Et si vous rendiez vos applications Web Offline [Part #3]
Cette partie complémente la précédente et propose une autre solution d'implémentation des applications web en mode déconnecté, une solution où connecté et déconnecté sont vus de manière transparente par l'utilisateur...
La solution peut être schématisée de la manière suivante :
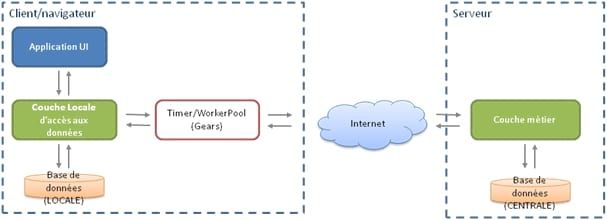
A la différence de la solution explicitée dans la précédente partie [linker sur la partie 2], la présente solution ne demande pas à l'utilisateur de passer " explicitement " en mode déconnecté.
L'application est conçue pour travailler systématiquement en mode déconnecté. Des mécanismes (Timer et workerPool Gears) sont mis en place pour synchroniser - lorsque la connexion Internet le permet - les données en local et les données en central.
Rapatriement des données sur le poste client
Les mécanismes d'initialisation sont identiques à ceux explicités préalablement. Il est nécessaire
- De créer la structure de la base de données
- De rapatrier l'ensemble des données nécessaires à l'exécution des Uses Cases disponibles en mode déconnecté
Appel de services
Cette solution ne nécessite pas de " switcher " entre une couche d'accès aux services distants et une couche d'accès aux services locaux. Une seule couche de service est utilisée par l'IHM : celle des services locaux.
De fait, l'implémentation locale de la couche d'accès aux données peut définir sa propre interface de service.
public class OfflineSampleService implements SampleLocalService {
…
public interface SampleLocalService {
public static class Util {
public static SampleLocalService getInstance() {
return new OfflineSampleService();
}
}
public List getContracts(String clientId);
public Client getClientDetail(String clientId);
public void createWithdrawal(Transfer obj);
}
Cette interface est agnostique à tous les mécanismes asynchrones de GWT (callback et autres...). De plus et contrairement à la solution précédente, le code d'appel de ces services locaux est différent de celui, classique, des appels de services distants : Les callback onsuccess et onfailure sont remplacées par une gestion classique par exception
…
try {
SampleLocalService.Util.getInstance().createWithdrawal(transfer);
…
} catch (BusinessException e) {
Log.error("exception", e);
//display message to user
}
…
Synchronisation des données du client vers le serveur central
L'ensemble des synchronisations des données est réalisé de manière transparente pour l'utilisateur. Autrement dit, les solutions proposées par Gears - à savoir les WorkerPool et surtout les Timer - ont été utilisées à la fois pour rapatrier les données de la base centrale vers la base locale et descendre ces données locales vers le serveur central.
Les Timer introduits par Gears fonctionnent comme tous les timers : ils exécutent une méthode - dans ce cas run() - dans un interval de temps choisi.
Dans notre exemple, toutes les 10 secondes, les données mises à jour côté client, ie. les virements, sont redescendues vers le serveur central
Timer timer = new Timer() {
public void run() {
…
//normalement masque dans un service local
rs = db.execute("select * from transfer",
new String[] {});
List returnedObjects = new ArrayList();
for (int i = 0; rs.isValidRow(); i++, rs.next()) {
Transfer obj = new Transfer();
obj.setDebitAccountNumber(rs.getFieldAsString(1));
obj.setCreditAccountNumber(rs.getFieldAsString(2));
…
returnedObjects.add(obj);
}
AsyncCallback callback = new AsyncCallback() {
public void onFailure(Throwable arg0) {
Log.error("sync to server error", arg0);
//display offline message to user
}
public void onSuccess(Object arg0) {
Log.info("sync to server ok");
}
};
SampleRemoteServiceAsync service = SampleRemoteService.Util.getInstance();
service.createWithdrawals(returnedObjects, callback);
}
};
timer.scheduleRepeating(10000);
…
Dans le cas où les services distants ne sont pas accessibles, une exception est levée et traitée via la callback onFailure(). L'utilisateur se voit alors simplement informé que son application est en mode déconnecté.
Comment savoir quelles données synchroniser ?
Dans notre exemple précédent, la question ne s'était pas posée car les tables étaient nettoyées lors de la synchronisation initiale. On pouvait donc considérer que tous les virements présents dans la base locale avaient été créés pendant l'utilisation en mode déconnecté et qu'il était donc nécessaire de tous les synchroniser.
Ce modèle n'est pas applicable dans la solution que nous cherchons à implémenter ici. En effet, toutes les données sont présentes au niveau de la base locale. De fait, il faut distinguer celles qui devront être redescendues au serveur central de celles qui ont déjà été synchronisées...
Une solution propre serait d'avoir une table de journalisation des évènements de création et modification. Cette table référencerait l'ensemble des objets (type, identifiant...) qu'il est nécessaire de redescendre sur le serveur central. Une fois la synchronisation réalisée, les enregistrements présents dans cette table pourraient être supprimés, physiquement ou logiquement.
Au regard de la simplicité de notre exemple (seule la table virement doit être redescendue vers le serveur central), un flag a été rajouté sur la table virement. Ce flag distingue les enregistrements à synchroniser des autres. A noter que cette solution de flag n'est pas généralisable : trop intrusive sur la structure des tables.
Ce flag est mis à jour si la redescente des données s'est effectuée sans problème :
Timer timer = new Timer() {
public void run() {
public void onSuccess(Object arg0) {
…
String query = "update transfer set isMerged = 'true' where id = ?";
try {
GearsHelper.getInstance().execute(query,
new String[] { id });
}
};
…
SampleRemoteServiceAsync service = SampleRemoteService.Util.getInstance();
service.createWithdrawal(returnedObjects, callback);
Feedback utilisateur : comment informer l'utilisateur du mode connecté/déconnecté dans lequel il travaille ?
Même si l'application se comporte de manière identique en mode connecté ou déconnecté, il reste important d'informer l'utilisateur du mode dans lequel il travaille. Pour ce faire, un simple service de type ping() appelé depuis un Timer a été mis en place. En cas d'échec de l'appel, un indicateur visuel affiche le style associé au mode déconnecté. Dans les autres cas, ce même indicateur affiche le style associé au mode connecté.
Timer iconTimer = new Timer() {
public void run() {
AsyncCallback callback = new AsyncCallback() {
public void onFailure(Throwable arg0) {
offlineButton.setStyleName("offline");
}
public void onSuccess(Object arg0) {
offlineButton.setStyleName("online");
}
};
SampleRemoteServiceAsync service = SampleRemoteService.Util
.getInstance();
service.ping(callback);
}
};
Conclusions
Au travers de cette série d'articles, deux solutions d'implémentation d'applications web déconnectées ont été présentées mais indépendamment de ces solutions, les enjeux d'usabilité, d'architecture ou de développement sont identiques.
L'usabilité tout d'abord avec des questionnements à avoir autour de l'offre de tout ou partie des fonctionnalités en mode déconnecté mais surtout autour de la gestion des erreurs de synchronisation - comment rendre compte à l'utilsateur de ces erreurs (le feedback) ? comment lui permettre de corriger ces erreurs (le contrôle de l'application) ? - .
Le développement ensuite : beaucoup de nos désormais irremplaçables frameworks et outils sont à porter sur la plateforme Gears. Cette dernière ne fournit pas de solution de mapping objet-relationnel et même s'il existe quelques initiatives personnelles visant à combler ce manque, il faudra attendre avant qu'elles atteignent le niveau de maturité d'un Hibernate ? Alors que les développements serveur en Java ne peuvent (quasiment) plus se faire sans Spring, Gears ne fournit aucune solution similaire visant à structurer le code client et les accès à la base de données locale. Peut-on envisager que GWT et Gears propose l'intégration native avec Guice ?
Concernant l'architecture enfin. La constitution de la base de données - et les problématiques de création mais surtout de mise à jour de la structure - reste un point de vigilance. La synchronisation des données restera quant à elle une problématique spécifique à chaque contexte applicatif - notamment au travers des mécanismes de " merge " qu'il sera, ou pas, nécessaire de mettre en oeuvre - mais il subsiste deux limitations importantes : les problèmes de performances liés à volumétrie de la base locale et l'absence d'implémentation native par Gears d'un mécanisme de " journal " - stockant l'ensemble des objets modifiés, créés, supprimés... -. Concernant la mutualisation des règles de gestion, que dire...L'émulation du JRE fournit par le compilateur GWT est trop limité pour espérer à ce jour implémenter l'intégralité des règles en Java - quitte à ce que GWT les compile en Javascript... - . Dur d'imaginer devoir implémenter l'ensemble des règles de gestion en double et dans deux langages.
Quoiqu'il en soit, Gears est déjà et avec succès utilisé sur des applications offrant une faible complexité métier : Google Apps, Google Reader, Mail... Cela reste donc une affaire à suivre de près mais ces solutions " déconnectées " ne doivent pas complètement omettre l'évolution de l'internet mobile qui nous offre la possibilité de se connecter presque n'importe où...restera à construire des logicielles tolérants aux pertes de connexions réseaux...