Et si les métriques de monitoring de ML devenaient fonctionnalités ?
Les équipes développant des applications de Data Science investissent beaucoup d’énergie pour identifier et implémenter des métriques de monitoring pertinentes. Nous pensons qu’il est possible de capitaliser sur ce travail en proposant des fonctionnalités supplémentaires à nos utilisateurs afin de renforcer l’impact de nos applications.
Le monitoring s’appuie notamment sur le calcul de métriques à des fins de supervisions; c'est-à-dire mesurer l’état de service et détecter des problèmes. Les métriques calculées peuvent être plus ou moins haut niveau, plus ou moins éloignées du matériel:
- Bas niveau : CPU, RAM, etc.
- Haut niveau : Le nombre d'utilisateurs, le temps moyen passé sur l’application, le chiffre d'affaires, etc.
Les métriques haut niveau ont souvent la qualité d’être plus actionable mais elles sont souvent plus coûteuse à mettre en place et la boucle de feedback est plus lente.
En Machine Learning (ML), nous sommes amenés à calculer encore plus de métriques haut niveau (performance du modèle, métriques métiers, …) qu’en logiciel sans ML
Nous faisons dans cet article l'apologie d’une réutilisation des métriques de monitoring sous forme de fonctionnalité de l’application pour renforcer la confiance, améliorer la prise de décision, améliorer la satisfaction, améliorer le collective ownership autour du système.
Ce que l’on peut monitorer en Machine Learning
Comme nous venons de le voir, il existe plusieurs niveaux de monitoring répondant chacun à des besoins et ayant des coûts de mise en place différents. En Machine Learning, les éléments à monitorer sont plus nombreux qu’en logiciel n’incluant pas de ML. En plus de tous les éléments classiques à monitorer, nous en ajoutons deux à notre système : la donnée et le modèle. Ces deux briques ne sont pas figées dans le temps, elles sont vouées à évoluer régulièrement ; il convient donc de les monitorer.
Monitorer de la donnée et des modèles se fait à différents niveaux que nous proposons de résumer par la pyramide ci-dessous :
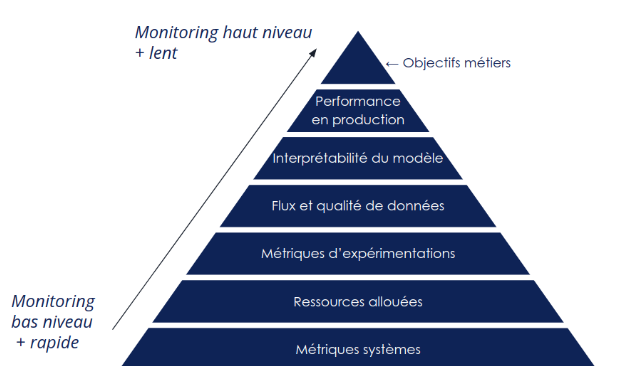
Figure 1 : Pyramide du monitoring
Au plus bas niveau, nous retrouvons les métriques systèmes, c’est classiquement ce que l’on monitore le plus en software engineering. Et pour cause, cela représente l’état de santé de notre application. Le contrôle de l'état de notre CPU, GPU, RAM… est primordial, tous ces éléments sont essentiels au fonctionnement de toutes les autres briques du système. En cas de saturation de l’un d’eux, l’ensemble du système peut être impacté (ex : API d’exposition de modèles down → plus de prédictions possibles). Ce monitoring de métriques peut typiquement être exposé sur un dashboard Grafana.
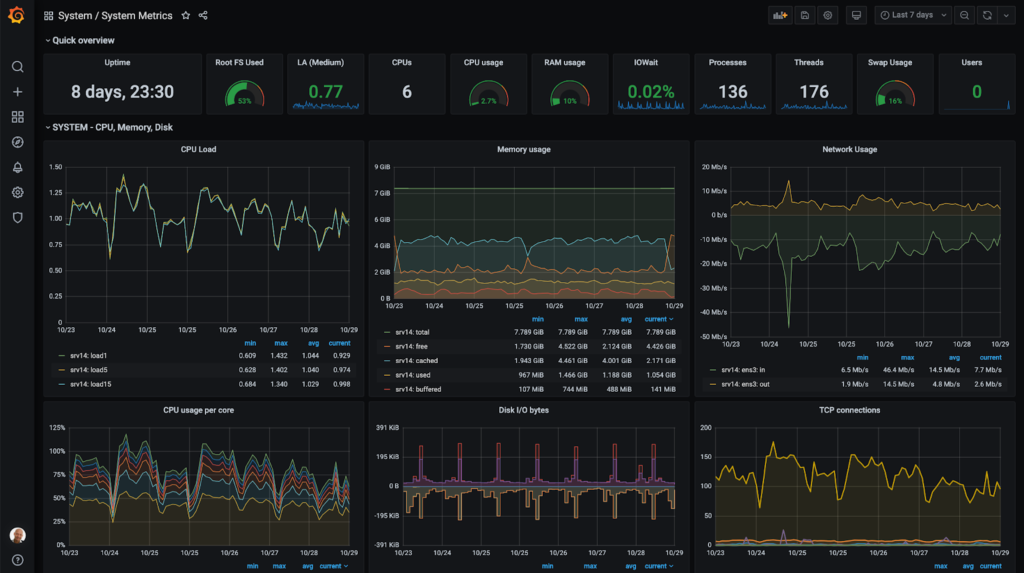
Figure 2 : Dashboard Grafana
Vient ensuite le monitoring des ressources, en Machine Learning, la puissance de calcul nécessaire à l'entraînement des modèles ainsi que l’espace de stockage pour héberger la donnée génèrent des coûts importants : il convient donc de les comprendre et de les visualiser afin de les optimiser. Deux types de coûts entrent en jeu :
- Des coûts financiers,
- Des coûts environnementaux qui sont et qui deviendront de plus en plus un enjeu important (Impact de l'IA sur l'environnement : démêler le vrai du faux).
Dans le cas de l’utilisation d’un Cloud provider, les coûts financiers peuvent être visualisés directement dans la console de celui-ci.
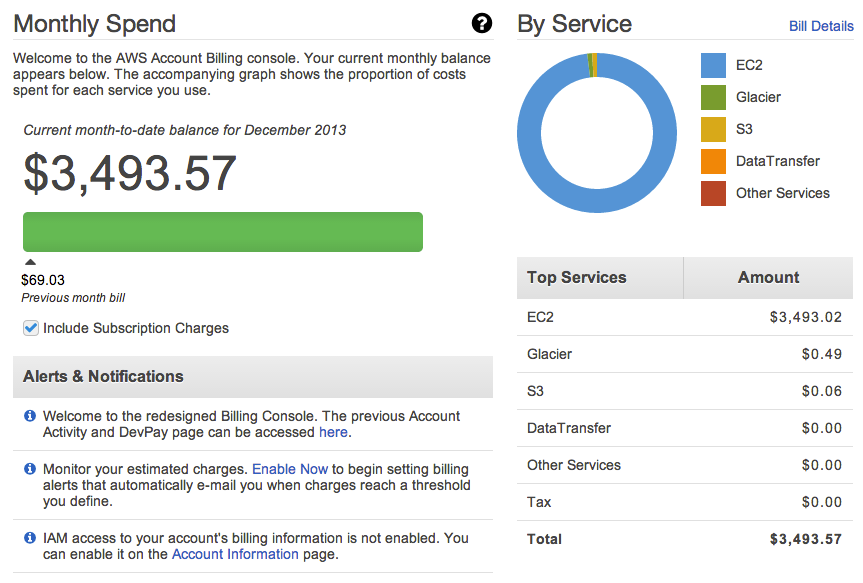
Figure 3 : Visualisation des dépenses mensuelles sur AWS
Lors de la conception d’un modèle de Machine Learning, plusieurs modèles sont entraînés avec chacun leurs spécificités ainsi qu’un paramétrage différent. À l'issue de l’entraînement de chacun d’entre eux, on récupère des métriques d’expérimentations sur le modèle entraîné. Ces métriques vont nous permettre de choisir entre tous les modèles entraînés lequel convient le plus à nos besoins et donc lequel nous allons exposer en production. Afin de monitorer ces métriques d’expérimentations, nous pouvons tout simplement noter dans un tableur, pour chaque modèle, ses métriques et ainsi faire notre choix. Pour un projet plus conséquent, nous vous conseillons tout de même d’utiliser un outil tel que MLFlow qui permet des fonctionnalités poussées sur le versionning de modèle ainsi que la gestion de son cycle de vie.
Les données en entrée du modèle peuvent changer dans le temps au gré de l’évolution des usages. Par exemple, pour un modèle de classification de déchets entraîné à reconnaître si un déchet est recyclable ou non, la nature des déchets traités évolue avec le temps. Nous avons ainsi un flux de données qui viendra alimenter notre dataset. Cependant, celles-ci peuvent être très différentes des données utilisées lors de l'entraînement et ainsi impacter fortement les performances de notre système. Nous devons donc monitorer le flux et la qualité de ces nouvelles données.
Pour cela, de nombreux outils plus ou moins complets et complexes existent parmi lesquels : Tensor Flow Data Validation, Prometheus, Great expectations.
Avoir un modèle performant est une chose importante, mais le comprendre en est une autre. Ainsi, l’interprétabilité du modèle ne doit pas être négligée : elle permet d’avoir confiance dans les prédictions du modèle et de prendre des décisions éclairées.
Le fait de considérer cette partie comme du monitoring peut être sujet à débat, mais nous avons quand même décidé de l’intégrer à cette pyramide, car c’est un indicateur calculé sur le système de prédiction.
L’interprétabilité est rarement exposée autre part que dans le notebook du Data Scientist même si cela peut arriver, notamment en computer vision, ou les zones d’interprétabilitées peuvent être mises en relief sur l’image.
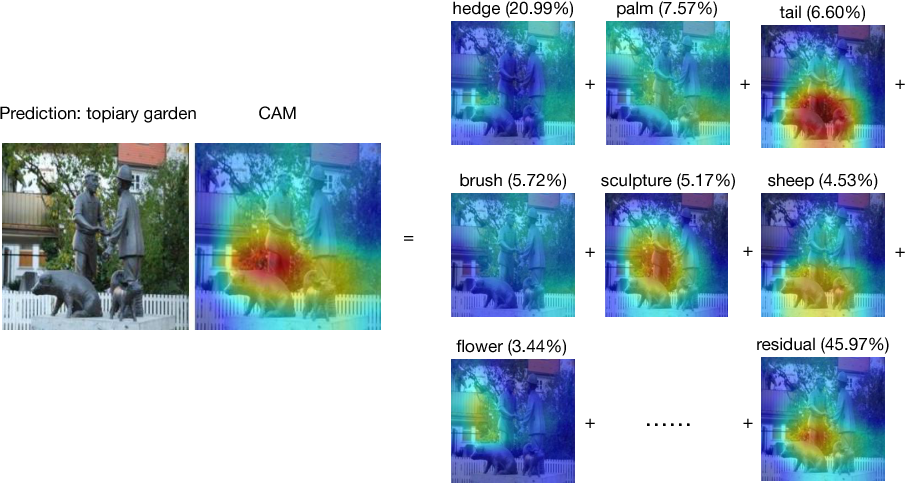
Figure 4 : Zone d’interprétabilité en fonction d’une prédiction
On a vu au milieu de cette pyramide les métriques liées à l'entraînement du modèle. Or, une fois notre modèle en production, ses performances peuvent être bien différentes (notamment dues à un manque de réalisme dans les données d’entraînement). Si les performances du modèle en production sont trop faibles, nous devons les détecter au plus vite pour y remédier. Ce calcul de performance en production peut cependant s’avérer complexe. En effet, le calcul d’une performance nécessite de connaître la prédiction idéale, ce qui est difficile en production. Cette performance peut être monitorée avec un outil de visualisation si nous pouvons récupérer automatiquement la prédiction idéale ou l’obtenir auprès d’un expert.
Finalement, la mesure du bénéfice métier apporté par l’application est la boucle de feedback la plus haut niveau. Elle est malheureusement souvent oubliée ou difficile à mettre en place. L’objectif est de s’assurer que l’application sert effectivement les objectifs de l’organisation (un bénéfice pour une entreprise ou être d’utilité publique pour un organisme à but non lucratif). Il est possible de mesurer plusieurs proxys de cet objectif. Par exemple : mesurer le nombre d’articles vendus, la marge et le CA généré par cette application. Ces métriques sont souvent calculées à la main grâce à des extractions de données de contrôle de gestion ou bien souvent pas calculées du tout.
Ce que l’on peut afficher à l’utilisateur, le bénéfice attendu et la forme
Maintenant que nous avons identifié les différents types de métriques que nous sommes amenés à exposer pour monitorer une application de machine learning, nous allons détailler quelques métriques que vous pouvez exposer à l’utilisateur avec un exemple de mise en forme et un bénéfice attendu.
Courbe montrant l’évolution des performances du modèle depuis sa mise en service
Il est maintenant acquis que les performances d’un modèle de ML risquent de se dégrader avec le temps. Les utilisateurs de modèles de ML sont souvent au courant de ce phénomène, mais n’ont la plupart du temps pas les moyens de savoir si cette dégradation a eu lieu ou si les performances sont encore bonnes. Nous proposons donc d’offrir à l’utilisateur un historique des performances du modèle, par exemple sur les derniers jours.
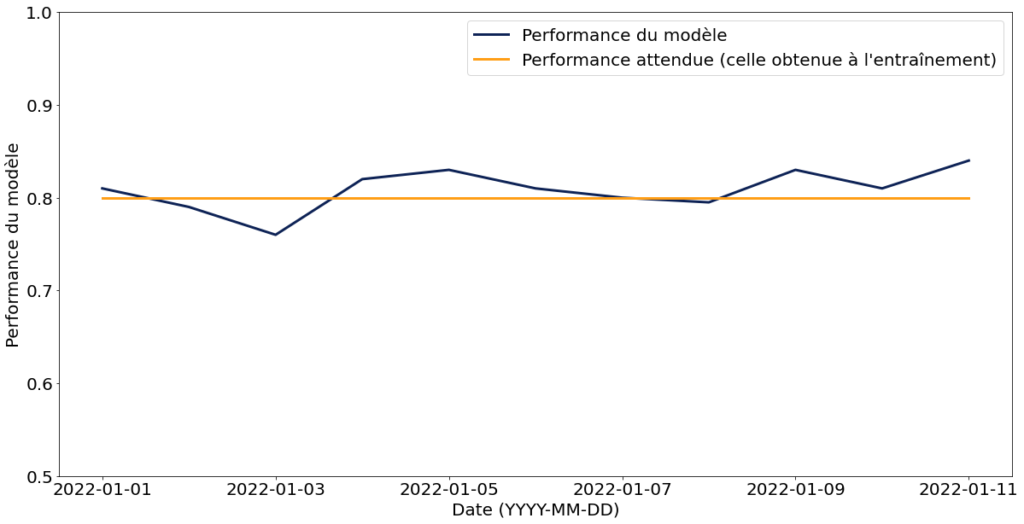
Figure 5 : Proposition de présentation des performances passées du modèle et de la performance attendue (celle obtenue en phase d’entraînement).
La métrique que vous choisissez d’afficher doit être compréhensible par l'utilisateur, on évitera donc les AUC pour des utilisateurs non data scientist.
Le bénéfice attendu de cette information est de permettre à l’utilisateur de prendre conscience de cycle de vie du modèle : est-ce qu’il performe bien ? Est-ce qu’il commence à moins performer ? Est-ce qu’il est obsolète ? Et ainsi lui permettre de prendre de meilleures décisions, voire de remonter des alertes.
Disponibilité du service
En général, une application nécessite une disponibilité 24h/24 et 365 jours par an.
Nous pouvons définir la surveillance de la disponibilité des applications comme le processus de vérification des fonctionnalités, de la vitesse et des performances de l'application. Rendre accessibles aux utilisateurs les indicateurs de surveillance permet d’avoir une expérience utilisateur transparente.
Apple, par exemple, a une page web dédiée à l’état de tous ses systèmes qui permet d’informer de la disponibilité des services en temps réel.

Figure 6 : Etat des services apple (https://www.apple.com/fr/support/systemstatus/)
Une mise à jour de l’état de chaque système est faite chaque minute pour mettre en confiance l’utilisateur ; la date de la dernière mise à jour est affichée.
Un état du flux de données
Dans un but de mise en confiance de l’utilisateur, à l'instar d’Apple qui donne la date de sa dernière mise à jour sur l’état de son système, Covid tracker qui met à disposition des chiffres sur la COVID19, fournit également la date mise à jour des données. Cette date permet de contextualiser les chiffres.
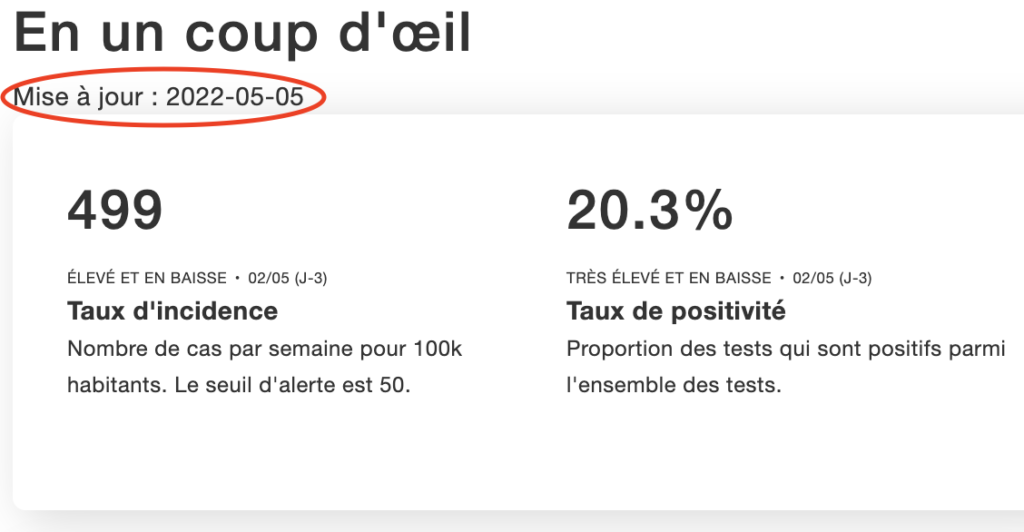
Figure 7 : Capture d’écran de CovidTracker affichant la date de mise à jour des données
De même pour le site Magic Sea Weed, connu par les surfeurs comme étant une référence dans la prédiction de la houle, met aussi à disposition des utilisateurs la date de prédiction du modèle.

Figure 8 : Capture d’écran de Magic Sea Weed affichant la date de mise à jour des prédictions
Cela permet à l’utilisateur d’être plus en confiance et de savoir si ce qui est affiché est pertinent.
Même si ce n’est pas vraiment du monitoring, nous trouvons intéressant de mentionner que Magic Sea Weed affiche aussi le modèle utilisé, qui donne un gage de qualité. Dans des secteurs, comme la prédiction météorologique, certains modèles sont des références, comme dans cet exemple pour le modèle “Lotus 3M”.

Figure 9 : Affichage du nom de modèle
L'Interprétabilité d’un modèle (ie les critères clefs de décision)
En plus d’afficher le modèle utilisé, ajouter les critères clefs de décision permettra à l’utilisateur de comprendre comment l’application est arrivée à une telle prédiction et quelles sont les variables qui sont entrées en jeu.
Par exemple, lors d’une prédiction d’un prix de maison (construit à partir du Boston Housing Dataset), l’utilisateur peut voir quelle variable a influé sur le prix et par exemple mettre en place des actions pour mieux valoriser son logement.
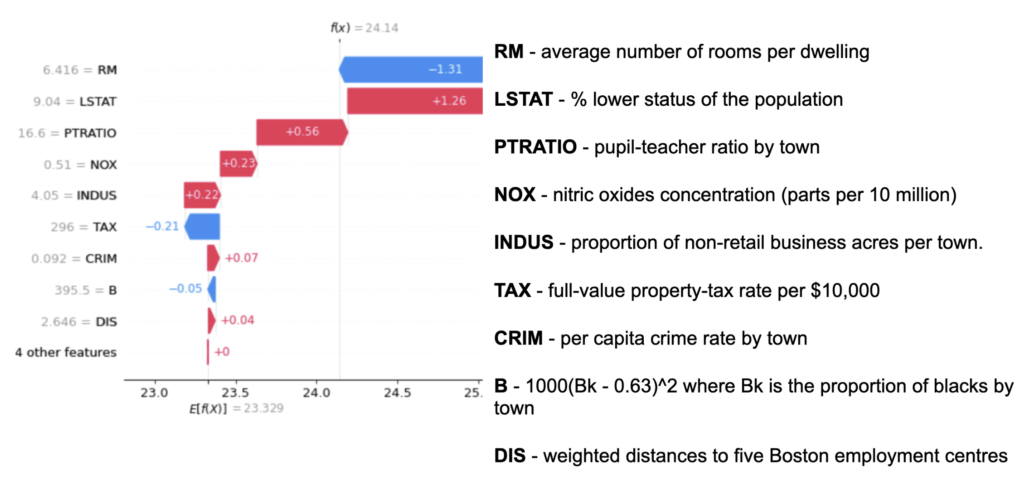
Figure 10 : Exemple de représentation extrait des shap values
Dans la figure ci-dessus, nous pouvons voir qu’une prédiction a été faite à 24,14. La variable RM a contribué à diminuer la prédiction de 1,31, la variable LSTAT a contribué à augmenter la prédiction de 1,26, etc.
Un autre exemple d’interprétabilité du modèle serait de comprendre pourquoi un e-mail est considéré comme un spam. En effet, toute personne ayant une adresse e-mail à probablement déjà rencontré des e-mails allant directement dans leur courrier indésirable.
Pour cela, il serait intéressant de tuner l’algorithme de reconnaissance de spam et d’expliquer pour chaque e-mail la raison pour laquelle il a été envoyé dans le dossier des courriers indésirables. L’exemple ci-dessous montre que ce mail est considéré comme un spam, car l’adresse e-mail de l’expéditeur est identifiée comme un spam.

Figure 11 : Exemple de mail indésirable avec la raison
Affiche une fiabilité de l’estimation
La fiabilité de l’estimation peut prendre la forme d’un pourcentage ou d’une erreur type dans le cas d’une classification ; d’un écart-type dans le cas d’une régression. Un tel indicateur permettra de renforcer la confiance de l’utilisateur dans la prédiction, voire de lui permettre de prendre de meilleures décisions. Par exemple, lorsque le site Meilleurs Agent accompagne chaque estimation d’un bien immobilier d’une fourchette de prix :

Figure 12 : Fiabilité d’un prix de bien immobilier donnée par https://www.meilleursagents.com/
D’ailleurs, Meilleurs Agents profite de cet affichage pour collecter du feedback sur la prédiction, via un petit formulaire présenté à l’utilisateur :

Figure 13 : Formulaire de prise de feedback sur une prédiction proposé par meilleur agent.
Un autre exemple est Netflix qui donne un pourcentage de correspondance d’un contenu à vos goûts :
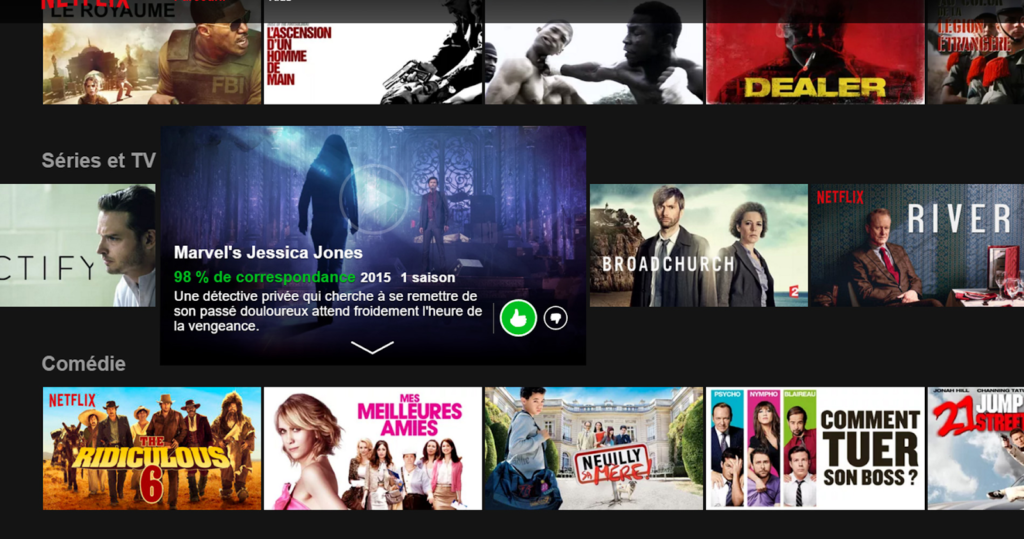
Figure 14 : Pourcentage de correspondance d’une recommandation donnée par Netflix.
Valider ou invalider une prédiction
Certaines applications permettent à leurs utilisateurs de valider, invalider, ou modifier le résultat d’une prédiction pour offrir une meilleure expérience. C’est le cas par exemple de l’application Vivino, qui permet à ses utilisateurs de reconnaître une bouteille de vin par une simple photo et d’obtenir des avis, et qui permet à l’utilisateur de valider ou d’invalider ses prédictions. Cette intervention personnelle de l’utilisateur, qui n’agit pourtant pas en vue d’améliorer le système, nous permet néanmoins de récupérer la ground truth.
Lorsque vous prenez une photo d'une bouteille de vin, vous pouvez immédiatement consulter les avis de crowdsourcing. Une fois la photo prise, l’application propose à l’utilisateur de modifier la prédiction s’il la considère fausse. En plus d’améliorer les prédictions futures en labellisant, cela va permettre à l’entreprise de labelliser la base de données pour faire du réentraînement et va permettre à l’utilisateur d’être en confiance face au désir d’amélioration continue de l’entreprise.
La dépense énergétique du modèle
De plus en plus d’articles parlent du coût énergétique des modèles de Machine Learning (article 1, article 2, …) et des velléités de ML plus “green” apparaissent. Dans le cas de certaines applications, il serait intéressant d’afficher le coût énergétique d’un modèle, ou d’une prédiction. Même si cela n’existe pas encore à notre connaissance, nous pourrions imaginer un service de classification ou de speech-to-text à la demande où seraient offerts plusieurs modèles à utiliser en affichant des coûts différents. Un peu comme Uber propose l’option Uber Green :
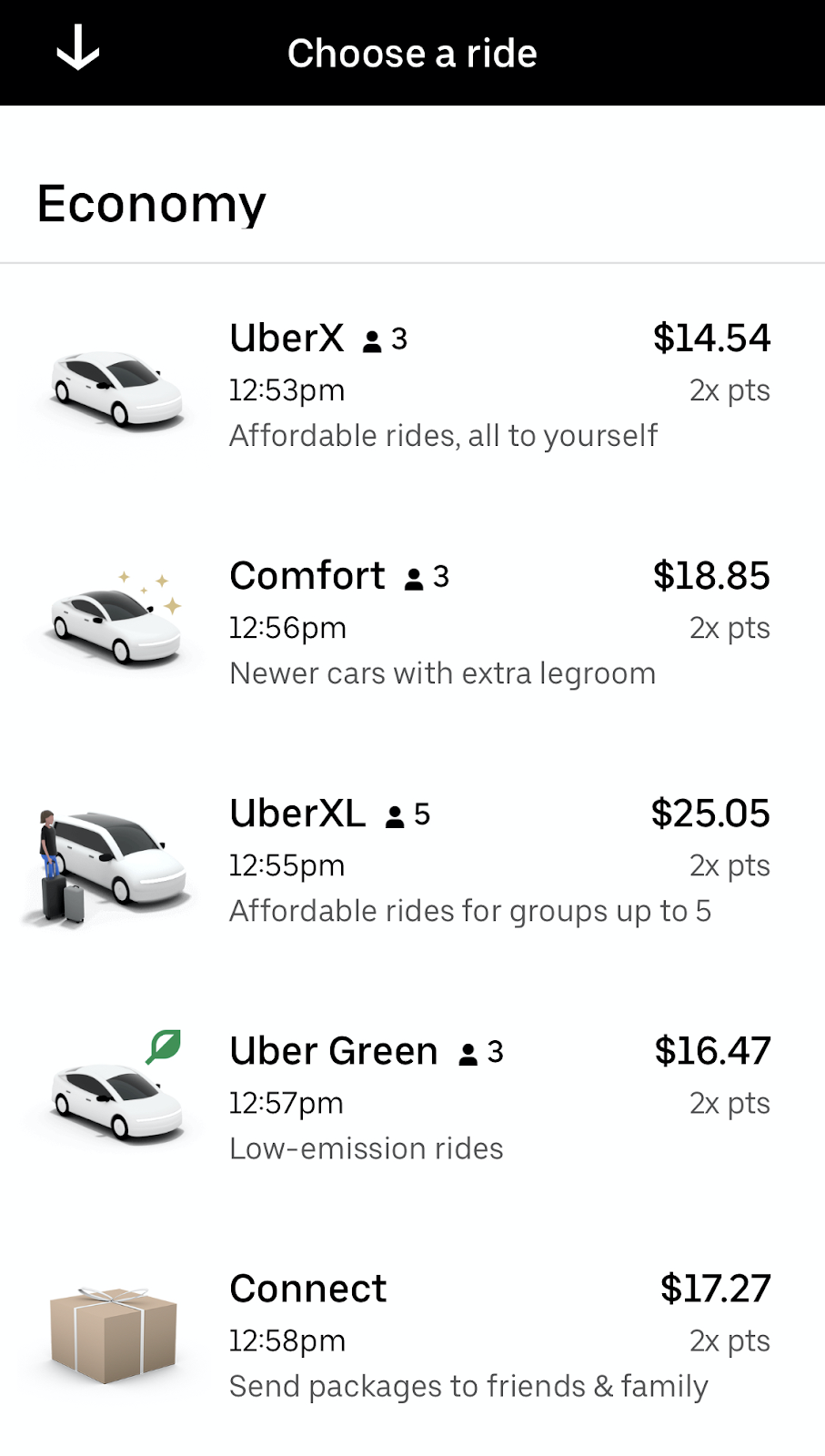
Figure 15 : Proposition d’une offre “green” par Uber pour un trajet
Appliqué à un service de classification à la demande, cela pourrait ressembler à :
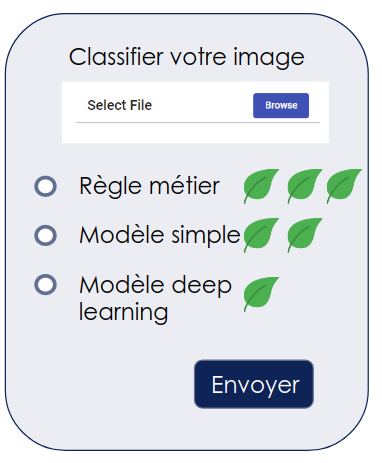
On pourrait imaginer que lorsque l’on passe la souris sur les feuilles vertes, on ait un détail des performances réel du modèle et de ses émissions actuelles (par exemple étant donné le mix énergétique à l’instant “t” fourni par exemple par electricity map).
L’objectif d’une telle démarche serait de promouvoir une responsabilité collective, voire de faire des économies d’énergies.
Conclusion
En Machine Learning, il est possible de calculer de nombreux indicateurs de monitoring. Nous proposons de les afficher à nos utilisateurs afin de tirer différents bénéfices que l’on résume dans le tableau ci-dessous :
| Objectif | Choses exposables |
| Confiance / Transparence / Éthique | Monitoring de la performance (DS ou métier) Interprétabilité Intervalle de confiance |
| Amélioration de la prise de décision | Monitoring de la performance (DS ou métier) Etat des flux de données Intervalle de confiance |
| Gestion intelligente des ressources | Monitoring du CPU/GPU Monitoring des coûtsMonitoring de la pollution (dont CO2) |
| Récupérer du feedback | Indice de fiabilité |
Dans cet article, nous avons fourni une liste à la Prévert d’indicateur, pour décider ce que vous voulez réellement exposer à vos utilisateurs, vous pouvez :
- Avoir une démarche d’UX pour valider l’intérêt
- Identifier le niveau de transparence à avoir avec les utilisateurs
- Identifier le contexte utilisateur interne ou externe à l’organisation
NB : Une fois que vous aurez identifié cela, vous devrez alors vous poser la question des SLO/SLAs de cette nouvelle fonctionnalité.
Nous tenons à remercier nos relecteurs : Mehdi Houacine, Jérémy Surget, Baptiste Saintot, Philippe Prados.