Entre pixels et réalité : notions clés des formats d'images
ℹ️ Lien pour retrouver l’ensemble des articles de cette série “Entre pixels et réalité”

Vous en avez déjà entendu parler. Nous-même, on l’a évoqué dans les précédents articles sans rentrer dans les détails. Avec des “on vous en parlera plus tard”, ou encore des “on développera plus dans un prochain article” c’est enfin le moment d’aborder les formats d’image… enfin presque. Pour être sûr que l’article soit accessible à tous, autant pour les novices que pour les plus aguerris, on souhaite passer en revue un certain nombre de notions nécessaires à la compréhension des formats d’images. Et comme on sait que lorsqu’un article dépasse 15 mins de lecture, cela en décourage plus d’un, nous avons décidé de couper l’article en 2, l’un abordant les notions importantes à savoir pour comprendre ce qu’est un format et quelles en sont toutes les composantes, et un autre qui présentera les différents formats d'images qui existent aujourd’hui et comment faire votre choix en fonction de votre besoin.
Type d’image
On distingue 2 catégories : Image matricielle et l’image vectorielle
L’image matricielle, aussi appelée le bitmap, est composée de pixels (petits points de couleur). Chaque pixel contient des informations de couleur. La qualité de l’image dépend de la résolution. Plus on zoome, plus on perd en qualité (pixellisation).
L’image vectorielle, quant à elle, est construite à partir de formes géométriques (vecteurs) comme des lignes, courbes, polygones. Elle est redimensionnable à l’infini sans perte de qualité. Taille légère et modifiable facilement. Même s’il est très rare d'utiliser des formats vectoriels, le plus utilisé de nos jours est certainement le SVG. Ce format est largement utilisé dans des domaines tels que la publication numérique, le design graphique, la cartographie ou encore la data visualisation. Ces secteurs nécessitent des images capables de conserver une excellente qualité, quel que soit le niveau de zoom ou la taille d’affichage. Grâce à sa nature vectorielle, un SVG reste parfaitement net aussi bien en miniature qu’en gros plan, sans perte de précision. C’est pourquoi ce format est régulièrement utilisé pour des logos et illustrations.

Profondeur de couleur
Aussi connue sous le nom de “Bit depth” ou “Color depth”, elle représente le nombre maximum de couleurs que peut contenir un pixel. Elle s’exprime en bits par pixel (BPP).
Plus le nombre de bit par pixel est élevé, plus l’image contiendra de nuances de couleur. Les configurations les plus connues sont:
- 8 bits: 256 couleurs
- 16 bits: 65 536 couleurs, aussi appelées “High Color”
- 24 bits: 16,7 millions de couleurs, aussi appelé "True Color", configuration standard pour JPEG et PNG
- 32 bits: 24 bits de couleur + 8 bits pour le canal alpha qui gère la transparence, correspond au format RGBA

À savoir qu’il existe d’autres configurations bien supérieures à 16 bits, qui sont utilisées par exemple dans l'imagerie à grande gamme dynamique (ou imagerie large-gamme) (high-dynamic-range imaging ou HDRI). Le HDR (High Dynamic Range) est une technique d’imagerie qui permet de capturer ou afficher beaucoup plus de détails dans les zones très claires et très sombres d’une image. Contrairement à une image standard (aussi appelée image SDR – Standard Dynamic Range) où il est difficile de voir tous les détails à la fois des zones très claires ET des zones très foncées. Le plus souvent, soit les zones claires sont trop surexposées, soit les zones d’ombres sont trop sombres. Pour faire des images HDR, cela nécessite des appareils adaptés capable de faire des images avec une profondeur de couleur supérieur à 32 bits. Cependant certains appareils numériques permettent de faire ce rendu grâce à leur logiciel qui combine plusieurs photos prises avec différentes expositions.
Canal alpha et transparence
Aussi appelé “Alpha channel”, il représente le niveau de transparence pour chaque pixel. C’est apparu dans les années 80 notamment avec le format TIFF, mais cela a surtout été démocratisé avec le PNG dans les années 90.
Souvent visualisé comme une couche supplémentaire de couleur, il peut être illustré par une image où une partie est transparente (permettant de voir l'arrière-plan à travers elle) et une autre est opaque. Cela permet de gérer la superposition d’éléments graphiques tels que d’autres images, textes, etc. Typiquement, une image PNG avec un fond en damier gris et blanc dans un logiciel d'édition (comme Photoshop) est l'illustration la plus courante pour indiquer qu'il n'y a pas de couleur de fond (c'est-à-dire que le canal alpha est activé).

Compression
À l’exception des formats bruts (aussi connus sous sa désignation “raw”), la compression est un mécanisme qui a pour but de réduire le poids du fichier d'une image, afin de faciliter et d'accélérer son chargement, son téléchargement et son partage sur Internet. En effet, une image compressée est plus légère, elle a besoin de moins de ressources pour s’afficher. Cela permet ainsi une meilleure expérience à l’utilisateur, car il attend peu que l’image se charge et de ce fait permet un meilleur de taux de conversion et un meilleur référencement (SEO). Mais, la compression présente des avantages qui vont au-delà de l'usage internet. Elle permet un gain en termes de poids de stockage et facilite ainsi le transfert des ressources allégées.
Il existe 2 genres de compressions : avec perte (lossy) et sans perte (lossless).
La compression avec perte consiste à réduire la taille d’une image en supprimant certaines informations visuelles jugées peu ou pas perceptibles pour l’œil humain. L’objectif est d’alléger le fichier tout en conservant une qualité visuelle acceptable.
La première étape consiste à analyser l’image afin d’identifier les zones où apparaissent de très faibles variations de couleurs. Dans ces régions, les pixels de couleurs proches peuvent être fusionnés ou simplifiés. Les dégradés deviennent alors moins progressifs, ce qui peut parfois provoquer l’apparition de bandes de couleurs visibles. Ce phénomène est appelé banding.
Ensuite, certains algorithmes transforment l’image en fréquences spatiales grâce à des techniques mathématiques comme la Discrete Cosine Transform. Cette opération sépare l'image en deux parties : les informations générales (basses fréquences) comme les grandes surfaces de couleur et les formes principales, et les détails (hautes fréquences) comme les textures ou les bords précis.
Lors de la compression, les informations associées aux hautes fréquences sont généralement simplifiées ou réduites, car elles contribuent moins à la perception globale de l’image. Cette étape est suivie d’une quantification, qui consiste à réduire la précision de certaines valeurs afin de diminuer encore la quantité de données à stocker.
Enfin, les données restantes sont encodées afin de produire un fichier plus léger. Contrairement à la compression sans perte, la compression avec perte est irréversible : une fois les informations supprimées, il n’est plus possible de reconstruire parfaitement l’image originale.
La compression sans perte quant à elle, est réversible. Elle est composée d’une succession d’étapes qui permet, lors de la décompression de l’image, d’être restituée comme avant la compression. Il y a comme étapes :
- Le pré-traitement / la prédiction: une phase d’analyse qui va comparer les pixels entre eux. Lors de ce traitement, l’algorithme va partir d’un pixel connu (pixel1) et va essayer de prédire quel sera le pixel suivant (pixel2). Alors, il ne va enregistrer que la différence entre la prédiction et la valeur réelle du pixel 2. Ces différences sont souvent petites (proches de zéro), ce qui facilite leur compression. Par exemple : pour une zone de couleur unie, les différences entre pixels sont très faibles — ce qui génère beaucoup de redondance compressible.
- Encodage des redondances: Une fois les données transformées par prédiction, on applique des techniques classiques de compression sans perte :
- Run-Length Encoding (RLE) : Remplace les séquences longues de mêmes valeurs par une notation compacte (ex. au lieu de AAAABBBB, on écrit 4A4B).
- Codage entropique (Huffman, codage arithmétique): Attribution de codes courts aux motifs fréquents et codes longs aux motifs rares, ce qui réduit la taille globale du flux binaire .
- Algorithmes de type LZ (LZ77 / LZSS) : Identifient des séquences répétées dans l’image et les remplacent par des références au lieu de réécrire les mêmes données (ex: 11111 devient (distance = 1, longueur = 5).
Chacune des étapes est réversible ce qui explique que le processus soit réversible.’
Dans un algorithme moderne, comme celui utilisé par PNG, on combine plusieurs de ces techniques pour maximiser la compression sans perte.

Encodage / Décodage
L’encodage d’une image est le processus qui transforme les données brutes de l’image en une représentation numérique standardisée (de type JPEG, PNG, Web ou autres). L’objectif est de réduire la quantité de données à stocker ou à transmettre, tout en conservant autant que possible une qualité visuelle acceptable de l’image. 
Ce processus inclut plusieurs phases, dont l’une des plus connues et la plus importante, la compression. Mais nous retrouvons aussi d’autres phases comme la phase de conversion : l’image RGB (Red-Green-Blue) en image YCbCr (Y = luminance autrement dit la sensation de clarté, ou de luminosité, qu'une surface produit dans les yeux de l'utilisateur, Cb= chrominance, composante bleu, Cr: composante rouge). Cette phase a pour but de séparer la lumière de la couleur. L'œil étant plus sensible à la luminance qu’à la couleur, lors de la compression, on va chercher à garder un maximum de luminance et on va rogner/ dégrader les couleurs.
Après compression, on encapsule les données dans un format de fichier qui contient :
- Les données d’image compressées,
- Les métadonnées (EXIF, profils de couleur),
- Des marques de structure (en-têtes, tables, …).
Le décodage est le processus inverse de l’encodage : il consiste à lire une image compressée ou encodée dans le format choisi et à reconstruire les pixels originaux ou une approximation visuelle pour pouvoir afficher l’image à l’écran ou la traiter. 
Pour être affichée à l’écran ou imprimée, une image numérique doit être représentée sous la forme d’une grille de pixels, chaque pixel correspondant à une couleur précise. Cependant, les formats modernes d’image compressés ne stockent pas directement cette grille. Ils enregistrent l’image sous une forme compressée. Avant l’affichage ou l’impression, le fichier doit donc être décodé afin de reconstruire la grille de pixels pour reformer une image exploitable.
Les formats compressés (JPEG, PNG, etc.) ne sont pas directement lisibles comme une grille de pixels : il faut d’abord les décoder pour obtenir l’information visuelle.
Chargement d’une image
Ici on aborde le chargement de l’image dans la page d’un navigateur.
On distingue plusieurs types de chargements:
Chargement classique (eager loading) : C’est le comportement par défaut :l’image est chargée immédiatement lorsque la page est chargée.Toutes les images présentes dans le HTML sont téléchargées dès le rendu initial.
Lazy Loading (chargement différé) : L’image est chargée uniquement lorsqu’elle devient visible dans la zone d’affichage (aussi appelée le viewport). Cette méthode présente plusieurs avantages notamment améliore la performance, réduit le temps de chargement initial, diminue l’usage de bande passante.
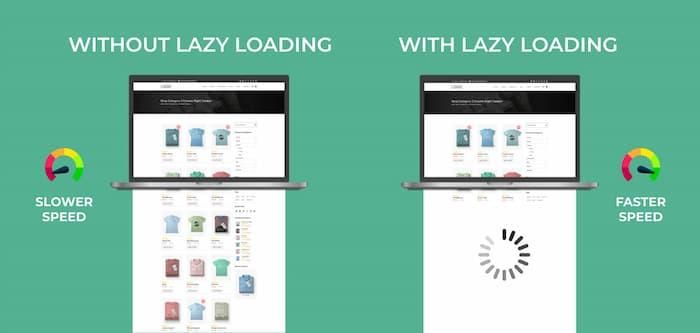
- Preloading (préchargement) : Permet d’indiquer au navigateur de charger une image avant qu’elle soit utilisée, car elle est importante. Cette méthode est utilisée pour les images considérées comme clefs (bannières, grande image principale, …), et pour améliorer le Largest Contentful Paint (LCP).
Affichage de l’image
En fonction du format choisi de l’image, plusieurs stratégies d’affichage sont possibles (attention, en anglais pour l’affichage, on parle aussi de chargement / loading):
- Décodage progressif par résolution :
- Principe : L'image apparaît d'abord très floue, en basse résolution (dite coarse), puis gagne progressivement en détail et en netteté (jusqu'à la fine résolution) à mesure que de nouvelles couches de données sont téléchargées et décodées.
- Avantage : Permet à l'utilisateur de percevoir rapidement le contenu global de l'image (le skeleton), ce qui est crucial pour la métrique de performance web LCP.

- Décodage progressif par qualité :
- Principe : L'image est affichée dans sa résolution finale dès le début, mais avec une faible qualité visuelle (très compressée ou bruitée). Au fur et à mesure du téléchargement, la qualité et la fidélité des couleurs augmentent progressivement jusqu'à atteindre la qualité maximale du fichier.
- Avantage : L'utilisateur voit l'image à sa taille finale immédiatement, éliminant les changements de mise en page (Cumulative Layout Shift, CLS) potentiels.

- Streaming-Friendly (Décodage progressif par octets ou Baseline loading) :
- Principe : Le format JXL est conçu pour le streaming efficace. Cela signifie que le décodeur peut commencer à traiter et afficher l'image dès qu'il reçoit les premiers octets, sans attendre la fin complète du fichier.
- Avantage : Maximise l'utilisation de la bande passante et minimise la latence perçue, car le rendu commence presque instantanément après le début du transfert. Il est idéal pour des connexions lentes ou des images très volumineuses.

- Chargement adaptatif (Responsive Images):
- Principe: Le navigateur choisit automatiquement l’image adaptée selon les conditions du terminal de l’usager. Si les conditions changent en cours de visionnage, la qualité peut être adaptée. Les caractéristiques qui vont être étudiées:
- Vitesse de connexion internet
- Puissance de l’appareil
- Taille d’écran
- Résolution
- Densité de pixels
- Avantages: Permet de réduire le temps de chargement, d’économiser sur la bande passante, d’éviter des interruptions ou des problèmes de chargement et par conséquent améliorer l’expérience utilisateur. L’article sur le chargement adaptatif du site MDN illustre bien comment fonctionne le chargement adaptatif.
Compatibilité et fallback
On parle de compatibilité lorsqu’on cherche à savoir si une technologie ou un programme fonctionnera sur tel device ou tel navigateur. Dans un idéal, chaque site ou application doit être accessible à tous les utilisateurs peu importe leur terminal, leur navigateur ou leur connexion. La réalité est tout autre. Chaque image a un format particulier qui peut ne pas être compatible avec un navigateur ou un terminal. C’est souvent le cas des formats récents : ils ne sont pas toujours compatibles avec tous les navigateurs/terminaux et s’ils le sont, c’est avec les versions les plus récentes. Pour vérifier la compatibilité, on peut s’appuyer sur des sites/outils comme CanIUse ou Baseline.
Le site CanIUse permet d’avoir beaucoup de détails sur la compatibilité par rapport aux différents navigateurs ordinateur dit “Desktop” et smartphone dit “Mobile”. Il se résume souvent par le pourcentage de couverture. Ce chiffre est parfois trompeur, il peut être difficile à interpréter.
Baseline du W3C fournit des informations claires sur les fonctionnalités des plateformes web qui fonctionnent sur tous les navigateurs. C’est un bon système pour avoir une bonne vision synthétique sur la compatibilité.
Le Baseline indique uniquement si la fonctionnalité est prise en charge par tous les navigateurs récents. Il ne donne aucune information sur l 'accessibilité (y compris le support des lecteurs d'écran), l'expérience utilisateur (UX), ni la performance.
Dans les faits, Baseline complète les informations de CanIUse et interprète de manière ternaire le risque (quasi nul, modéré ou important) que l'on prend à introduire une nouvelle fonctionnalité (dans notre cas, un nouveau format d'image) sur le web.
En pratique, il se concrétise en 3 niveaux, clair et court :
- “Largement disponible” ⇒ sûr, car : support stable dans tous les navigateurs depuis ~2,5 ans (soit 30 mois).

La fonctionnalité est donc être utilisée sans stratégie spéciale.
- “Nouvellement disponible” ⇒ utilisable, mais récent, car : fonctionne dans les versions stables actuelles de tous les navigateurs.Peut échouer sur vieux appareils / vieux OS / vieux navigateurs.
C’est pour être utilisé pour des terminaux modernes, mais cela reste potentiellement encore de côté les vieux terminaux
- “Disponibilité limitée” ⇒ dangereuse en production, car : pas supporté par tous les navigateurs majeurs et certains utilisateurs vont casser immédiatement.

C’est donc soit à éviter, soit il doit impérativement avoir une mise en place de système de protection de type fallback, polyfill lourd.
Baseline est de plus en plus disponible, car il est disponible dans CanIUse et dans les pages de MDN.
Durant les Lightning talks de Paris Web 2025, on a pu voir : « Avez-vous la base(line) ? » par Nicolas Arduin pour nous parler de l’utile https://baseline.nicool.fr/, c’est peut-être un site temporaire en attendant c’est bien pratique pour avoir des informations sur une fonctionnalité. Voilà un exemple avec le format WebP :

Lorsqu’on choisit une solution qu’on sait incompatible pour un certains nombres d’utilisateurs, on doit mettre en place une solution de repli, ce qu’on appelle un fallback. Dans un souci de performance, d’amélioration de l’expérience utilisateur, on peut vouloir utiliser des formats récents avec des meilleures performances d’encodage et/ou décodage. Mais cela ne doit pas se faire au détriment de l’information apportée à l’utilisateur.
Typiquement dans le cas d’un site internet qui souhaite afficher des images au format AVIF, si on sait qu’on a des utilisateurs qui utilisent des versions de navigateurs antérieurs à 2020, on doit prévoir en solution de fallback, l’affichage d’images en JPEG.
Il existe des attributs natifs HTML qui permettent de mettre facilement en place un fallback. Il y à la balise <picture>.
Voici un exemple de fallback: dans la balise <picture> , on retrouve 2 balises <source> une image avec un format avif et l’autre avec une image en webp. On retrouve aussi une balise <img> qui contient une image.jpg. Si le navigateur de l’utilisateur ne supporte pas ni le avif ni le webp, ça sera la version jpg qui sera présentée à l’utilisateur.
<picture>
<source srcset="photo.avif" type="image/avif" />
<source srcset="photo.webp" type="image/webp" />
<img src="photo.jpg" alt="texte alternatif" />
</picture>
En passant, voilà des explications complémentaires sur le texte alternatif.
Conclusion
Avant de pouvoir sélectionner le format d'image le plus pertinent pour un projet, il était indispensable de maîtriser ces notions fondamentales : de l'encodage au décodage, en passant par la compression (avec ou sans perte), le canal alpha et la compatibilité navigateur.
C’est sur ces bases solides que nous pourrons maintenant plonger dans le vif du sujet : l'état des lieux des formats d'images actuels. Dans le prochain article de cette série, nous détaillerons les spécificités techniques, les avantages et les inconvénients du JPEG, du PNG, et des formats récents et prometteurs comme le WebP, l'AVIF et le JPEG XL. Nous vous donnerons les clés pour choisir, en fonction de vos priorités (qualité, performance, écoresponsabilité), le format le plus adapté à vos besoins.
À très bientôt pour la suite…
ℹ️ Lien pour retrouver l’ensemble des articles de cette série “Entre pixels et réalité”.