Et si Devops nous emmenait vers TDI (Test Driven Infrastructure) ?
Des usines de développement au service de l'infrastructure ?
Le mouvement DevOps a permis aux applications de gagner en productivité et donc en rapidité d’évolutions grâce entre autre à une démarche très efficace : le Continuous Delivery. Grâce à un rapprochement des pratiques entre Dev et Ops on arrive à apporter aux équipes infrastructures tout l'outillage du développement d'applications. Et c'est là qu'arrive l'un des grands concepts Devops : Infrastructure As Code.
Les géants du web sont largement en avance sur ce que l’on fait aujourd’hui dans la majorité des entreprises. Surtout concernant la mise en place et le déploiement des infrastructures mais également sur un sujet encore peu exploré : l'automatisation des tests d'infrastructure.
On sait aujourd'hui parfaitement tester nos applications mais quid des infrastructures qui les hébergent et que l'on automatise de plus en plus ?
Pourtant, si on rentre dans Infrastructure as Code, on écrit bien du code, on a bien un cycle de vie habituel de code, il faut donc tester ce code!
Une chose est sûre, on doit tester de bout en bout tout ce que l'on automatise soit même.
Si on garde en tête que l'objectif est d'aller vite à déployer, que ce soit les applications ou les infrastructures, on ne peut plus se permettre l'action manuelle d'un utilisateur consistant à vérifier que le service répond sur tel port, que le site est accessible via le navigateur etc : cela nous ferait perdre tout l'intérêt d'une automatisation complète. Et surtout, cela nous ferait énormément perdre en vélocité.
De fait il devient donc évident qu'il faut écrire des tests sur l'infrastructure aussi, oui oui aussi.
Des tests unitaires sur l'infra ?
Par rapport à ce qui est fait côté applicatif, côté infrastructure on a encore du retard à rattraper sur la partie testing. Utiliser les mêmes outils, côté développement et côté ops ne semble pas toujours possible car les frameworks et langages dédiés à l'infrastructure ne sont pas aussi outillés que leurs pendants applicatifs.
On peut alors se demander comment arriver à une intégration continue sur des outils et langages qui ne sont pas forcément prévus pour. Que ce soit un shell maison, bash ou ksh peu importe, ils ne sont pas aussi outillés que les Java, .NET et consort. C'est aussi ce vide qui amène de plus en plus d'ops à utiliser Ruby ou Python qui viennent avec les outils adéquats.
Même dans la démarche cela diffère : un test unitaire au niveau infra a rarement du sens, il faut plutôt parler de tests d'intégration à gros volume et là les choses se compliquent. Automatiser les tests d'infrastructure implique aussi de savoir monter automatiquement une infrastructure car si à chaque fois on doit tout installer à la main puis lancer nos tests automatisés le gain est faible. On a donc ici un problème de poule et d'oeuf : pour automatiser une infrastructure il faut des tests, et pour faire des tests automatisés d'infrastructure il faut automatiser le déploiement de celle-ci ... Oserais-t-on parler de Test Driven Infrastructure ?
Chez Octo, pour répondre à cet enjeu, sachant que la majorité des outils de gestion de configuration système automatisés (Chef/Puppet pour ne citer qu'eux) tournent autour du langage Ruby, nous avons étendu au sein de notre framework master-chef les capacité du framework de test unitaire de base de Ruby. Nous l'avons rendu capable de faire des tests et des assertions à l’intérieur de la machine (via ssh), mais aussi à l’extérieur grâce à des requêtes HTTP ou autre. Il est aussi possible d'utiliser Rspec ou Cucumber, on voit de plus en plus de framework de tests apparaitre tels que pour Chef : Chef Spec ou pour Puppet : RSpec-Puppet. Enfin, il existe aussi des outils éditeurs pour répondre à ces enjeux.
L'idée est donc de tester un système complet et pas seulement une application. Retenons surtout que la technologie choisie pour écrire les tests importe peu, c'est encore une fois la démarche qui importe. Et on peut y aller étape par étape, par exemple
- Etape 1 : Tester que les services déployés sont accessibles (requêtes HTTP par exemple)
- Etape 2 : Tester qu'ils tournent sur les bons ports réseaux, que les fichiers de configurations sont tous présents
- Etape 3 : Tester l'intégration entre les noeuds de l'infrastructure déployée
- Etape 4 : ...
- Etape N : Lancer les tests d'intégration mis en place côté dev !
Bref vous l'aurez compris, il y a un peu de travail mais c'est aussi le fait de savoir que votre SI est testé de haut en bas qui va vous donner fiabilité, productivité et surtout vous permettre de faire du Continous Delivery... jusqu'à la prod ! De plus, mettre en place la partie monitoring au préalable (en automatisant à nouveau) permettra de valider son fonctionnement avant la prod est aussi une première forme de tests => si je déploie une plateforme de tests, et qu'une fois le déploiement terminé son monitoring est au vert partout, c'est déjà plutôt bon signe! On peut alors résumer ça autrement : les questions que se sont posées au préalable les devs puis l’intégration pour savoir si une plateforme est up and running ont forcément amené à des résultats qui doivent être réutilisées plutôt que ré-inventées par les Ops.
Workflow d'un test complet ...
Le workflow de chaîne d'intégration côté infrastructure ressemble fortement à celui d'une application, on commit du code, on le déploie, on passe des tests dessus ... rien de bien nouveau !
La variation réside dans le fait qu'il faut provisionner / déprovisionner des machines au lieu d'uniquement déployer des applicatifs dans un environnement quasi-statique.
Pour une seule machine (mais le schéma est le même si on a N machines) cela peut se résumer à ces étapes :
- Création d'une machine virtuelle
- Injection de la configuration que l'on souhaite tester
- Installation OS / Packages / Configuration réseau etc.
- Déploiement d'applications
- Passage d'assertions en tous genre en utilisant SSH pour passer des commandes systèmes à la machine, requêtes réseaux de tout type etc...
- Lancer la batterie de tests associés à la configuration de machine montée.
- Puis finalement, destruction de la machine virtuelle pour libérer les ressources.
On peut alors faire un résumé d'un déploiement allant des infrastructures jusqu'aux applications par le schéma suivant, ici sur une stack classique : Hyperviseur VMWare, Chef Solo piloté par Capistrano. Toutefois vous verrez que ce schéma peut très facilement s'adapter à du Chef-server du Puppet .. Dans ce cas nous utilisons RVC pour piloter les hyperviseurs ( RVC = Ruby vSphere Client). Peu importe l'hyperviseur, on fait la même chose sur du LXC, du KVM ... Le tout est d'avoir une "api" pour le piloter.
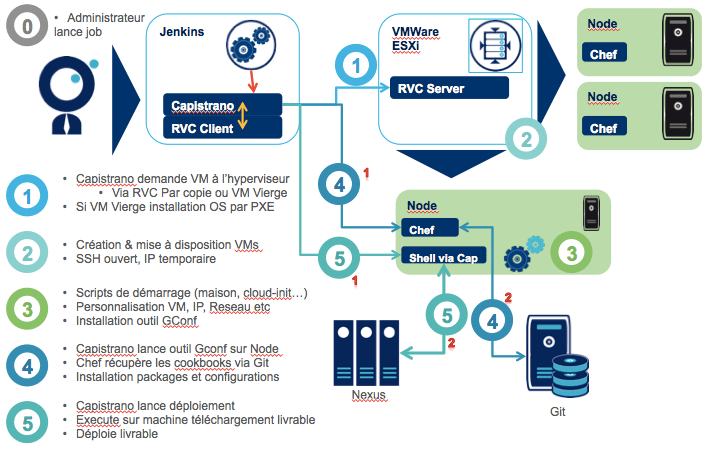
On voit ici qu'on va tout tester : les scripts de création de machine virtuelles, l'installation d'OS automatisée, la configuration des OS via l'outil de GConf (Gestion de configuration), les scripts de déploiements, puis finalement l'applicatif.
Ensuite il faut faire passer ces mêmes étapes à tous les niveaux de promotion d’une version de la plateforme, en pilotant l'ensemble avec un Jenkins par exemple.
Les mécanismes évoqués à l’instant sont déjà utilisés côté développement mais pour ainsi dire jamais sur un SI complet, or c'est cela qui va nous permettre d'arriver à une réelle intégration continue côté infrastructure.
Qualité du code
Et oui dès qu'on parle de code ce sujet revient vite sur la table. On ne va pas refaire l'article de la nécessité de faire de la qualité sur son code mais sachez que le code utilisé côté Infrastructure peut aussi (doit aussi...) faire l'objet d'analyse de qualité. Pour ça il existe des outils tels que Foodcritic pour Chef. Puppet est aussi bien fourni (voir dans cet article de Puppetlabs).
Pour notre framework opensource de cookbook chef nous utilisons Travis pour faire passer Foodcritic (un outil de qualité pour le code chef) régulièrement sur le code. De plus, nous avons un jenkins qui reconstruit régulièrement des VMs "générique", les installe puis lance nos tests. Cela nous permet de nous assurer de la stabilité de nos cookbooks Chef.
Il peut aussi être très utile de reconstruire (via des Nightly Build) des plateformes types toutes les nuits pour valider que tout fonctionne et qu'on peut encaisser n'importe quel crash ou mise à jour majeure nécessitant une reconstruction complète d'une partie ou de l'intégralité d'une plateforme. Nous mettons en place cette méthode chaque fois que nous pouvons disposer de ressources (hyperviseur) pour le faire, nous avons aussi parfois utilisé Amazon EC2 pour répondre à ce besoin. En effet étant donné que les VMs utilisées pour les tests automatisées ont une durée de vie courte, le coût est léger et maîtrisable.
En conclusion
Pour finir, les outils existent pour répondre à toutes les problématiques d'une infrastructure entièrement automatisée et testée. La difficulté réside plus dans l'intégration et l'assemblage de ces outils mais aussi et surtout dans la démarche qu'il faut établir et adapter à son besoin avant de commencer le moindre développement.
Nous avons entièrement migré le SI d'OCTO sous ce paradigme. Nous avons aussi accompagné plusieurs clients vers cette approche. C'est ce qui nous a amené au développement de frameworks open source tel que master-chef, un ensemble de cookbook pour chef très courants, master-cap un framework capistrano avancé : gestion de topologie, intégration chef dans cap ... Et finalement vous pourrez trouver des exemples de ces tests automatisés dans master-chef-tests, tout ceci se passe sur ce compte GitHub : Kitchenware.
Enfin, retenez surtout qu'Infrastructure as Code rend de nombreux services mais pour vous assurer de faire évoluer sereinement vos "cookbooks" vous devez les entourer (comme dans un cycle de développement classique), d'un harnais de tests automatisés !