l'a pas mise en musique. Et c'est exactement ce qu'on va faire dans le prochain article.
Au programme : on construit tout ça pour de vrai, en full AWS. EventBridge, Lambda, SQS, DLQ, et toute les briques qui nous ont servi à connecter SmartRecruiters à Mattermost, Jira et nos fameux fichiers Excel. Avec du code, des schémas d'architecture, et nos galères.
Et cette fois-ci il y aura des images, des schémas, bref une BD.
À très vite, et d'ici là, n'oubliez pas d'être idempotents.