Environnements éphémères : passer du pet au cattle
Remerciement aux relecteurs, et les octos qui ont pratiqué l’exercice du Perfection Game en interne pour aider à l’améliorer : Julien Tellier, Georgia Bjärstål, Sofía Calcagno, Emmanuel-Lin Toulemonde.
DEV, STG, QUAL, UAT-1, Recette-2, … Vous connaissez probablement cette routine : après avoir développé votre fonctionnalité, il faut traverser une multitude d’environnements, construits par on-ne-sait-qui il y a très longtemps et qu’il faut parfois partager avec d’autres équipes, avant d’enfin apercevoir la lumière de la production.
Je vous propose dans cet article de découvrir la pratique des environnements éphémères au travers d’un retour d’expérience de projets où des dizaines d’environnements étaient construits (et détruits) chaque mois, à la demande, pour obtenir du feedback au fil de l’eau et livrer du code en production par petits lots, sans en faire un parcours du combattant et sans faire exploser la facture cloud. Si vous n’avez jamais détruit un de vos environnements antéproduction sur vos projets, cet article va vous intéresser.
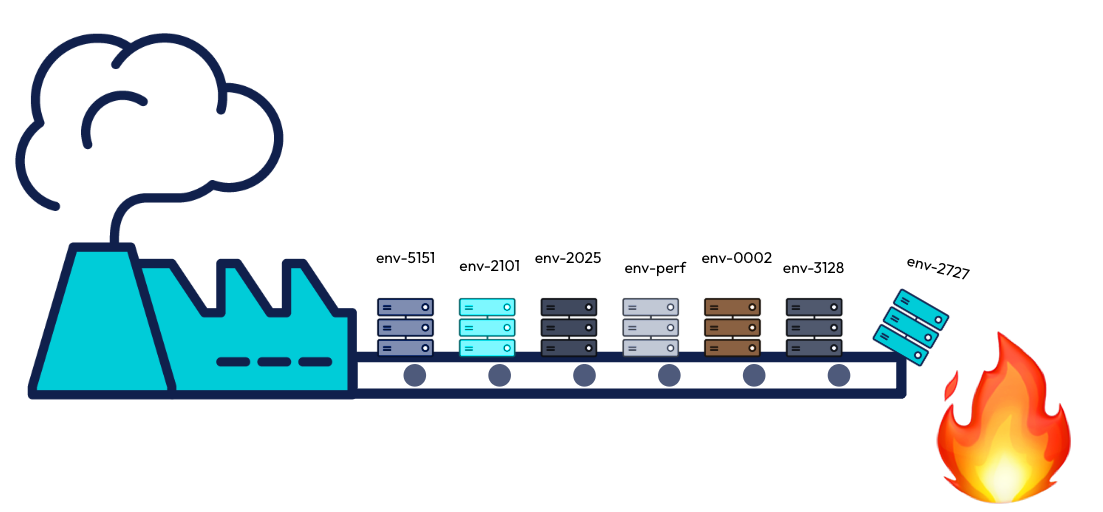
Environnements pérennes | “Toute ressemblance avec des environnements existants serait purement fortuite”™️
Il y a quelques années, j’ai rejoint un projet avec le rôle d’ops. C’était la première fois que j’occupais ce rôle dans une équipe et ma lettre de mission était la suivante :
> Dans votre équipe, vous êtes responsable du maintien en conditions opérationnelles des environnements cloud utilisés par les équipes de dév pour livrer leur produit.
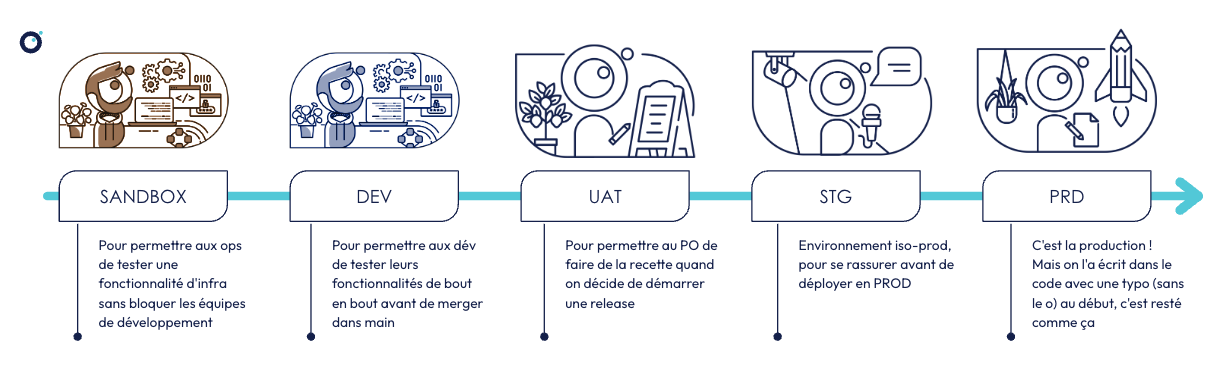
À la genèse du projet, les ops et les équipes de développement avaient défini leur processus de livraison en production, et les environnements qu’ils considéraient nécessaires pour le réaliser. Les voici :
J’ai rejoint ce projet 3 ans après son démarrage, le nombre d’environnement avait alors presque doublé et le paysage avait évolué pour ressembler à ceci :
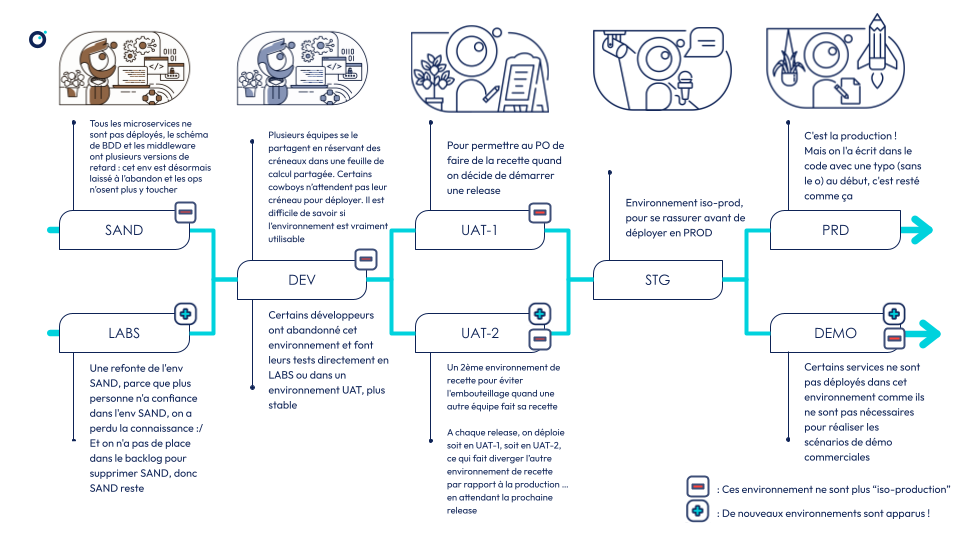
Le travail de maintien en conditions opérationnelles (MCO) de ces environnements était titanesque, nous avions à gérer dans notre périmètre de responsabilité :
- 8 environnements dans le cloud
- Un parc de près de 150 machines virtuelles déployées (avec les services EC2 et ECS), répartis entre ces environnements qui tournaient 24 heures sur 24, 7 jours sur 7
- Des pipelines de déploiement continu (CD) qui ne fonctionnaient qu’en DEV et UAT-1, mais pas pour les autres environnements, par manque de temps et par priorisation d’autres tâches. Les actions de déploiement et de promotion d’artéfacts étaient donc réalisées manuellement par les ops
- Des environnements laissés à l’abandon, que l’équipe ops ne voulait plus utiliser par manque de confiance comme la SANDBOX, ou l’UAT-2, mais dont le décommissionnement n’était jamais la priorité car cela coûte du temps et n’apporte pas de valeur visible aux utilisateurs
- Des environnements avec des écarts de configuration notables accumulés au fil du temps : des services déployés dans certains environnements mais pas d’autres, des versions et schémas de bases de données différentes, …
L’activité de MCO occupait notre équipe de 5 ops à temps plein, et cela se reflétait bien dans certains de nos indicateurs de performance de delivery (cf. DORA) : notre fréquence de déploiement était de 100 jours. C’est à dire que presque 3 mois s’écoulaient en moyenne entre le moment où le Product Owner donnait le top départ pour réaliser une livraison logicielle et le moment où la nouvelle version du produit était utilisable en production.

Parcours pour réaliser une release du produit 🏃
Trop occupée à corriger les problèmes relevés dans les nombreux environnements, et paralysée par les tâches parasites (toil), mon équipe avait peu de temps à consacrer à des tâches essentielles d’amélioration continue comme automatiser les déploiements dans tous les environnements, investir dans l’observabilité et l’alerting pour gagner en proactivité sur les incidents, ou bien résoudre les problèmes de sécurité accumulés au fil du temps sur une infrastructure qui n’avait pas redémarré depuis plusieurs mois.
Accueillir une nouvelle personne dans l’équipe était aussi douloureux : en moyenne, un nouvel arrivant dans l’équipe ops mettait 4 mois avant de pouvoir prendre une tâche triviale du backlog en autonomie. C’était le temps nécessaire pour se familiariser avec les subtilités de chaque environnement et vivre au moins une fois le processus de release du début à la fin.
La bataille entre les développeurs dans l’environnement DEV faisait rage : ce dernier était une ressource en concurrence entre plusieurs équipes pour réaliser des tests quotidiennement. Une feuille de calcul servait d’agenda partagé entre les équipes pour réserver des créneaux d’utilisation de l’environnement, mais les déploiements successifs de travaux en cours des différentes équipes laissaient souvent l’environnement dans un état instable, le rendant difficilement utilisable par l’équipe ayant réservé la plage suivante. Certaines équipes ont alors commencé à détourner l’usage d’autres environnements, comme l’UAT, pour faire leurs tests de développement.
De son côté, le PO en perte de confiance dans le processus de delivery était condamné à recetter des lots de fonctionnalités conséquents. Équipé de son cahier de tests fonctionnels dans Word, il testait l'équivalent de 3 mois de fonctionnalités à chaque release tout en réalisant des tests de non-régression. En général, c’est au moins la moitié des items à recetter qui ne correspondaient pas aux attendus : les développeurs devaient interrompre leur travail en cours pour revoir leur copie en urgence mais il était difficile de se remettre dans le contexte d’une fonctionnalité développée plusieurs mois auparavant.
Dans une telle situation, le delivery est peu prédictible, les déploiements sont douloureux. Avec un time-to-market de 3 mois minimum, le PO réfléchissait à démarrer la prochaine release du produit avant même que celle en cours ne soit terminée pour tenir les délais de livraison.
😵 Comment en est-on arrivé là ?
Quand autant de problématiques techniques et organisationnelles se cumulent, il n’est pas simple d'identifier une unique root cause pour expliquer la situation. Le nombre d’environnements que nous avions à gérer pourrait être un bon candidat. Pour les lecteurs qui n'arrivent pas à faire le lien entre le nombre élevé d’environnements à gérer et les problèmes évoqués plus haut (complexité accidentelle à foison, charge cognitive extrême, situations propices au burnout, …), voici quelques détails.
💥 De la complexité accidentelle s’est accumulée dans les pipelines CI/CD : chaque fichier de pipeline Jenkins comptait plusieurs milliers de lignes de code implémentés selon un paradigme impératif : du code avec des structures de contrôles, des boucles for, while et des if empilés sur plusieurs niveaux d’imbrication pour pouvoir gérer les cas particuliers de chaque environnement.
stage('Deploy microservices') {
def AWS_ENV = env.AWS_ENV
if (AWS_ENV == "DEV") {
echo '🚀 Déploiement sur DEV'
sh 'aws cloudformation update-stack --stack-name microservices-${tenant_name}-dev ...;'
} else if (AWS_ENV == "UAT") {
echo '🚀 Déploiement sur UAT'
// Redémarrage d'une task souvent capricieuse dans cet env et pas les autres
aws ecs stop-task ...
sh 'aws cloudformation update-stack --stack-name microservices-${tenant_name}-uat ...;'
// Une pause, parce que des fois c'est nécessaire dans cet env
sleep 1000;
slackSend channel: "#aws_env_uat_notifications", message: "UAT deployment should have ended"
} else if (AWS_ENV == "STG") {
...
}
}
Extrait d’un bout de pipeline de CD Jenkins en Groovy avec des structures conditionnelles pour gérer les divergences de configuration et de comportements entre environnements
📁 La topologie d’infrastructure est certes modélisée avec du code (d’infrastructure), mais chaque fichier de cette topologie contient entre 500 et 1500 lignes en moyenne. Être familier avec un seul environnement sur ce projet qui avait 3 ans d’existence nécessitait d’être en maîtrise d’un patrimoine de presque 10 000 lignes de code.
📁📁 Chaque environnement était modélisé sous la forme d’un dossier dans le code :
- un dossier SAND/,
- un dossier LABS/,
- un dossier DEV/,
- un dossier UAT-1/,
- un dossier UAT-2/,
- un dossier STG/,
- un dossier DEMO/,
- un dossier PRD/.
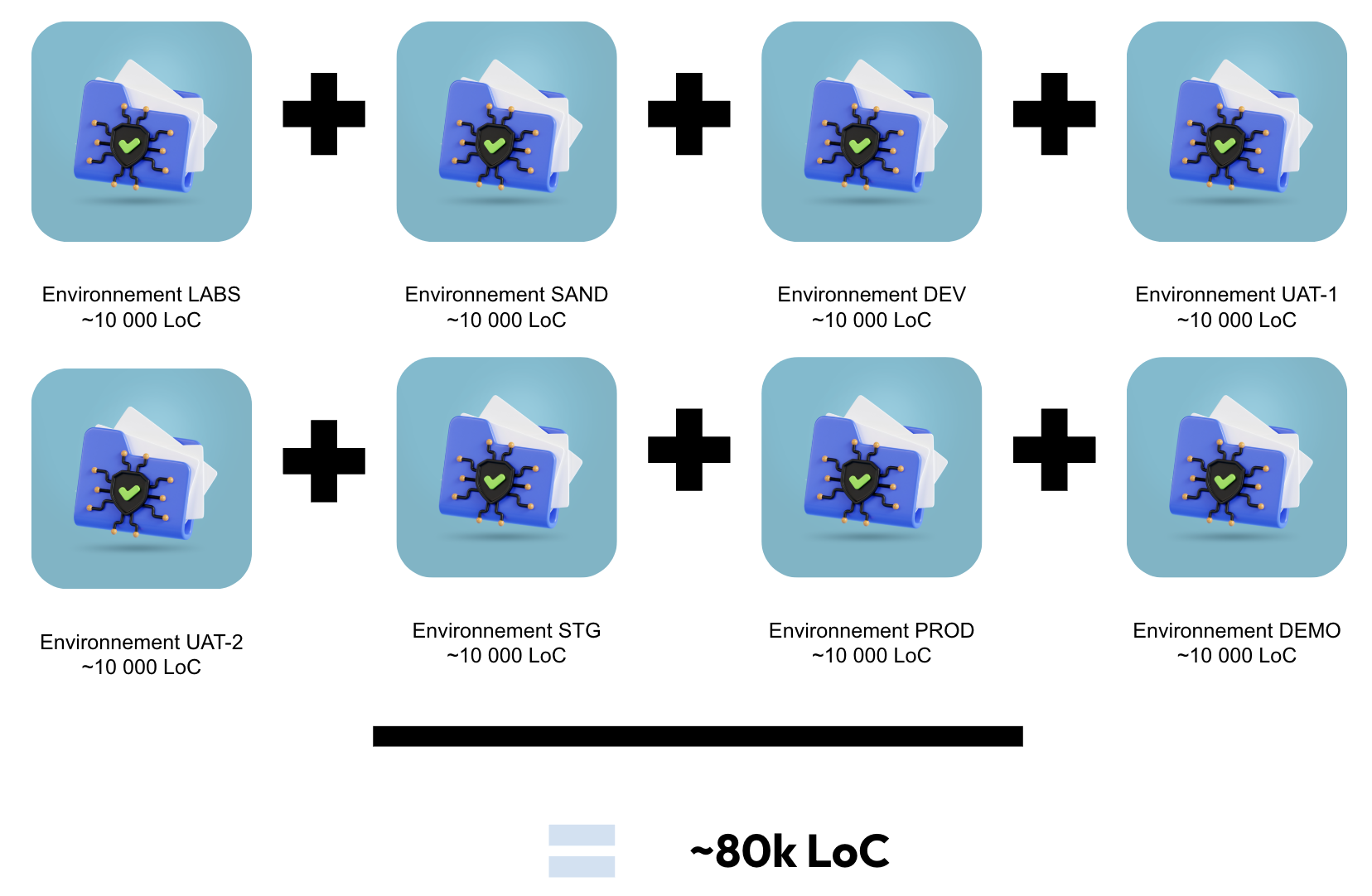
Cela amène de la duplication de code d’infrastructure : on construit d’abord un premier environnement (par exemple, PRD), puis on duplique le dossier PRD/ autant de fois qu’on souhaite avoir d’environnements. Si cette stratégie permet de savoir exactement comment est configuré un environnement (on ouvre le dossier éponyme pour être fixé, sans ambiguïté), cela signifie aussi qu’être familier avec toute la topologie d’infrastructure, c’est être familier avec … un peu moins de 100 000 lignes de code 💀 (sans compter d’autres éléments de code d’infrastructure comme : les pipelines CI/CD, les Dockerfiles, d'éventuels scripts bash/Python/Makefile/Justfile, …)
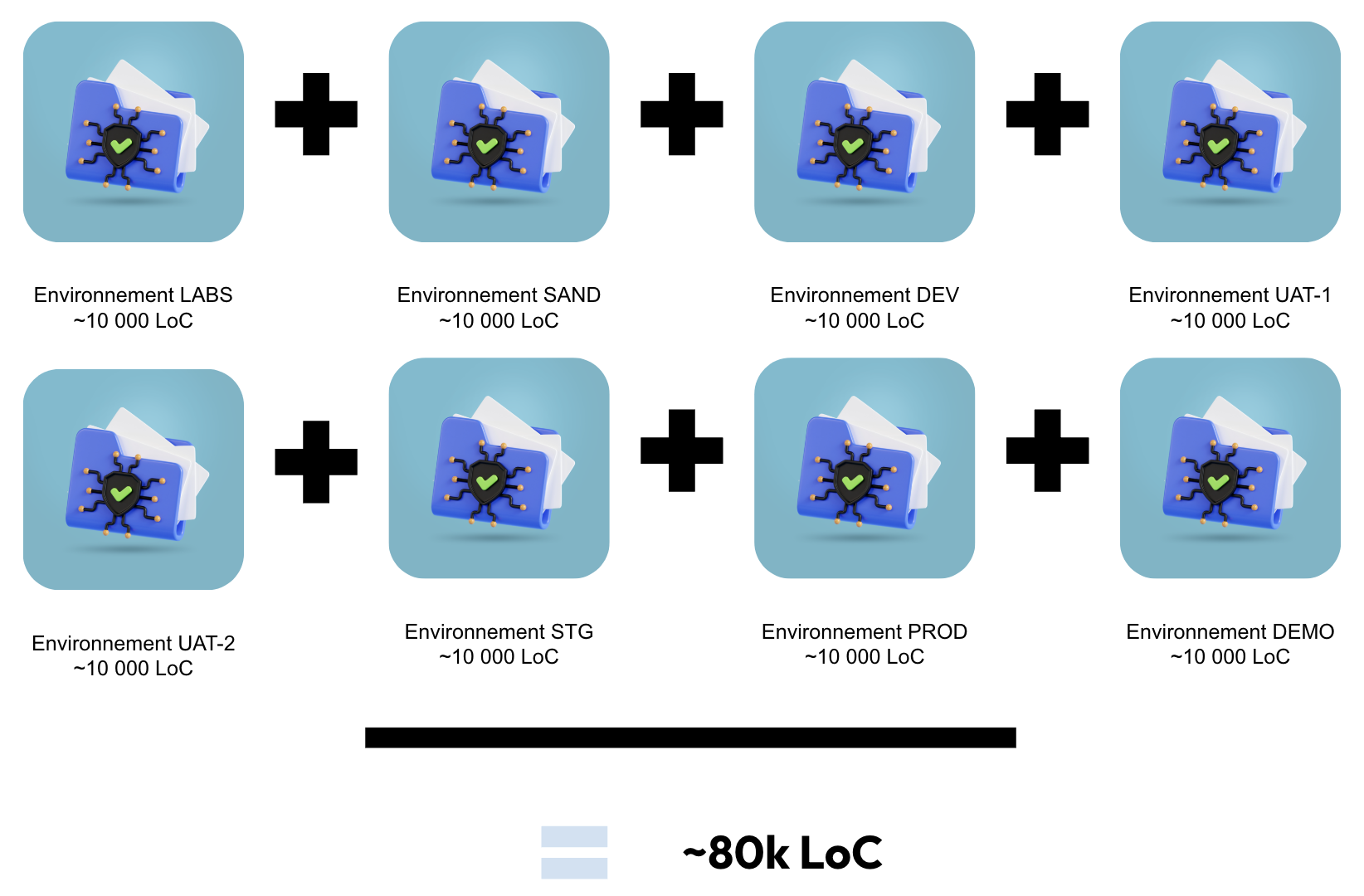
Avec 1 environnement par dossier, le nombre de lignes de code
évolue linéairement avec le nombre d’environnements à maintenir 📈
Les divergences observées entre les environnements provenaient souvent d’un manque de discipline ou d’éparpillement de l’équipe : on corrige un problème dans un environnement donné au détour d’une tâche de support sur un incident, et on ne pense pas toujours à répliquer la même évolution dans tous les environnements.
> 💡 Si par habitude on cherche généralement à produire le maximum de découplage entre des composants dans notre code*, le couplage délibéré peut avoir du bon dans le cas où on veut que nos environnements évoluent ensemble, de manière iso.*
Enfin, au-delà des enjeux techniques, cette charge cognitive qui s’accumule amène naturellement la transformation de l’équipe en une “colocation” d’individus : un groupe de personnes qui partagent un repo de code mais collaborent peu. Chacun développe son expertise sur un pan de la base de code à défaut de pouvoir tout absorber, tout savoir, et tout faire : la connaissance se silote alors entre
- Un expert des environnements anté-production mais pas du reste,
- Un autre membre de l’équipe expert du support en production mais pas du reste,
- Un expert des pipelines CI/CD,
- C’est celui qui sait où ils sont exécutés, quand, comment, avec quels arguments, et qui sait quoi faire quand il y a des logs d’erreurs ou qu’un pipeline ne veut pas se lancer,
- Un expert “code d’infrastructure mais juste sur le périmètre des bases de données”
- C’est celui qui connaît les procédures en cas de disaster recovery, il sait où sont les backups, s’il y en a, comment en générer un, comment en restaurer un, …
- Un expert “code d’infrastructure mais juste sur le périmètre des services applicatifs à déployer”,
- C’est celui qui a par exemple appris au fil des années qu’il faut déployer ce microservice avant celui-ci, sinon ça ne marche pas,
- Un expert du déploiement manuel des APIs dans l’outil d’API management à l’interface graphique labyrinthique,
- …

Quand la charge cognitive est trop forte, l'équipe et l'expertise se silotent
Is there a better way ?
Si je pensais que cette organisation du code d’infrastructure avec 1 dossier par environnement et beaucoup de duplication de code était une singularité de ce projet, j’ai retrouvé cette organisation du code et quelques douleurs associées sur tous les projets que j’ai rejoint par la suite.
Alors que je pensais que cette manière d’organiser du code était une fatalité, j’ai rejoint mon dernier projet en tant qu’ops, à sa genèse. J’étais alors responsable de poser les premières briques du code d’infrastructure d’un nouveau projet, et j’étais bien décidé à tenter une nouvelle approche.
Je faisais à cette époque un peu de veille sur le sujet, j’ai découvert alors pêle-mêle des outils qui m’étaient inconnus comme Pulumi ou Terragrunt : des outils d’infrastructure-as-code qui se définissent en alternative à Terraform, mettant en avant la promesse de faire mieux.
La landing page de Terragrunt, qui se présente comme une surcouche d’orchestration à Terraform rendant le code “plus maintenable” 🤔
N’étant pas spécialement fâché avec Terraform mais avec la pratique de dupliquer mon code d’infrastructure dans des proportions qui nuisent à ma charge cognitive, je décide de creuser la documentation de Terraform. Je m’intéresse alors à une fonctionnalité qui existe depuis 2 ans à l’époque mais dont je n’avais jamais entendu parler : les workspaces Terraform.
> ⚠️ Pour illustrer une manière de corriger les problèmes de gestion des environnements rencontrés plus tôt, nous allons devoir rentrer dans le détail de ce qu’est un workspace Terraform. Pour autant, cet outil n’est qu’un détail d’implémentation*, il est possible d’obtenir les propriétés d’isolation entre des environnements qui vont être présentées avec d’autres outils ou pratiques.*
La définition d’un workspace Terraform dans la documentation officielle ne m’a pas beaucoup aidé la première fois que je l’ai lue :
> Workspaces in the Terraform CLI refer to separate instances of state data inside the same Terraform working directory.
Je la formulerais ainsi : lorsqu’on réalise des actions dans un dossier avec Terraform (plan, apply, destroy, …), Terraform se positionne par défaut dans un workspace nommé “default”, avec un fichier de state associé à ce workspace.
Dans ce même dossier contenant du code d’infrastructure, en tant qu’utilisateur de la CLI Terraform, nous avons la possibilité de créer d’autres workspaces, avec chacun leur state isolé des autres. On crée alors une relation “one-to-many” entre
- 1 modèle de code d’infrastructure unique
- et plusieurs versions de l’infrastructure physiquement déployées, chacune en isolation des autres et avec chacune leur état
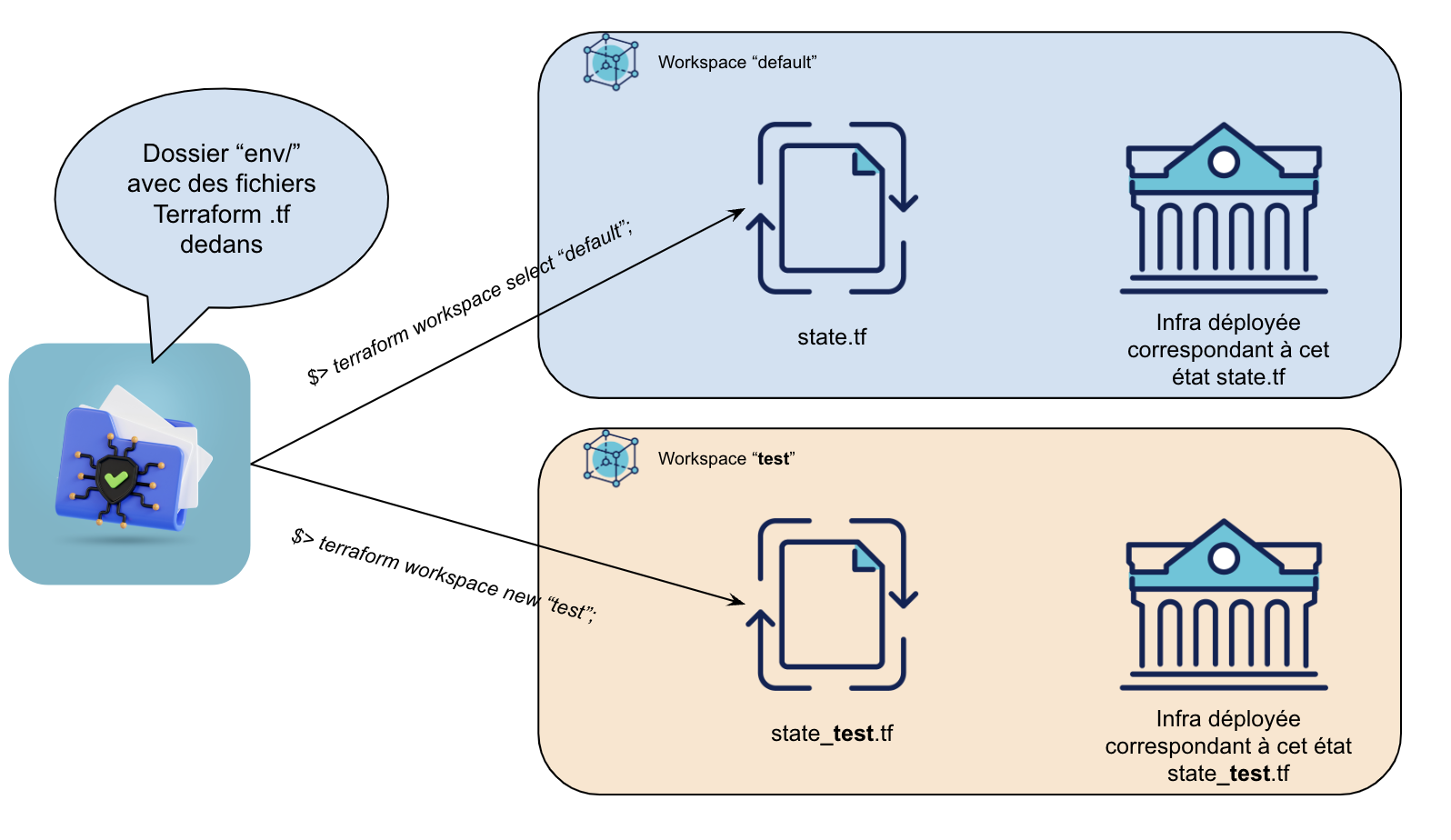
Cette abstraction de workspace ouvre le champ des possibles : en rendant le code d’infrastructure paramétrable, on peut alors imaginer refactorer le premier projet présenté en début d’article
- Avant : 8 dossiers, 1 par environnement avec du code d’infrastructure dupliqué en 8 exemplaires,
- Après : du code d’infrastructure en un seul exemplaire, dans 1 dossier nommé “infrastructure”, pour générer dynamiquement autant d’environnements que souhaité
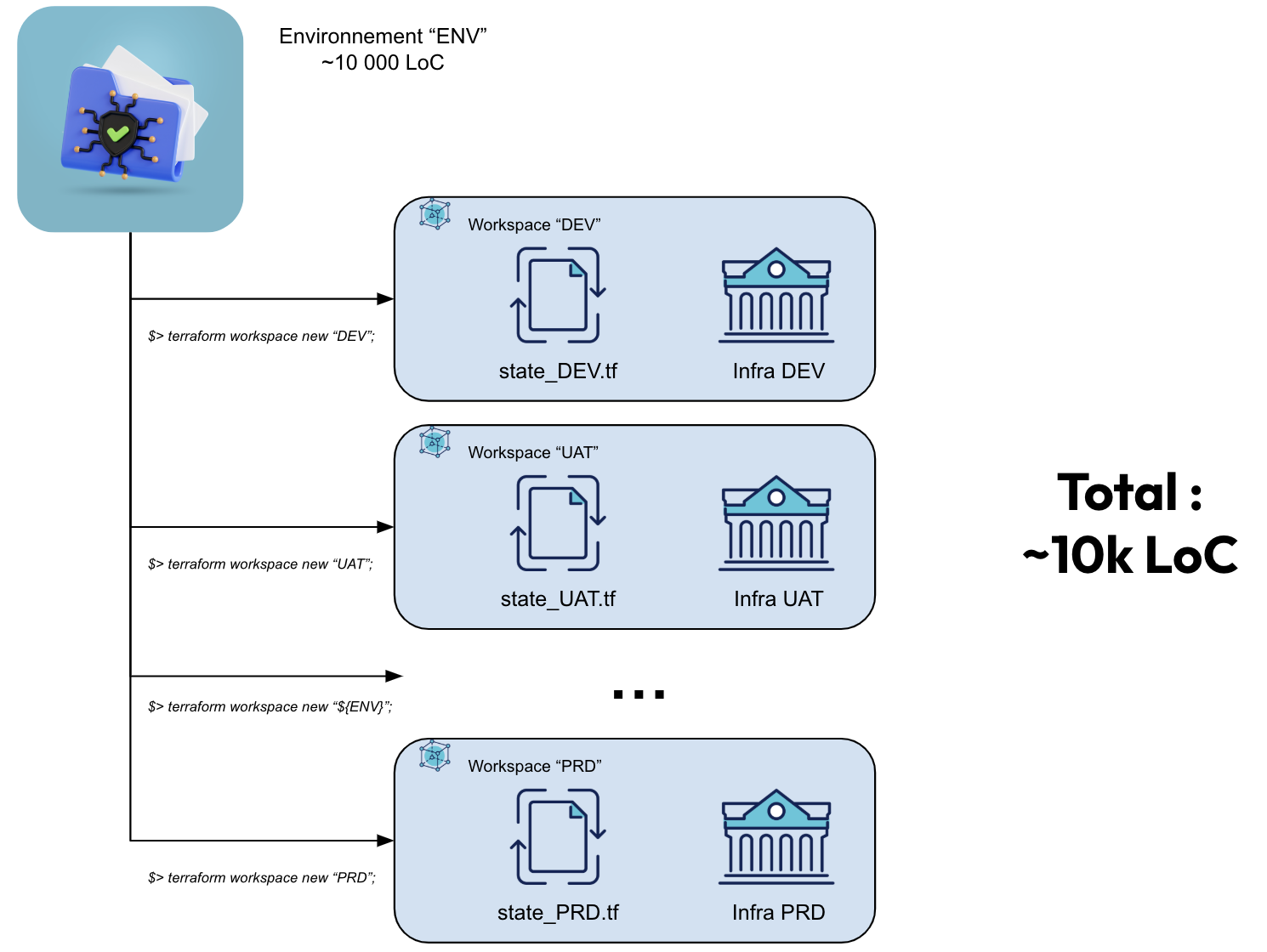
Créer un workspace peut se faire comme suit :
- $> terraform workspace new sand;
- $> terraform workspace new dev;
- $> terraform workspace new uat;
- $> terraform workspace new …;
- $> terraform workspace new prod;
On part alors d’une feuille blanche sur laquelle on peut déployer notre infrastructure, en exécutant le ou les commandes “terraform apply” nécessaires.
Mais, si construire un nouvel environnement est aussi peu coûteux, on peut se demander:
- Pourquoi ces environnements pérennes existent-ils ?
- Pourquoi les maintenir dans la durée ?
- Pourquoi ne pas monter un environnement “UAT” quand le besoin de recetter un lot à livrer survient, et le détruire quand la recette est terminée ?
Pourquoi ne pas pousser la démarche encore plus loin ? On pourrait avoir comme “environnement pérenne” uniquement l’environnement PROD, et créer des environnements à la volée pour répondre à des besoins ponctuels :
- On pourrait par exemple créer un environnement pour faire des tirs de charge avec la commande “terraform workspace new env-perf;” et le détruire quand le tir est terminé.
- On pourrait par exemple créer un environnement juste pour accompagner la short-lived branch feat-JIRA-2727-implement-policy-subscription-api-endpoint avec la commande “terraform workspace new feat-2727;”.
Nous commençons à toucher du doigt le concept d’”environnement éphémère”, qu’on trouve aussi nommé “review app” dans la littérature.
💡Pour conclure cette partie, on notera en aparté que modéliser ses environnements avec des workspaces plutôt qu’avec des dossiers est une pratique de conception logicielle qui encourage à garder ses environnements iso. En effet, cette pratique nous amène à rédiger le code d’infrastructure de tous nos environnements en un seul exemplaire, sans duplication de code. Cela crée certes du couplage (logiciel) entre nos environnements, mais c’est un couplage désirable dans notre cas : une modification du code d’infrastructure appliquée à un environnement est immédiatement répercutée sur le code de tous les autres environnements, par design. Créer de la divergence entre les environnements accidentellement est plus difficile, alors que la divergence intentionnelle est toujours possible, en introduisant des structures conditionnelles délibérément dans le code, par exemple.
Environnements éphémères | Un peu de théorie
Vos environnements sont-ils des animaux de compagnie 🐈 ou du bétail 🐄🐄 ?
Commençons par une définition avant de décortiquer cette pratique. Le site ephemeralenvironments.io la décrit ainsi :
Un environnement éphémère est un environnement à la durée de vie courte qui permet de réaliser le déploiement d’une application en isolation [d’autres déploiements].
Idéalement, on souhaitera que ces environnements divergent le moins possible de l’environnement de production.
Ainsi, même si la partie précédente de cet article illustre le concept des environnements éphémères avec Terraform, on notera que cette pratique est agnostique d’un langage ou d’une technologie particulière. On notera aussi avec cette définition que cette pratique est une façon d’appliquer le principe “Pet 🐈 Vs. Cattle 🐄🐄” , non pas à des unités d’infrastructure (ex: 1 machine virtuelle) comme il est coutume de l’appliquer mais à des environnements complets.
Avoir un environnement qu’on appelle par son petit nom (“UAT”, par exemple), qui tourne 24h/24, que l’on maintient pour en prendre soin, qu’on a construit une fois au début du projet et qu’on serait incapable de détruire et reconstruire en un temps raisonnable (disons, 1 journée au plus) : tout cela évoque la définition du principe “Pet” tel que le décrivait Arnaud Mazin sur le blog OCTO il y a presque 10 ans déjà, rappelez-vous, c'était en 2016.
A gauche : des animaux de compagnie, et à droite : un troupeau
Ce phénomène que l’on observe ici a un nom, nous l’appelons l’approche « Pet ». Vous avez l’impression d’avoir affaire à des animaux de compagnie que vous appelez par leur petit nom, chouchoutez, dorlotez, à qui vous mettez un petit nœud sur la tête pour éviter que ses poils ne retombent sur ses yeux. – Arnaud Mazin, « pet vs. cattle », de l’artisan du serveur à l’artisan codeur (2016)
💡 Appliquer le principe “Pet” à nos environnements n’est pas nécessairement un mal : il semble de bon ton de l’appliquer à l’environnement de production qui vient souvent avec des niveaux de service élevés qui ne nous laissent pas le luxe de pouvoir le détruire régulièrement sans consommer utilement notre budget d’erreur. Si ces exigences ne s’appliquent pas aux autres environnements, il devrait être possible de les détruire à tout moment et d’en avoir un usage ponctuel, éphémère.
Les Review Apps, une façon d’utiliser ces environnements éphémères
Pour comprendre leur utilité, on peut aller chercher un usage des environnements éphémères du côté de GitLab qui proposait en 2016 le concept des Review Apps, décrit comme suit dans la documentation de GitLab-CI :
Une review app est un outil de collaboration qui prend la forme d’un environnement servant à montrer un changement (sur une application ou un produit) réalisé dans une feature branch.
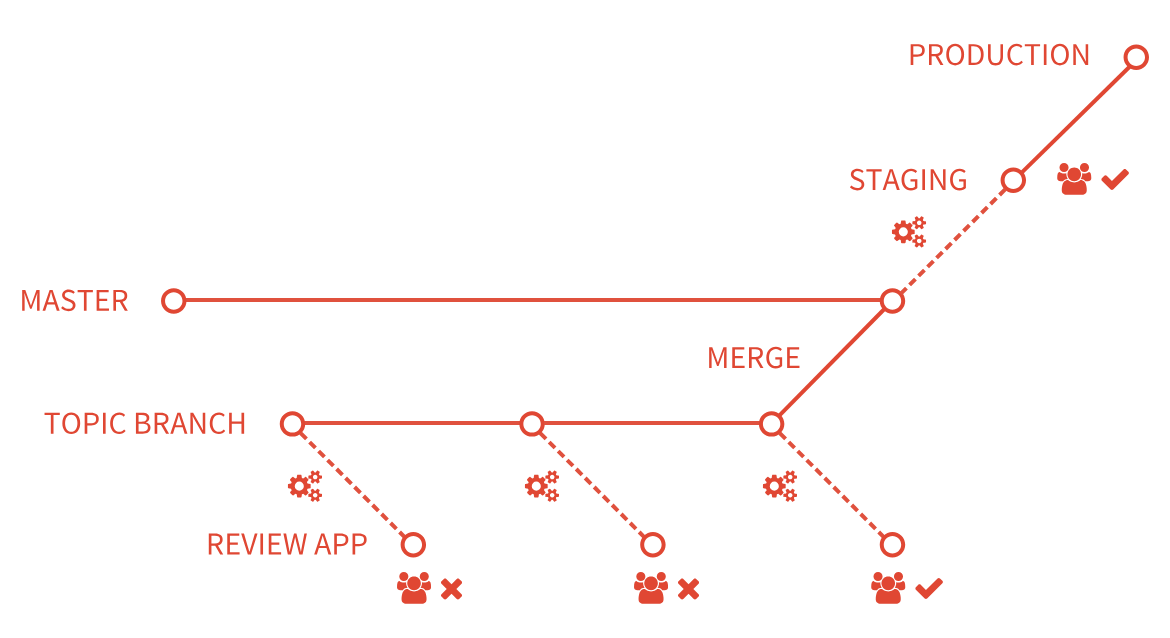
Illustration du concept de Review App selon GitLab - Source
La pratique consiste à produire un environnement de manière dynamique, en support d’une merge request (MR), afin d’obtenir du feedback non seulement de techniciens (pour la revue de code) mais aussi de designers ou de product managers (pour la revue de l’application). Le cycle de vie de l’environnement éphémère est alors couplé à celui de la MR :
- L’environnement est créé à l’ouverture de la MR
- L’application est reconstruite et redéployée à chaque push d’un commit sur la feature branch
- L’environnement est détruit à la clôture de la MR, quand il n’est plus utile
Il devient alors possible d’obtenir du feedback ou de tester une hypothèse sur le produit développé, sur son apparence graphique, sur une interaction, ou sur ses performances :
- Sans attendre pendant plusieurs sprints qu’une équipe ops/plateforme ait fini de monter un environnement pérenne dédié à la recette ou aux tirs de performance
- Sans avoir à attendre que l’environnement pérenne de recette ou de performance soit libre, car c’est une ressource souvent partagée entre plusieurs équipes pour faire des économies
- Avant d’avoir mergé du code dans la branche principale
- En isolation des autres travaux en cours
C’est une pratique qui permet aussi de tester régulièrement son PRA (plan de reprise d’activité) car on valide régulièrement notre capacité à déployer notre infrastructure en partant de zéro. De même, la pratique nous amène aussi à vérifier plus régulièrement notre capacité à détruire notre infrastructure. Cela peut sembler être un acquis, mais détruire un environnement même s’il est modélisé avec du code d’infrastructure peut échouer pour plusieurs raisons : si l'infrastructure déployée a trop dérivé du code, ou encore si des dépendances circulaires sont présentes dans le code quand des ressources d’infrastructure se référencent entre elles.
>💡On peut aussi imaginer un modèle où l’environnement éphémère n’est pas créé systématiquement** à l’ouverture de la MR. Certains changements triviaux ou simples à valider en local ne nécessitent pas toujours de créer de l’infrastructure avant de merger une feature branch. Dans ce modèle, l’environnement peut être créé à la demande, en self-service, en déclenchant manuellement un pipeline de déploiement sur la MR en question par exemple.
Environnements éphémères | Est-ce que je suis prêt ?
Si mettre en œuvre ces pratiques dans vos projets vous intéresse, voici quelques éléments à avoir en tête pour jauger l’effort à investir avant de vous lancer.
🔑🚚 Un pré-requis fort pour mettre en place simplement cette pratique est que l’équipe qui souhaite en bénéficier doit avoir la main sur ses ressources d’infrastructures. Si celle-ci doit demander à une autre équipe de créer des ressources via formulaires de demandes complexes interposés, cela va créer trop de friction et l’équipe ne sera pas assez autonome pour mettre en place cette pratique. Il est nécessaire que l’équipe puisse créer des ressources en autonomie, à n’importe quel moment, idéalement avec du code.
📝 🏗️ Rédigez votre code d’infrastructure de manière à ce que l’environnement soit un paramètre. Si vous avez l’habitude de suffixer ou tagger vos ressources en écrivant en dur le nom de l’environnement où elles vont être déployées, il va devenir nécessaire de variabiliser la référence à cet environnement. Pour illustrer avec un langage d’infrastructure-as-code commun, Terraform met à disposition la variable terraform.workspace pour connaître le nom du workspace actif au moment de lancer une commande.
resource "azurerm_resource_group" "this" {
name = lower("myapp-${terraform.workspace}") # évalué en myapp-pr-2727 dans le workspace "pr-2727"
location = var.location
tags = merge(var.tags, {
EnvironmentName = terraform.workspace,
})
}
📝 🤖 Rédigez vos pipelines CI/CD de manière à ce que l’environnement soit un paramètre. Idem, si vos pipelines CI/CD ne s’exécutaient qu’en réaction à l’activité de la branche principale (main ou master), mettre en place des review-apps nécessite d’exécuter vos pipelines de CI et de CD aussi sur vos feature branches.
💥 💣 Détruisez vos environnements. C’est un geste à mettre en place immédiatement si vous ne voulez pas être submergé par les coûts des ressources d’infrastructure qui s’entassent. Quelques implémentations vues sur le terrain :
- L’owner de l’environnement (ex: l’auteur de la feature branch associée) est responsable de son environnement. Il le détruit lui-même quand sa branche est mergée, en lançant une commande de destruction d’environnement depuis son poste
- L’owner de l’environnement détruit l’environnement lui-même quand sa branche est mergée en lançant un pipeline de destruction d’environnement paramétré, en se rendant dans la console de l’outil de pipelines ou via une API. On fournit dans ce cas une manière simple et standard à l’owner de détruire un environnement. Le paramètre de ce pipeline est l’identifiant de l’environnement, à saisir manuellement
- L’outil de pipelines réagit automatiquement à l’événement “branche mergée” par le déclenchement d’un pipeline de destruction d’environnement paramétré.
- Un pipeline de destruction de tous les environnements éphémères tourne à fréquence régulière (ex : tous les soirs, ou chaque weekend). Si ces environnements sont toujours utiles, ils pourront toujours être facilement reconstruits le lendemain par ceux qui en ont besoin.
- En bonus : être alerté
- quand ces pipelines de destruction échouent,
- ou quand des environnements éphémères existent depuis trop longtemps (ex: plus de 1 semaine),
- ou quand le budget alloué mensuellement pour l’infrastructure éphémère dépasse un seuil FinOps prédéfini.
📦 ✂️ Travailler par petits lots. Si ces environnements ont vocation à vivre aussi longtemps que les feature branch, on ne peut les appeler “éphémères” si ces branches restent ouvertes pendant des semaines ou des mois. Au-delà de l’outillage technique et des pipelines automatiques à mettre en place, il y a un enjeu méthodologique à travailler en short-lived branches et découper son travail en petits lots.
Quid de la donnée ?
Le lecteur attentif remarquera que l’aspect éphémère des environnements s’applique aussi à la donnée : en détruisant un environnement, on supprime aussi les données qui s’y sont accumulées en s’en servant. Hors, dans certaines situations, un environnement peut être inutilisable sans donnée. Il peut être en effet difficile de réaliser des tirs de charge réalistes, d’entraîner un modèle de Machine Learning ou de générer des rapports de BI dans un environnement aux bases de données et autres marts vierges.
Si ces données ne peuvent être générées simplement, la pratique des environnements éphémères nécessitera de mettre en place un mécanisme pour alimenter ces environnements en données, avec par exemple :
- Un injecteur capable d’alimenter une base de données avec un jeu de données construit par un expert du domaine (SME) ou bien un jeu de données générés
- Un simulateur capable d’alimenter une base de données avec un jeu de données généré en suivant une distribution de probabilité vraisemblable
- Un extracteur capable d’alimenter une base de données avec un jeu de données dupliqué depuis l’environnement de production afin de travailler avec de la donnée réelle provenant du terrain
- ⚠️ On notera les précautions d’usage à avoir au moment de manipuler des données de production : tous les environnements ne sont pas prévus pour accueillir de la donnée de production, des cadres légaux et de régulation doivent être respectés selon la nature des données manipulées.
Plus de détails sur la gestion des données à des fins de tests sont abordés dans cet article : La gestion des données de tests en Delivery de Machine Learning.
Environnements éphémères | Retours d’expérience
Voici quelques retours d’expérience de projets où cette pratique a été éprouvée. Nous aborderons dans cette dernière partie des éléments méthodologique, technique mais aussi financier 💰 et green 🌱.
Retour d’expérience #1 - Mise en place avec Terraform et Azure Devops
Dans ce contexte, l’infrastructure est instanciable à la demande, l’architecture est composée de services managés sur Azure avec une majorité de services serverless (Azure functions, bases de données managées, …). L’effectif est composé de 15 personnes (tech, POs, PM, concepteur UX) répartis en domaines métier sur 3 équipes dès le 1er jour. La gestion de l’infrastructure est une responsabilité commune à tous les profils tech de ce dispositif.
| Décisions et cycles de vie d’un env éphémère | Implémentation |
|---|---|
| 🧓 Nombre d’environnements pérennes | 2 : la production, et un environnement nommé “DEV”. Note: A posteriori, cet environnement “DEV” était mal nommé, nous en parlerons plus tard dans cet article. |
| 🦋 Nombre d’environnements éphémères | ~400 en 6 mois, pour une équipe qui a démarré avec ~10 contributeurs sur la base de code dès le 1er jour du projet |
| 🛖 Quelle forme prend-il ? | Un environnement éphémère prend la forme d’un workspace dans le code Terraform, et est délimité par un resource group dans l’infrastructure Azure |
| 🏗️ Création de l’environnement | A l’ouverture d’une pull request, pour merger une feature branch dans la branche main : - Un pipeline Azure DevOps construit et package l’application, - Puis créé un workspace Terraform, - Puis déploie l’infrastructure éphémère avec Terraform dans ce workspace - Puis déploie l’application dans cet environnement avec Terraform |
🏷️ Convention de nommage de l’environnement éphémère | Concaténation de “pr” (pour “pull request”) + l’identifiant unique de pull request, par exemple : pr51000 pour la 51000e pull request dans l’organisation Azure DevOps |
| 🆕 Quand mettre à jour l’environnement éphémère | A chaque commit poussé sur cette branche, tant que la PR est ouverte |
| 💥 Destruction de l’environnement éphémère | Quand la PR est mergée dans main, un pipeline de destruction d’environnement se déclenche automatiquement et récupère l’identifiant de la dernière pull request mergée dans main par API. On connaît ainsi le nom de l’environnement à détruire avec le code d’infrastructure |
| 💥💥 Destruction de tous les environnements éphémères | Quand ils ne sont pas utiles ou utilisés, tous les environnements éphémères sont détruits via un pipeline planifié qui s’exécute chaque soir à 20h, car nous ne travaillons pas la nuit 🌃 Nous appliquons une Regex sur les noms de tous les resource groups actifs pour connaître les identifiants des environnements à détruire. Un pipeline de destruction d’environnement est déclenché dans Azure Devops pour chaque identifiant récolté à des fins de traçabilité |
Retour d’expérience #2 | Mise en place avec Kubernetes et GitLab-CI en contexte on-premise
Dans ce contexte, l’infrastructure n’est pas instanciable à la demande. 5 machines virtuelles sont mises à disposition de l’équipe pour couvrir tous les besoins de développement. L’effectif a évolué de 3 à 10 développeurs et ops sur 1 an. Deux équipes de développement collaborent en proximité avec une équipe de 2 ops.
| Décisions et cycles de vie d’un env éphémère | Implémentation |
|---|---|
| 🧓 Nombre d’environnements pérennes | 2 : l’environnement DEV et la production |
| 🦋 Nombre d’environnements éphémères | Plusieurs dizaines par mois, pour une équipe passée progressivement de 3 à 10 personnes sur 1 année |
| 🛖 Quelle forme prend-il ? | Un namespace dans un cluster Kubernetes |
| 🏗️ Création de l’environnement | A l’ouverture d’une pull request, pour merger une feature branch dans la branche master : - un pipeline GitLab-CI package les applications Java, - puis créé un namespace Kubernetes, - puis déploie l’infrastructure éphémère dans ce namespace, - puis déploie des microservices applicatifs dans cet environnement Note : tous les environnements partagent la même base de données. Des tables suffixées avec le nom de l’environnement sont créées dans la base de données pour bénéficier d’une isolation sur la donnée (ex: une table compensation_financiere_abc_3128 pour avoir une table compensation_financiere dédiée à l’environnement abc_3128) |
| 🏷️ Convention de nommage de l’environnement pérenne | Concaténation de “ABC” (pour le nom de code du projet) + l’identifiant unique de ticket dans Jira, par exemple : abc_3128 pour le ticket 3128 dans Jira |
| 🆕 Quand mettre à jour l’environnement éphémère | A chaque commit poussé sur cette branche, tant que la MR est ouverte |
| 💥💥 Destruction de tous les environnements éphémères | Tous les namespaces hors dev et prod sont détruits via un pipeline planifié qui s’exécute chaque vendredi à 20h |
💡Le lecteur attentif remarquera dans ces deux retours d’expérience que, même si le titre de cet article encourage à n’avoir qu’un seul environnement pérenne (la production), ces deux expériences mentionnent la présence de 2 environnements pérennes : la production et un environnement “DEV”.
Dans les deux cas, cet environnement “DEV” est mal nommé : les développeurs utilisaient des environnements éphémères pour leurs besoins de développement quotidiens. Comme beaucoup de choses en informatique, nous avons posé un nom sur cet environnement en début de projet et nous n’avons jamais pris le temps de remettre en question ce nommage (et la raison d’être de cet environnement).
C’est un environnement qui a subsisté par son côté pratique : étant persistant, cet environnement “DEV” pouvait contenir des jeux de données métier réalistes, difficiles à (re)construire, stockés en bases de données ou sous la forme de fichiers sur un serveur. Ces données étaient pratiques pour réaliser des scénarios de démo complexes. La présence de ces données permettait aussi de mettre en évidence certains problèmes (performance, migration de données, …) difficiles à percevoir dans des environnements éphémères vierges de données à leur création.
Dans ces deux contextes, l’environnement “DEV” aurait pu être détruit pour être remplacé par un injecteur de données (voir partie “Quid de la donnée” plus haut dans l’article).
1 environnement pérenne, ça me coûte déjà cher, si je crée 1 000 environnements ce mois-ci, mes coûts vont exploser 📈 ?
On pourrait intuitivement penser qu’avoir des environnements éphémères est coûteux : si l’environnement de production, pérenne, coûte 1 000€ par mois et que je construis 10 autres environnements, est-ce que je vais devoir payer 10 000€ de facture cloud ce mois-ci ?
Ce raisonnement ne prend pas en compte que les environnements en question sont éphémères et que les modèles de facturation sur le cloud sont souvent basés sur le paiement à l’usage des ressources déployées ou à leur durée de vie. Un environnement éphémère peut donc être moins gourmand qu’un environnement pérenne si le modèle de facturation cloud le permet, si sa durée de vie est suffisamment courte ou si les besoins en ressources sont moindres.
Voici quelques abaques mesurées sur le retour d’expérience #1 ci-dessus, sur Azure, sur 6 mois d’étude. L’infrastructure d’un environnement était composée, entre autres : d’une App Service, une demi-douzaine d’Azure Functions, une base de données Postgres managée, un broker de messages Azure Event Grid, de stockage Azure Blob storage.
- 400 environnements éphémères ont été produits, pour une équipe de 10 personnes
- Le coût d’un environnement a augmenté au fil du temps, à mesure que l’architecture du projet s’est étoffée itérativement, juste à temps
- 89 environnements ont coûté entre 0 et 1 euro, ils ont vécu en général une demi-journée
- 145 environnements ont coûté entre 1 et 10 euros, ils ont vécu entre une demi-journée et quelques jours
- Une trentaine ont coûté plus de 100 euros : il s’agissait d’environnements qui ont vécu plusieurs semaines, soit pour réaliser des tirs de performances, soit parce que la fonctionnalité associée n’était pas assez bien cadrée et s’est avérée plus longue à développer que prévue. Le standard de l’équipe était de découper ses tâches de manière à ce qu’elles puissent être terminées en 2 jours (ouvrés) maximum.
- L’environnement de production était pérenne, son coût sur 6 mois était de $2,830 dollars
- L’environnement DEV était aussi pérenne mais légèrement sous-dimensionné par rapport à la production, son coût sur 6 mois était de $2,750 dollars
Les économies réalisées sur cette période peuvent être calculées en comparant sur la même période :
- le coût financier des environnements éphémères (~$10,400 cumulés) avec
- le coût financier d’avoir plusieurs environnements pérennes, auquel on peut additionner le nombre de jours passé par les équipes de développement à attendre quand ces environnements ne sont pas disponibles (parce qu’une autre équipe s’en sert par exemple) mais aussi d’autres coûts liés au total cost of ownership comme le temps passé à maintenir ces environnements, appliquer des patchs de sécurité sur l’infrastructure, s’assurer qu’ils restent iso-production, …
- Par exemple dans ce contexte, avoir 6 environnements pérennes (Sandbox, DEV, UAT-1, UAT-2, STG et PROD) aurait produit une facture de consommation cloud de 6 * $2,830 = $16,980 à laquelle il faudrait rajouter les autres coûts cités ci-avant.
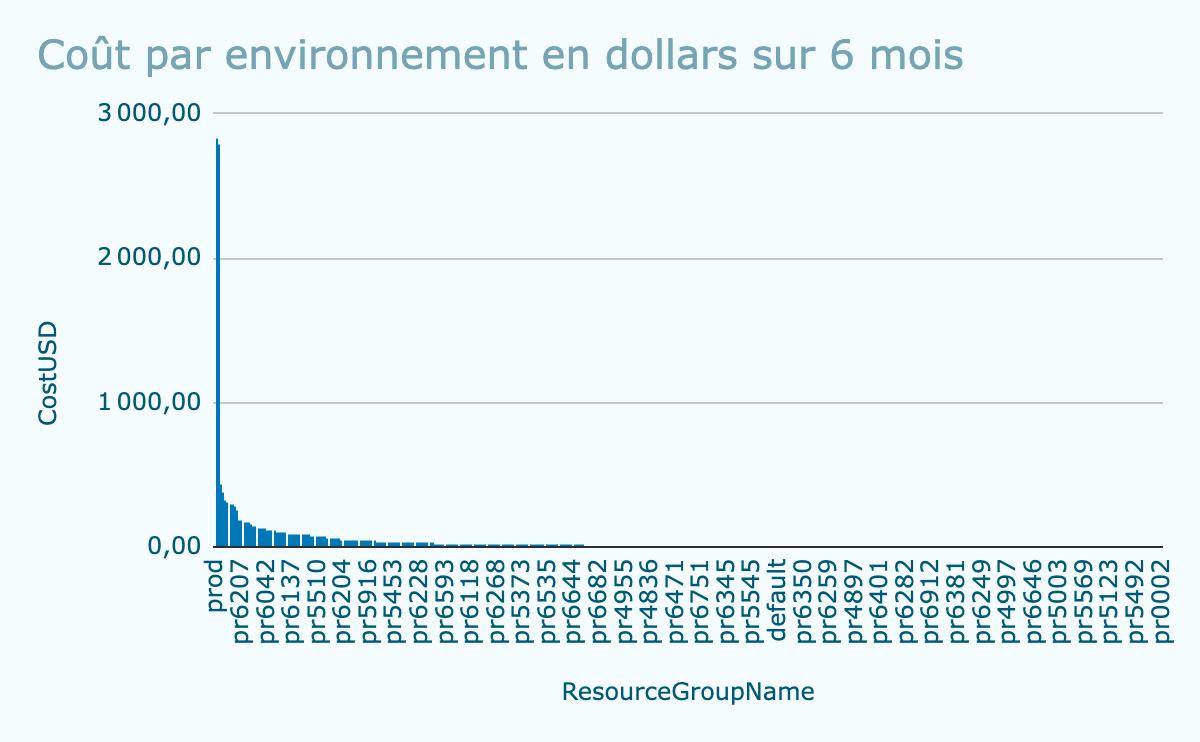
Coût en dollars par environnement sur ce projet, lors des 6 premiers mois, extrait dans le service Microsoft Cost Management sur Azure. L’ensemble des 400 environnements ne figurent pas en abscisse par manque de place.
🌱 Les environnements éphémères, une pratique responsable vis-à-vis de … l’environnement ? 🥁
Il peut être légitime de se demander quelle approche est plus consommatrice en énergie. À ce jour, il est compliqué d'apporter une réponse définitive à cette question par manque d’indicateurs fiables à mesurer et suivre : si nos fournisseurs cloud nous permettent de suivre le coût financier des services que nous utilisons chaque mois, ils ne fournissent pas à ce jour de suivi de la consommation énergétique. (Edit: le service Azure Carbon Optimization actuellement disponible en preview semble combler ce vide, cela mériterait d’être creusé).
Intuitivement, on peut penser que la pratique des environnements éphémères est une pratique qui invite à la sobriété : un environnement éphémère n’existe que le temps où celui-ci est utile, et le temps où un environnement pérenne n’est pas utilisé peut être perçu comme de l’énergie gaspillée et irrécupérable.
A priori, un environnement pérenne (hors production) allumé 24 heures sur 24 est inactif pendant une plus grande partie de l'année qu'il n'est actif. Toutefois, comparer le temps d’usage entre un environnement pérenne et un environnement éphémère de cette façon est simpliste : en pratique, nous sommes amenés à déployer plusieurs environnements éphémères en parallèle, pour chaque tâche nécessitant une revue.
Voici une illustration, schématique, pour essayer de se représenter le temps d’activité d’un environnement pérenne et de plusieurs environnements éphémères sur un projet de 6 mois.
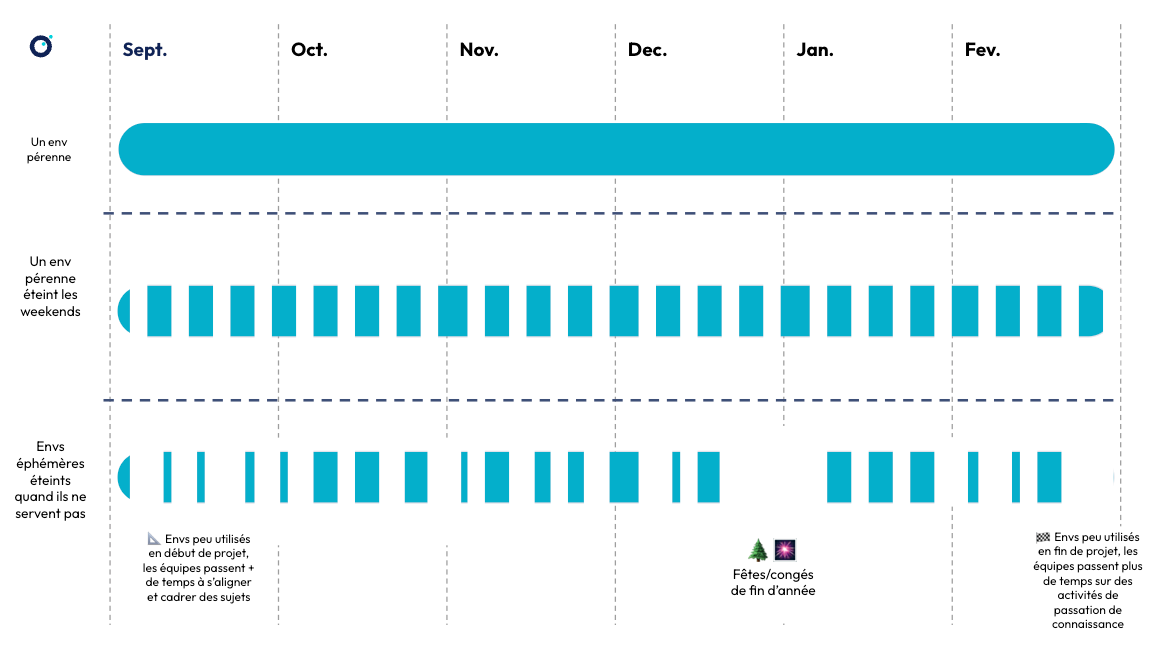
Légende : Comparatif schématique entre temps de disponibilité d’un environnement pérenne et temps de disponibilité cumulé de tous les environnements éphémères sur une période de 6 mois. De haut en bas :
- Modèle #1 : on fait l’hypothèse que l’environnement pérenne est actif 100% du temps (actif 7 jours par semaines),
- Modèle #2 : on fait l’hypothèse que les SLA de l’environnement pérenne permettent de l’éteindre le week-end (actif 5 jours par semaine)
- Modèle #3 : on fait l’hypothèse que les environnements éphémères sont actifs quand il y en a besoin (actifs 4h par jour en moyenne sauf les weekends et pendant les congés de l’équipe) et que les tâches de l’équipe sont découpées en lots suffisamment petits.
Enfin, on notera un dernier élément pour répondre au problème posé : au-delà de l’usage d’un environnement, est-ce que créer un environnement est coûteux en énergie ? Les valeurs qui suivent sont schématiques et ne servent qu’à illustrer la problématique : si un environnement actif consomme 1 kg équivalent CO2 (kgCO2) par jour et que créer un environnement nécessite 15 kgCO2, il est alors peut-être contre-productif d’allumer et éteindre un environnement chaque soir. Le processus optimal serait alors de détruire nos ressources 1 fois par sprint de 2 semaines.
A cette équation difficile vient se rajouter que les cloud providers mettent peut-être en place des mécanismes pour optimiser globalement la consommation de leurs clients, et que notre proactivité locale à éteindre ces services la nuit est peut-être contre-productive. C’est le cas par exemple d’AWS qui met en place un mécanisme de “freeze” sur les lambda déployées pour optimiser la consommation des ressources lorsque les fonctions ne sont pas invoquées, rendant peut-être certaines optimisations locales (comme détruire les lambda quand elles ne sont pas utiles) contre-productives. Là encore, il est compliqué d'apporter une réponse définitive à cette question par manque d’indicateurs fiables à mesurer et suivre.
Conclusion
La pratique des environnements éphémères représente un changement de paradigme fort dans la gestion de l’infrastructure. Bien que la mise en place d'environnements éphémères nécessite un investissement initial en termes d'outillage et de méthodologie, les bénéfices en termes d’agilité, de vitesse de delivery ou de vitesse d’expérimentation peuvent être considérables.
Modéliser ses environnements anté-prod de façon éphémère peut aider à limiter la charge cognitive des équipes en charge de les maintenir et expérimenter plus librement sur l’infrastructure. Avoir moins d’environnement pérennes à maintenir permet aussi de réduire le chemin à parcourir pour aller en production, réduire les coûts et avoir potentiellement un usage plus sobre de son infrastructure.
Bien sûr, s’engager dans cette pratique peut être ambitieux : l’Agilité, DevOps, modéliser son infrastructure avec du code, maîtriser ses pipelines CI/CD sont des pratiques essentielles à maîtriser avant de s’y essayer. Refactorer son code d’infrastructure pour passer d’un fonctionnement d’environnements pérennes avec de la duplication de code vers un fonctionnement éphémère peut aussi présenter de nombreux défis :
- Convaincre les utilisateurs habitués à ces environnements pérennes de changer de paradigme,
- Poser des tests de caractérisation sur l’infrastructure, idéalement automatisés,
- Mais aussi peut-être migrer des fichiers d’états,
- Ou encore réconcilier les écarts entre les environnements non-iso.
Et vous, est-ce que vous avez déjà sauté le pas de pet à cattle pour vos environnements ? Sinon, est-ce que vous êtes prêt à vous lancer ? N’hésitez pas à me contacter pour en discuter, vos retours d’expérience m’intéressent !
🔗 Annexes | Pour aller plus loin
- opentofu/opentofu issue #2160 ouverte par apparentlymart : Deprecate (and eventually remove?) the concept of "workspaces"
- L’auteur de l’issue rappelle en quoi consiste la fonctionnalité des workspaces Terraform
- Et il pose un regard critique sur l’intérêt de la porter (ou non) dans le fork OpenTofu
- Review Apps | Gitlab
- ephemeralenvironments.io | Shipyard
- Ephemeral Environments And DORA Metrics | Shipyard
- De l’impact de la pratique des environnements éphémères sur les indicateurs DORA
- Why you should use ephemeral environments when you do serverless | Yan Cui aka TheBurningMonk, AWS Serverless Hero, 2019
- How to handle serverful resources when using ephemeral environments | Yan Cui aka TheBurningMonk, AWS Serverless Hero, 2023
- TheFrugalArchitect.com | Blog de Werner Vogels, CTO @ Amazon, qui porte sur l’éco-conception d’architecture
- Keynote de Werner Vogels @ AWS Re:Invent 2023 | à propos de la démarche d’éco-conception d’AWS concernant les services S3 et Lambda
- Ship / Show / Ask (Rouan Wilsenach @ martinfowler.com)