Et si vous rendiez vos applications Web Offline [Part #2]
La précédente partie a présenté - vue d'avion - les principales problématiques des applications déconnectées et une des technologies d'implémentation : Google Gears.
Cette partie expliquera comment rendre " offline " une application GWT en respectant un premier pattern : " déconnexion explicite ".
Le " pattern " est simple :
du point de vue de l'usabilité, l'utilisateur " demande " explicitement - ie. via une action sur un bouton ou autre... - à se déconnecter du " système central ". De même pour la reconnexion qui se fait via une action explicite.
du point de vue technique, les données sont rapatriées sur le poste client (en local donc) lors du click de l'utilisateur. Ces mêmes données (enfin pas exactement les mêmes puisqu'elles auront été modifiées entre temps...) seront redescendues vers le serveur (en central) lors de l'action de l'utilisateur
La vue haut niveau donne le schéma suivant :
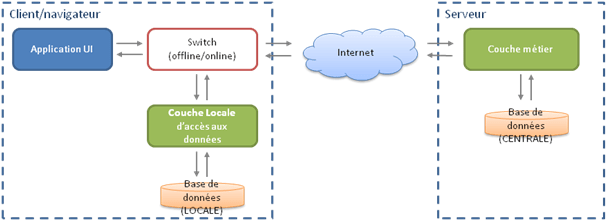
Reste à mettre en oeuvre l'ensemble en réalisant les grandes étapes suivantes
- Synchronisation des ressources HTML, CSS, images, javascript..
- Création de la base de données
- Synchronisation des données du " serveur central " vers le client
- Gestion des appels de services (en fait le switch offline/online sur le schéma précédent) et mutualisation des règles métier
- Synchronisation des données du client vers le " serveur central "
Synchronisation des différentes ressources HTML, CSS, images, javascript
Gears met à disposition deux objets :
- LocalServer que l'on peut voir comme un cache d'URL qui intercepterait les appels HTTP afin de servir les ressources à partir d'un ResourceStore.
- Le ResourceStore justement : Un espace de stockage des ressources. Il en existe deux familles. Dans un cas, les ressources sont automatiquement téléchargées sur la base d'un fichier de configuration qui les liste (ManagedResourceStore). Dans un autre cas, le téléchargement est fait manuellement en spécifiant dans le code les ressources http.
Gears sert systématiquement les ressources à partir du LocalServer dès que celui-cii est activé. Ce qui se traduit simplement au niveau du code par :
store.setEnabled(<strong>true</strong>);
Concernant le ManagedResourceStore, ce dernier utilise un fichier qui liste l'ensemble des ressources (HTML, images, JS...) à rapatrier sur le poste client.
Reste que l'application utilise GWT et qu'un problème se présente : comment connaitre à l'avance le nom des ressources puisque celles-ci sont générées à la compilation, et que de plus, ces dernières sont loin d'avoir des noms très " human-compliant "...Heureusement gwt-google-apis (dans sa version de développement au moment où cet article est écrit Cf. http://code.google.com/p/gwt-google-apis/issues/detail?id=6 ) propose de générer ce fichier à la compilation et sur la base des ressources HTML et Javascript générées par la compilation GWT...génial non ? Presque, parce que du coup, il est nécessaire d'utiliser la version 1.5 de GWT, à ce jour en release candidate...
Concernant la mise en oeuvre de cette solution :
- Ajouter l'héritage suivant dans le fichier module.gwt.xml de votre application
<module>
...
<!-- pour la l’utilisation de gwt-google-apis -->
<inherits name='com.google.gwt.gears.Gears' />
<inherits name='com.google.gwt.gears.Offline' />
</module>
Rajouter le ficher suivant " générique " dans le répertoire public de votre application (GearsManifest.json)
// This is an example of a custom manifest {"betaManifestVersion" : 1, "version" : "__VERSION__", "entries" : [ // The following line will be automatically expanded __ENTRIES__, // ^--- This comma is necessary because we have entries below // Make the "directory" url redirect to the host page { "url" : ".", "redirect" : "Application.html" } ] }A la compilation, le fichier suivant est généré (c'est un extrait...) :
{"betaManifestVersion" : 1, "version" : "D801D0B2E74616C157BCFE6DF43C1CF0", "entries" : [ // The following line will be automatically expanded { "url" : "066A5C064BBE8499808C9CE00AF44CEA.cache.html" }, … { "url" : "Application.css" }, { "url" : "Application.html" },… { "url" : "octo.gif" }, { "url" : "org.octo.Application.nocache.js" }, …Dès lors, les ressources nécessaires à l'application seront servies par le LocalServer. Reste maintenant à gérer les données.
Création de la base de données
Le préalable à la récupération des données est simplement la création du schéma.
La première idée serait de recopier telle quelle l'intégralité du schéma proposé sur le serveur central sauf que comme on l'abordera dans la section suivante : il n'est pas nécessaire de rapatrier l'intégralité des données. Voire même, il est certainement très malin de ne rapatrier que les données strictement utiles à l'utilisateur pour réaliser uniquement l'ensemble des cas d'utilisation disponibles en déconnecté...
Typiquement dans notre exemple, il est clairement inutile de rapatrier l'ensemble des comptes de tous les clients et utilisateurs. En plus d'évidents problèmes de performance, on peut affirmer que l'application ne sera utilisée en mode déconnecté à l'instant t que par un seul utilisateur, seules les informations des comptes liées à l'utilisateur en question sont donc pertinentes.
" Oui mais c'est une problématique de données !" me direz-vous. Sauf que pour le coup, la structure de la table ACCOUNT s'en trouve modifiée : pas besoin de gérer la relation entre un compte et son titulaire. Tous les comptes présents dans la table sont " déjà " ceux du titulaire...
Cette parenthèse close, la base de données sera créée lorsque l'utilisateur choisira de passer en " mode déconnecté ".
private static final String DB_ACCOUNT_CREATE = "create table ACCOUNT (" + "id INTEGER primary key, " + "number text not null, type text not null, balance text not null, " + "debitCardBalance text null)"; … db = new Database("GearsSample-Part2"); … db.execute(DB_ ACCOUNT_CREATE);- La base de données est instanciée avec un nom logique. Si cette base existe déjà, elle n'est pas recréée.
- La structure de la base de données est créée via des requêtes SQL. A l'initialisation, pas de souci. Mais quid des updates...
- Quelle stratégie mettre en place lorsqu'il est nécessaire de mettre à jour le schéma côté client ? plutôt un mode " drop/create " ou plus incrémental à base " d'alter table ". J'imagine que cela dépend du type de modification réalisé sur la structure. L'ajout d'un champ " nullable " se gèrera très simplement avec un " alter table ". L'ajout de colonnes jouant le rôle de clé étrangère me parait plus simple à gérer avec un " drop/create "...
- Et dans le cas de mises à jour incrémentale, comment gérer les versions de base et savoir quelle est la version en cours sur le poste client ? comment en déduire la liste des altérations à réaliser sur le schéma (car cette dernière sera différente suivant que l'on upgrade depuis la dernière version ou que l'on upgrade depuis 2 ou 3 version antérieure...)? La première idée qui me vient à l'esprit serait d'utiliser une table technique contenant l'information de version du schéma à ce moment utilisé. L'écart entre ce numéro de version et le numéro de version courant permettrait d'en déduire la liste des modifications à réaliser...
Deux points à noter:
Synchronisation des données du " serveur central " vers le client...
Ce point a été introduit précédemment et consiste à répondre à la question : quelles données synchroniser ? Synchronise-t-on l'intégralité de la base de données " centrale " (hum sympa les performances...) ou juste une partie (mais laquelle ?) ? Voilà quelques pistes à mon sens utiles :
- Ne synchroniser que les données utiles pour les uses cases disponibles en mode déconnecté. Pas si évident que cela a priori.
- Ne synchroniser que les données auxquelles l'utilisateur à accès. En effet et dans notre exemple, inutile de récupérer l'intégralité de la table ACCOUNT. Seuls les comptes de l'utilisateur sont intéressants pour l'application. Cela permet de plus de s'abstraire de nouvelles problématiques d'habilitation sur les données.
Dans notre exemple, il n'a pas été nécessaire d'implémenter des services de récupération spécifiques: les services métier disponibles nous permettent de récupérer l'ensemble des données utiles: le client, ses comptes...
Un autre enjeu complexe à adresser lors de cette synchronisation des données : les problèmes de duplication des données...En effet, lors du développement de notre exemple, si l'utilisateur passait en mode déconnecté deux fois consécutives, la base de données locale était chargée deux fois, créant ainsi des doublons : deux fois le même utilisateurs, 2 fois les mêmes N comptes...
Deux approches et un postulat permettent de régler ce problème.
Concernant le postulat, il faut s'imposer qu'aucune nouvelle mise à jour des données ne peut être faite du serveur central vers le client, tant que l'utilisateur reste en mode déconnecté. Autrement dit, la récupération des données est faite au moment où l'utilisateur passe explicitement en mode déconnecté. La redescente des données vers le serveur central ne se fera que lorsque l'utilisateur passera explicitement du mode déconnecté au mode connecté. Cela permet d'éviter d'avoir à gérer les cas (et les problématiques de merge de données) où une mise à jour est faite sur la base de données local et où l'utilisateur demande ensuite la récupération des données du serveur central.
Concernant les approches, la première consiste à réaliser un " delete all/insert all " : à l'instar du schéma de la base, l'ensemble des données est supprimé avant l'insertion des nouvelles. La seconde consiste à gérer " au cas par cas " c'est-à-dire de vérifier si l'enregistrement est déjà présent en base, puis de réaliser une insertion ou une mise à jour suivant le cas...bonjour le casse tête.
Dans notre exemple, la première approche a été privilégiée et la synchronisation est implémentée comme suit : les données sont récupérées au niveau du serveur central par appel de service, les tables locales sont purgées avant l'insertion des données :
AsyncCallback callback = new AsyncCallback() { … public void onSuccess(Object arg0) { Client client = (Client) arg0; try { db.execute("delete from CLIENT"); db.execute("insert into CLIENT values (NULL,?,?,?,?,?)", new String[] { client.getFirstName(), client.getLastName(),… … SampleRemoteService.Util.getInstance().getClientDetail(clientId, callback);Gestion des appels de service
La question est la suivante: comment appeler des services " offline " (appelés " couche locale d'accès aux données " dans le schéma précédent), ie. des services appelant la base de données locale sans impacter l'ensemble du code IHM...
En préalable, définissons l'implémentation " offline " des services existant à l'origine :
public class OfflineSampleService implements SampleRemoteService, SampleRemoteServiceAsync { … public Client getClientDetail(String clientId) { ResultSet rs = null; try { rs = db.execute("select * from CLIENT", new String[] {}); //retourne un seul élément mais le code devrait être plus défensif if (rs.isValidRow()) { Client client = new Client(); client.setFirstName(rs.getFieldAsString(1)); client.setLastName(rs.getFieldAsString(2)); … return client; } return null; … } }On note :
- que cette classe implémente les deux interfaces nécessaires à GWT-RPC
- que la callback est gérée manuellement sur la gestion des exceptions
- que les services réalisent les accès à la base de données locale
Pour accélérer mes développements et générer l'ensemble des interfaces et configuration des services GWT-RPC, j'utilise Cypal Studio...La création d'un service GWT-RPC via ce plugin eclipse génère, sur l'interface métier, une classe Util qui " wrappe " simplement la tuyauterie classique d'appel au service GWT, à savoir :
SampleRemoteServiceAsync instance = (SampleRemoteServiceAsync) GWT .create(SampleRemoteService.class); ServiceDefTarget target = (ServiceDefTarget) instance; target.setServiceEntryPoint(GWT.getModuleBaseURL() + SERVICE_URI);De fait, il semble intéressant de modifier cette classe Util pour gérer l'aspect " offline " et le switch entre l'implémentation distante - celle disponible sur le serveur - et l'implémentation locale - celle interagissant avec la base de données Gears.
Cette classe " Util " doit de plus être modifiée pour gérer le " switch online/offline" :
if(!Context.getInstance().isOffline()){ SampleRemoteServiceAsync instance = (SampleRemoteServiceAsync) GWT .create(SampleRemoteService.class); ServiceDefTarget target = (ServiceDefTarget) instance; target.setServiceEntryPoint(GWT.getModuleBaseURL() + SERVICE_URI); return instance; } else { return new OfflineSampleService(); }(*) L'application utilise un objet de type " Context " permettant de conserver certaines informations, dont un Boolean indiquant l'utilisation connectée ou déconnectée de l'application.
L'implémentation " offline " ou " online " du service est donc appelée sans que le code d'appel soit impacté. Il reste le suivant :
SampleRemoteService.Util.getInstance().getClientDetail(Context.getInstance().getCurrentClientId(), callback);Mutualisation des règles métiers et création d'un virement...
L'application propose un service simple permettant de créer un virement, d'un compte vers un autre. Ce service est régi par une règle métier simple : le virement n'est accepté que si le montant viré est inférieur au solde du compte débiteur.
Première option pour éviter d'avoir à mutualiser, rendre indisponible la fonctionnalité de virement. C'est certainement une option plus qu'intéressante dans certains cas où mutualisation des règles métier et synchronisation des données risqueraient d'être trop complexes. C'est ce que fait GoogleApps : il est impossible de créer un nouveau document lorsque vous êtes en mode déconnecté.
Seconde option, stocker la demande de virement en local et l'envoyer vers le serveur centrale lors de la reconnexion. Dans notre exemple rien de plus simple.
Une première implémentation du service réalise l'insertion en base
String query = "insert into transfer values (null,?,?,?,?)"; GearsHelper.getInstance().execute(query, new String[] { obj.getDebitAccountNumber(), obj.getCreditAccountNumber(),…});Et la règle métier ? Aujourd'hui cette dernière est bien encapsulée dans ma couche métier, au fin fond de mon serveur d'application...alors comment faire ? Il semble nécessaire de créer un composant externe regroupant
les règles métier et ayant les caractéristiques suivantes :
- proposer une API avec les objets à valider en paramètres et une valeur de retour (par exemple liste d'erreur ou simple valeur booléenne)
- n'avoir aucune adhérence à une quelconque couche d'accès aux données...les dépendances seront " injectées "
Dans notre exemple, la règle métier a été externalisée dans un objet Java. La version plus complète serait d'avoir un composant, un jar référencé dans le projet (exactement comme pour les composants graphiques...)
public class TransferRules { public boolean checkRules(Account debitAccount, double transferAmount) { if (debitAccount.getBalance() < transferAmount) { throw new RuntimeException("not enough balance"); } return true; } }Ce composant est appelé de manière identique côté client et côté serveur. En effet, pour le client, le code est le suivant et sera compilé en Javascript
try { // check le solde TransferRules rules = new TransferRules(); rules.checkRules(this.getAccount(obj .getDebitAccountNumber()), obj.getDebitAmount()); // String query = "insert into transfer values (null,?,?,?,?)";Et pour le serveur, le code est le suivant et sera compilé en bytecode Java
ccount debitAccount = this.getAccount(obj.getDebitAccountNumber()); TransferRules rules = new TransferRules(); rules.checkRules(debitAccount, obj.getDebitAmount()); FileOutputStream storeFile = null;Il existe malgré tout (au moins) deux limitations à cette manière de mutualiser le code métier. La première et pas des moindre : GWT n’émule qu’une partie du JRE. Autrement dit et pour faire simple, seuls les packages java.lang et java.util sont utilisables dans la partie cliente d’une application GWT. Du coup, impossible d’utiliser des objets de type BigDecimal…et écrire des règles de gestion sans ces objets risque de vite devenir complexe. La seconde est que cela complexifie le code.
Une alternative serait de ne mutualiser que certaines règles de gestion, les plus importantes et d'en vérifier l'intégralité lors de la reconnexion au serveur central. Du coup, l'enjeu technique devient un enjeu métier - quelles sont les règles de gestion indispensables ? - et un enjeu d'usabilité - comment informer, lors de la reconnexion, l'utilisateur des actions réalisées en mode déconnecté et qui ne respectent pas l'ensemble des règles de gestion et comment lui donner la liberté de " réparer " cela ? - .
Il existe malgré tout (au moins) deux limitations à cette manière de mutualiser le code métier. La première et pas des moindre : GWT n'émule qu'une partie du JRE. Autrement dit et pour faire simple, seuls les packages java.lang et java.util sont utilisables dans la partie cliente d'une application GWT. Du coup, impossible d'utiliser des objets de type BigDecimal...et écrire des règles de gestion sans ces objets risque de vite devenir complexe. La seconde est que cela complexifie le code.
Synchronisation des données du client vers le " serveur central "
" On n'a jamais été aussi près " aurait un guide du désert marocain...Et c'est bien vrai : il ne reste " plus " qu'à redescendre les données de la base locale vers la base centrale. Le lecteur aguerri aura bien entendu noté le " plus " entre guillemets...
De même que l'utilisateur a rapatrié les données en local lors de la déconnexion, ces dernières seront redescendues vers le serveur sur la reconnexion explicite de ce dernier. Le bon côté de cette synchronisation, c'est que seules les données mises à jour ou créées côté client ont besoin d'être redescendues sur le système central. Reste à les identifier et pour cela, deux options :
- la première consiste à créer une table jouant le rôle de journal. Ce journal est utilisé lors de la synchronisation pour savoir quelles sont les données qu'il est nécessaire de redescendre sur le serveur " central "
- la seconde, plus simple mais moins robuste, repose sur l'hypothèse que tables contenant les données créées en mode déconnecté sont systématiquement purgées au moment du passage du mode connecté au mode déconnecté. Ainsi, l'intégralité de ces tables peut être redescendue dans le système " central "
Dans notre cas, seuls les objets " virements " sont créés et la seconde option est tout à fait applicable. Cela a été implémenté de la façon suivante lors du " click " de l'utilisateur :
offlineButton.addClickListener(new ClickListener() { public void onClick(Widget arg0) { if (!Context.getInstance().isOffline()) { … } else { rs = db.execute("select * from transfer", new String[] {}); List returnedObjects = new ArrayList(); for (int i = 0; rs.isValidRow(); i++, rs.next()) { Transfer obj = new Transfer(); obj.setDebitAccountNumber(rs.getFieldAsString(1)); … returnedObjects.add(obj); } AsyncCallback callback = new AsyncCallback() { … public void onSuccess(Object arg0) {…} }; Context.getInstance().setOffline(false); service.createWithdrawals(returnedObjects, callback); offlineButton.setStyleName("online");Dans notre exemple, il n'y a pas de risque d'accès concurrents sur les données de demande de virements. La synchronisation reste donc simple et ne demande pas de prévoir des mécanismes de " merge " au niveau du système central : les données sont récupérées de la base locale puis poussées au système central via un appel de service ensembliste createWithdrawals().
Synchronisation des données et gestion des erreurs
Là où c'est plus drôle : imaginons le cas métier où un ordre de débit est passé entre le moment où le client s'est déconnecté et le moment où il s'est reconnecté. Il est fort possible que son solde soit plus faible et il est tout à fait pensable que notre règle de gestion ne soit plus valide au moment de la redescente d'information vers la base centrale ! Que faire ?
D'autres cas d'erreurs peuvent également survenir lors de la synchronisation des données, aussi bien dans le sens serveur vers client que dans le sens client vers serveur. Une insertion dans la base de données locale peut être refusée...Que faire ? Doit-on tout annuler si l'insertion d'une donnée échoue ? Doit-on utiliser une unité de mise à jour plus fine avec le problème d'avoir des données incohérentes (certaines mises à jour d'autres pas...)
A ces réelles questions, " no silver bullet " malheureusement. La gestion de ces cas d'erreurs sera contextuelle - certainement qu'une unité de mise à jour par bloc fonctionnel est la meilleure solution. Encore faut il pouvoir déterminer et isoler ces blocs - mais également et surtout d'usabilité - comment informer l'utilisateur de ces erreurs et lui laisser la liberté et le pouvoir de les corriger ? -