ElastiCache d'Amazon
En septembre dernier, Amazon annonce la disponibilité de l’offre ElastiCache. Bien nommé, il propose un service de cache distribué ‘in-memory’. Quels sont les intérêts et limitations de cette offre ? C’est ce que nous verrons après l'avoir détaillée.
ElastiCache, kesako ?
C’est un ensemble de web-services pour la gestion de cluster ‘Memcached’.
Jusque là ça va, mais memcached c’est quoi ?
A la question « qu’est-ce que memcached ? », consultez cet article pour une réponse complète. Rapidement, il s’agit d’une solution open source de cache objet distribué où les données accessibles sous forme clé/valeur sont stockées en RAM sur des serveurs de caches (aussi appelés nœuds memcached). L’utilisation typique qui en est fait est le partage de données de sessions au sein de clusters applicatifs.
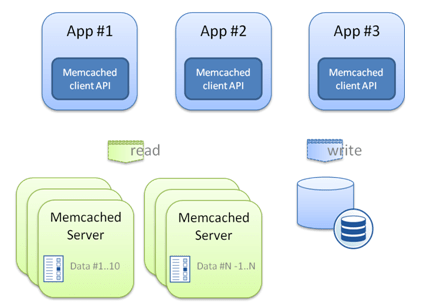
L’ensemble du cache est constitué de ces serveurs plus les clients. En effet, chaque client doit connaître la liste des nœuds, ce qui lui permet de déterminer quel nœud interroger pour une clé donnée. Globalement, deux algorithmes sont possibles : modulo et consistent hashing, ce dernier étant moins sensible à la modification du nombre de nœuds du cluster. Les clients memcached sont disponibles pour divers environnements, notamment JAVA, PHP, Python, C++, .Net, MySQL …
Qu’apporte ElastiCache ?
Avant la disponibilité d’ElastiCache, il était toujours possible créer un cluster memcached à la main à partir de ses propres instances EC2. Cela entrainait les étapes suivantes :
- Créer une image disque de référence (AMI) pour vos nœuds. Cette référence doit contenir l’OS ainsi que la stack memcached.
- Configurer l‘image disque pour que les futures instances EC2 lancées à partir de cette référence soient fonctionnelles dès le boot On pense notamment au démarrage des services requis et au paramétrage memcached (quel espace alloué en RAM ?, quelle taille maximale d’objets ?...). A ce stade, on note déjà une première difficulté, qui est d’adapter la configuration du cache à la taille de RAM, et donc au type de l’instance EC2.
- Lancer vos n nœuds à partir de l’AMI de référence
L’architecture jusque là assez simple, se complique si l’on souhaite introduire une certaine tolérance à la panne du cluster. Le concept d’auto-scaling proposé par Amazon correspond au besoin : la création de nœuds memcached au sein d’un groupe ‘Auto scaling’ avec les nombres d’instances min / max égaux à n permet d’assurer un nombre constant de nœuds toujours fonctionnels. Est-ce suffisant ? Non. Rappelons en effet qu’une instance EC2 se voit attribuer une paire d’IPs (publique et privée au sein du Datacenter Amazon) de manière aléatoire lors du démarrage. Ainsi, supposons qu’un nœud memcached tombe, le nœud le remplaçant aura de nouvelles adresses qui seront inconnues des clients. Des contournements seraient possibles : mise en place de hooks au démarrage de chaque nœud pour l’associer à une IP fixe (elasticIP), ou bien utiliser des notifications pour mettre à jour la liste des nœuds par les clients.
Une telle solution présente de nombreux désagréments : complexité tarifaire, complexité technique, gestion unitaire des nœuds…
Avec ElastiCache, c’est beaucoup plus simple puisque le service avance les fonctionnalités suivantes :
- Tolérance à la panne : les nœuds sont monitorés et remplacés lorsqu’un problème applicatif ou réseau se manifeste. Les noms DNS sont préservés ce qui résout les problèmes de mise à jour des listes de nœuds utilisées par les clients.
- Monitoring. De manière graphique au travers de la console de Management Amazon ou en appelant des web-services, il est possible de remonter des métriques sur chaque nœud, telles que l’utilisation RAM/CPU, le nombre d’entrées dans le cache, le nombre de clés demandées absentes, le nombre de connexions**…**
- Mise à jour du service applicatif. Pour cela, vous devez définir une fenêtre de maintenance d’une heure. La montée de version mineure peut être désactivée mais pas la mise à jour des patchs de sécurité.
- Elasticité. Dans le cas d’ajout ou suppression de nœuds du cluster, il est nécessaire de mettre à jour la liste des nœuds disponibles sur chaque client. Le service ElastiCache intègre la gestion d’évènements associés à un cluster de cache. Parmi ces évènements (remplacement d’un nœud défectueux, arrêt du cluster…), certains sont générés lors de l’ajout ou la suppression d’un nœud. Prévus pour être diffusés via le service de notifications SNS, le cadre technique est disponible pour automatiser les mises à jour sur les clients des nœuds à utiliser**.**
Au niveau de la sécurité, rien n'a été ajouté en passant à ElastiCache. Il n'y a donc aucune fonctionnalité de contrôle d’accès au niveau applicatif. Cependant, les nœuds ElastiCache, sont comme toutes les autres instances EC2, associés à des groupes de sécurité. Il s’agit de configurations de pare-feu agissant au niveau réseau. Dans le cas d’instances EC2 « classiques », il est possible de définir des plages d’adresses IP publiques autorisées pour les connexions entrantes. Cela n’est pas possibles pour les instances ElastiCache : on ne peut déclarer que des groupes de machines EC2 ou bien des machines appartenant à un utilisateur EC2. La conséquence est que seuls des clients hébergés sur des instances EC2 de la même région peuvent s’y connecter (en même temps, avoir des clients ‘on-premises’ qui requêtent un cache situé sur un data center AWS (Irlande par exemple), n’a pas beaucoup de sens en terme de performance).
En complément la tarification se veut assez claire : on paye par mois au nombre d’heures UP par nœud. Dans le cas où les instances EC2 clientes sont dans une autre zone de disponibilité que le cluster Memcached, 0,01$ sont comptés par Go entrant/sortant.
L’API
C’est un ensemble de Web-services REST sur HTTPS. Amazon propose d’appeler l’API depuis :
- Les clients en ligne de commande
- Les librairies pour différents langages (JAVA, Python, PHP, Ruby, .Net)
- La console Web ‘AWS Mangement Console’
Création, modification et suppression d’un cluster de cache.
Créer un cluster est simple, il suffit d’indiquer un nom de cluster, un nombre de nœuds avec leur configuration matérielle, et enfin un groupe de sécurité pour identifier quelles instances EC2 clientes pourront s’y connecter. Il est important de noter que toutes les instances d’un cluster doivent avoir le même profil matériel et la même configuration memcached (nous en reparlons plus tard).
L’ajout ou la suppression d’un nœud est aussi simple, il suffit d’une requête contenant l’identifiant du cluster.
Enfin, les opérations possibles pour la gestion du cluster sont :
- l’activation des notifications SNS. Elles permettent de recevoir des notifications par SMS, mail au format JSON ou texte ; ou encore d’exécuter des requêtes http.
- L’ajustement de la fenêtre de maintenance.
Configuration Memcached
Tous les nœuds d’un cluster partagent la même configuration memcached. Cette configuration fixe des paramètres comme la taille maximale d’un objet, le nombre de connexions simultanées, la taille RAM maximum, le nombre de threads...
Amazon propose une configuration adaptée pour chaque profil matériel. Il est cependant possible de sur-charger des paramètres.
Gestion des groupes de sécurité
Il est question de créer, supprimer et modifier les groupes de sécurité du cache. Ils sont à ne pas confondre avec les groupes de sécurité EC2 puisqu’un groupe destiné à sécuriser un cluster ElastiCache peut référer un ou plusieurs groupes de sécurité EC2.
Monitoring du cluster
Le monitoring du cluster passe par l’API CloudWatch. Celle-ci retourne des métriques mises à jour toutes les minutes dans le cas d’ElastiCache. On trouve deux types de métriques : celles qui portent sur chaque nœud et celles au niveau du cluster. En outre, la commande memcached stats a été intégrée à CloudWatch.
Les métriques disponibles sont donc :
- Au niveau nœud : utilisation CPU, utilisation du SWAP, mémoire libre, trafic réseau. A cela, s’ajoute les statistiques memcached comme le nombre d’octets utilisés, le nombre d’objets stockés, de connexions actives, de requêtes dont la clé a été trouvée…
- Au niveau du cluster, les métriques sont : le nombre de nouvelles connexions, le nombre d’objets ajoutés et enfin l’espace mémoire inutilisé.
Listes des événements.
Comme indiqué plus haut, un cluster ElastiCache génère des évènements qui peuvent être relayés par des notifications. Dans tous les cas, les évènements sont loggés et donc consultables pendant 14 jours au maximum.
Règles de mises en œuvre
Dans le cadre d’une utilisation classique d’un cache de données, c’est à dire entre une base de données et une application, mettre en place un cluster ElastiCache, c’est répondre aux questions : combien de nœuds ? Avec quelle configuration matérielle ?
Pour répondre à ces questions, trois éléments sont à prendre en compte :
1) La taille totale du cluster, qui doit couvrir le besoin total de mémoire requis pour l’intégralité des données stockées.
2) Le partitionnement, qui doit offrir une granularité suffisamment petite pour ne pas écrouler la base de données backend lors de la chute d’un noeud.
3) Le prix.
Taille du cluster
Le stockage des objets dans memcached repose sur l’allocation pré-établie de briques mémoire de différentes tailles. La liste des tailles étant configurable en indiquant une taille minimale et un facteur d’agrandissement récursif. Comme expliqué dans l’article suivant, un objet de 1001 octets occupe une place de 1250 octets.
C’est pourquoi le calcul de la taille du cluster qui est assez simple en première approche – multiplication de la taille moyenne des objets par le nombre d’objets à stocker – implique d’arrondir la taille moyenne des objets à la taille supérieure de la brique mémoire englobante (1250 octets occupés pour une taille moyenne de 1001 octets). Enfin, plus l’écart type sur la taille des objets à mettre en cache sera élevé, plus l’assertion sur le calcul de la taille mémoire sera fausse.
Partitionnement
C’est un compromis entre le nombre de nœuds que l’on s’autorise à perdre, pendant combien de temps, et la puissance mise de coté au niveau de la base de données pour repeupler les nœuds remplaçant ceux tombés. Une solution pour limiter les accès à la base de données pour reconstruire une partie du cache serait d’effectuer une réplication du cluster ElastiCache (« à la main », c’est à dire au niveau applicatif puisqu’Amazon ne propose rien sur ce sujet.).
Dans les faits, le partitionnement de cache est réservé aux applications plaçant de très gros volumes de données en cache (plusieurs Go).
Prix
Il est temps de revenir sur la tarification ElastiCache pour un noeud :
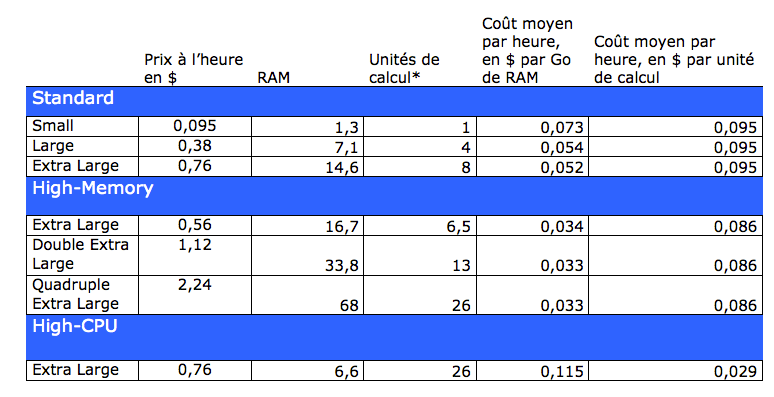
*Pour information, Amazon indique qu’une unite de calcul est équivalente à un Opteron ou un Xeon de 1.0 à 1.2 GHz en 2007.
Avant d’aller plus loin, indiquons que la solution memcached étant réputée pour être économe en CPU, nous partons du principe qu’un cluster de cache est avant tout gourmand en mémoire. C’est pourquoi dans la suite, nous nous focalisons sur la RAM, laissant de côté les capacités de calcul.
Le graphique suivant reprend les données du tableau de coût :
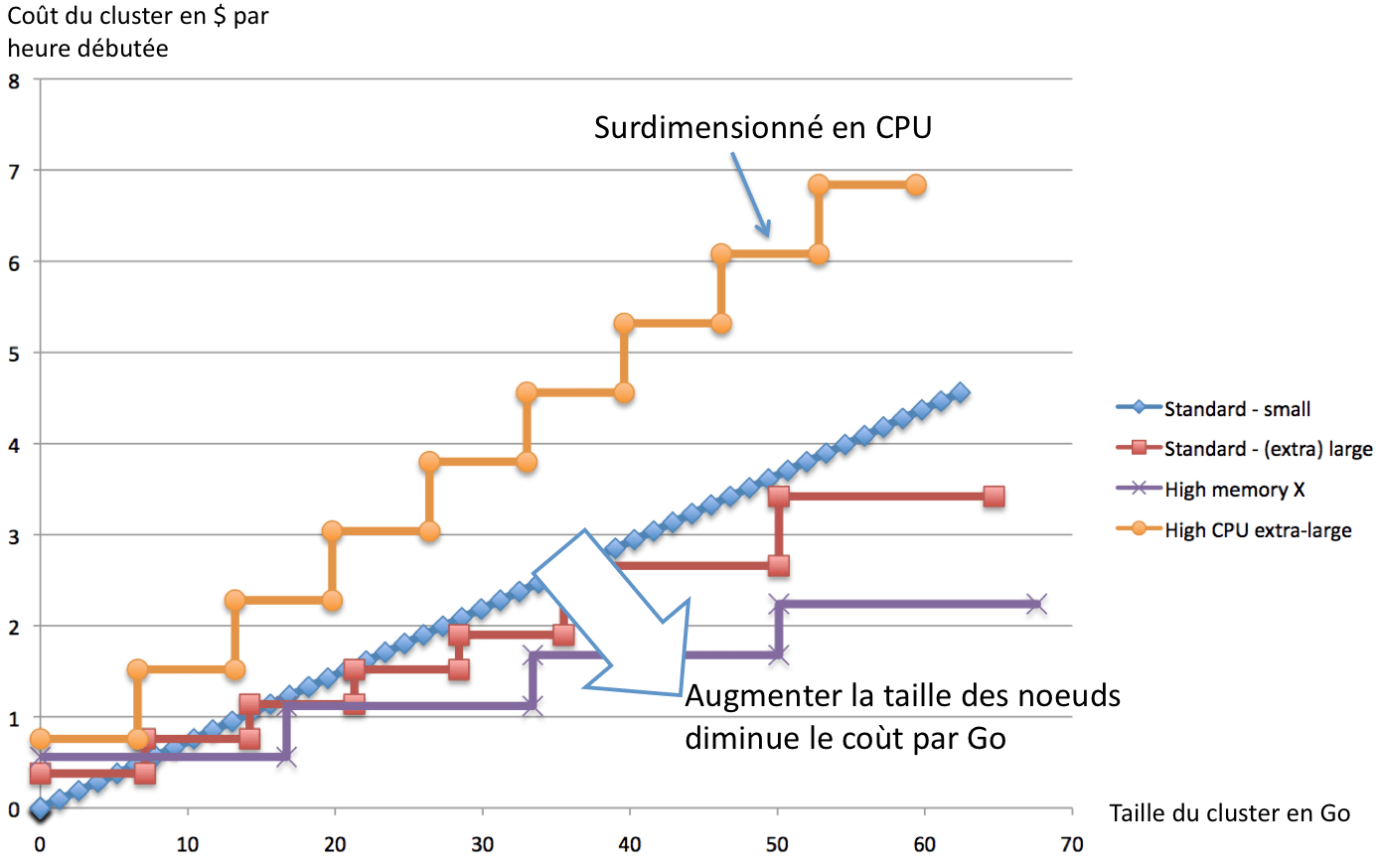
Puisque les instances Large et Extra-Large de la catégorie Standard ont un coût par Go de RAM identique, nous les faisons apparaître sous le libellé « Standard – (extra) large ». De la même manière, les instances de la catégorie High-Memory sont groupées dans la même courbe.
Première remarque : les coûts unitaires les plus faibles par RAM et CPU sont obtenus pour les configurations les plus grosses. Amazon cherche à faciliter l’emploi de machines performantes au lieu d’une multitude de petites instances en parallèle. Utiliser des nœuds de 68 Go de mémoire est moins onéreux qu’utiliser 53 nœuds de 1,3 Go de RAM.
La catégorie HIGH-GPU favorise les capacités de calcul à la RAM, ce qui les réserve à des applications sollicitant particulièrement les nœuds ElastiCache.
Pour terminer cette partie sur les coûts, il est intéressant de faire un zoom sur les « petits » espaces de cache ; de 0 à 14 Go :
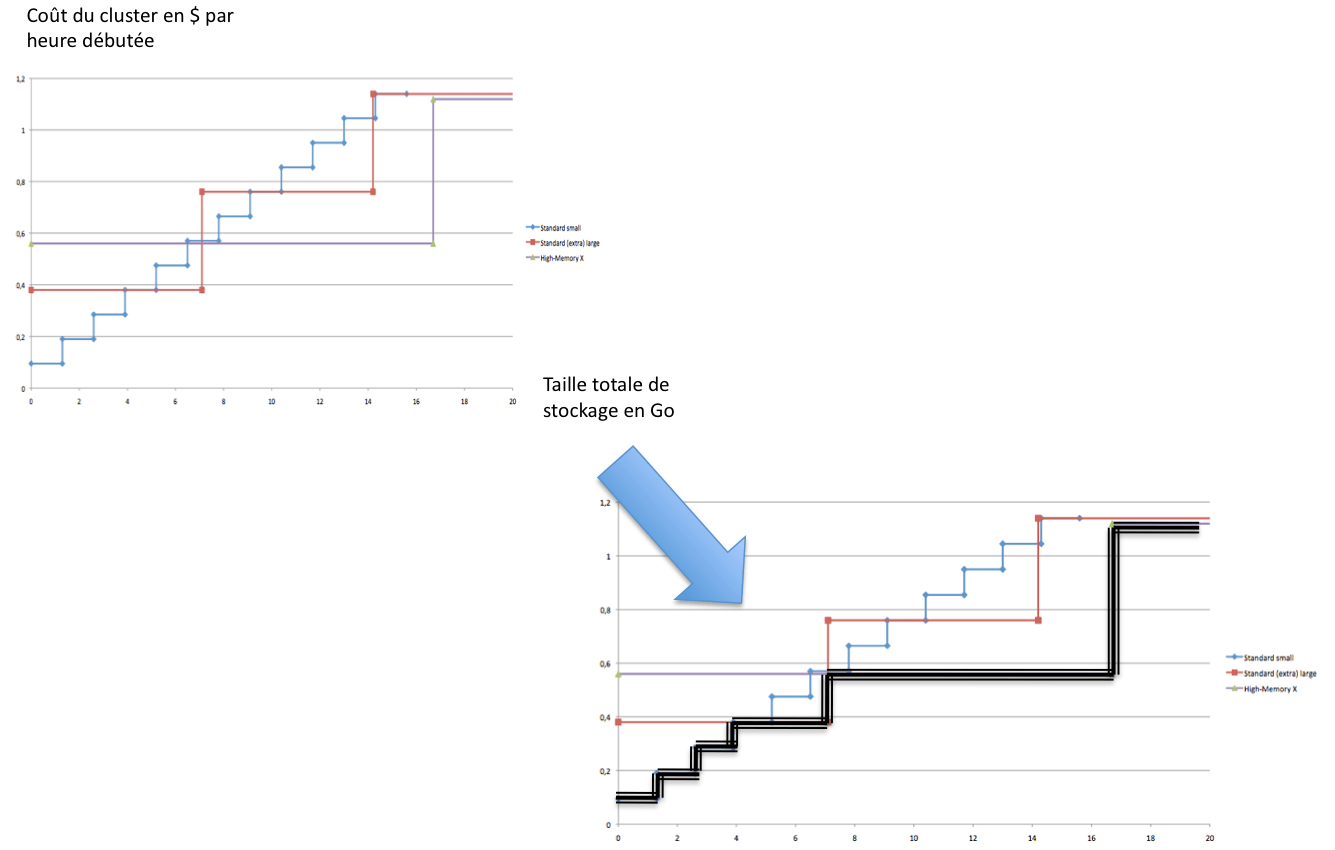
Jusqu’à un besoin de 3,9 Go de mémoire, 3 nœuds « SMALL » font le job. Au delà, il est préférable de passer à des instances LARGE compte tenu du surcoût en RAM généré par les instances SMALL. Enfin, pour des besoins supérieurs à 7,1 Go, il semble plus pertinent d’utiliser des nœuds de la catégorie HIGH-MEMORY plutôt que de doubler le nombre de nœuds STANDARD-LARGE.
Etude de cas
Supposons que l’on ait une application A nécessitant 4 Go de cache. Cette application exécute 100 requêtes par seconde sur le cluster de cache. Nous avons vu précédemment que pour un cache de 4 Go, un seul nœud de type Standard – Large permettait d’avoir le coût le plus bas. La chute de ce nœud implique que la base de données doit absorber les 100 requêtes par seconde pour repeupler le nœud remplaçant.
Supposons maintenant que nous ayons une application B qui effectue 300 requêtes par seconde en cache avec une base de données qui offre des temps de réponse acceptable jusqu’à 100 QPS. Si nous restons sur un seul nœud ElastiCache, la base de données s’écroulera lors de la construction du cache. Cela pourra être acceptable au démarrage de l’application (temps de Warm-Up), mais ne le sera pas le cas lorsque des utilisateurs seront en ligne et que le nœud du cache tombera au milieu d’une transaction. Dans ce cas, il nous faudra partitionner le cache pour diminuer le nombre de requêtes en base pendant une phase de reconstruction d’un nœud.
Conclusion
Avec ElastiCache, Amazon fait un coup similaire à ElasticBeanstalk : agréger différents services EC2 pour proposer une offre qui facilite l’instanciation et le monitoring. En effet, une ligne de commande suffit à obtenir un cluster de nœuds offrant des capacités de monitoring et une gestion centralisée.
Au niveau des regrets, Amazon n’a pas mis en œuvre de redondance sur les clusters. Si un nœud tombe, il sera remplacé par une nouvelle instance « vide ». Il sera nécessaire de peupler cette nouvelle instance. La redondance pourrait permettre de penser à de nouvelles utilisations de la stack memcached (en tant que base de données clé/valeur chargée en mémoire par exemple), or elle est à gérer à la main : créer deux clusters dans deux zones de disponibilités différentes puis synchroniser les 2 clusters en écriture et lire dans le cluster secondaire si un nœud du cluster primaire est tombé.